TF项目实战(SSD目标检测)-VOC2007
TF项目实战(SSD目标检测)-VOC2007
理论详解:https://blog.csdn.net/u013989576/article/details/73439202
训练好的模型和代码会公布在网上(含 VOC数据集 vgg16 模型 以及训练好的模型):
待续
步骤:
1.代码地址:https://github.com/balancap/SSD-Tensorflow
2.解压ssd_300_vgg.ckpt.zip 到checkpoint文件夹下(另外将vgg16模型放在本路径下)

3.测试一下看看,在notebooks文件夹下创建demo_test.py,其实就是复制ssd_notebook.ipynb中的代码,该py文件是完成对于单张图片的测试。
import os
import math
import random import numpy as np
import tensorflow as tf
import cv2 slim = tf.contrib.slim
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import sys sys.path.append('../')
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
from notebooks import visualization # TensorFlow session: grow memory when needed. TF, DO NOT USE ALL MY GPU MEMORY!!!
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
# Input placeholder.
net_shape = (300, 300)
data_format = 'NHWC'
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
# Evaluation pre-processing: resize to SSD net shape.
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format, resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
image_4d = tf.expand_dims(image_pre, 0) # Define the SSD model.
reuse = True if 'ssd_net' in locals() else None
ssd_net = ssd_vgg_300.SSDNet()
with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)):
predictions, localisations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse) # Restore SSD model.
ckpt_filename = '../checkpoints/ssd_300_vgg.ckpt'
# ckpt_filename = '../checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt'
isess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(isess, ckpt_filename) # SSD default anchor boxes.
ssd_anchors = ssd_net.anchors(net_shape) # Main image processing routine.
def process_image(img, select_threshold=0.5, nms_threshold=.45, net_shape=(300, 300)):
# Run SSD network.
rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],
feed_dict={img_input: img}) # Get classes and bboxes from the net outputs.
rclasses, rscores, rbboxes = np_methods.ssd_bboxes_select(
rpredictions, rlocalisations, ssd_anchors,
select_threshold=select_threshold, img_shape=net_shape, num_classes=21, decode=True) rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
rclasses, rscores, rbboxes = np_methods.bboxes_nms(rclasses, rscores, rbboxes, nms_threshold=nms_threshold)
# Resize bboxes to original image shape. Note: useless for Resize.WARP!
rbboxes = np_methods.bboxes_resize(rbbox_img, rbboxes)
return rclasses, rscores, rbboxes # Test on some demo image and visualize output.
# 测试的文件夹
path = '../demo/'
image_names = sorted(os.listdir(path))
# 文件夹中的第几张图,-1代表最后一张
img = mpimg.imread(path + image_names[-1])
rclasses, rscores, rbboxes = process_image(img) # visualization.bboxes_draw_on_img(img, rclasses, rscores, rbboxes, visualization.colors_plasma)
visualization.plt_bboxes(img, rclasses, rscores, rbboxes)
4. 将自己的数据集或者 VOC2007直接放在工程目录下
5. 修改datasets文件夹中pascalvoc_common.py文件,将训练类修改别成自己的(这里如果自己的类别) 本文以两类为例子
VOC_LABELS = {
'none': (0, 'Background'),
'aeroplane': (1, 'Vehicle'),
'bicycle': (2, 'Vehicle'),
'bird': (3, 'Animal'),
'boat': (4, 'Vehicle'),
'bottle': (5, 'Indoor'),
'bus': (6, 'Vehicle'),
'car': (7, 'Vehicle'),
'cat': (8, 'Animal'),
'chair': (9, 'Indoor'),
'cow': (10, 'Animal'),
'diningtable': (11, 'Indoor'),
'dog': (12, 'Animal'),
'horse': (13, 'Animal'),
'motorbike': (14, 'Vehicle'),
'person': (15, 'Person'),
'pottedplant': (16, 'Indoor'),
'sheep': (17, 'Animal'),
'sofa': (18, 'Indoor'),
'train': (19, 'Vehicle'),
'tvmonitor': (20, 'Indoor'),
}
#自己的数据
# VOC_LABELS = {
# 'none': (0, 'Background'),
# 'aeroplane': (1, 'Vehicle'),
# }
6. 将图像数据转换为tfrecods格式,修改datasets文件夹中的pascalvoc_to_tfrecords.py文件,然后更改文件的83行读取方式为’rb‘,如果你的文件不是.jpg格式,也可以修改图片的类型。

另外这个修改

7.运行tf_convert_data.py文件,但是需要传给它一些参数: 这个文件生成TFrecords文件的代码
但是该文件需要像类似于linux 命令那样传入参数。 pycharm中如何解决呢???
假设我们需要执行:python ./tf_convert_data.py --dataset_name=pascalvoc --dataset_dir=./VOC2007/ --output_name=voc_2007_train --output_dir=./tfrecords_怎么办呢?
我们可以在 run中的 Edit ... 进入
一、
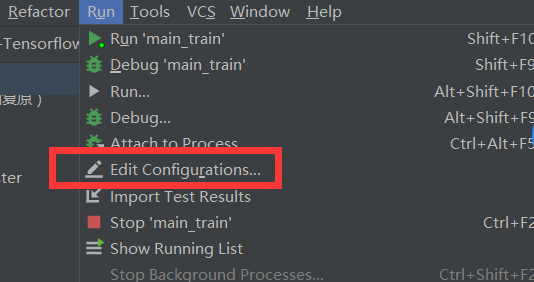
二、

三、

参数:--dataset_name=pascalvoc --dataset_dir=./VOC2007/ --output_name=voc_2007_train --output_dir=./tfrecords_
然后执行该py文件就ok。
如果出现错误(文件夹相关的错误),则在工程下建立一个文件夹 就可以了。
就可以了。
8.训练模型train_ssd_network.py文件中修改

None代表一直训练。

其它需要修改的文件:
① nets/ssd_vgg_300.py (因为使用此网络结构) ,修改87 和88行的类别

② train_ssd_network.py,修改类别120行,GPU占用量,学习率,batch_size等
③ eval_ssd_network.py 修改类别,66行

④ datasets/pascalvoc_2007.py 根据自己的训练数据修改整个文件
9.开始训练
类似于第7步中的 三
训练的主文件为 train_ssd_network.py
参数为:
--train_dir=./train_model/ --dataset_dir=./tfrecords_/ --dataset_name=pascalvoc_2007 --dataset_split_name=train --model_name=ssd_300_vgg --checkpoint_path=./checkpoints/vgg_16.ckpt --checkpoint_model_scope=vgg_16 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --save_summaries_secs=60 --save_interval_secs=600 --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --learning_rate_decay_factor=0.94 --batch_size=24 --gpu_memory_fraction=0.9

训练过程
:
10 测试:
先看效果


另外我修改了demo_test文件 调取电脑摄像投来执行代码。

如果单独看一张图的效果则执行函数:

代码如下:
__author__ = "WSX"
import os
import math
import random import numpy as np
import tensorflow as tf
import cv2 slim = tf.contrib.slim
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import sys sys.path.append('../')
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
from notebooks import visualization # TensorFlow session: grow memory when needed. TF, DO NOT USE ALL MY GPU MEMORY!!!
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
# Input placeholder.
net_shape = (300, 300)
data_format = 'NHWC'
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
# Evaluation pre-processing: resize to SSD net shape.
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format, resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
image_4d = tf.expand_dims(image_pre, 0) # Define the SSD model.
reuse = True if 'ssd_net' in locals() else None
ssd_net = ssd_vgg_300.SSDNet()
with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)):
predictions, localisations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse) # Restore SSD model.
ckpt_filename = '../checkpoints/ssd_300_vgg.ckpt'
# ckpt_filename = '../checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt'
isess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(isess, ckpt_filename) # SSD default anchor boxes.
ssd_anchors = ssd_net.anchors(net_shape) # Main image processing routine.
def process_image(img, select_threshold=0.5, nms_threshold=.45, net_shape=(300, 300)):
# Run SSD network.
rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],
feed_dict={img_input: img}) # Get classes and bboxes from the net outputs.
rclasses, rscores, rbboxes = np_methods.ssd_bboxes_select(
rpredictions, rlocalisations, ssd_anchors,
select_threshold=select_threshold, img_shape=net_shape, num_classes=21, decode=True) rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
rclasses, rscores, rbboxes = np_methods.bboxes_nms(rclasses, rscores, rbboxes, nms_threshold=nms_threshold)
# Resize bboxes to original image shape. Note: useless for Resize.WARP!
rbboxes = np_methods.bboxes_resize(rbbox_img, rbboxes)
return rclasses, rscores, rbboxes #===========================================测试部分===========================================
#----------------------------------单张图片测试---------------------------
# Test on some demo image and visualize output.
# 测试的文件夹
def demo():
path = '../demo/'
image_names = sorted(os.listdir(path))
# 文件夹中的第几张图,-1代表最后一张
img = mpimg.imread(path + image_names[-1])
print(img.shape)
rclasses, rscores, rbboxes = process_image(img) # visualization.bboxes_draw_on_img(img, rclasses, rscores, rbboxes, visualization.colors_plasma)
visualization.plt_bboxes(img, rclasses, rscores, rbboxes) #======================================做成实时显示的代码===================================================
L = ["None","aeroplane","bicycle","bird ","boat ","bottle ","bus ","car ","cat ","chair","cow ","diningtable","dog","horse","motorbike","person",
"pottedplant","sheep","sofa","train","tvmonitor"]
colors_tableau = [(255, 255, 255), (31, 119, 180), (174, 199, 232), (255, 127, 14), (255, 187, 120),
(44, 160, 44), (152, 223, 138), (214, 39, 40), (255, 152, 150),
(148, 103, 189), (197, 176, 213), (140, 86, 75), (196, 156, 148),
(227, 119, 194), (247, 182, 210), (127, 127, 127), (199, 199, 199),
(188, 189, 34), (219, 219, 141), (23, 190, 207), (158, 218, 229)] def Load_video_show(): #获取视频
video = cv2.VideoCapture("1.mp4") # 0 表示摄像头 , 如果为文件路径则 为加载视频
while (True):
ret, frame = video.read() #frame为 帧 这里当做一张图
frame = cv2.flip( frame ,1) #镜像变换,图像正与不正
cv2.resizeWindow("video", 640, 360) #设置窗口大小
frame = cv2.resize(frame, (640, 360)) #设置图大小
#cv2.imshow("video" ,frame)
rclasses, rscores, rbboxes = process_image(frame)
height = frame.shape[0]
width = frame.shape[1]
colors = dict()
for i in range(rclasses.shape[0]):
cls_id = int(rclasses[i])
if cls_id >= 0:
score = rscores[i]
if cls_id not in colors:
colors[cls_id] = (random.random(), random.random(), random.random())
ymin = int(rbboxes[i, 0] * height)
xmin = int(rbboxes[i, 1] * width)
ymax = int(rbboxes[i, 2] * height)
xmax = int(rbboxes[i, 3] * width)
cv2.rectangle(frame, (xmin, ymin), (xmax,ymax), colors[cls_id], 2) #画矩形框
class_name = L[cls_id]
cv2.putText(frame, '{:s} | {:.3f}'.format(class_name, score), (xmin, ymin - 2,), cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 255, 0), 1) #写文字
cv2.imshow("video", frame)
c = cv2.waitKey(50)
if c == 27: #esc退出
break #Load_video_show()
demo()
TF项目实战(SSD目标检测)-VOC2007的更多相关文章
- 从零开始实现SSD目标检测(pytorch)(一)
目录 从零开始实现SSD目标检测(pytorch) 第一章 相关概念概述 1.1 检测框表示 1.2 交并比 第二章 基础网络 2.1 基础网络 2.2 附加网络 第三章 先验框设计 3.1 引言 3 ...
- TF项目实战(基于SSD目标检测)——人脸检测1
SSD实战——人脸检测 Tensorflow 一 .人脸检测的困难: 1. 姿态问题 2.不同种族人, 3.光照 遮挡 带眼睛 4.视角不同 5. 不同尺度 二. 数据集介绍以及转化VOC: 1. F ...
- AI SSD目标检测算法
Single Shot multibox Detector,简称SSD,是一种目标检测算法. Single Shot意味着SSD属于one stage方法,multibox表示多框预测. CNN 多尺 ...
- 动手创建 SSD 目标检测框架
参考:单发多框检测(SSD) 本文代码被我放置在 Github:https://github.com/XinetAI/CVX/blob/master/app/gluoncvx/ssd.py 关于 SS ...
- caffe SSD目标检测lmdb数据格式制作
一.任务 现在用caffe做目标检测一般需要lmdb格式的数据,而目标检测的数据和目标分类的lmdb格式的制作难度不同.就目标检测来说,例如准备SSD需要的数据,一般需要以下几步: 1.准备图片并标注 ...
- 如何使用 pytorch 实现 SSD 目标检测算法
前言 SSD 的全称是 Single Shot MultiBox Detector,它和 YOLO 一样,是 One-Stage 目标检测算法中的一种.由于是单阶段的算法,不需要产生所谓的候选区域,所 ...
- 【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!
文章目录 1 目标检测简介 2 lmdb数据制作 2.1 VOC数据制作 2.2 lmdb文件生成 lmdb格式的数据是在使用caffe进行目标检测或分类时,使用的一种数据格式.这里我主要以目标检测为 ...
- SSD目标检测实战(TF项目)——人脸检测2
数据转化为VOC格式: 一.我们先看 VOC格式的数据是什么??? Annotations:存放xml 包括 文件夹信息 图片名称. 图片尺寸信息. 图片中object的信息. JPEGImage ...
- 使用SSD目标检测c++接口编译问题解决记录
本来SSD做测试的Python接口用起来也是比较方便的,但是如果部署集成的话,肯定要用c++环境,于是动手鼓捣了一下. 编译用的cmake,写的CMakeList.txt,期间碰到一些小问题,简单记录 ...
随机推荐
- 基于Monte Carlo方法的2048 A.I.
2048 A.I. 在 stackoverflow 上有个讨论:http://stackoverflow.com/questions/22342854/what-is-the-optimal-algo ...
- 三星860 evo 250g 开启AHCI模式读写对比
主板比较老,只支持sata2接口 换用三星860evo后跑分对比
- LFS Linux From Scratch 笔记(经验非教程)
做了一个自己的DIY Linux系统.从编译每一行代码,建立每一个文件系统结构开始. 创造自己的GNU/Linux系统,不同于任何发行版.按照的教程是来自 linuxfromscratch.org 来 ...
- PHP PSR4自动加载代码赏析
第一部分是引入自动加载配置文件 1.入口文件:autoload.php里面没什么东西,就是导入ComposerAutoloader主题文件,一般由一个复杂的名字,不过不用担心就是机器随机生成的一个码而 ...
- python代码检查工具pylint 让你的python更规范
1.pylint是什么? Pylint 是一个 Python 代码分析工具,它分析 Python 代码中的错误,查找不符合代码风格标准(Pylint 默认使用的代码风格是 PEP 8,具体信息,请参阅 ...
- m3u8解析、转码、下载、合并
m3u8解析.转码.下载.合并 现在网也上大多数视频需要下载都很麻烦,极少数是MP4,大多都是m3u8, 先说视频下载, pc端: 打开网页,点击视频播放,打开开发者工具,找到网络那一栏, 等整个网页 ...
- 自定义实现一个loghub(或kafka)的动态分片消费者负载均衡?
一般地,像kafka之类的消息中间件,作为一个可以保持历史消息的组件,其消费模型一般是主动拉取方式.这是为了给消费者足够的自由,回滚或者前进. 然而,也正是由于将消费消息的权力交给了消费者,所以,消费 ...
- JS中闭包的介绍
闭包的概念 闭包就是能够读取其他函数内部变量的函数. 一.变量的作用域 要理解闭包,首先必须理解Javascript特殊的变量作用域. 变量的作用域无非就是两种:全局变量和局部变量. Javascri ...
- Python笔记【2】_列表学习
#!/usr/bin/env/python #-*-coding:utf-8-*- #Author:LingChongShi #查看源码Ctrl+左键 #字符串:通常有单引号“'”.双引号“" ...
- golang切片和数组的区别
好久的没有写博客了,这段时间没事研究了下go这门语言. 我们先介绍下go中的数组和切片的区别和用法 说了这么多 我们先来看段代码吧 var arr1 [3]int var arr2 [3]int = ...