Java面试题汇总---升级版(附答案)
前几天写了Java面试题汇总---基础版,总结了面试中常见的问题及答案,那我今天基于昨天的话题做一次升级,也就是说,求职者除了要学习了解哪些常见的基础面试题之外,还得准备些什么呢?
对有工作经验的求职者来说,项目经历也是一个重点。这个我想大家应该还是比较清楚,你要知道,一般招聘有经验的人,不是你投的,就是HR通过用人部门需求关键词搜索到你的。比如用人部门想招聘几个有分布式开发和电商项目经验的,那么HR可能会用“Dubbo”,“SpringCloud”,“电商”等关键词搜索。那你去面试,这些技术及相关内容也就是常问的话题了。
一,项目经验
当HR邀约你去面试前,简历中写到的项目一定得总结熟悉,尤其之前项目中涉及的技术。我曾经有面试一个JAVA开发,当时他的简历写的很完美,有三年多的开发经验,而却最近一个项目是B2C的电商项目,什么Dubbo, ZK, Redis, MQ, Springboot, FastDfs等目前新的技术一应俱全。然后我就问他Dubbo和ZK的理解以及它们怎么协调工作,他回答的却很简单,仅仅概念上的一些东西。后来又问他文件服务是用什么技术实现的,他告诉一个完全听不懂的玩意,然后我指着简历上的FastDFS问他用来做什么,然后发现他楞了一下,接着说不好意思他说错了,然后顺带问了下FastDFS,他竟然完全说不清楚,那面试的结果呢,肯定是over了。但那哥们最后还算坦诚,告诉我B2C电商项目他没做过,是从其他地方搬过来的,为了提高简历曝光率。因此,我要告诉大家,简历中的项目经历可以适当包装,但一定不可过于离谱,你要保证涉及的技术在面试中可控,能应对面试官基础的问答。
二,目前流行技术及问题
这块也是一个重点,要想找一份心仪不错的工作,那你在准备找工作前,一定要了解目前市场动态。最简单的方式,去51job搜你想应聘的岗位,看看各个公司都有什么要求,看过50家,你的心里基本就有数了。在这里,我总结下目前流行的技术吧!
1,分布式
目前最流行的Java后端开发,莫过于分布式开发了。说到分布式,那什么是分布式系统呢?分布式系统就是由多个节点(计算机服务器)组成的系统。而且这些节点一般不是孤立的,是互通的。这些连通的节点上部署了我们的节点,并且相互的操作会有协同。
分布式系统对于用户而言,他们面对的就是一个服务器,提供用户需要的服务而已,而实际上这些服务是通过背后的众多服务器组成的一个分布式系统,因此分布式系统看起来像是一个超级计算机一样。
例如京东商城,这个平时大家都会使用,它本身就是一个分布式系统。当我们使用它的App时,这个请求的背后就是一个庞大的分布式系统在为我们提供服务,整个系统中有的负责请求处理,有的负责存储,有的负责计算,最终他们相互协调把最后的结果返回并呈现给用户。
2,微服务
说完分布式,那什么又是微服务呢?对于微服务,业界并没有一个统一的,标准的定义。通常而言,微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。
而传统项目开发应用程序都是单体型,所有的功能和业务模块都集中在一个项目中,虽然开发和部署比较方便,但后期随着业务的不断增加,开发迭代和性能瓶颈等问题,将会困扰开发工作,微服务就是解决此问题的有效手段。那么要用微服务,他涉及哪些技术呢?大致整理如下:
流行的微服务Java项目框架:Spring Boot
微服务治理:Dubbo, SpringCloud
涉及技术:Zookeeper, Eureka, Redis, MQ等
Dubbo和SpringCloud等原理及区别这里不做解释,我前面的文章《又到了跳槽季,你们都准备好了吗?我来告诉Java程序员们如何快速全面的复习》中有介绍,这里只做相关面试问题汇总。
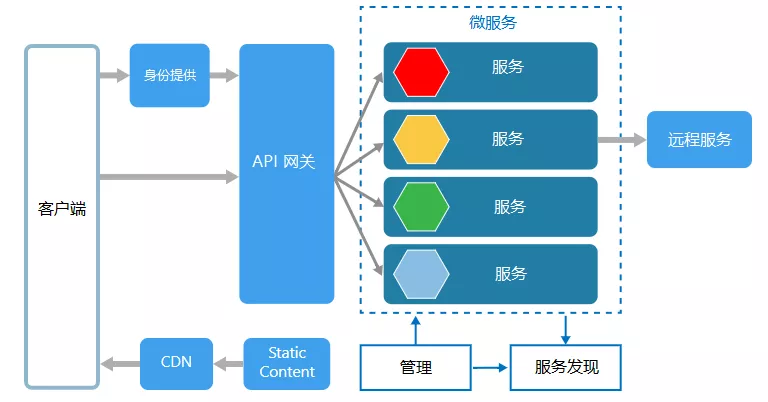
3,分布式环境中如何实现单点登录与session共享
在单服务器web应用中,登录用户信息只需存在该服务的session中,这是我们几年前最长见的办法。而在当今分布式系统的流行中,微服务已成为主流,用户登录由某一个单点服务完成并存储session后,在高并发量的请求(需要验证登录信息)到达服务端的时候通过负载均衡的方式分发到集群中的某个服务器,这样就有可能导致同一个用户的多次请求被分发到集群的不同服务器上,就会出现取不到session数据的情况,于是session的共享就成了一个问题。目前实现session共享的解决方案:
1)Session复制与共享 多个server之间相互同步session,这样每个server上都包含全部Service的session。
优点:tomcat等多数主流web服务器都支持此功能。
不足:session同步需要数据传输,占内网带宽,有时延。所有服务器都包含所有session数据,特别是当session中保存了较大的对象,而且对象变化较快时,性能下降显著,这种特性使得web应用的水平扩展受到了限制。
2)客户端存储法 服务端存储所有用户的session,内存占用较大,也可以将session存储到浏览器cookie中,每个端只要存储一个用户的数据了。
优点:服务端不需要存储
缺点:每次http请求都携带session,占外网带宽数据存储在端上,并在网络传输,存在泄漏、篡改、窃取等安全隐患。session存储的数据大小受cookie限制。
3)反向代理hash一致性 为了保证高可用,有多台冗余,反向代理层能不能做一些事情,让同一个用户的请求保证落在一台web服务器上呢?具体方案:反向代理使用IP或http协议中的某些业务参数来做hash,以保证同一个浏览器用户的请求落在同一个web服务器上。
优点:只需要改nginx配置,不用改应用代码,负载均衡,只要hash属性是均匀的,多台web服务器的负载是均衡的。可以支持web服务器水平扩展(session同步法是不行的,受内存限制)
缺点:如果web服务器重启,一部分session会丢失,产生业务影响,例如部分用户重新登录。如果web服务器水平扩展,rehash后session重新分布,也会有一部分用户路由不到正确的session。
4)服务端集中存储 将session存储在后端的存储层,如:数据库或者缓存。客户端每发次一次请求,都会先从存储中获取,再处理具体的业务逻辑。
优点:无安全隐患,可以水平扩,服务器重启或者扩容都不会造成session丢失。
不足:增加了一次网络调用,要修改应用代码。
总结:一般对单点登录和session共享的处理,大都选择在服务端集中存储来实现。对于db存储还是cache,肯定cache是首选。因为session读取的频率会很高,使用数据库压力会比较大。如果有session高可用需求,cache可以做高可用,但大部分情况下session可以丢失,一般也不需要考虑高可用。目前主流的现实方案是用redis实现session的存储。
4,分布式环境下的事务处理方案
分布式事务顾名思义就是在分布式环境下运行的事务,对于分布式事务来说,事务的每个操作步骤是运行在不同机器上的服务的。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
事务的ACID特性:原子性,一致性,隔离性,持久性。
解决方案:
1)消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败。以支付宝转账到余额宝为例,当支付宝账户扣除1万后,只要生成一个凭证(消息)即可,这个凭证(消息)上写着“让余额宝账户增加 1万”,只要这个凭证(消息)能可靠保存,我们最终是可以拿着这个凭证(消息)让余额宝账户增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
2)TCC编程模式
TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
5,Zookeeper的原理及选举机制?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。Zookeeper可以作为服务协调的注册中心,还可以做分布式锁。它作为注册中心,主要存储的数据是ip、端口,还有心跳机制。
Zookeeper做集群最好是奇数个,它的集群管理主要是检查是否有机器的退出和加入、选举master。Zookeeper的角色主要分:Leader、Follower、Observer。Leader主机负责读和写,Follower负责读,并将写操作转发给Leader,Follower还参与Leader选举投票。Observer充当观察者的角色,不参与投票。当Leader不可用时,会重新选举Leader。超过半数的Follower选举投票即可。
6,使用Redis做缓存有哪些优势?
Redis是内存式缓存,它的存取是纯内存操作,因此性能非常出色,每秒可处理超过10万次读写。它的优势如下:
内存式缓存,读写速度特别快;
支持丰富数据类型,包括:string,list,set,sorted set,hash;
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行;
丰富的特性: 可用于缓存、消息,按key设置过期时间,过期后自动清除;
单线程,单进程,采用IO多路复用技术;
7,分布式系统中如何生成唯一ID?
系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,也常常为这个问题而纠结。生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。下面就介绍一些常见的ID生成策略。
1)数据库自增长序列实现
这是最常见的方式,利用数据库自增ID,实现全数据库ID唯一。
优点:
a)简单,代码方便,性能可以接受。
b)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
a)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
b)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
c)在性能达不到要求的情况下,比较难于扩展。
d)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
e)分表分库的时候会有麻烦。
2) 通过UUID实现
常见的方式。可以利用数据库也可以利用程序生成。UUID的的组成部分:当前日期和时间+时钟序列+全局唯一的IEEE机器识别号。如:550e8400-e29b-41d4-a716-446655440000。
优点:
a)简单,代码方便。
b)生成ID性能非常好,基本不会有性能问题。
c)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
a)没有排序,无法保证趋势递增。
b)UUID往往是使用字符串存储,查询的效率比较低。
c)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
d)传输数据量大,不可读。
3) Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E: 5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
优点:
a)不依赖于数据库,灵活方便,且性能优于数据库。
b)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
a)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
b)需要编码和配置的工作量比较大。
4) Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
a)不依赖于数据库,灵活方便,且性能优于数据库。
b)ID按照时间在单机上是递增的。
缺点:
a)在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
三,其他相关问题
1,Java代码优化(基础版)
Java代码的基本优化总结如下:
1) 尽量指定类、方法的final修饰符, 尽量重用对象, 尽可能用局部变量。
2) 及时关闭流。
3) 尽量减少对变量的重复计算。
4) 尽量采用懒加载的策略,即在需要的时候才创建。
5) 慎用异常,不要在循环中使用try...catch...,应该把其放在最外层。
6) 如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度。
7) 当复制大量数据时,使用System.arraycopy()命令。
8) 乘法和除法使用移位操作。
9) 循环内不要不断创建对象引用。
10) 基于效率和类型检查的考虑,应该尽可能使用array,无法确定数组大小时才使用ArrayList。
11) 尽量使用HashMap、ArrayList、StringBuilder,除非线程安全需要,否则不推荐使用Hashtable、Vector、StringBuffer,后三者由于使用同步机制而导致了性能开销。
12) 不要将数组声明为public static final。
13) 尽量减少硬编码,提高代码的易维护性。
2,谈谈常见的SQL优化?
一般的SQL优化注意及方案:
1)在数据量大的表中建索引, 优先考虑where、group by使用到的字段;
2)避免使用select *,返回无用的字段会降低查询效率;
3)尽量避免使用in 和not in, or等, 导致数据库放弃索引进行全表扫描;
4)尽量避免在 where 子句中使用!=或<>操作符;
5)尽量避免在字段开头模糊查询;
6)尽量避免在Where条件后进行null值;
7)尽量避免在where条件中等号的左侧进行表达式、函数操作;
8)尽量避免向客户端返回大数据量;
9)尽量避免大事务操作,提高系统并发能力;
10)通过EXPLAIN 分析低效 SQL的执行计划;
3,你是如何实现Api接口安全的?
目前市面上有很多实现方案,如最典型的ouath。这里我只谈谈目前最普遍的实现方案。也就是http+token授权+参数签名(sign)的方式。实现方案:
1)token授权 用户登录成功后,服务器端生成一个Token(32位随机字符串),并用这个token为key,登录用户信息为值存放在缓存中(Redis)。然后就token返回客户端,作为授权凭证。
2)封装sign参数 登录后请求任何一个Api接口,请求参数除正常的业务参数外,必须带token,并用业务参数和token参数通过规定的签名算法生成签名,将生成的sign也作为请求参数发起请求。如:通过ID查用户信息,请求参数:{“id”:"11","token":"授权返回的token值","sign":"生成的签名参数"}。
3)过滤器检验拦截 请求发起后,先进入服务端的过滤器,基于相同的签名算法校验sign参数,如果校验不通过,直接拦截请求。如果sign校验通过,再通过请求参数中的token值获取缓存中的登录信息,如果此token在缓存中不存在,我们认为此用户没有登录或登录过期,直接拦截请求。如果获取到登录信息并校验通过,过滤器不做拦截,请求进入服务层。
4,HTTP和HTTPS的区别,及HTTPS工作流程?
这都是些基础知识,但我也曾见过一个Java高级开发者不知道什么的HTTPS。那HTTPS究竟是什么呢?如果你平时细心,应该早都注意到,大多数网站都是用HTTPS请求的,例如:百度。

其实,HTTPS协议就是由HTTP+SSL构建的可进行加密传输、身份认证的网络协议。比http协议安全。
HTTPS工作流程如下:
1) 客户端发送自己支持的加密规则给服务器,告诉服务器要进行连接。
2) 服务器从中选出一套加密算法和hash算法以及自己的身份信息(地址等)以证书的形式发送给浏览器,证书中包含服务器信息,加密公钥,证书的办法机构。
3) 客户端收到网站的证书之后要做下面的事情:
a,验证证书的合法性
b,如果验证通过证书,浏览器会生成一串随机数作为密钥K,并用证书中的公钥进行加密
c,用约定好的hash算法计算握手消息,然后用生成的密钥K进行加密,然后一起发送给服务器
4) 服务器接收到客户端传送来的信息,要求下面的事情:
a,用私钥解析出密码,用密码解析握手消息,验证hash值是否和浏览器发来的一致
b,使用密钥加密消息,回送
如果计算法hash值一致,握手成功。
5,谈谈负载均衡的原理及算法?
在一些大的网站中,当系统面临大量用户访问,负载过高的时,通常会使用增加服务器数量来进行横向扩展,使用集群和负载均衡提高整个系统的处理能力。一般系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。
纵向扩展,是从单机的角度通过增加硬件处理能力,比如CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题。
因此需要采用横向扩展的方式,通过添加机器来满足大型网站服务的处理能力。比如应用集群,一台机器不能满足,则增加两台或者多台机器,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。

负载均衡算法:
常见6种算法: 轮询, 随机, 源地址哈希, 加权轮询, 加权随机, 最小连接数。
nginx的5种算法: 轮询, weight, ip_hash, fair(响应时间), url_hash。
dubbo的均衡算法: 随机, 轮询, 最少活跃调用数, 一致性Hash。
6,谈谈你用过的设计模式?
说出几个你熟悉的设计模式就行,这里我列举几个。
1)单例模式 一个类在Java虚拟机中只有一个对象,并提供一个全局访问点。生活中例子如:太阳、月亮等。
模式结构:分为饿汉式和懒汉式(如果考虑性能问题的话,就使用懒汉式,因为懒汉式是在方法里面进行初始化的),构造器私 有化,对外提供方法加同步关键字。
2)代理模式 为其他对象提供一个代理,以控制对当前对象的访问。生活中的例子如:房屋中介。
模式结构:代理类和被代理类实现同一个接口,用户访问的时候先访问代理对象,然后让代理对象去访问被代理对象。框架里面使用:Spring里面的AOP实现。JDK里面使用:java.lang.reflect.Proxy。
3)适配器模式 将两个原来不兼容的类兼容起来一起工作。生活中的例子:变压器、充电器。
模式结构:分为类适配器和对象适配,一般常用的就是对象适配器,因为组合由于继承。框架里面使用:单元测试里面的asserEquels。
7,说说实现高并发量网站的解决方案
对一些中大型网站,在面对大量用户访问、高并发请求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。这些解决思路在一定程度上意味着更大的投入。
1)HTML静态化
其实大家都知道,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能使我们的网站上的页面采用静态页面来实现,这个最简单的方法其实也是最有效的方法。
2)图片服务器分离
大家知道,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他们都有独立的、甚至很多台的图片服务器。这样的架构可以降低提供页面访问请求的服务器系统压力,并且可以保证系统不会因为图片问题而崩溃。
3)数据库集群、库表散列
大型网站在高并发访问的时候,数据库瓶颈很快就能显现出来,这时一台数据库将很快无法满足应用,于是我们需要使用数据库集群或者库表散列。
4)缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是非常重要。这里先讲述最基本的两种缓存。高级和分布式的缓存在后面讲述。
5)镜像
镜像是大型网站常采用的提高性能和数据安全性的方式,镜像的技术可以解决不同网络接入商和地域带来的用户访问速度差异,比如ChinaNet和EduNet之间的差异就促使了很多网站在教育网内搭建镜像站点,数据进行定时更新或者实时更新。
6)负载均衡
负载均衡也是大型网站解决高负荷访问和大量并发请求采用的解决办法。
7)CDN加速技术(最新)
CDN的即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。
8,Linux常用指令及服务安装、部署维护
Linux操作系统使用相关的面试问题,也是中高级面试者肯定要面对的,这个完全得靠平时使用情况了。最简单的操作命令必须得知道,比如:ps, mkdir, vi, find等。具体这里不多说,如果没运维经验,就去把最基本的指令记住吧。
如果你想了解和学习,可以关注此公众号,在公众号联系或私聊

Java面试题汇总---升级版(附答案)的更多相关文章
- 2020最常见的200+Java面试题汇总(含答案解析)
前言 2020年快要结束了,很多朋友问题,有没有整理今年的一些面试题,最近抽时间整理了一份Java面试题.或许这份面试题还不足以囊括所有 Java 问题,但有了它,我相信足以应对目前市面上绝大部分的 ...
- 2019 最新 阿里天猫、蚂蚁、钉钉ava 面试题汇总,附答案
Java面试前需要做足各方面的准备工作,肯定都会浏览大量的面试题,本人也不例外,这是一些最新面试题,分享给大家. Java基础 面向对象的特征:继承.封装和多态 int 和 Integer 有什么区别 ...
- 2019新版UI设计面试题汇总(附答案)
问题一.Android手机的常用设计尺寸有_________.怎么适配ios和安卓. 答案:安卓320 X 480是常规模拟器.但现在的开发都是用360x640做一倍率.480 X 800(1.5倍率 ...
- Java面试题总结(附答案)
1.什么是B/S架构?C/S架构? B/S(Browser/Server),浏览器/服务器程序: C/S(Client/Server),客户端/服务端,桌面应用程序. 2.网络协议有哪些? HTTP: ...
- Mybatis常考面试题汇总(附答案)
1.#{}和${}的区别是什么? #{}和${}的区别是什么? 在Mybatis中,有两种占位符 #{}解析传递进来的参数数据 ${}对传递进来的参数原样拼接在SQL中 #{}是预编译处理,${}是字 ...
- Java面试题汇总---整理版(附答案)
今天继续为大家整理Java面试题,并涉及数据库和网络等相关知识,希望能帮助到各位开发者. 1,为什么要用spring,Spring主要使用了什么模式? spring能够很好的和各大框架整合,它通过IO ...
- 纯干货分享!2020阿里java岗笔试面试题总结(附答案)
前言 2020金九银十马上结束,现为大家整理了这次金九银十面试阿里的面试题总结,都是我从朋友那拿到的面试真题,话不多说,满满的干货分享给大家! int a=10是原子操作吗? 是的. 注意点: i+ ...
- 29道Zookeeper面试题超详细(附答案)
原文链接 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件 ...
- 20 几个知名公司的 Java 面试题汇总
查看不同公司新鲜真实的Java面试题,摘自Glassdoor.com 巴克莱投资: 假设有一个 getNextparson() 方法返回 Person 对象,Person 类实现了 comparabl ...
随机推荐
- iOS开发HTTP协议相关知识总结
HTTP原理 什么是URL URL中常见的几种协议 什么是HTTP协议 HTTP是做什么的 为什么要使用HTTP协议 HTPP协议的通信过程介绍 HTTP请求 HTTP响应 HTTP请求的选择 两种发 ...
- .NET中的GC总结
来自<CLR via C# 3rd Edition>总结 只管理内存,非托管资源,如文件句柄,GDI资源,数据库连接等还需要用户去管理 循环引用,网状结构等的实现会变得简单.GC的标志也压 ...
- 水晶报表异常“CrystalDecisions.ReportSource.ReportSourceFactory”的类型初始值设定项引发异常,未能加载文件或程序集“log4net
System.TypeInitializationException: “CrystalDecisions.ReportSource.ReportSourceFactory”的类型初始值设定项引发异常 ...
- 零元学Expression Blend 4 Chapter 22 以实作案例学习Frame及HyperlinkButton
原文:零元学Expression Blend 4 Chapter 22 以实作案例学习Frame及HyperlinkButton 本章将教大家如何以实作善用Blend4的内建功能-「Frame」以及「 ...
- Android零基础入门第2节:Android 系统架构和应用组件那些事
原文:Android零基础入门第2节:Android 系统架构和应用组件那些事 继上一期浅谈了Android的前世今生,这一期一起来大致回顾一下Android 系统架构和应用组件. 一.Android ...
- 程序的开机关机重启,开机启动,休眠功能delphi实现(使用AdjustTokenPrivileges提升权限)
TShutDownStatus = (sdShutDown,sdReboot,sdLogOff,sdPowerOff); procedure ShutDown(sdStatus : TShutDown ...
- 中芯国际在CSTIC上悉数追赶国际先进水平的布局
作为中国最大.工艺最先进的晶圆厂,中芯国际的一举一动都会受到大家的关注.在由SEMI主办的2017’中国国际半导体技术大会(CSTIC 2017)上,中芯国际CEO邱慈云博士给我们带来了最新的介绍. ...
- 前端工程师应该都了解的16个最受欢迎的CSS框架
摘要: 今天给大家分享16个最受欢迎的CSS框架.这些是根据笔者的爱好以及相关查阅规整出来的.可能还有一些更棒的或者您更喜欢的没有列举出来.如果有,欢迎留言! Pure : CSS Framework ...
- 浅谈js闭包(closure)
相信很多从事js开发的朋友都或多或少了解一些有关js闭包(closure)的知识. 本篇文章是从小编个人角度,简单地介绍一下有关js闭包(closure)的相关知识.目的是帮助一些对js开发经验不是很 ...
- 函数式编程里的Materialization应该翻译成什么?
Materialization是函数式编程里的一个专业术语, 用于特指函数式编程中查询被实际执行并生成结果的这一过程. 首先, 搜了一下中文资料, 暂时没有对该词的中文翻译, CSDN\博客园\阿里 ...