python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言
hello,大家好
本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json
所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去爬取。
为了方便我们就用requests模块就够了,因为够快。。。
上章的课程传送门:
[python网络爬虫之入门[一]](https://www.cnblogs.com/liwangwang/p/11977110.html)
[python网络爬虫之自动化测试工具selenium\[二\]](https://www.cnblogs.com/liwangwang/p/11977134.html)
理一下本章思路:
- 学习并掌握好正则表达式
- 使用正则表达式去分析网站来获取特定信息
一、正则表达式的学习
1、正则表达式的匹配工具
如果是学过正则表达式的却不知道这个工具的话,那绝对是一个很大的遗憾。
这个也叫做猫头鹰,
可能还有一些比较好用的工具把,但这个就已经够用了,
下载路径:
链接:https://pan.baidu.com/s/1g8Zn-CKopsnCjA_o9jS0TQ
提取码:iq9s
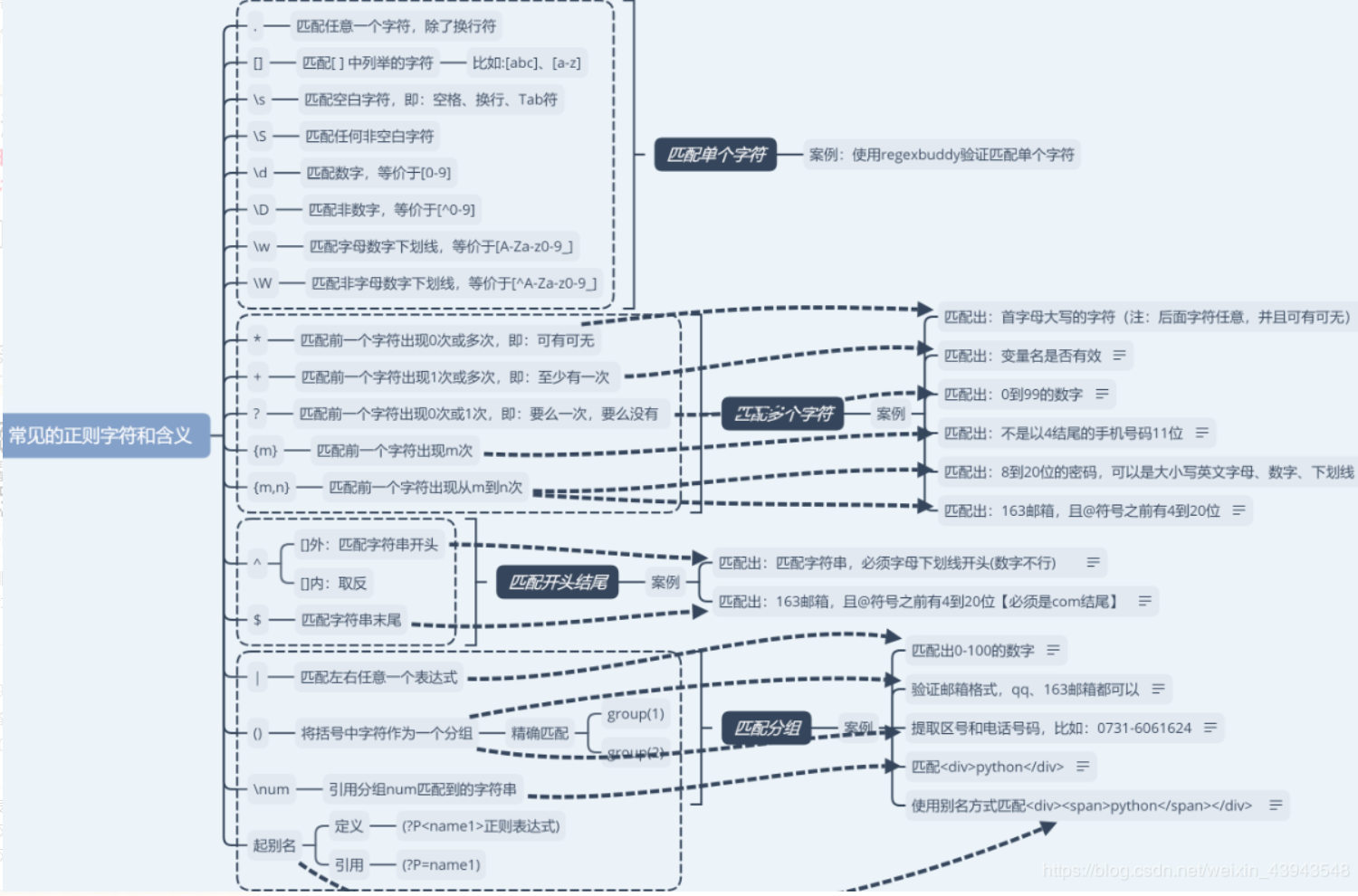
2、正则表达式的样式
本着大家好,我好的思想理念,所以我觉得给大家起一个匹配案例就行了,其他的正则自己可以慢慢看代码理解
放图:
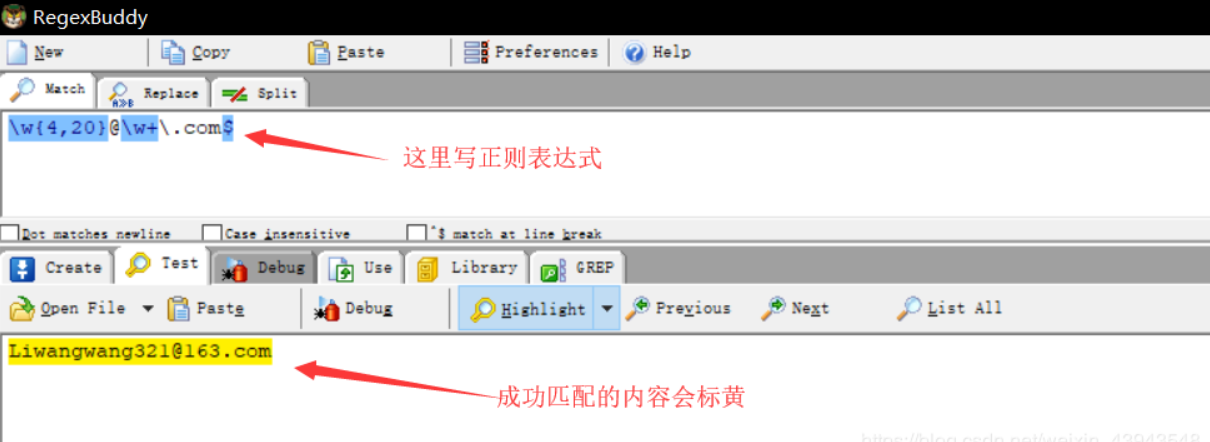
使用regexbuddy做检测:
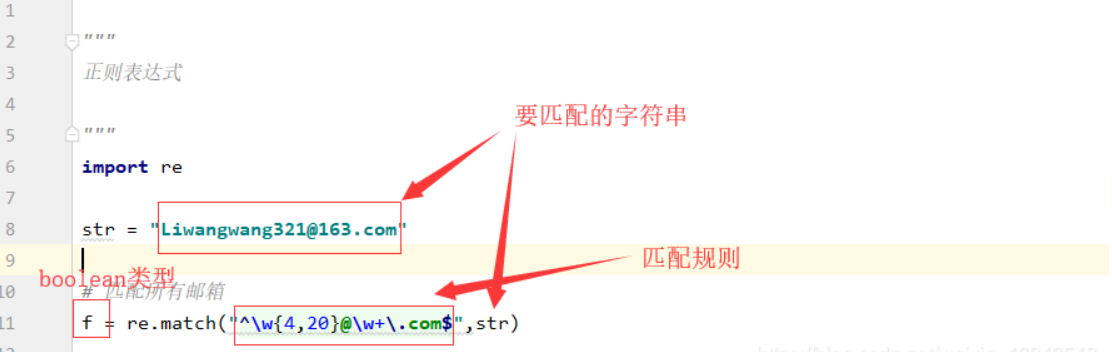
失败案例

在python中的一个测试
3、正则表达式的案例
"""
正则表达式 """
import re str = "Liwangwang321@163.com" # 匹配所有邮箱
# f = re.match("^\w{4,20}@\w+\.com$",str) # 匹配qq或163邮箱
# f = re.match("\w{4,20}@(qq|163)\.com",str) # 匹配<div><span>python</span></div> \num方法
# str = "<div><span>python</span></div>"
# f = re.match("<([A-Za-z]+)><([A-Za-z]+)>.*</\\2></\\1>",str) # 匹配<div><span>python</span></div> 起别名方法
str = "<div><span>python</span></div>"
f = re.match("<(?P<name1>[A-Za-z]+)><(?P<name2>[A-Za-z]+)>.*</(?P=name2)></(?P=name1)>",str) # 2、match和search的区别
# str = "你好,123,现在在线人数为9999"
# f = re.match("\\d*",str)
# f = re.search(",\\d*",str)
# f = re.findall("\\d*",str) # 3、贪婪与非贪婪 :加个?就行
# f = re.findall('src=".*"',str)
# f = re.findall('src=".*?"',str) # 4、免写转义\\ : 加个r
# f = re.match(r"<([A-Za-z]+)><([A-Za-z]+)>.*</\2></\1>",str) if f:
print("匹配成功")
print(f.group())
# for i in f:
# print(i)
else:
print("匹配失败")
二、爬取网页图片
1、分析网页
我们此次爬取的对象为http://pic.netbian.com/4kdongma
获取指定的图片查看:
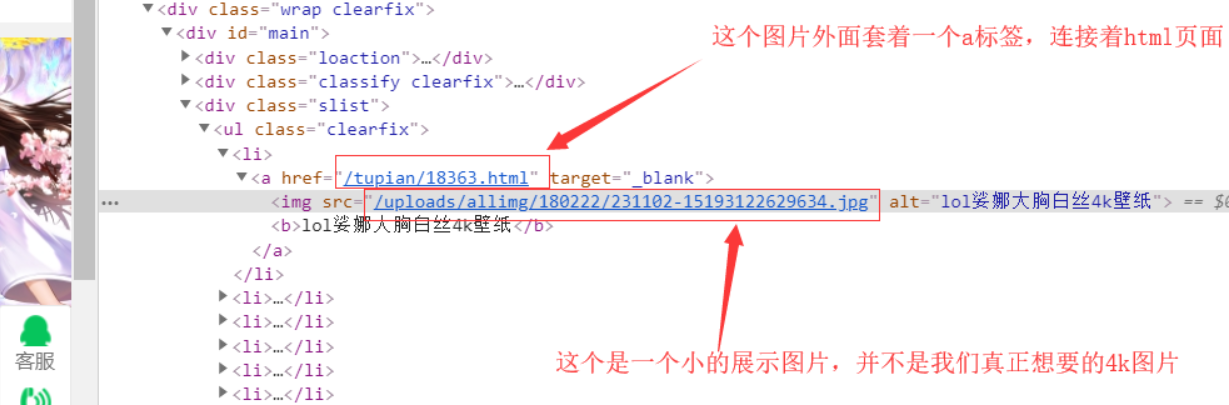
但是呢,一个展示图片根本不能符合我们的要求,
所以我们点击进去看看:

F12检索网页代码;
ok,我们查看一下这个图片路径http://pic.netbian.com/uploads/allimg/180222/231102-151931226201f1.jpg

接下来就是去分析一个网页的结构,确定好用什么正则表达式才能准确的拿到a标签的href,或者img标签的src
这个非常重要,重要,重要!!
比如
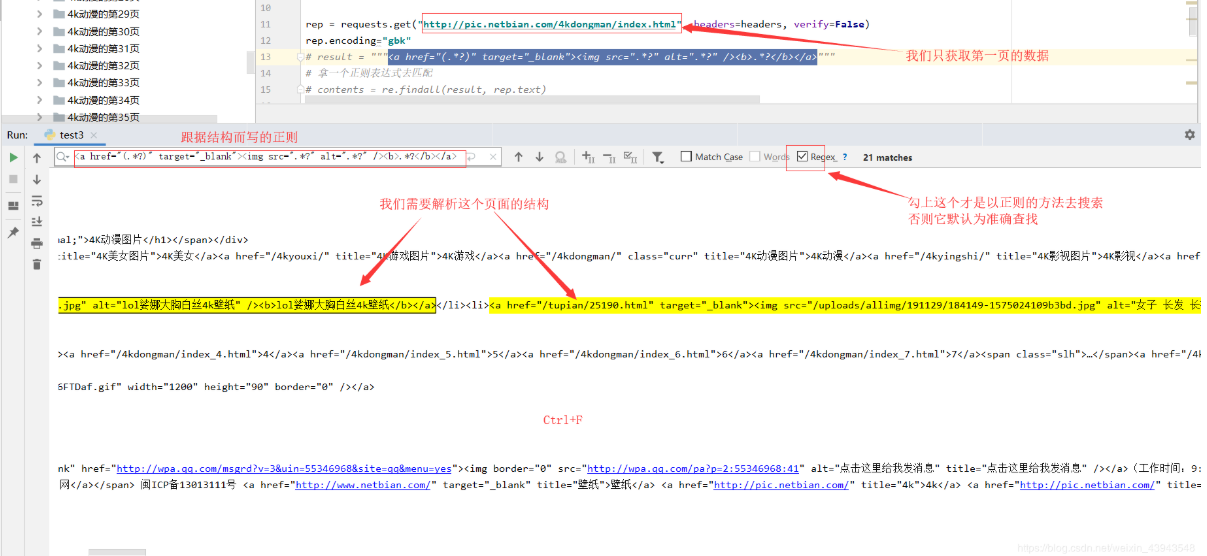
ok,一步一步的分析网页结构:
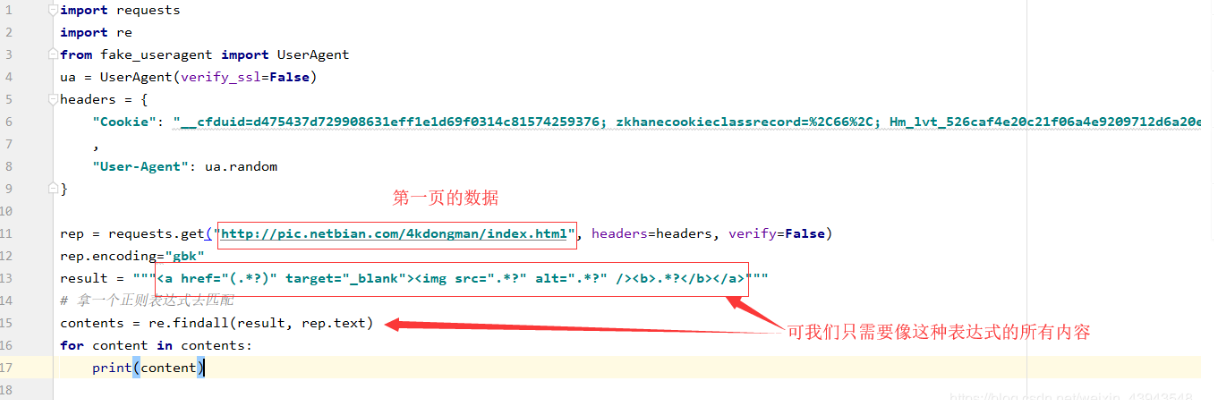
那么接下来的那个点击进去之后的html路经,我们照样可以通过这个方法访问,解析
下面自己测试
import requests
import re
from fake_useragent import UserAgent
ua = UserAgent(verify_ssl=False)
headers = {
"Cookie": "__cfduid=d475437d729908631eff1e1d69f0314c81574259376; zkhanecookieclassrecord=%2C66%2C; Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1574259380,1574691901,1574734052; security_session_verify=ebb4b36dc44da23d2cdd02fa4650ae15; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1574735387"
,
"User-Agent": ua.random
} rep = requests.get("http://pic.netbian.com/4kdongman/index.html", headers=headers, verify=False)
rep.encoding="gbk"
# result = """<a href="(.*?)" target="_blank"><img src=".*?" alt=".*?" /><b>.*?</b></a>"""
# 拿一个正则表达式去匹配
# contents = re.findall(result, rep.text) print(rep.text)
# for content in contents:
# print(content)
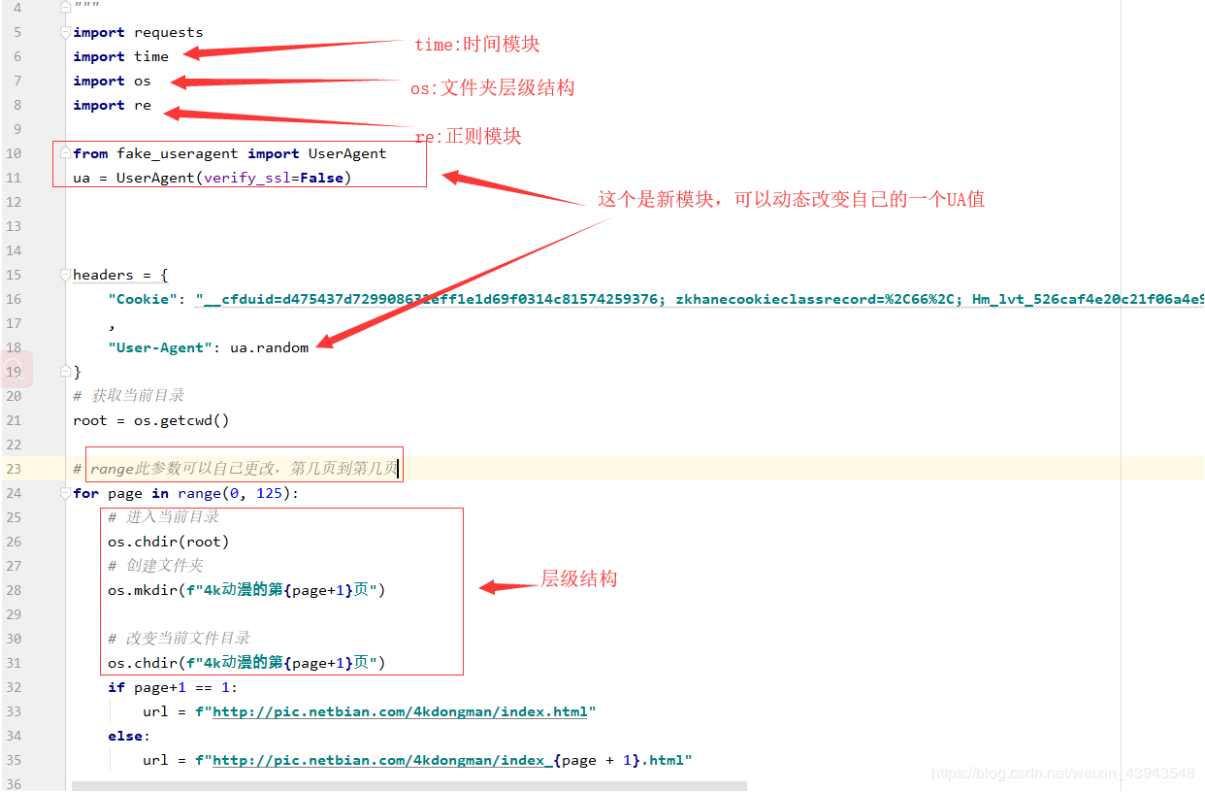
2、获取数据
我们先看一下图解:

全部代码
"""
爬取4k动漫图片 """
import requests
import time
import os
import re from fake_useragent import UserAgent
ua = UserAgent(verify_ssl=False) headers = {
"Cookie": "__cfduid=d475437d729908631eff1e1d69f0314c81574259376; zkhanecookieclassrecord=%2C66%2C; Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1574259380,1574691901,1574734052; security_session_verify=645e98edf446fb2efa862d275906b0ba; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1574782670"
,
"User-Agent": ua.random
}
# 获取当前目录
root = os.getcwd() # range此参数可以自己更改,第几页到第几页
for page in range(0, 125):
# 进入当前目录
os.chdir(root)
# 创建文件夹
os.mkdir(f"4k动漫的第{page+1}页") # 改变当前文件目录
os.chdir(f"4k动漫的第{page+1}页")
if page+1 == 1:
url = f"http://pic.netbian.com/4kdongman/index.html"
else:
url = f"http://pic.netbian.com/4kdongman/index_{page + 1}.html" response = requests.get(url,headers=headers,verify=False)
response.encoding="gbk" if response.status_code == 200 :
result= """<a href="(.*?)" target="_blank"><img src=".*?" alt=".*?" /><b>.*?</b></a>"""
# 拿一个正则表达式去匹配
contents = re.findall(result,response.text)
# 去遍历所有的图片
for content in contents:
path = content
print(f"{path}正在进入html......")
response2 = requests.get("http://pic.netbian.com"+path, headers=headers,verify=False)
response2.encoding = "gbk"
time.sleep(1)
result2 = """<a href="" id="img"><img src="(.*?)" data-pic=".*?" alt="(.*?)" title=".*?"></a>"""
contents2 = re.findall(result2, response2.text)
for content2 in contents2:
path2 = content2[0]
name = content2[1]
response3 = requests.get("http://pic.netbian.com"+path2, headers=headers,verify=False)
# 保存到本地
with open(f"{name}.jpg","wb") as f:
f.write(response3.content)
print(f"{name} : {path2} 保存成功,等待1秒后继续爬取")
time.sleep(1)
print(f"第{page + 1}页抓取成功,,等待2秒后继续爬取")
time.sleep(2)
爬取妹子网的案例
这个案例来自于:https://blog.csdn.net/qq_33958297/article/details/89388556
爬取的网站:https://www.mzitu.com/
# -*- coding: utf-8 -*- import requests
import os
from lxml import etree
from threading import *
from time import sleep nMaxThread = 3 #这里设置需要开启几条线程
ThreadLock = BoundedSemaphore(nMaxThread) gHeads = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
} class Meizitu(Thread):
def __init__(self,url,title):
Thread.__init__(self)
self.url = url #这里的url在后面的referer中需要使用
self.title = title def run(self):
try:
PhotoUrl,Page = self.GetPhotoUrlAndPageNum()
if PhotoUrl and Page > 0:
self.SavePhoto(PhotoUrl,Page)
finally:
ThreadLock.release() def GetPhotoUrlAndPageNum(self):
html = requests.get(self.url,headers=gHeads)
if html.status_code == 200:
xmlContent = etree.HTML(html.text)
PhotoUrl = xmlContent.xpath("//div[@class='main-image']/p/a/img/@src")[0][:-6] #01.jpg 正好是-6
PageNum = xmlContent.xpath("//div[@class='pagenavi']/a[5]/span/text()")[0]
return PhotoUrl,int(PageNum)
else:
return None,None def SavePhoto(self,url,page):
savePath = "./photo/%s" % self.title
if not os.path.exists(savePath):
os.makedirs(savePath)
for i in range(page):
heads = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer": "%s/%d" %(self.url,i+1),
"Accept": "image/webp,image/apng,image/*,*/*;q=0.8"
}
j = 0
while j<5:
print (u"Download : %s/%d.jpg" % (self.title, i + 1))
html = requests.get("%s%02d.jpg"%(url,i+1),headers=heads)
if html.status_code == 200:
with open(savePath + "/%d.jpg"%(i+1),"wb") as f:
f.write(html.content)
break
elif html.status_code == 404:
j+=1
sleep(0.05)
continue
else:
return None def main():
while True:
try:
nNum = int(raw_input(u"请输入要下载几页: "))
if nNum>0:
break
except ValueError:
print(u"请输入数字。")
continue
for i in range(nNum):
url = "https://www.mzitu.com/xinggan/page/%d/"%(i+1)
html = requests.get(url,headers=gHeads)
if html.status_code == 200:
xmlContent = etree.HTML(html.content)
hrefList = xmlContent.xpath("//ul[@id='pins']/li/a/@href")
titleList = xmlContent.xpath("//ul[@id='pins']/li/a/img/@alt")
for i in range(len(hrefList)):
ThreadLock.acquire()
t = Meizitu(hrefList[i],titleList[i])
t.start() if __name__ == '__main__':
main()
后记
如果有正则基础的可以直接看如何爬取,没有的可以学一学。
不过regexbuddy工具都可以玩玩看
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)
python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]的更多相关文章
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
目录 前言 XPath的使用方法 XPath爬取数据 后言 @(目录) 前言 本章同样是解析网页,不过使用的解析技术为XPath. 相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用 ...
- Python 网络爬虫 007 (编程) 通过网站地图爬取目标站点的所有网页
通过网站地图爬取目标站点的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 2016 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- 一篇文章带你用Python网络爬虫实现网易云音乐歌词抓取
前几天小编给大家分享了数据可视化分析,在文尾提及了网易云音乐歌词爬取,今天小编给大家分享网易云音乐歌词爬取方法. 本文的总体思路如下: 找到正确的URL,获取源码: 利用bs4解析源码,获取歌曲名和歌 ...
- ASP.NET网络爬虫小研究 HtmlAgilityPack基础,爬取数据保存在数据库中再显示再自己的网页中
1.什么是网络爬虫 关于爬虫百度百科这样定义的:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- Python网络爬虫数据解析的三种方式
request实现数据爬取的流程: 指定url 基于request发起请求 获取响应的数据 数据解析 持久化存储 1.正则解析: 常用的正则回顾:https://www.cnblogs.com/wqz ...
随机推荐
- SpringCloud之Zuul过滤器实现登录鉴权实战(十一)
自定义zuul过滤器实现登录鉴权实战 1.新建filter包 2.新建类继承ZuulFilter,重写方法 3.在类顶部加注解@Comment让spring扫描 /** * @author WGR * ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- 百度语音合成---前端vue项目
☞:官方文档 ☞:网页示例 具体步骤: 1.通过 socket.io 接收后端传过来的数据. 2.判断是否在播放声音. 如果没有则直接获取百度 token 播放声音 3.如果有,则存入数组.声音播放 ...
- js如何展示上传的图片
前言:本文章主要讲的是上传的图片如何展示在页面上. 一般来说,我们会先将本地图片上传到服务器,上传成功后,由后台返回图片的网络地址再在前端显示.但是,我今天讲的是不通过前面说的过程,而是直接使用js将 ...
- [2018-01-08] Python强化周的第一天
Python强化周的第一天 学生管理系统-制作(成绩类)模块 class Score: lesson_name = "python" # 课程名 score = 0 # 分数 # ...
- Zabbix_agent 三 被动模式的配置
zabbix一共有三种监控模式分别默认是被动模式,由agent端收集数据,server去请求然后获取agent的数据. 还有就是主动模式,由agent收集数据并定时发送到server端,则就是被动模式 ...
- [Luogu5384][Cnoi2019] 雪松果树
传送门 虽然这题是一道二合一,也不算难,但还是学到了很多东西啊,\(k\) 级儿子个数的五种求法!!我还是觉得四种比较好( \(k\) 级儿子个数有五种求法,你知道么? --鲁迅 首先 \(k\) 级 ...
- [考试反思]1015csp-s模拟测试74:压迫
其实同时也是第27,一大片并列的. 真的是越考越烂. T1是个弱化的贪心原题,15分钟拿下没什么可说的. T2打的记忆化搜索,hash_mod太小撞哈希了,50->30 T3,想不到正解,90分 ...
- 字体图标转base64
如果你在阿里矢量库下载了字体图标在项目引入无法显示时,可以把图标转成base64 在线转换的链接 https://transfonter.org/ css字体图标的制作
- 【idea】高德地图可以关爱一下高个汽车
现状:1.交通事故时不时能看到大卡车,双层巴士在城市里限高区域时的车祸 原因分析:1.司机对路况不熟,驶入新的限高路,造成事故2.司机对车况不熟,临时换的车驾驶,忘记车高的变化3.司机路况车况都熟,道 ...