并查集(不相交集合)详解与java实现
@
认识并查集
对于并查集(不相交集合),很多人会感到很陌生,没听过或者不是特别了解。实际上并查集是一种挺高效的数据结构。实现简单,只是所有元素统一遵从一个规律所以让办事情的效率高效起来。
对于定意义,百科上这么定义的:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
并查集解析
基本思想
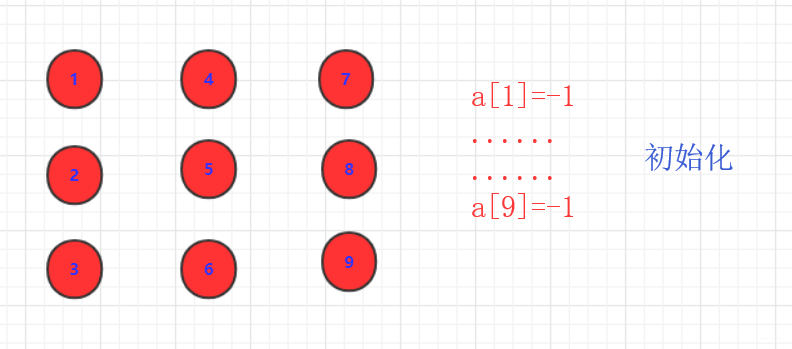
- 初始化,一个森林每个都为独立。通常用数组表示,每个值初始为-1。
各自为根
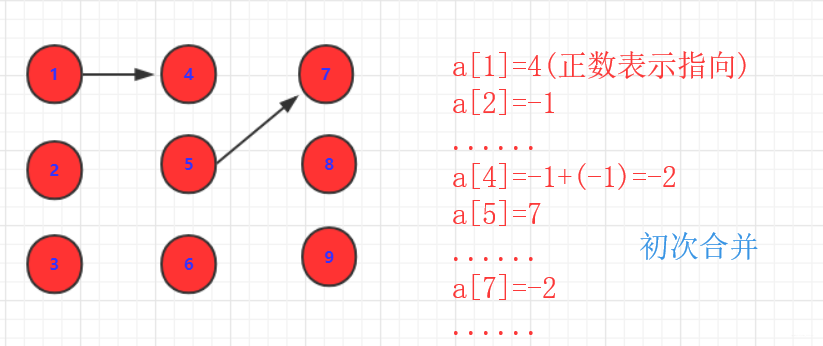
join(a,b)操作。a,b两个集合合并。注意这里的a,并不是a,b合并,而是a,b的集合合并。这就派生了一些情况:- a,b如果是独立的(没有和其他合并),那么直接a指向b(或者b指向a),即
data[a]=b;同时为了表示这个集合有多少个,原本-1的b再次-1.即data[b]=-2.表示以b为父亲的节点有|-2|个。
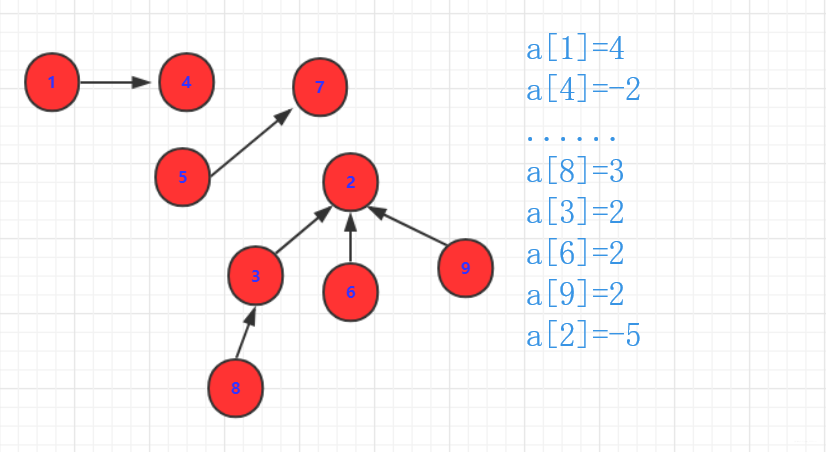
- a,b如果有集合(可能有父亲,可能自己是根),那么我们当然
不能直接操作a,b(因为a,b可能已经指向别人了.)那么我们只能操作a,b的祖先。因为a,b的祖先是没有指向的(即数据为负值表示大小)。那么他们首先一个负值要加到另外一个上面去。另外这个数值要变成指向的那个表示联系。
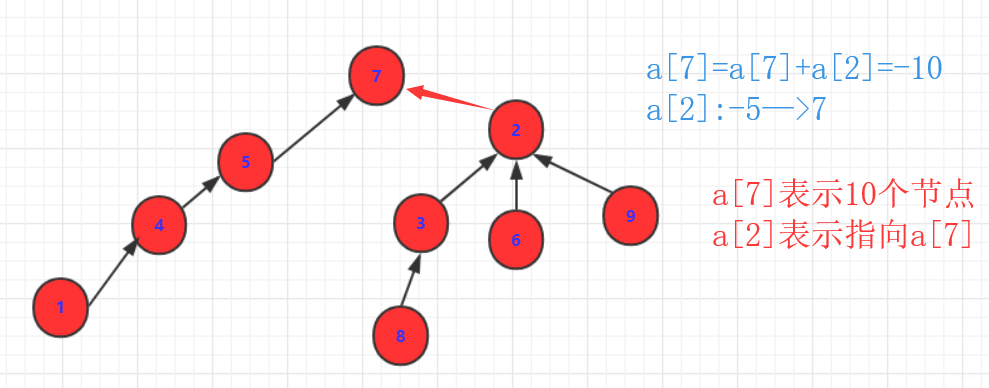
对于上述你可能会有疑问:
如何查看a,b是否在一个集合?
- 查看是否在一个集合,只需要查看
节点根祖先的结果是否相同即可。因为只有根的数值是负的,而其他都是正数表示指向的元素。所以只需要一直寻找直到不为正数进行比较即可!
a,b合并,究竟是a的祖先合并在b的祖先上,还是b的祖先合并在a上?
- 这里会遇到两种情况,这个选择也是非常重要的。你要弄明白一点:树的高度+1的化那么整个元素查询的效率都会降低!
所以我们通常是:小数指向大树(或者低树指向高树),这个使得查询效率能够增加!
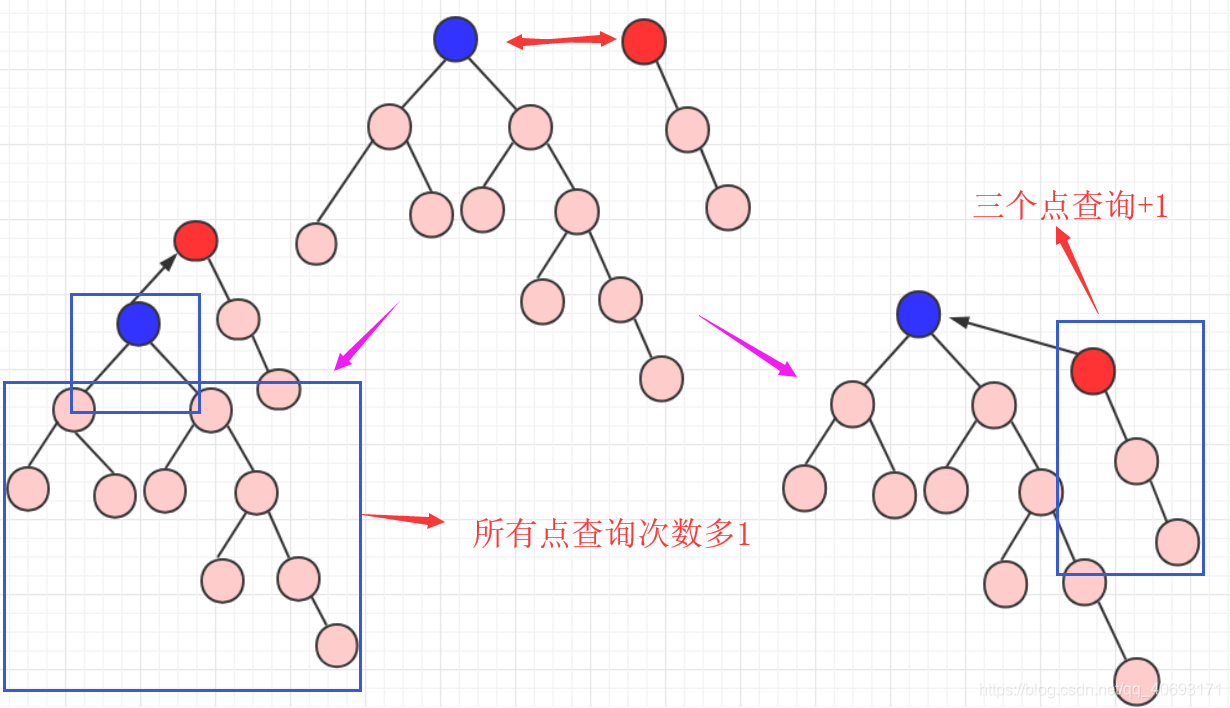
当然,在高度和数量的选择上,还需要你自己选择和考虑。
其他路径压缩?
每次查询,自下向上。当我们调用递归的时候,可以顺便压缩路径,因为我们查找一个元素其实只需要直到它的祖先,所以当他距离祖先近那么下次查询就很快。并且压缩路径的代价并不大!
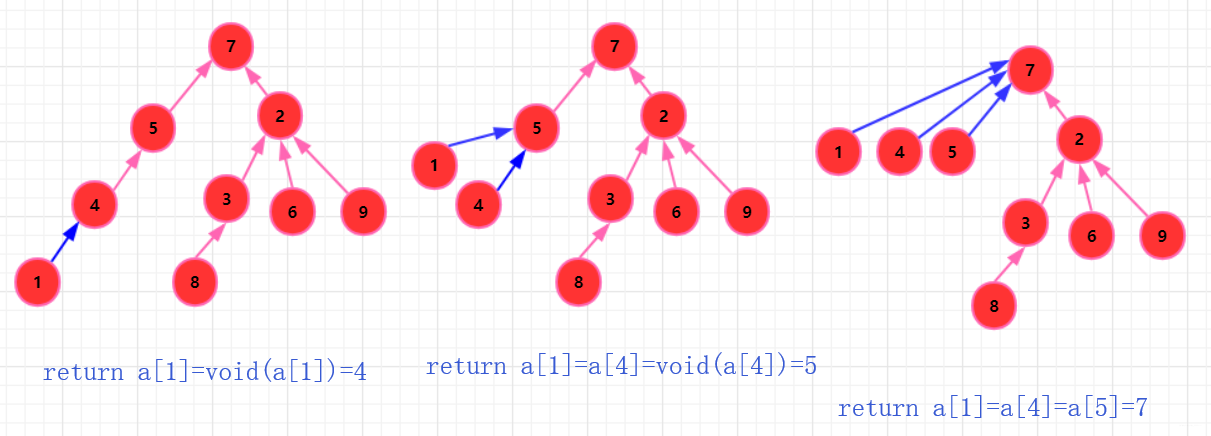
代码实现
并查集实现起来较为简单,直接贴代码!
package 并查集不想交集合;
import java.util.Scanner;
public class DisjointSet {
static int tree[]=new int[100000];//假设有500个值
public DisjointSet() {set(this.tree);}
public DisjointSet(int tree[])
{
this.tree=tree;
set(this.tree);
}
public void set(int a[])//初始化所有都是-1 有两个好处,这样他们指向-1说明是自己,第二,-1代表当前森林有-(-1)个
{
int l=a.length;
for(int i=0;i<l;i++)
{
a[i]=-1;
}
}
public int search(int a)//返回头节点的数值
{
if(tree[a]>0)//说明是子节点
{
return tree[a]=search(tree[a]);//路径压缩
}
else
return a;
}
public int value(int a)//返回a所在树的大小(个数)
{
if(tree[a]>0)
{
return value(tree[a]);
}
else
return -tree[a];
}
public void union(int a,int b)//表示 a,b所在的树合并
{
int a1=search(a);//a根
int b1=search(b);//b根
if(a1==b1) {System.out.println(a+"和"+b+"已经在一棵树上");}
else {
if(tree[a1]<tree[b1])//这个是负数,为了简单减少计算,不在调用value函数
{
tree[a1]+=tree[b1];//个数相加 注意是负数相加
tree[b1]=a1; //b树成为a的子树,直接指向a;
}
else
{
tree[b1]+=tree[a1];//个数相加 注意是负数相加
tree[a1]=b1; //b树成为a的子树,直接指向a;
}
}
}
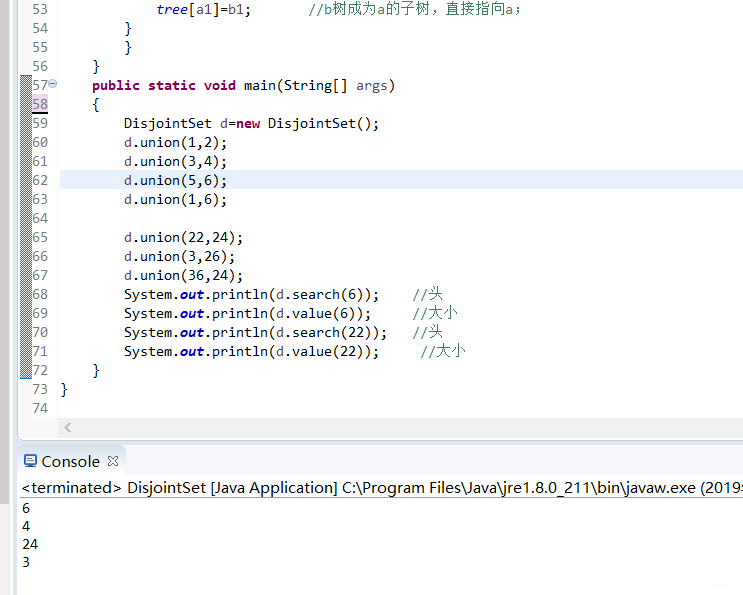
public static void main(String[] args)
{
DisjointSet d=new DisjointSet();
d.union(1,2);
d.union(3,4);
d.union(5,6);
d.union(1,6);
d.union(22,24);
d.union(3,26);
d.union(36,24);
System.out.println(d.search(6)); //头
System.out.println(d.value(6)); //大小
System.out.println(d.search(22)); //头
System.out.println(d.value(22)); //大小
}
}
结语
- 并查集属于简单但是很高效率的数据结构。在集合中经常会遇到。如果不采用并查集而传统暴力效率太低,而不被采纳。
- 另外,
并查集还广泛用于迷宫游戏中,下面有机会可以介绍用并查集实现一个走迷宫小游戏。大家欢迎关注! - 最后,欢迎大家关注笔者公众号,一起学习、交流!
笔者学习资源也放置公众号和大家一起分享!

并查集(不相交集合)详解与java实现的更多相关文章
- poj1417 true liars(并查集 + DP)详解
这个题做了两天了.首先用并查集分类是明白的, 不过判断是否情况唯一刚开始用的是搜索.总是超时. 后来看别人的结题报告, 才恍然大悟判断唯一得用DP. 题目大意: 一共有p1+p2个人,分成两组,一组p ...
- Java集合详解1:一文读懂ArrayList,Vector与Stack使用方法和实现原理
本文非常详尽地介绍了Java中的三个集合类 ArrayList,Vector与Stack <Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Java集合详解6:TreeMap和红黑树
Java集合详解6:TreeMap和红黑树 初识TreeMap 之前的文章讲解了两种Map,分别是HashMap与LinkedHashMap,它们保证了以O(1)的时间复杂度进行增.删.改.查,从存储 ...
- Java集合详解8:Java集合类细节精讲,细节决定成败
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解7:一文搞清楚HashSet,TreeSet与LinkedHashSet的异同
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解6:这次,从头到尾带你解读Java中的红黑树
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解4:一文读懂HashMap和HashTable的区别以及常见面试题
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解3:一文读懂Iterator,fail-fast机制与比较器
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
随机推荐
- Unity AR Foundation 和 CoreML: 实现手部的检测和追踪
0x00 前言 Unity的AR Foundation通过上层抽象,对ARKit和ARCore这些底层接口进行了封装,从而实现了AR项目的跨平台开发能力. 而苹果的CoreML是一个可以用来将机器学习 ...
- C# backgroundwork的使用方法
引言:在 WinForms 中,有时要执行耗时的操作,在该操作未完成之前操作用户界面,会导致用户界面停止响应.解决的方法就是新开一个线程,把耗时的操作放到线程中执行,这样就可以在用户界面上进行其它操作 ...
- kaptcha谷歌验证码工具
Kaptcha 简介 Kaptcha 是一个可高度配置的实用验证码生成工具,可自由配置的选项如: 验证码的字体 验证码字体的大小 验证码字体的字体颜色 验证码内容的范围(数字,字母,中文汉字!) 验证 ...
- sqlmap续
sqlmap续 注入语句(知道绝对路径时候可用) http://192.168.99.171/test2/sqli/example10.php?catid=3’union select 1,’< ...
- HTTP_1_Web及网络基础
Web使用一种HTTP(HyperText TransFer Protocol,超文本协议)的协议作为规范,完成从客户端到服务器等一系列运作流程.可见web是建立在HTTP协议上通信的. 通常我们使用 ...
- 【Mac】nsurlsessiond 后台下载问题的解决方法
最近在使用 Mac 系统的时候,经常发现 nsurlsessiond 这个进程,一直在后台下载,非常占用网速.解决方案如下: 通过终端执行下面的语句可以停止后台的自动更新: #!/bin/sh lau ...
- java类加载器-Bootstrap、 ExtClassLoader、 AppClassLoader的关系
1. 简单介绍 Bootstrap. ExtClassLoader. AppClassLoader是java最根正苗红的类加载器. Bootstrap是本地代码编写的(例如C), ExtClassL ...
- 【杂项】关于NOIP2018复赛若干巧合的声明
导言 参加NOIP2018时本人学龄只有两个月,却斩获了省一等奖,保送了重点中学,这看上去是个我创造的神话,然而,在我自己心中,我认为这只是个巧合(其实我认为运气也是实力的一部分),接下来,我将说明一 ...
- 安装yarn实况
[**前情提要**]最近在gayhub上面得到一个开源项目,遂准备研究一下源码,当然第一步就是要把项目运行起来.然后看了一下技术栈,发现包管理工具是使用yarn,以前也听说过yarn但是也没有具体使用 ...
- Maven多模块项目打包前的一些注意事项(打包失败)
一. 最近在打包Maven项目时遇到了点问题,这个项目是Maven多模块项目,结构如下: projectParent├── xxxx-basic├── xxxx-web1├── xxxx-collec ...