(转)理解滑动平均(exponential moving average)
转自:理解滑动平均(exponential moving average)
1. 用滑动平均估计局部均值
滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
变量vv在tt时刻记为 vtvt,θtθt 为变量 vv 在 tt 时刻的取值,即在不使用滑动平均模型时 vt=θtvt=θt,在使用滑动平均模型后,vtvt 的更新公式如下:
上式中,β∈[0,1)β∈[0,1)。β=0β=0 相当于没有使用滑动平均。
假设起始 v0=0v0=0,β=0.9β=0.9,之后每个时刻,依次对变量 vv 进行赋值,不使用滑动平均和使用滑动平均结果如下:
表 1 三种变量更新方式
| t | 不使用滑动平均模型,即给vv直接赋值θθ |
使用滑动平均模型, |
使用滑动平均模型, |
|---|---|---|---|
| 0, 1, 2, ... , 35 | [0, 10, 20, 10, 0, 10, 20, 30, 5, 0, 10, 20, 10, 0, 10, 20, 30, 5, 0, 10, 20, 10, 0, 10, 20, 30, 5, 0, 10, 20, 10, 0, 10, 20, 30, 5] | [0, 1.0, 2.9, 3.61, 3.249, 3.9241, 5.5317, 7.9785, 7.6807, 6.9126, 7.2213, 8.4992, 8.6493, 7.7844, 8.0059, 9.2053, 11.2848, 10.6563, 9.5907, 9.6316, 10.6685, 10.6016, 9.5414, 9.5873, 10.6286, 12.5657, 11.8091, 10.6282, 10.5654, 11.5089, 11.358, 10.2222, 10.2, 11.18, 13.062, 12.2558] | [0, 10.0, 15.2632, 13.321, 9.4475, 9.5824, 11.8057, 15.2932, 13.4859, 11.2844, 11.0872, 12.3861, 12.0536, 10.4374, 10.3807, 11.592, 13.8515, 12.7892, 11.2844, 11.1359, 12.145, 11.9041, 10.5837, 10.5197, 11.5499, 13.5376, 12.6248, 11.2844, 11.1489, 12.0777, 11.8608, 10.6276, 10.5627, 11.5365, 13.4357, 12.5704] |
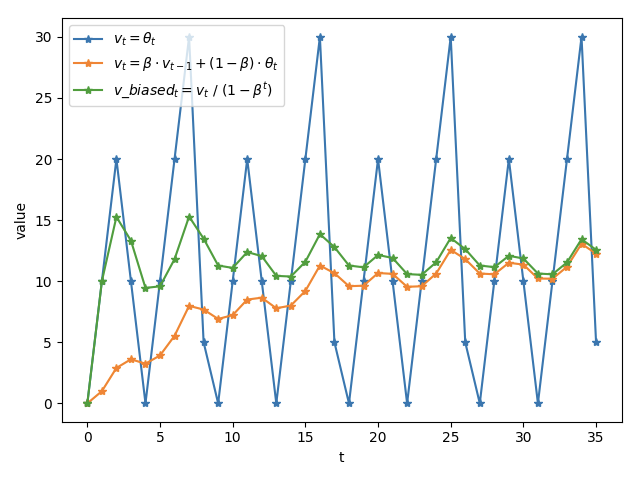 图 1:三种变量更新方式
图 1:三种变量更新方式
Andrew Ng在Course 2 Improving Deep Neural Networks中讲到,tt 时刻变量 vv 的滑动平均值大致等于过去 1/(1−β)1/(1−β) 个时刻 θθ 值的平均。这个结论在滑动平均起始时相差比较大,所以有了Bias correction,将 vtvt 除以 (1−βt)(1−βt) 修正对均值的估计。
加入了Bias correction后,vtvt 和 v_biasedtv_biasedt 的更新公式如下:
tt 越大,1−βt1−βt 越接近 1,则公式(1)和(2)得到的结果 (vtvt 和 v_biasedtv_biasedt)将越来越近,如图 1 所示。
当 ββ 越大时,滑动平均得到的值越和 θθ 的历史值相关。如果 β=0.9β=0.9,则大致等于过去 10 个 θθ 值的平均;如果 β=0.99β=0.99,则大致等于过去 100 个 θθ 值的平均。
滑动平均的好处:
占内存少,不需要保存过去10个或者100个历史 θθ 值,就能够估计其均值。(当然,滑动平均不如将历史值全保存下来计算均值准确,但后者占用更多内存和计算成本更高)
2. TensorFlow中使用滑动平均来更新变量(参数)
滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大,如图 1所示。
TensorFlow 提供了 tf.train.ExponentialMovingAverage 来实现滑动平均。在初始化 ExponentialMovingAverage 时,需要提供一个衰减率(decay),即公式(1)(2)中的 ββ。这个衰减率将用于控制模型的更新速度。ExponentialMovingAverage 对每一个变量(variable)会维护一个影子变量(shadow_variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为:
公式(3)中的 shadow_variable 就是公式(1)中的 vtvt,公式(3)中的 variable 就是公式(1)中的 θtθt,公式(3)中的 decay 就是公式(1)中的 ββ。
公式(3)中,decay 决定了影子变量的更新速度,decay 越大影子变量越趋于稳定。在实际运用中,decay一般会设成非常接近 1 的数(比如0.999或0.9999)。为了使得影子变量在训练前期可以更新更快,ExponentialMovingAverage 还提供了 num_updates 参数动态设置 decay 的大小。如果在初始化 ExponentialMovingAverage 时提供了 num_updates 参数,那么每次使用的衰减率将是:
这一点其实和 Bias correction 很像。
TensorFlow 中使用 ExponentialMovingAverage 的例子:code (如果 GitHub 无法加载 .ipynb 文件,则将 .ipynb 文件的 URL 复制到网站 https://nbviewer.jupyter.org/)
3. 滑动平均为什么在测试过程中被使用?
滑动平均可以使模型在测试数据上更健壮(robust)。“采用随机梯度下降算法训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。”
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;对于梯度下降 batch gradient decent,我感觉影子变量作用不大,因为梯度下降的方向已经是最优的了,loss 一定减小;对于 mini-batch gradient decent,可以尝试滑动平均,毕竟 mini-batch gradient decent 对参数的更新也存在抖动。
设 decay=0.999decay=0.999,一个更直观的理解,在最后的 1000 次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的 1000 次抖动进行了平均,这样得到的权重会更加 robust。
References
Course 2 Improving Deep Neural Networks by Andrew Ng
《TensorFlow实战Google深度学习框架》 4.4.3
(转)理解滑动平均(exponential moving average)的更多相关文章
- 理解滑动平均(exponential moving average)
1. 用滑动平均估计局部均值 滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving average),可以 ...
- EMA计算的C#实现(c# Exponential Moving Average (EMA) indicator )
原来国外有个源码(TechnicalAnalysisEngine src 1.25)内部对EMA的计算是: var copyInputValues = input.ToList(); for (int ...
- (转)滑动平均法、滑动平均模型算法(Moving average,MA)
原文链接:https://blog.csdn.net/qq_39521554/article/details/79028012 什么是移动平均法? 移动平均法是用一组最近的实际数据值来预测未来一期或几 ...
- 一文详解滑动平均法、滑动平均模型法(Moving average,MA)
任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主在线答疑~此外,公众号内还有更多AI.算法.编程和大数据知识分享,以及免费的SSR节点和 ...
- [leetcode]346. Moving Average from Data Stream滑动窗口平均值
Given a stream of integers and a window size, calculate the moving average of all integers in the sl ...
- Tensorflow滑动平均模型tf.train.ExponentialMovingAverage解析
觉得有用的话,欢迎一起讨论相互学习~Follow Me 移动平均法相关知识 移动平均法又称滑动平均法.滑动平均模型法(Moving average,MA) 什么是移动平均法 移动平均法是用一组最近的实 ...
- 『TensorFlow』滑动平均
滑动平均会为目标变量维护一个影子变量,影子变量不影响原变量的更新维护,但是在测试或者实际预测过程中(非训练时),使用影子变量代替原变量. 1.滑动平均求解对象初始化 ema = tf.train.Ex ...
- tensorflow入门笔记(二) 滑动平均模型
tensorflow提供的tf.train.ExponentialMovingAverage 类利用指数衰减维持变量的滑动平均. 当训练模型的时候,保持训练参数的滑动平均是非常有益的.评估时使用取平均 ...
- deep_learning_Function_tf.train.ExponentialMovingAverage()滑动平均
近来看batch normalization的代码时,遇到tf.train.ExponentialMovingAverage()函数,特此记录. tf.train.ExponentialMovingA ...
随机推荐
- C#使用 OleDbConnection 连接读取Excel
/// <summary> /// 读取Excel中数据 /// </summary> /// <param name="strExcelPath"& ...
- 约数之和(POJ1845 Sumdiv)
最近应老延的要求再刷<算法进阶指南>(不得不说这本书不错)...这道题花费了较长时间~(当然也因为我太弱了)所以就写个比较易懂的题解啦~ 原题链接:POJ1845 翻译版题目(其实是AcW ...
- C#线程学习笔记五:线程同步--事件构造
本笔记摘抄自:https://www.cnblogs.com/zhili/archive/2012/07/23/Event_Constructor.html,记录一下学习过程以备后续查用. 前面讲的线 ...
- 如何正确使用 Spring Cloud?【中】
3. Spring 集成了哪些常用组件? 从 2004 年发布 1.0 版本开始,Spring 目前已经演进至 5.x 版本了,为不同时期的应用开发提供了强有力的支撑.现在我们正面对微服务.DevOp ...
- Android 菜单 使用XML
@Override public boolean onCreateOptionsMenu(Menu menu) { // Inflate the menu; this adds items to th ...
- Csharp:HttpWebRequest or HttpClient
/// <summary> /// Define other methods and classes here /// </summary> /// <param nam ...
- Sql Server数据库常用Transact-SQL脚本
数据库 1.创建数据库 USE master ; GO CREATE DATABASE Sales ON ( NAME = Sales_dat, FILENAME = 'C:\Program File ...
- 全文检索--Lucene & ElasticSearch
全文检索--Lucene 2.1 全文检索和以前高级查询的比较 1.高级查询 缺点:1.like让数据库索引失效 2.每次查询都是查询数据库 ,如果访问的人比较多,压力也是比较大 2.全文检索框架:A ...
- IoT缺德相关
https://github.com/nebgnahz/awesome-iot-hacks <揭秘家用路由器0day漏洞挖掘技术> Embedded Device Security: Pw ...
- 【原创】你的Redis怎么持久化的
引言 (本文改编自生活真实案例,如有类同,绝不是巧合!) 端午节,烟哥正在一边愉快的学习.... 突然,微信一阵抖动.原来是老刘呼唤烟哥!善良的烟哥本以为人家是要约我出去玩!然而,打开微信一看,出现下 ...