100天搞定机器学习|Day33-34 随机森林
前情回顾
100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
100天搞定机器学习|Day21 Beautiful Soup
100天搞定机器学习|Day23-25 决策树及Python实现
前言: 随机森林是一个非常灵活的机器学习方法,从市场营销到医疗保险有着众多的应用。它可以用于市场营销对客户获取和存留建模或预测病人的疾病风险和易感性。
随机森林能够用于分类和回归问题,可以处理大量特征,并能够帮助估计用于建模数据变量的重要性。
1 什么是随机森林
随机森林可以用于几乎任何一种预测问题(包括非线性问题)。它是一个相对较新的机器学习策略(90年代诞生于贝尔实验室)可以用在任何方面。它属于机器学习中的集成学习这一大类。
1.1 集成学习
集成学习是将多个模型进行组合来解决单一的预测问题。它的原理是生成多个分类器模型,各自独立地学习并作出预测。这些预测最后结合起来得到预测结果,因此和单独分类器的结果相比,结果一样或更好。
随机森林是集成学习的一个分支,因为它依靠于决策树的集成。
1.2 随机决策树
我们知道随机森林是将其他的模型进行聚合, 但具体是哪种模型呢?从其名称也可以看出,随机森林聚合的是分类(或回归) 树。一颗决策树是由一系列的决策组合而成的,可用于数据集的观测值进行分类 。
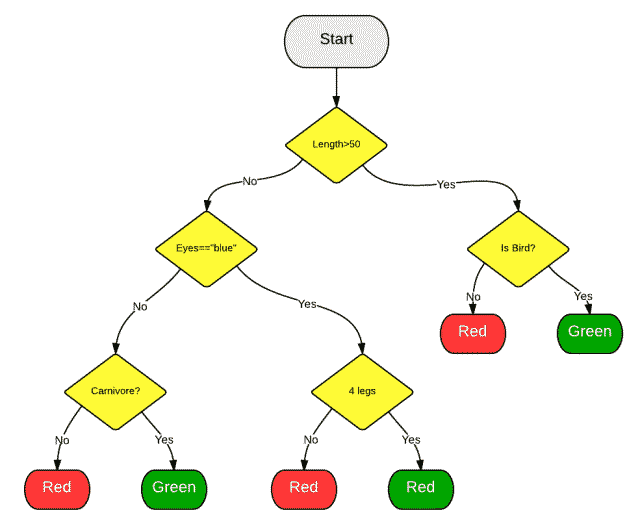
1.3 随机森林
引入的随机森林算法将自动创建随机决策树群。由于这些树是随机生成的,大部分的树(甚至 99.9%)对解决你的分类或回归问题是没有有意义。
1.4 投票
那么,生成甚至上万的糟糕的模型有什么好处呢?好吧,这确实没有。但有用的是,少数非常好的决策树也随之一起生成了。
当你要做预测的时候,新的观察值随着决策树自上而下走下来并被赋予一个预测值或标签。一旦森林中的每棵树都给有了预测值或标签,所有的预测结果将被归总到一起,所有树的投票返回做为最终的预测结果。
简单来说,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会脱颖而出,从而得到一个好的预测结果。

2 为什么要用它
随机森林是机器学习方法中的Leatherman(多功能折叠刀)。你几乎可以把任何东西扔给它。它在估计推断映射方面做的特别好,从而不需要类似SVM医一样过多的调参(这点对时间紧迫的朋友非常好)。
2.1 一个映射的例子
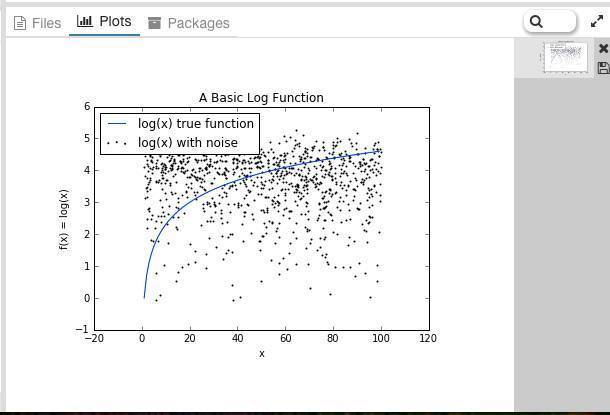
随机森林可以在未经特意手工进行数据变换的情况下学习。以函数f(x)=log(x)为例。
我们将在Yhat自己的交互环境Rodeo中利用Python生成分析数据,你可以在here下载Rodeo的Mac,Windows和Linux的安装文件。
首先,我们先生成一下数据并添加噪声。

得到如下结果:
如果我们建立了一个基本的线性模型通过使用x来预测y,我们需要作一条直线,一定成都市算是平分log(x)函数。而如果我们使用随机森林算法,它可以更好的逼近log(x)曲线从而使得它看起来更像实际的函数。
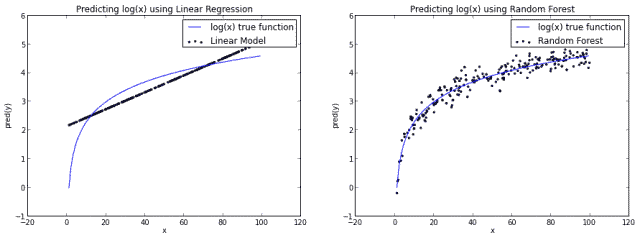
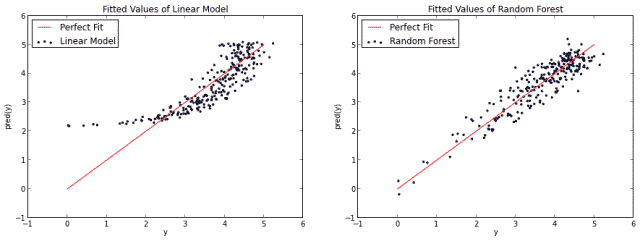
当然,你也可以说随机森林对log(x)函数有点过拟合。不管怎么样,这说明了随机森林并不限于线性问题。
3 使用方法
3.1 特征选择
随机森林的一个最好用例是特征选择。尝试很多个决策树变量的一个副产品就是,你可以检查变量在每棵树中表现的是最佳还是最糟糕。
当一些树使用一个变量,而其他的不使用这个变量,你就可以对比信息的丢失或增加。实现的比较好的随机森林工具能够为你做这些事情,所以你需要做的仅仅是去查看那个方法或参数。
在下述的例子中,我们尝试弄明白区分红酒或白酒时,哪些变量是最重要的。
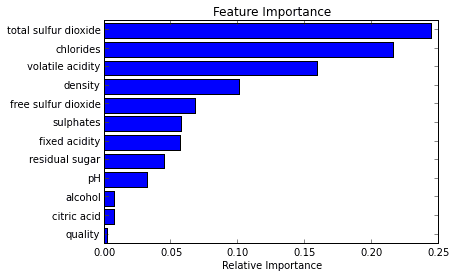
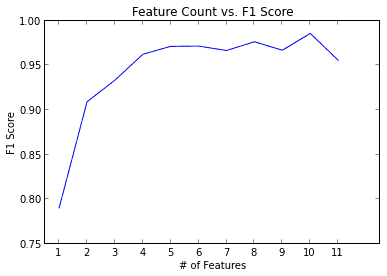
3.2 分类
随机森林也很善长分类问题。它可以被用于为多个可能目标类别做预测,它也可以在调整后输出概率。你需要注意的一件事情是过拟合。
随机森林容易产生过拟合,特别是在数据集相对小的时候。当你的模型对于测试集合做出“太好”的预测的时候就应该怀疑一下了。避免过拟合的一个方法是在模型中只使用有相关性的特征,比如使用之前提到的特征选择。
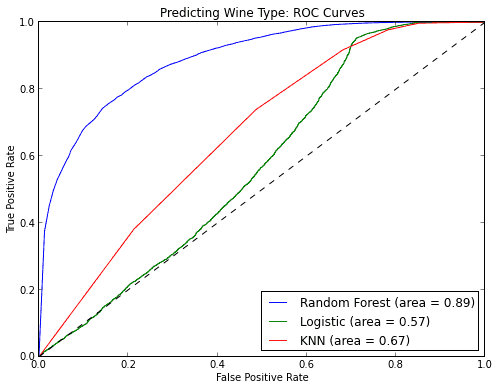
3.3 回归
随机森林也可以用于回归问题。
我发现,不像其他的方法,随机森林非常擅长于分类变量或分类变量与连续变量混合的情况。
4 一个简单的Python示例
#导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#导入数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
#将数据集拆分成训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
#特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
#调试训练集的随机森林
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
#预测测试集结果
y_pred = classifier.predict(X_test)
#生成混淆矩阵,也称作误差矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
#将训练集结果可视化
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
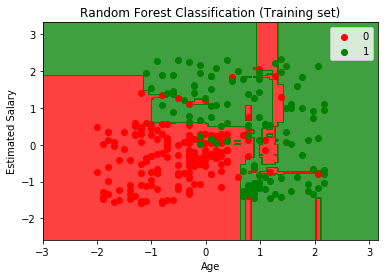
plt.title('Random Forest Classification (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
#将测试集结果可视化
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Random Forest Classification (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
100天搞定机器学习|Day33-34 随机森林的更多相关文章
- 100天搞定机器学习|Day56 随机森林工作原理及调参实战(信用卡欺诈预测)
本文是对100天搞定机器学习|Day33-34 随机森林的补充 前文对随机森林的概念.工作原理.使用方法做了简单介绍,并提供了分类和回归的实例. 本期我们重点讲一下: 1.集成学习.Bagging和随 ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day35 深度学习之神经网络的结构
100天搞定机器学习|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习 ...
- 100天搞定机器学习|day37 无公式理解反向传播算法之精髓
100天搞定机器学习(Day1-34) 100天搞定机器学习|Day35 深度学习之神经网络的结构 100天搞定机器学习|Day36 深度学习之梯度下降算法 本篇为100天搞定机器学习之第37天,亦 ...
- 100天搞定机器学习|day40-42 Tensorflow Keras识别猫狗
100天搞定机器学习|1-38天 100天搞定机器学习|day39 Tensorflow Keras手写数字识别 前文我们用keras的Sequential 模型实现mnist手写数字识别,准确率0. ...
- 100天搞定机器学习:PyYAML基础教程
编程中免不了要写配置文件,今天我们继续Python网络编程,学习一个比 JSON 更简洁和强大的语言----YAML .本文老胡简单介绍 YAML 的语法和用法,以及 YAML 在机器学习项目中的应用 ...
- 100天搞定机器学习|Day7 K-NN
最近事情无比之多,换了工作.组队参加了一个比赛.和朋友搞了一些小项目,公号荒废许久.坚持是多么重要,又是多么艰难,目前事情都告一段落,我们继续100天搞定机器学习系列.想要继续做这个是因为,一方面在具 ...
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
随机推荐
- C# Linq 常用查询操作符
限定操作: 1. All:用来确定是否序列中的所有元素都满足条件 2. Any:用来确定序列是否包含任何元素,有参方式用来确定序列中是否有元素满足条件 3. Contains:方法用来确定序列是否包含 ...
- CDQZ 集训大总结
好爆炸的一次集训…… 成绩: 什么鬼, 烂到一定地步了. 在这里每天考试80%都是暴力,正解思维难度的确比之前大了很多,考的范围也扩大了,比起之前的单独考一个知识点,转变为了多知识点多思维的综合,见了 ...
- python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系. 注:未使用接口,仅爬虫学习,不做任何违法操作. """ 新浪财经,爬取历史股票数据 ""&q ...
- Windows10 OpenSSH 快捷设置 避免 Bad owener or permission on
配置ssh 有两个地方 ~/.ssh/config 这个亲测失败,怎么搞都报错 bad owner .... c:/programdata/ssh/ssh_config 亲测有效 (显示隐藏文件才看的 ...
- HiLoGenerator生成id
using System.Linq; namespace Product.Host { public class HiLoGenerator { ; ; ; private object Sequen ...
- VS2010中GetMenu()和GetSubMenu(0)为NULL引发异常的解决方法 及添加方法
对于前面问题的分析:来源于http://blog.163.com/yuyang_tech/blog/static/216050083201211144120401/ 解决方法1: //来源:http: ...
- Linux下移动图像监测系统——motion的移植及应用
移动图像监控主系统的开发 移动图像监控的原理方法: 通过获取摄像头图像,比较前后每一帧的图像数据,从而实现移动物体监控.所有移动监控均是如此,只是图像帧的比较算法不同. 移动图像监控系统的实现 选择开 ...
- Excel催化剂开源第1波-自定义函数的源代码全公开
Excel催化剂插件从2018年1月1日开始运营,到今天刚好一周年,在过去一年时间里,感谢社区里的许多友人们的关心和鼓励,得以坚持下来,并收获一定的用户量和粉丝数和少量的经济收入回报和个人知名度的提升 ...
- Keil debug command SAVE 命令保存文件的解析
简介 使用 Keil debug 很方便,把内存中的一段区域 dump 出来也很方便,例如使用命令 SAVE filepath startAddr, endAddr, typeCode .但是要查看 ...
- 如何让Git适应敏捷开发流程?
一旦涉及到版本控制系统,Git实际上代表敏捷开发的水平.Git作为一款强大的开源系统,有较强的灵活性,可以按需匹配任何开发团队的工作流程.而这种分布式相比较集中式来说,可以赋予系统更好的性能特征,且允 ...