021.掌握Pod-Pod调度策略
一 Pod生命周期管理
1.1 Pod生命周期
|
状态值
|
描述
|
|
Pending
|
API Server已经创建该Pod,且Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
|
|
Running
|
Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
|
|
Succeeded
|
Pod内所有容器均成功执行退出,且不会重启。
|
|
Failed
|
Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
|
|
Unknown
|
由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
|
1.2 Pod重启策略
- Always:当容器失效时,由kubelet自动重启该容器;
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器;
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1/2/4/8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行;
- Job:OnFailure或Never,确保容器执行完成后不再重启;
- kubelet:在Pod失效时重启,不论将RestartPolicy设置为何值,也不会对Pod进行健康检查。
|
Pod包含的容器数
|
Pod当前的状态
|
发生事件
|
Pod的结果状态
|
||
RestartPolicy=Always
|
RestartPolicy=OnFailure
|
RestartPolicy=Never
|
|||
|
包含1个容器
|
Running
|
容器成功退出
|
Running
|
Succeeded
|
Succeeded
|
|
包含1个容器
|
Running
|
容器失败退出
|
Running
|
Running
|
Failed
|
|
包括两个容器
|
Running
|
1个容器失败退出
|
Running
|
Running
|
Running
|
|
包括两个容器
|
Running
|
容器被OOM杀掉
|
Running
|
Running
|
Failed
|
1.3 Pod健康检查
- ExecAction:在容器内执行一个命令,若返回码为0,则表明容器健康。
1 [root@uk8s-m-01 study]# vi dapi-liveness.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: dapi-liveness-pod
6 labels:
7 test: liveness-exec
8 spec:
9 containers:
10 - name: dapi-liveness
11 image: busybox
12 args:
13 - /bin/sh
14 - -c
15 - echo ok > /tmp/health; sleep 10; rm -rf /tmp/health; sleep 600
16 livenessProbe:
17 exec:
18 command:
19 - cat
20 - /tmp/health
21
22 [root@uk8s-m-01 study]# kubectl describe pod dapi-liveness-pod

- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,若能建立TCP连接,则表明容器健康。
1 [root@uk8s-m-01 study]# vi dapi-tcpsocket.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: dapi-healthcheck-tcp
6 spec:
7 containers:
8 - name: nginx
9 image: nginx
10 ports:
11 - containerPort: 80
12 livenessProbe:
13 tcpSocket:
14 port: 80
15 initialDelaySeconds: 30
16 timeoutSeconds: 1
17
18 [root@uk8s-m-01 study]# kubectl create -f dapi-tcpsocket.yaml
二 Pod调度
2.1 Depolyment/RC自动调度
1 [root@uk8s-m-01 study]# vi nginx-deployment.yaml
2 apiVersion: apps/v1beta1
3 kind: Deployment
4 metadata:
5 name: nginx-deployment-01
6 spec:
7 replicas: 3
8 template:
9 metadata:
10 labels:
11 app: nginx
12 spec:
13 containers:
14 - name: nginx
15 image: nginx:1.7.9
16 ports:
17 - containerPort: 80
18
19 [root@uk8s-m-01 study]# kubectl get deployments
20 NAME READY UP-TO-DATE AVAILABLE AGE
21 nginx-deployment-01 3/3 3 3 30s
22 [root@uk8s-m-01 study]# kubectl get rs
23 NAME DESIRED CURRENT READY AGE
24 nginx-deployment-01-5754944d6c 3 3 3 75s
25 [root@uk8s-m-01 study]# kubectl get pod | grep nginx
26 nginx-deployment-01-5754944d6c-hmcpg 1/1 Running 0 84s
27 nginx-deployment-01-5754944d6c-mcj8q 1/1 Running 0 84s
28 nginx-deployment-01-5754944d6c-p42mh 1/1 Running 0 84s
2.2 NodeSelector定向调度
1 [root@uk8s-m-01 study]# kubectl label nodes 172.24.9.14 speed=io
2 node/172.24.9.14 labeled
3 [root@uk8s-m-01 study]# vi nginx-master-controller.yaml
4 kind: ReplicationController
5 metadata:
6 name: nginx-master
7 labels:
8 name: nginx-master
9 spec:
10 replicas: 1
11 selector:
12 name: nginx-master
13 template:
14 metadata:
15 labels:
16 name: nginx-master
17 spec:
18 containers:
19 - name: master
20 image: nginx:1.7.9
21 ports:
22 - containerPort: 80
23 nodeSelector:
24 speed: io
25
26 [root@uk8s-m-01 study]# kubectl create -f nginx-master-controller.yaml
27 [root@uk8s-m-01 study]# kubectl get pods -o wide
28 NAME READY STATUS RESTARTS AGE IP NODE
29 nginx-master-7fjgj 1/1 Running 0 82s 172.24.9.71 172.24.9.14
2.3 NodeAffinity亲和性调度
- 更具表达力,即更精细的力度控制;
- 可以使用软限制、优先采用等限制方式,即调度器在无法满足优先需求的情况下,会使用其他次条件进行满足;
- 可以依据节点上正在运行的其他Pod的标签来进行限制,而非节点本身的标签,从而实现Pod之间的亲和或互斥关系。
1 [root@uk8s-m-01 study]# vi nodeaffinity-pod.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: with-node-affinity
6 spec:
7 affinity:
8 nodeAffinity:
9 requiredDuringSchedulingIgnoredDuringExecution:
10 nodeSelectorTerms:
11 - matchExpressions:
12 - key: kubernetes.io/arch
13 operator: In
14 values:
15 - amd64
16 preferredDuringSchedulingIgnoredDuringExecution:
17 - weight: 1
18 preference:
19 matchExpressions:
20 - key: disk-type
21 operator: In
22 values:
23 - ssd
24 containers:
25 - name: with-node-affinity
26 image: gcr.azk8s.cn/google_containers/pause:2.0
- 若同时定义nodeSelector和nodeAffinity,则必须两个条件都满足,Pod才能最终运行指定在Node上;;
- 若nodeAffinity指定多个nodeSelectorTerms,则只需要其中一个能够匹配成功即可;
- 若nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行该Pod。
2.4 PodAffinity亲和性调度
1 [root@uk8s-m-01 study]# vi nginx-flag.yaml #创建名为pod-flag,带有两个标签的Pod
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: pod-affinity
6 spec:
7 affinity:
8 podAffinity:
9 requiredDuringSchedulingIgnoredDuringExecution:
10 - labelSelector:
11 matchExpressions:
12 - key: security
13 operator: In
14 values:
15 - S1
16 topologyKey: kubernetes.io/hostname
17 containers:
18 - name: with-pod-affinity
19 image: gcr.azk8s.cn/google_containers/pause:2.0
1 [root@uk8s-m-01 study]# vi nginx-affinity-in.yaml #创建定义标签security=S1,对应如上Pod “Pod-flag”。
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: pod-affinity
6 spec:
7 affinity:
8 podAffinity:
9 requiredDuringSchedulingIgnoredDuringExecution:
10 - labelSelector:
11 matchExpressions:
12 - key: security
13 operator: In
14 values:
15 - S1
16 topologyKey: kubernetes.io/hostname
17 containers:
18 - name: with-pod-affinity
19 image: gcr.azk8s.cn/google_containers/pause:2.0
20
21 [root@uk8s-m-01 study]# kubectl create -f nginx-affinity-in.yaml
22 [root@uk8s-m-01 study]# kubectl get pods -o wide

1 [root@uk8s-m-01 study]# vi nginx-affinity-out.yaml #创建不能与参照目标Pod运行在同一个Node上的调度策略
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: anti-affinity
6 spec:
7 affinity:
8 podAffinity:
9 requiredDuringSchedulingIgnoredDuringExecution:
10 - labelSelector:
11 matchExpressions:
12 - key: security
13 operator: In
14 values:
15 - S1
16 topologyKey: failure-domain.beta.kubernetes.io/zone
17 podAntiAffinity:
18 requiredDuringSchedulingIgnoredDuringExecution:
19 - labelSelector:
20 matchExpressions:
21 - key: security
22 operator: In
23 values:
24 - nginx
25 topologyKey: kubernetes.io/hostname
26 containers:
27 - name: anti-affinity
28 image: gcr.azk8s.cn/google_containers/pause:2.0
29
30 [root@uk8s-m-01 study]# kubectl get pods -o wide #验证
2.5 Taints和Tolerations(污点和容忍)
1 tolerations:
2 - key: "key"
3 operator: "Equal"
4 value: "value"
5 effect: "NoSchedule"
1 tolerations:
2 - key: "key"
3 operator: "Exists"
4 effect: "NoSchedule"
- operator的值是Exists(无须指定value);
- operator的值是Equal并且value相等;
- 空的key配合Exists操作符能够匹配所有的键和值;
- 空的effect匹配所有的effect。
1 $ kubectl taint node node1 key=value1:NoSchedule
2 $ kubectl taint node node1 key=value1:NoExecute
3 $ kubectl taint node node1 key=value2:NoSchedule
4 tolerations:
5 - key: "key1"
6 operator: "Equal"
7 value: "value"
8 effect: "NoSchedule"
9 tolerations:
10 - key: "key1"
11 operator: "Equal"
12 value: "value1"
13 effect: "NoExecute"
1 tolerations:
2 - key: "key1"
3 operator: "Equal"
4 value: "value"
5 effect: "NoSchedule"
6 tolerationSeconds: 3600
- 独占节点:
- 具有特殊硬件设备的节点
1 $ kubectl taint nodes 【nodename】 special=true:NoSchedule
2 $ kubectl taint nodes 【nodename】 special=true:PreferNoSchedule
- 定义Pod驱逐行为
- 没有设置toleration的pod会被立刻驱逐;
- 配置了对应toleration的pod,若没有为tolerationSeconds赋值,则会一直保留在此节点中;
- 配置了对应toleration的pod,且为tolerationSeconds赋值,则在指定时间后驱逐。
2.6 DaemonSet
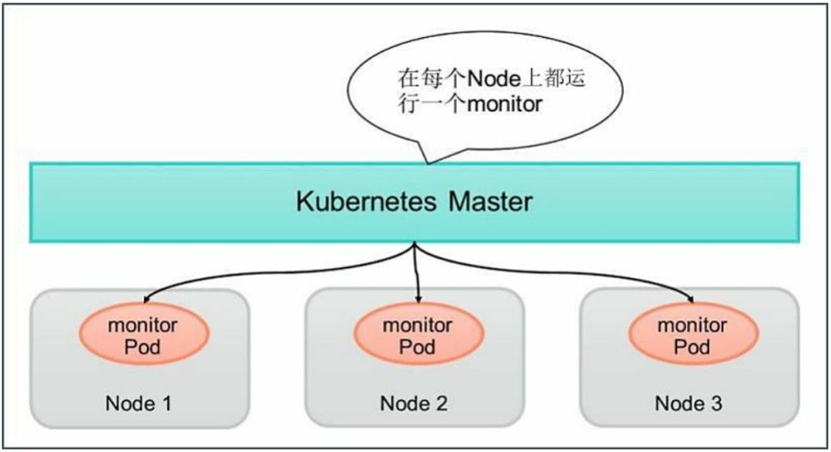
1 [root@uk8s-m-01 study]# vi fluentd-ds.yaml
2 apiVersion: extensions/v1beta1
3 kind: DaemonSet
4 metadata:
5 name: fluentd-cloud-logging
6 namespace: kube-system
7 labels:
8 k8s-app: fluentd-cloud-logging
9 spec:
10 template:
11 metadata:
12 namespace: kube-system
13 labels:
14 k8s-app: fluentd-cloud-logging
15 spec:
16 containers:
17 - name: fluentd-cloud-logging
18 image: gcr.azk8s.cn/google_containers/fluentd-elasticsearch:1.17
19 resources:
20 limits:
21 cpu: 100m
22 memory: 200Mi
23 env:
24 - name: FLUENTD_ARGS
25 value: -q
26 volumeMounts:
27 - name: varlog
28 mountPath: /var/log
29 readOnly: false
30 - name: containers
31 mountPath: /var/lib/docker/containers
32 readOnly: false
33 volumes:
34 - name: containers
35 hostPath:
36 path: /var/lib/docker/containers
37 - name: varlog
38 hostPath:
39 path: /var/log
2.7 Job批处理调度

- Non-parallel Jobs
- Parallel Jobs with a fixed completion count
- Parallel Jobs with a work queue
- 每个Pod都能独立判断和决定是否还有任务项需要处理;
- 如果某个Pod正常结束,则Job不会再启动新的Pod;
- 如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的情况。它们应该都处于即将结束、退出的状态;
- 如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Jod成功结束。
2.8 Cronjob定时任务
1 [root@uk8s-m-01 study]# vi cron.yaml
2 apiVersion: batch/v2alpha1
3 kind: CronJob
4 metadata:
5 name: hello
6 spec:
7 schedule: "*/1 * * * *"
8 jobTemplate:
9 spec:
10 template:
11 spec:
12 containers:
13 - name: hello
14 image: busybox
15 args:
16 - /bin/sh
17 - -c
18 - date; echo Hello from the Kubernetes cluster
19 restartPolicy: OnFailure
1 [root@master study]# kubectl create -f cron.yaml
2 [root@master study]# kubectl get cronjob hello
3 NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
4 hello */1 * * * * False 0 <none> 29s
5 [root@master study]# kubectl get pods
6 NAME READY STATUS RESTARTS AGE
7 hello-1573378080-zvvm5 0/1 Completed 0 68s
8 hello-1573378140-9pmwz 0/1 Completed 0 8s
9 [root@node1 ~]# docker logs c7 #node节点查看日志
10 Sun Nov 10 09:31:13 UTC 2019
11 Hello from the Kubernetes cluster
12 [root@master study]# kubectl get jobs #查看任务
13 NAME COMPLETIONS DURATION AGE
14 hello-1573378500 1/1 8s 3m7s
15 hello-1573378560 1/1 4s 2m7s
16 hello-1573378620 1/1 6s 67s
17 hello-1573378680 1/1 4s 7s
18 [root@master study]# kubectl get pods -o wide | grep hello-1573378680 #以job任务查看对应的pod
19 [root@master study]# kubectl delete cj hello #删除cronjob
2.9 初始化容器
- 等待其他关联组件正确运行( 例如数据库或某个后台服务) 。
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置, 或者将自身注册到某个中央数据库中。
- 下载相关依赖包, 或者对系统进行一些预配置操作。
1 [root@uk8s-m-01 study]# vi nginx-init-containers.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: nginx
6 annotations:
7 spec:
8 initContainers:
9 - name: install
10 image: busybox
11 command:
12 - wget
13 - "-O"
14 - "/work-dir/index.html"
15 - http://kubernetes.io
16 volumeMounts:
17 - name: workdir
18 mountPath: "/work-dir"
19 containers:
20 - name: nginx
21 image: nginx:1.7.9
22 ports:
23 - containerPort: 80
24 volumeMounts:
25 - name: workdir
26 mountPath: /usr/share/nginx/html
27 dnsPolicy: Default
28 volumes:
29 - name: workdir
30 emptyDir: {}
1 [root@uk8s-m-01 study]# kubectl get pods
2 NAME READY STATUS RESTARTS AGE
3 nginx 0/1 Init:0/1 0 2s
4 [root@uk8s-m-01 study]# kubectl get pods
5 NAME READY STATUS RESTARTS AGE
6 nginx 1/1 Running 0 13s
7 [root@uk8s-m-01 study]# kubectl describe pod nginx #查看事件可知会先创建init容器,名为install
- 如果多个init container都定义了资源请求/资源限制, 则取最大的值作为所有init container的资源请求值/资源限制值。
- Pod的有效(effective) 资源请求值/资源限制值取以下二者中的较大值。
- 所有应用容器的资源请求值/资源限制值之和。
- init container的有效资源请求值/资源限制值。
- 调度算法将基于Pod的有效资源请求值/资源限制值进行计算,即init container可以为初始化操作预留系统资源, 即使后续应用容器无须使用这些资源。
- Pod的有效QoS等级适用于init container和应用容器。
- 资源配额和限制将根据Pod的有效资源请求值/资源限制值计算生效。
- Pod级别的cgroup将基于Pod的有效资源请求/限制, 与调度机制
- init container的镜像被更新时, init container将会重新运行, 导致Pod重启。 仅更新应用容器的镜像只会使得应用容器被重启。
- Pod的infrastructure容器更新时, Pod将会重启。
- 若Pod中的所有应用容器都终止了, 并且RestartPolicy=Always, 则Pod会重启。
021.掌握Pod-Pod调度策略的更多相关文章
- Docker 与 K8S学习笔记(二十五)—— Pod的各种调度策略(上)
上一篇,我们学习了各种工作负载的使用,工作负载它会自动帮我们完成Pod的调度和部署,但有时我们需要自己定义Pod的调度策略,这个时候该怎么办呢?今天我们就来看一下如何定义Pod调度策略. 一.Node ...
- 三、Kubernetes之深入了解Pod
1.yaml格式的Pod配置文件内容及注解 深入Pod之前,首先我们来了解下Pod的yaml整体文件内容及功能注解. 如下: # yaml格式的pod定义文件完整内容: apiVersion: v ...
- kubernetes 实践四:Pod详解
本篇是关于k8s的Pod,主要包括Pod和容器的使用.Pod的控制和调度管理.应用配置管理等内容. Pod的定义 Pod是k8s的核心概念一直,就名字一样,是k8s中一个逻辑概念.Pod是docekr ...
- pod详解
什么是pod? 官方说明: Pod是Kubernetes应用程序的最基本执行单元-是你创建或部署Kubernetes对象模型中的最小和最简单的单元. Pod表示在集群上运行的进程.Pod封装了应用程序 ...
- k8s核心资源之namespace与pod污点容忍度生命周期进阶篇(四)
目录 1.命名空间namespace 1.1 什么是命名空间? 1.2 namespace应用场景 1.3 namespacs常用指令 1.4 namespace资源限额 2.标签 2.1 什么是标签 ...
- Pod 生命周期和重启策略
Pod 在整个生命周期中被系统定义为各种状态,熟悉 Pod 的各种状态对于理解如何设置 Pod 的调度策略.重启策略是很有必要的. Pod 的状态 状态值 描述 Pending API Server ...
- k8s 中的 Pod 细节了解
k8s中Pod的理解 基本概念 k8s 为什么使用 Pod 作为最小的管理单元 如何使用 Pod 1.自主式 Pod 2.控制器管理的 Pod 静态 Pod Pod的生命周期 Pod 如何直接暴露服务 ...
- [Kubernetes]深入解析Pod对象
k8s集群搭建是比较容易的,但是我们为什么要搭建,里面涉及到的内容,我们为什么需要? 这篇文章就尝试来讲讲,我们为什么需要一个Pod,对Pod对象来一个深入解析. 我们为什么需要Pod 我们先来谈一个 ...
- centos7下kubernetes(9。kubernetes中用label控制pod得位置)
Kubernetes通过label实现将pod运行在指定得node上. 默认配置下,Schesuler将pod调度到所有可用得node,有时候我们希望将pod部署到指定得node,比如将有大量磁盘I/ ...
- Kubernetes之POD
什么是Pod Pod是可以创建和管理Kubernetes计算的最小可部署单元.一个Pod代表着集群中运行的一个进程. Pod就像是豌豆荚一样,它由一个或者多个容器组成(例如Docker容器),它们共享 ...
随机推荐
- 代码审计-dedecms任意文件名修改拿shell
0x01 漏洞分析 漏洞文件: dede/file_manage_control.php ,$fmdo 开始时赋值,所以我们可以使fmdo=rename ,使其进入 if语句 ,调用 FileMana ...
- [USACO14JAN]滑雪等级Ski Course Rating
题目描述 The cross-country skiing course at the winter Moolympics is described by an M x N grid of eleva ...
- 关于Linux中的 localhost 默认地址简单介绍
大家都知道localhost指的是本机的IP地址:127.0.0.1 用于回路测试,那能不能修改localhost呢,答案肯定是可以的 打开终端--->输入: vim /etc/host 然后 ...
- 面试必问:ACID/CAP
转载: https://www.jdon.com/artichect/acid-cap.html ACID和CAP的详尽比较 事务机制ACID和CAP理论是数据管理和分布式系统中两个重要的概念,很不巧 ...
- 玩转u8g2 OLED库,一篇就够
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- pytorch笔记
Tensor slice Tensor的indices操作 以[2,3]矩阵为例,slice后可以得到任意shape的矩阵,并不是说一定会小于2行3列. import torch truths=tor ...
- js小数加减乘除时精度不准确
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_33237207/article/d ...
- 下载达 10 万次的 IDEA 插件,K8s 一键部署了解一下?
作者 | 铃儿响叮当 导读:涉及开发的技术人员,永远绕不开的就是将应用部署到相应服务器上,本文将给大家讲解:对于容器服务 ACK,怎么实现真正"一键部署",提高开发部署效率,在 K ...
- HTTP 304状态码的详细讲解
首先,对于304状态码不应该认为是一种错误,而是对客户端有缓存情况下服务端的一种响应. 客户端在请求一个文件的时候,发现自己缓存的文件有 Last Modified ,那么在请求中会包含 If Mod ...
- 【原创】go语言学习(十一)package简介
目录 Go源码组织方式 main函数和main包 编译命令 自定义包 init函数以及执行行顺序 _标识符 Go源码组织方式 1. Go通过package的方式来组织源码 package 包名 注意: ...