Hadoop 系列(三)—— 分布式计算框架 MapReduce
一、MapReduce概述
Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。
MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值对处理,它将作业的输入视为一组 <key,value> 对,并生成一组 <key,value> 对作为输出。输出和输出的 key 和 value 都必须实现Writable 接口。
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)二、MapReduce编程模型简述
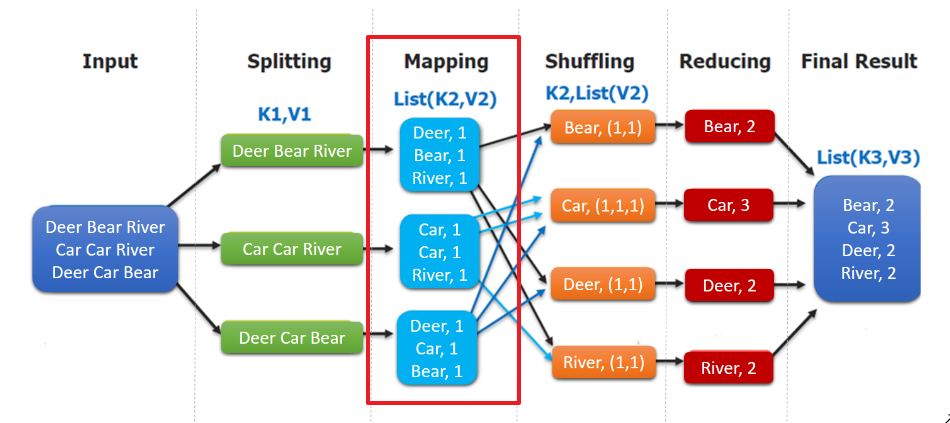
这里以词频统计为例进行说明,MapReduce 处理的流程如下:
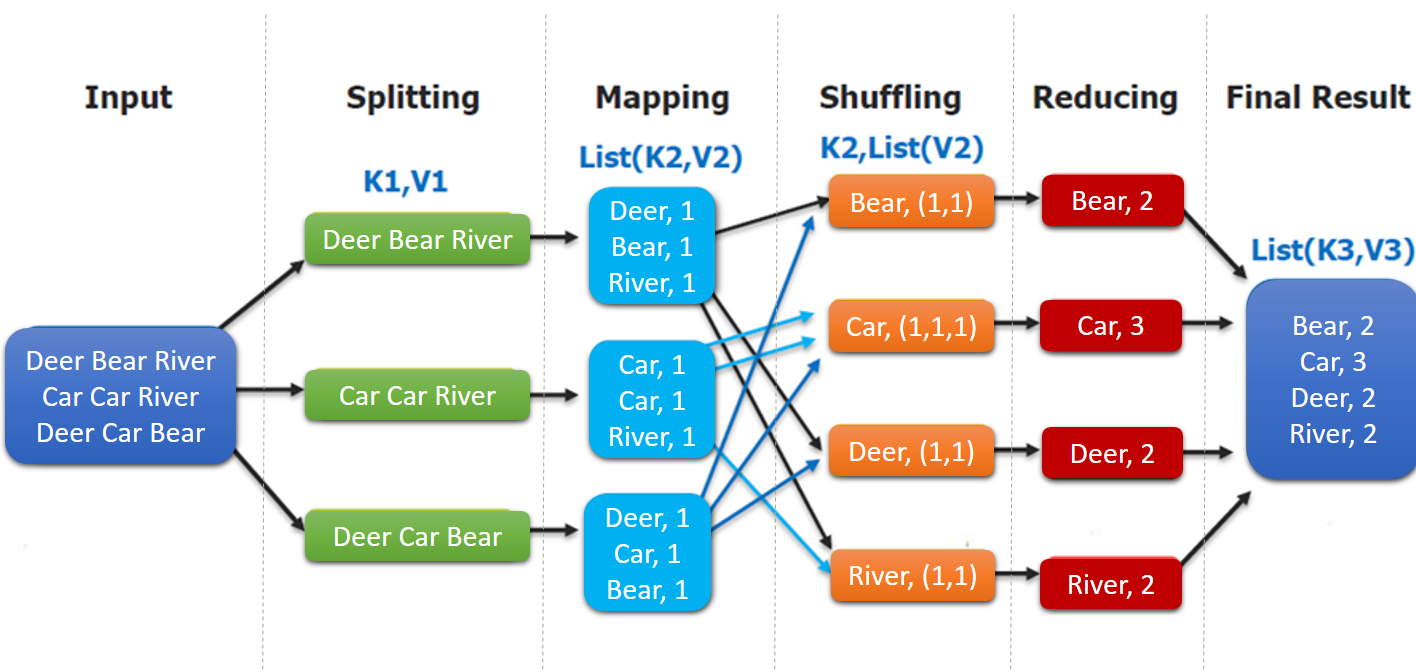
input : 读取文本文件;
splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容;- mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为 1,代表出现 1 次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是 Mapping 中的 V2; Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
三、combiner & partitioner
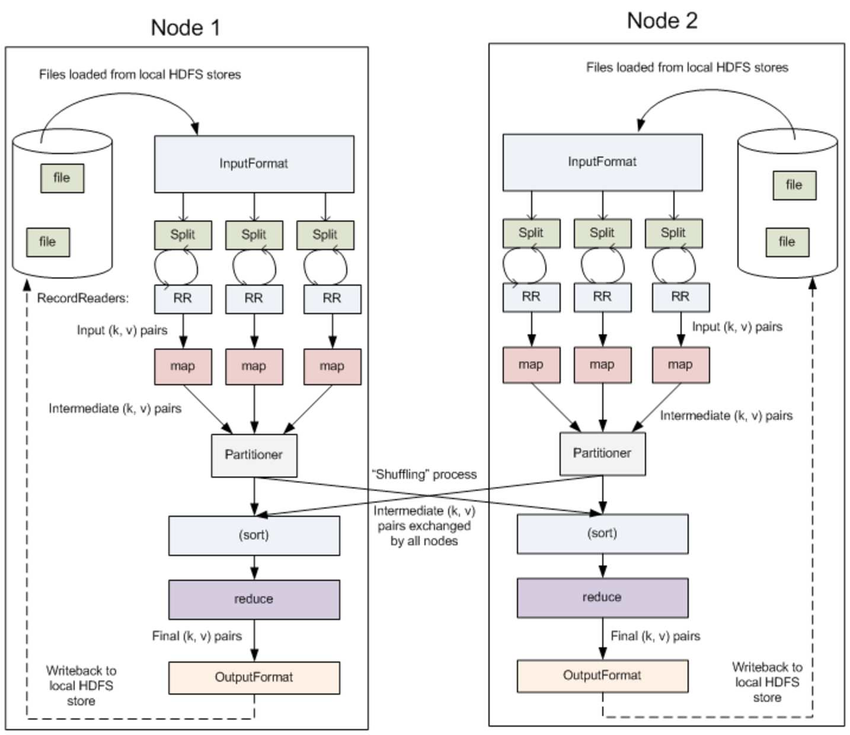
3.1 InputFormat & RecordReaders
InputFormat 将输出文件拆分为多个 InputSplit,并由 RecordReaders 将 InputSplit 转换为标准的<key,value>键值对,作为 map 的输出。这一步的意义在于只有先进行逻辑拆分并转为标准的键值对格式后,才能为多个 map 提供输入,以便进行并行处理。
3.2 Combiner
combiner 是 map 运算后的可选操作,它实际上是一个本地化的 reduce 操作,它主要是在 map 计算出中间文件后做一个简单的合并重复 key 值的操作。这里以词频统计为例:
map 在遇到一个 hadoop 的单词时就会记录为 1,但是这篇文章里 hadoop 可能会出现 n 多次,那么 map 输出文件冗余就会很多,因此在 reduce 计算前对相同的 key 做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
但并非所有场景都适合使用 combiner,使用它的原则是 combiner 的输出不会影响到 reduce 计算的最终输入,例如:求总数,最大值,最小值时都可以使用 combiner,但是做平均值计算则不能使用 combiner。
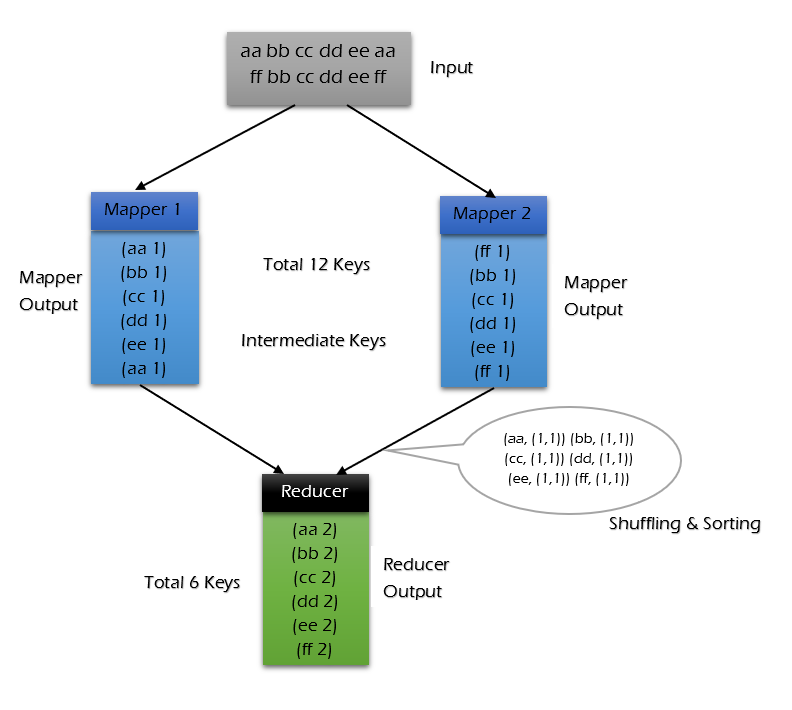
不使用 combiner 的情况:
使用 combiner 的情况:
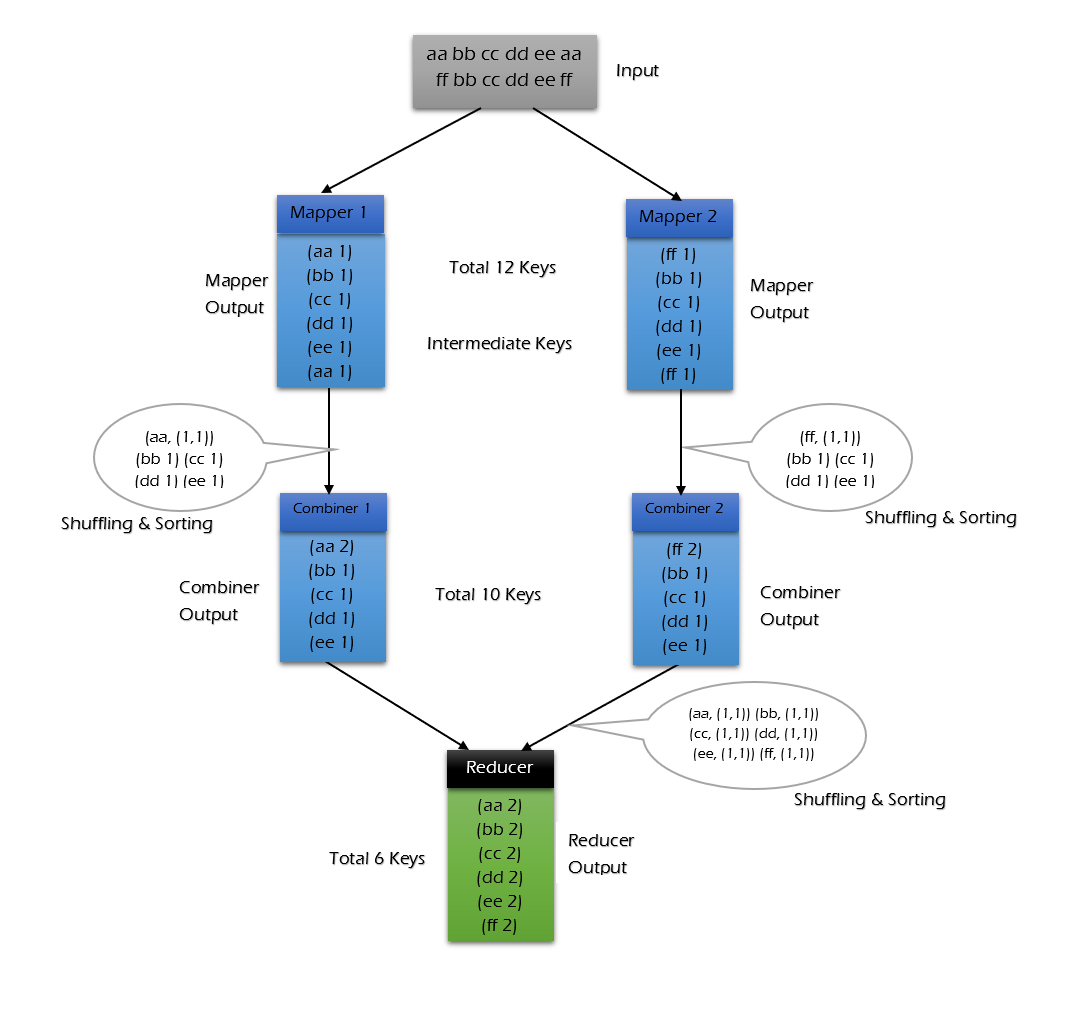
可以看到使用 combiner 的时候,需要传输到 reducer 中的数据由 12keys,降低到 10keys。降低的幅度取决于你 keys 的重复率,下文词频统计案例会演示用 combiner 降低数百倍的传输量。
3.3 Partitioner
partitioner 可以理解成分类器,将 map 的输出按照 key 值的不同分别分给对应的 reducer,支持自定义实现,下文案例会给出演示。
四、MapReduce词频统计案例
4.1 项目简介
这里给出一个经典的词频统计的案例:统计如下样本数据中每个单词出现的次数。
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive为方便大家开发,我在项目源码中放置了一个工具类 WordCountDataUtils,用于模拟产生词频统计的样本,生成的文件支持输出到本地或者直接写到 HDFS 上。
项目完整源码下载地址:hadoop-word-count
4.2 项目依赖
想要进行 MapReduce 编程,需要导入 hadoop-client 依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>4.3 WordCountMapper
将每行数据按照指定分隔符进行拆分。这里需要注意在 MapReduce 中必须使用 Hadoop 定义的类型,因为 Hadoop 预定义的类型都是可序列化,可比较的,所有类型均实现了 WritableComparable 接口。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}WordCountMapper 对应下图的 Mapping 操作:
WordCountMapper 继承自 Mappe 类,这是一个泛型类,定义如下:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
......
}- KEYIN :
mapping输入 key 的类型,即每行的偏移量 (每行第一个字符在整个文本中的位置),Long类型,对应 Hadoop 中的LongWritable类型; - VALUEIN :
mapping输入 value 的类型,即每行数据;String类型,对应 Hadoop 中Text类型; - KEYOUT :
mapping输出的 key 的类型,即每个单词;String类型,对应 Hadoop 中Text类型; - VALUEOUT:
mapping输出 value 的类型,即每个单词出现的次数;这里用int类型,对应IntWritable类型。
4.4 WordCountReducer
在 Reduce 中进行单词出现次数的统计:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
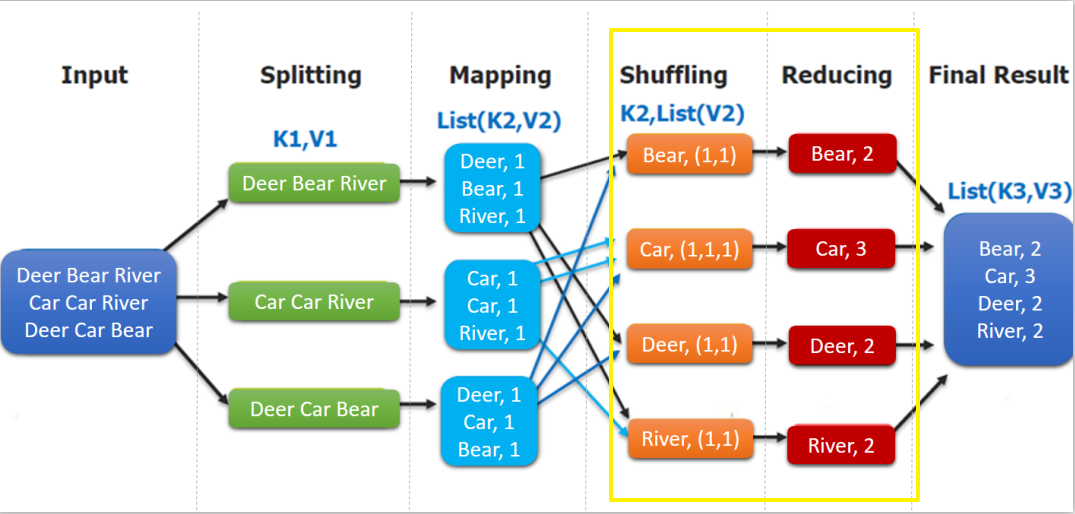
}如下图,shuffling 的输出是 reduce 的输入。这里的 key 是每个单词,values 是一个可迭代的数据类型,类似 (1,1,1,...)。
4.4 WordCountApp
组装 MapReduce 作业,并提交到服务器运行,代码如下:
/**
* 组装作业 并提交到集群运行
*/
public class WordCountApp {
// 这里为了直观显示参数 使用了硬编码,实际开发中可以通过外部传参
private static final String HDFS_URL = "hdfs://192.168.0.107:8020";
private static final String HADOOP_USER_NAME = "root";
public static void main(String[] args) throws Exception {
// 文件输入路径和输出路径由外部传参指定
if (args.length < 2) {
System.out.println("Input and output paths are necessary!");
return;
}
// 需要指明 hadoop 用户名,否则在 HDFS 上创建目录时可能会抛出权限不足的异常
System.setProperty("HADOOP_USER_NAME", HADOOP_USER_NAME);
Configuration configuration = new Configuration();
// 指明 HDFS 的地址
configuration.set("fs.defaultFS", HDFS_URL);
// 创建一个 Job
Job job = Job.getInstance(configuration);
// 设置运行的主类
job.setJarByClass(WordCountApp.class);
// 设置 Mapper 和 Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置 Mapper 输出 key 和 value 的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置 Reducer 输出 key 和 value 的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果输出目录已经存在,则必须先删除,否则重复运行程序时会抛出异常
FileSystem fileSystem = FileSystem.get(new URI(HDFS_URL), configuration, HADOOP_USER_NAME);
Path outputPath = new Path(args[1]);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
// 设置作业输入文件和输出文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outputPath);
// 将作业提交到群集并等待它完成,参数设置为 true 代表打印显示对应的进度
boolean result = job.waitForCompletion(true);
// 关闭之前创建的 fileSystem
fileSystem.close();
// 根据作业结果,终止当前运行的 Java 虚拟机,退出程序
System.exit(result ? 0 : -1);
}
}需要注意的是:如果不设置 Mapper 操作的输出类型,则程序默认它和 Reducer 操作输出的类型相同。
4.5 提交到服务器运行
在实际开发中,可以在本机配置 hadoop 开发环境,直接在 IDE 中启动进行测试。这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除 Hadoop 外的第三方依赖,直接打包即可:
# mvn clean package使用以下命令提交作业:
hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \
com.heibaiying.WordCountApp \
/wordcount/input.txt /wordcount/output/WordCountApp作业完成后查看 HDFS 上生成目录:
# 查看目录
hadoop fs -ls /wordcount/output/WordCountApp
# 查看统计结果
hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000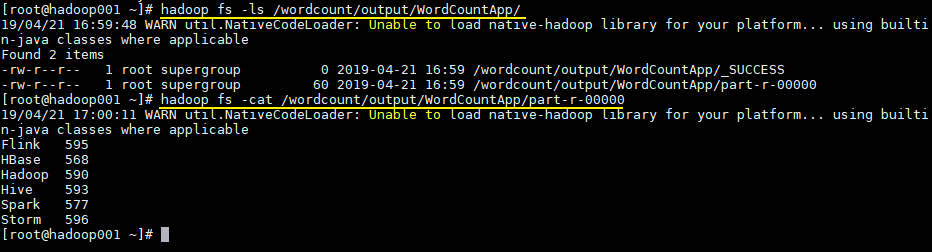
五、词频统计案例进阶之Combiner
5.1 代码实现
想要使用 combiner 功能只要在组装作业时,添加下面一行代码即可:
// 设置 Combiner
job.setCombinerClass(WordCountReducer.class);5.2 执行结果
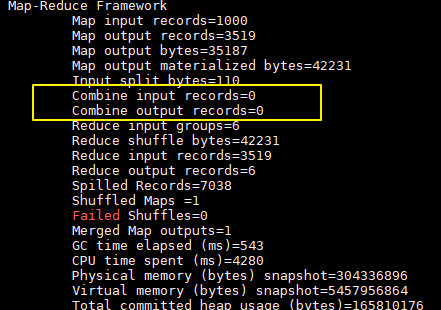
加入 combiner 后统计结果是不会有变化的,但是可以从打印的日志看出 combiner 的效果:
没有加入 combiner 的打印日志:
加入 combiner 后的打印日志如下:
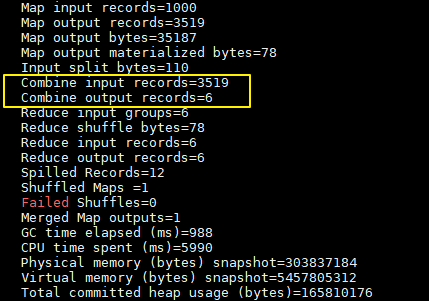
这里我们只有一个输入文件并且小于 128M,所以只有一个 Map 进行处理。可以看到经过 combiner 后,records 由 3519 降低为 6(样本中单词种类就只有 6 种),在这个用例中 combiner 就能极大地降低需要传输的数据量。
六、词频统计案例进阶之Partitioner
6.1 默认的Partitioner
这里假设有个需求:将不同单词的统计结果输出到不同文件。这种需求实际上比较常见,比如统计产品的销量时,需要将结果按照产品种类进行拆分。要实现这个功能,就需要用到自定义 Partitioner。
这里先介绍下 MapReduce 默认的分类规则:在构建 job 时候,如果不指定,默认的使用的是 HashPartitioner:对 key 值进行哈希散列并对 numReduceTasks 取余。其实现如下:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}6.2 自定义Partitioner
这里我们继承 Partitioner 自定义分类规则,这里按照单词进行分类:
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
return WordCountDataUtils.WORD_LIST.indexOf(text.toString());
}
}在构建 job 时候指定使用我们自己的分类规则,并设置 reduce 的个数:
// 设置自定义分区规则
job.setPartitionerClass(CustomPartitioner.class);
// 设置 reduce 个数
job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());6.3 执行结果
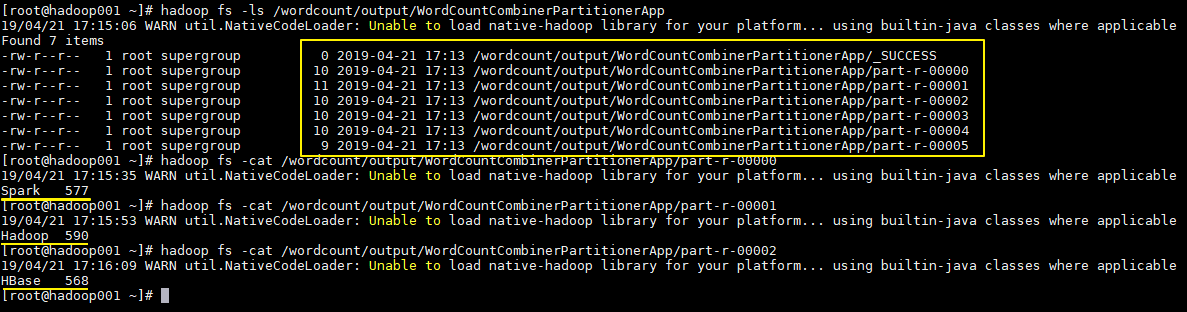
执行结果如下,分别生成 6 个文件,每个文件中为对应单词的统计结果:
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hadoop 系列(三)—— 分布式计算框架 MapReduce的更多相关文章
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- Hadoop介绍-2.分布式计算框架Hadoop原理及架构全解
Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统.最核心的模块包括Hadoop Common.HDFS与MapReduce. HDFS HDFS是Hadoop分布式文件系统(H ...
- 分布式计算框架-MapReduce 基本原理(MP用于分布式计算)
hadoop最主要的2个基本的内容要了解.上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理. MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并 ...
- Hadoop(三):MapReduce程序(python)
使用python语言进行MapReduce程序开发主要分为两个步骤,一是编写程序,二是用Hadoop Streaming命令提交任务. 还是以词频统计为例 一.程序开发1.Mapper for lin ...
- Hadoop整理三(Hadoop分布式计算框架MapReduce)
一.概念 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想.它极大 ...
- Hadoop整理四(Hadoop分布式计算框架MapReduce)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
随机推荐
- 快速接入业务监控体系,grafana监控的艺术
做一个系统,如果不做监控,是不完善的. 如果为做一个快速系统,花力气去做监控,是不值得的. 因为,我们有必要具备一个能够快速建立监控体系的能力.即使你只是一个普通开发人员! 个人觉得,做监控有三个核心 ...
- Xmanager 5远程连接CentOS7图形化界面
1.安装Xmanager 5下载链接:https://pan.baidu.com/s/1JwBk3UB4ErIDheivKv4-NA提取码:cw04 双击xmgr5_wm.exe进行安装 点击‘下一步 ...
- Codeforces 1133E - K Balanced Teams - [DP]
题目链接:https://codeforces.com/contest/1133/problem/C 题意: 给出 $n$ 个数,选取其中若干个数分别组成 $k$ 组,要求每组内最大值与最小值的差值不 ...
- ES5_04_Array扩展
介绍什么是Array对象? # Array 对象用于在单个的变量中存储多个值 1. 创建 Array 对象的语法: 2. Array 对象属性 3. Array 对象方法 补充: 1. Array.p ...
- C++智能指针的几种用法
auto在c++11中已经弃用. 一.auto_ptr模板 auto_ptr与shared_ptr.unique_ptr都定义了类似指针的对象,可以将new到的地址赋给这一对象,当智能指针过期时,析构 ...
- VS2013日常使用若干技巧+快捷键
1.注释的方法 1)sqlserver中,单行注释:— — 多行注释:/* 代码 */ 2)C#中,单行注释:// 多行注释:/* 代码 */ 3)C#中多行注释的快捷方式:先选中你要注 ...
- 【机器学习实践】解决Jupyter Notebook中不能正常显示中文标签及负号的方法
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams[' ...
- kuangbin专题 专题二 搜索进阶 Nightmare Ⅱ HDU - 3085
题目链接:https://vjudge.net/problem/HDU-3085 题意:有两个鬼和两个人和墙,鬼先走,人再走,鬼每走过的地方都会复制一个新鬼, 但新鬼只能等待旧鬼走完一次行程之后,下一 ...
- c++学习书籍推荐《C标准库(英文版)》下载
<C标准库(英文版)>是由世界级C语言专家编写的C标准库经典著作,影响了几代程序员. <C标准库(英文版)>集中讨论了C标准库,全面介绍了ANSI/ISO C语言标准的所有库函 ...
- set.contains()分析
先看一段代码 Set s = new HashSet(); List<String> list = new ArrayList<>(); list.add("a&qu ...