大数据Hadoop-1
大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵。
一、概述
本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建hadoop平台(2.1)。hadoop独立环境和伪分布式环境都无法发挥hadoop的价值,若想利用hadoop进行一些有价值的工作,必须搭建hadoop分布式集群环境。
下文以三台虚拟机为基础搭建集群环境,系统版本为CentOS-7,虚拟机地址分别为:192.168.1.106、192.168.1.109、192.168.1.110
二、修改主机名
编辑network文件,文件位于/etc/sysconfig路径下,若文件为空则添加如下内容,如不为空,则修改:HOSTNAME=namenode,namenode为修改的主机名。
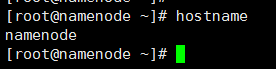
修改192.168.1.106的主机名为namenode、192.168.1.109的主机名为datanode01、192.168.1.110的主机名为datanode02。修改后键入命令hostname验证是否修改成功,如在192.168.1.106上键入hostname后出现namenode则表示修改成功,如下图所示:
三、修改hosts
修改hosts是为了配置前面修改的主机名和IP的映射关系。hosts文件位于/etc路径下,三台虚拟机都需要添加如下内容:
修改hosts
修改后效果如图所示:

四、关闭防火墙(三台机器均需关闭)
1、查看防火墙状态
查看防火墙状态
如下则表示防火墙处于开启状态:

2、关闭防火墙
临时关闭防火墙
再通过service iptables status查看防火墙状态,如下则表示防火墙已经关闭:

但是,这仅仅是在当前状态下关闭防火墙,系统重启后防火墙仍然会自动开启,所以需要禁止开机启动防火墙
禁止开机启动防火墙
执行命令后重启系统生效。
五、关闭selinux(三台机器均需关闭)
selinux是一个防护程序,类似于防火墙。编辑selinux文件,文件位于:/etc/sysconfig路径下
修改SELINUX=enforcing为SELINUX=disabled,修改后效果如下:

六、ssh免密码登录设置
hadoop集群模式下,各主机之间需要互相通信,比如上传文件到HDFS文件系统上时,都需要对文件进行备份。所以需要各机器之间能够进行免密码登录。
1、生成秘钥:输入命令:ssh-keygen -t rsa,按3次回车之后会生成秘钥。
2、拷贝秘钥到本机和其他两台机器上:分别执行命令:ssh-copy-id 192.168.1.109,ssh-copy-id 192.168.1.110拷贝秘钥。
3、免密码登录验证:执行命令ssh 192.168.1.109,如果不需要输入密码就能登录到109机器上,则免密码登录设置成功,110也执行相同的测试。
七、安装JDK并配置环境变量(三台机器均需要做相同的设置)
1、创建目录/home/software,上传JDK到该目录下并解压,此处使用的JDK版本是jdk1.8.0_131
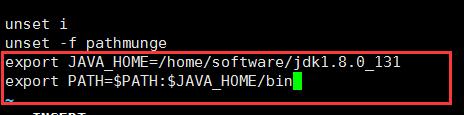
2、配置环境变量:编辑文件profile,文件位于:/etc目录下,在文件尾部添加如下内容:
配置java环境变量
如图所示:
3、输入命令source /etc/profile是文件立即生效
4、测试:在任意路径下输入命令:java -version,若打印出java的版本信息,则代表java安装成功。如下所示:

八、安装hadoop集群
1、下载hadoop安装包
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/,这是hadoop-2.7.3的项目存档地址。随着Apache各项目的版本更新,各项目的网站上只上架最新版本和近期历史重要版本,如果网站下架的项目,需要到Apache存档地址上寻找,该地址是:https://archive.apache.org/dist/,hadoop存档地址是:https://archive.apache.org/dist/hadoop/。在hadoop2.7.3版本的地址下,下载hadoop-2.7.3.tar.gz文件包。如下图所示:

2、安装hadoop并配置环境变量
①、上传hadoop安装包hadoop-2.7.3.tar.gz到/home/software目录下并解压,当然,也可以放在其他目录下。
②、编辑文件profile,文件位于/etc目录下,添加如下代码:
配置hadoop环境变量
并在PATH变量后追加如下代码:
追加PATH变量
输入命令source /etc/profile使profile配置文件立即生效。最终profile文件效果如下所示:

③、验证hadoop环境变量是否配置成功:在任何路径下输入命令hadoop,如果打印相关信息,则代表hadoop的安装和环境变量配置成功,如下图所示:

至此,hadoop安装和配置环境变量成功,但是,这仅仅是进行了基础的安装,还需要进行一些配置,使hadoop能真正的工作。
以上第八小节的操作,在一台机器上(我使用namenode机器)配置即可,其他两台机器只需要按第②、③点编辑profile文件,因为在接下来的内容中会接着配置hadoop,全部配置完成后,把hadoop-2.7.3文件拷贝到其他机器即可。
九、hadoop配置
1、修改hadoop-env.sh文件,文件位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
修改java_home,找到代码 export JAVA_HOME=${JAVA_HOME} ,修改为JAVA_HOME的值,即:export JAVA_HOME=/home/software/jdk1.8.0_131
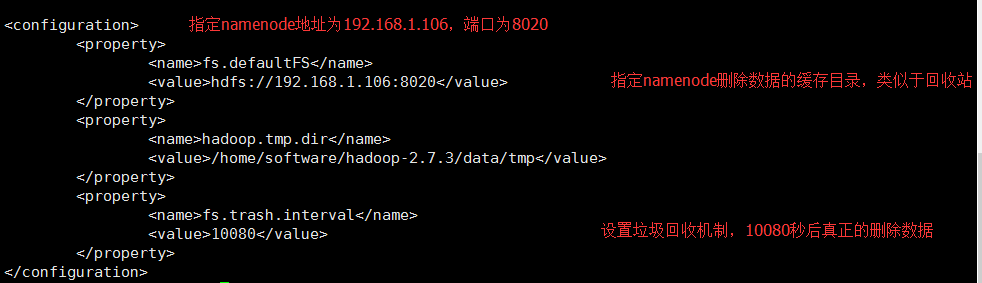
2、修改core-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
修改core-site.xml
修改后效果如下:
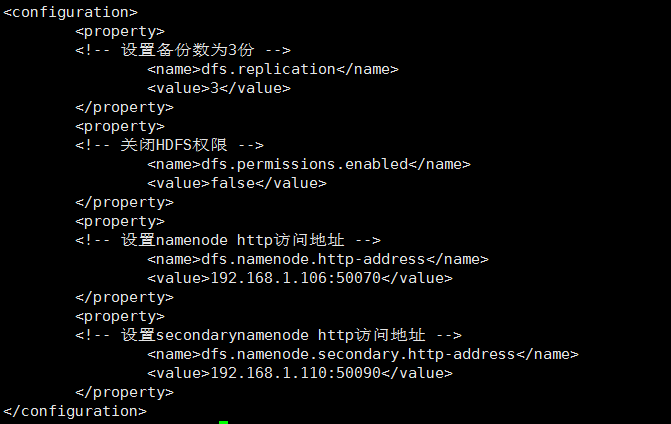
3、 修改hdfs-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
修改hdfs-site.xm
修改后效果如下:
4、修改mapred-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下,但是该路径下并不存在mapred-site.xml文件,只存在mapred-site.xml.template文件,将mapred-site.xml.template文件修改为mapred-site.xml即可。
找到<configuration>节点,在该节点下添加如下代码:
修改mapred-site.xm
修改后效果如下:
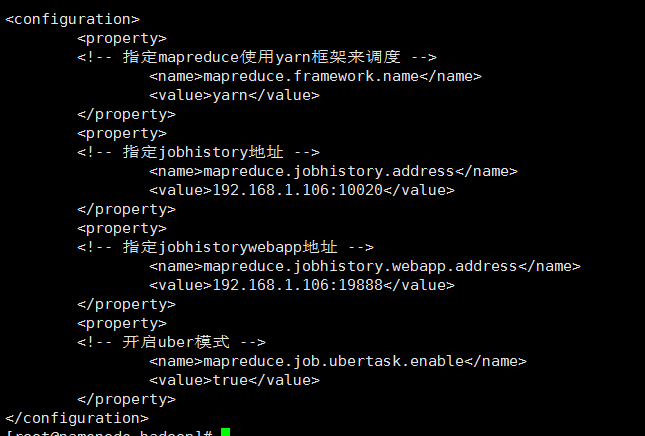
5、修改yarn-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
修改yarn-site.xml
修改后效果如下:
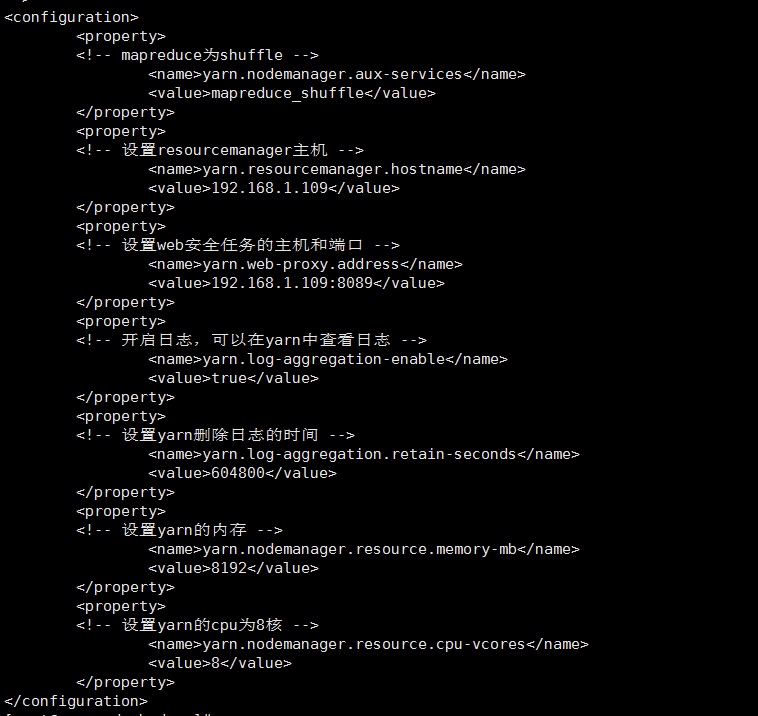
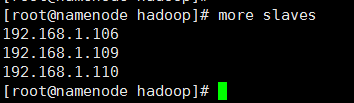
6、修改slaves文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
hadoop可以通过脚本命令在整合集群范围内启动和停止守护进程,但是,需要告诉命令hadoop集群中有哪些机器,slaves文件的作用正是如此,slaves文件中包含了机器的主机名或者是IP地址,每行代表一个机器信息,该文件列举了可以运行datanode和节点管理器(nodemanager)的机器。当然,slaves文件可以不放在/home/software/hadoop-2.7.3/etc/hadoop目录下,通过修改hadoop-env.sh配置文件中的HADOOP_SLAVES设置可以把slaves放到别的地方并赋予一个别名。
在slaves中添加如下内容:
hadoop集群主机地址
修改后效果如下:
7、分发hadoop-2.7.3
进行如上配置之后,把hadoop-2.7.3文件拷贝到其他机器上,注意,先格式化namenode之后再拷贝。
· ①、格式化hadoop:进入到hadoop-2.7.3文件下,及/home/software/hadoop-2.7.3路径下,输入命令:bin/hadoop namenode -format,等待格式化完成,格式化完成之后,在屏幕上打印出来的最后几行,可以看到has been successfully formatted代表格式化成功:

②、分发hadoop-2.7.3文件到其他机器上:使用scp -r hadoop-2.7.3 192.168.1.109:/home/software、scp -r hadoop-2.7.3 192.168.1.110:/home/software命令把hadoop-2.7.3文件拷贝到192.168.1.109和192.168.1.110机器上的/home/software路径下。
8、 启动服务
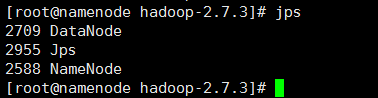
①、启动hdfs服务:在namenode主机上,进入/home/software/hadoop-2.7.3目录下,输入命令sbin/start-dfs.sh,等待服务启动。启动服务的过程中,会提示是否确定连接其他机器(Are you sure you want to continue connecting (yes/no)?),输入yes即可。启动成功之后,输入jps命令可以看到启动了NameNode和DataNode守护进程;其他两台机器上分别启动了DataNode,SecondaryNameNode、DataNode。
②、启动yarn服务:启动yarn服务需要在192.168.1.109机器上启动,因为在yarn-site.xml配置文件中,配置了yarn的服务地址为192.168.1.109。进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/start-yarn.sh,等待服务启动。
③、启动jobhistory:在192.168.1.106机器上启动jobhistory,进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/mr-jobhistory-daemon.sh start historyserver,等待服务启动。
④、启动proxyserver防护进程:在192.168.1.109机器上启动proxyserver,进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/yarn-daemon.sh start proxyserver,等待服务启动。
9、通过web界面查看hdfs和yarn
①、在浏览器输入地址:192.168.1.106:50070,能看到如下hdfs web界面:
②、在浏览器输入地址:192.168.1.109:8088,能看到如下yarn web界面:
十、结语
至此,hadoop集群模式安装并配置成功,可以在该集群环境上部署hadoop的应用,比如hive、hue、impala等应用,使hadoop投入工作。但是,此时的集群并不健壮,还需要进一步配置hadoop。在接下来的博文中会详细记录。
大数据Hadoop-1的更多相关文章
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- [转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别 https://www.cnblogs.com/adnb34g/p/9233906.html Posted on 2018-06-27 14:43 左手中倒影 阅 ...
随机推荐
- Python语言与其他语言对比
python作为一门高级编程语言,它的诞生虽然很偶然,但是它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的优缺点对比: 一:简介 1.Python 优势:简单易学,能够把用其他语言制 ...
- 01 shell编程规范与变量
前言: 大家对shell脚本应该都不算陌生了,如果突然问你什么是shell脚本?是干什么用的?由什么组成以及怎么使用?变量的概念是什么?作用范围是什么?变量间的算术运算怎么表示?你能很容易答出来吗 本 ...
- HTML5—— 你肯定会用到的新知识
HTML5 简介 语义化标签 新增结构标签 表单 多媒体 HTML5 简介 XML是更加严格的语言 是HTML和XHTML的结合 语义化标签 新增的语义化标签 header nav section a ...
- 微信小程序引用iconfont图标字体解决方案;
1)首先,登录阿里巴巴iconfont.cn 2)新建项目 3)点击icon收藏 4)加入到test项目中 5)下载到本地解压 6)生成代码 7)复制iconfont.css到xxx.wx ...
- Java 使用Apache POI读取和写入Excel表格
1,引入所用的包 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxm ...
- laravel路由组+中间件
在rotues中的web.php
- linux中安装node
1.去官网下载和自己系统匹配的文件: 英文网址:https://nodejs.org/en/download/ 中文网址:http://nodejs.cn/download/ 通过 uname -a ...
- MyBatis实现拦截器分页功能
1.原理 在mybatis使用拦截器(interceptor),截获所执行方法的sql语句与参数. (1)修改sql的查询结果:将原sql改为查询count(*) 也就是条数 (2)将语句sql进行拼 ...
- Ubuntu设置代理服务器
由于公司网络的原因,apache的网站访问不了,对于需要经常访问apache网站查看文档的我,最近想了一种方法,在自己的阿里云服务器上搭建一个代理服务器.经过查资料,最终决定使用TinyProxy. ...
- go学习笔记-结构体
结构体 结构体是由一系列具有相同类型或不同类型的数据构成的数据集合 定义 格式 type struct_variable_type struct { member definition; member ...