深度学习:Keras入门(一)之基础篇(转)
转自http://www.cnblogs.com/lc1217/p/7132364.html
1.关于Keras
1)简介
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。
Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
a)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
b)支持CNN和RNN,或二者的结合
c)无缝CPU和GPU切换
2)设计原则
a)用户友好:Keras是为人类而不是天顶星人设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
b)模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
c)易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
d)与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
2.Keras的模块结构
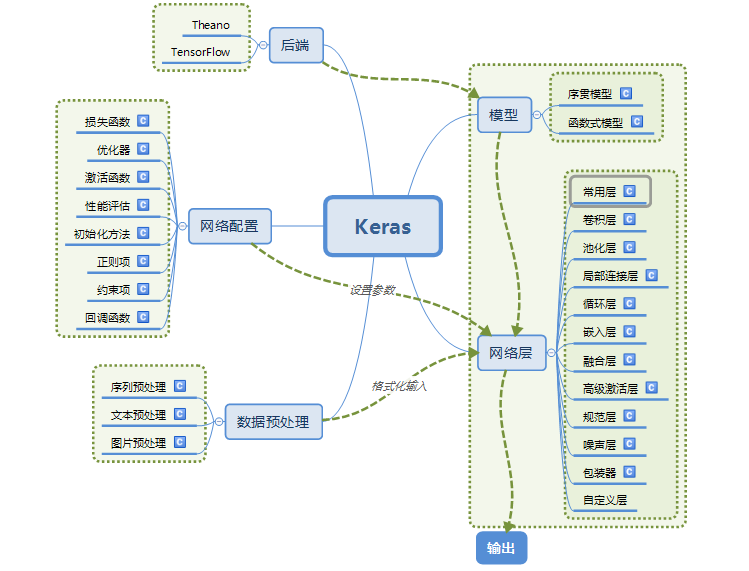
3.使用Keras搭建一个神经网络
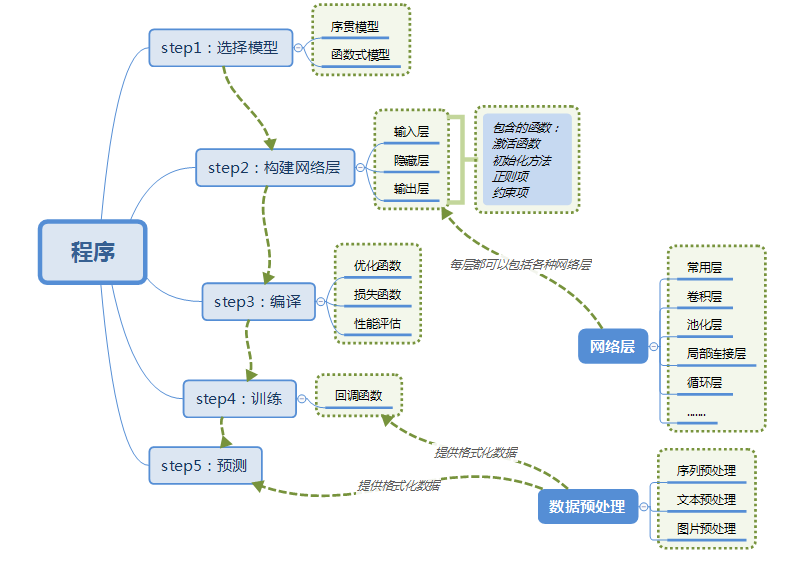
4.主要概念
1)符号计算
Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow,都是一个“符号式”的库。符号计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。
符号计算也叫数据流图,其过程如下(gif图不好打开,所以用了静态图,数据是按图中黑色带箭头的线流动的):
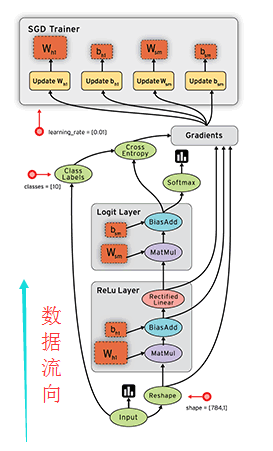
2)张量
张量(tensor),可以看作是向量、矩阵的自然推广,用来表示广泛的数据类型。张量的阶数也叫维度。
0阶张量,即标量,是一个数。
1阶张量,即向量,一组有序排列的数
2阶张量,即矩阵,一组向量有序的排列起来
3阶张量,即立方体,一组矩阵上下排列起来
4阶张量......
依次类推
重点:关于维度的理解
假如有一个10长度的列表,那么我们横向看有10个数字,也可以叫做10维度,纵向看只能看到1个数字,那么就叫1维度。注意这个区别有助于理解Keras或者神经网络中计算时出现的维度问题。
3)数据格式(data_format)
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
下面举例说明两种模式的区别:
对于100张RGB3通道的16×32(高为16宽为32)彩色图,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的区别就是表示通道个数3的位置不一样。
4)模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
5.第一个示例
这里也采用介绍神经网络时常用的一个例子:手写数字的识别。
在写代码之前,基于这个例子介绍一些概念,方便大家理解。
PS:可能是版本差异的问题,官网中的参数和示例中的参数是不一样的,官网中给出的参数少,并且有些参数支持,有些不支持。所以此例子去掉了不支持的参数,并且只介绍本例中用到的参数。
1)Dense(500,input_shape=(784,))
a)Dense层属于网络层-->常用层中的一个层
b) 500表示输出的维度,完整的输出表示:(*,500):即输出任意个500维的数据流。但是在参数中只写维度就可以了,比较具体输出多少个是有输入确定的。换个说法,Dense的输出其实是个N×500的矩阵。
c)input_shape(784,) 表示输入维度是784(28×28,后面具体介绍为什么),完整的输入表示:(*,784):即输入N个784维度的数据
2)Activation('tanh')
a)Activation:激活层
b)'tanh' :激活函数
3)Dropout(0.5)
在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,防止过拟合。
4)数据集
数据集包括60000张28×28的训练集和10000张28×28的测试集及其对应的目标数字。如果完全按照上述数据格式表述,以tensorflow作为后端应该是(60000,28,28,3),因为示例中采用了mnist.load_data()获取数据集,所以已经判断使用了tensorflow作为后端,因此数据集就变成了(60000,28,28),那么input_shape(784,)应该是input_shape(28,28,)才对,但是在这个示例中这么写是不对的,需要转换成(60000,784),才可以。为什么需要转换呢?
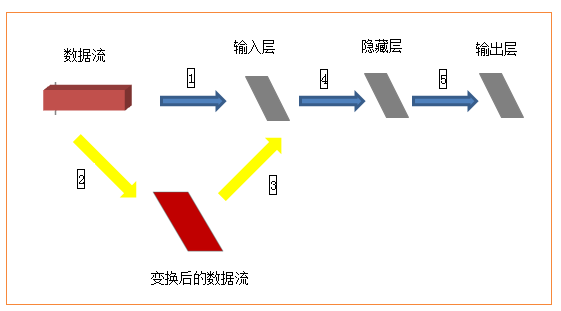
如上图,训练集(60000,28,28)作为输入,就相当于一个立方体,而输入层从当前角度看就是一个平面,立方体的数据流怎么进入平面的输入层进行计算呢?所以需要进行黄色箭头所示的变换,然后才进入输入层进行后续计算。至于从28*28变换成784之后输入层如何处理,就不需要我们关心了。(喜欢钻研的同学可以去研究下源代码)。
并且,Keras中输入多为(nb_samples, input_dim)的形式:即(样本数量,输入维度)。
- from keras.models import Sequential
- from keras.layers.core import Dense, Dropout, Activation
- from keras.optimizers import SGD
- from keras.datasets import mnist
- import numpy
- '''
- 第一步:选择模型
- '''
- model = Sequential()
- '''
- 第二步:构建网络层
- '''
- model.add(Dense(,input_shape=(,))) # 输入层,*=
- model.add(Activation('tanh')) # 激活函数是tanh
- model.add(Dropout(0.5)) # 采用50%的dropout
- model.add(Dense()) # 隐藏层节点500个
- model.add(Activation('tanh'))
- model.add(Dropout(0.5))
- model.add(Dense()) # 输出结果是10个类别,所以维度是10
- model.add(Activation('softmax')) # 最后一层用softmax作为激活函数
- '''
- 第三步:编译
- '''
- sgd = SGD(lr=0.01, decay=1e-, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
- model.compile(loss='categorical_crossentropy', optimizer=sgd, class_mode='categorical') # 使用交叉熵作为loss函数
- '''
- 第四步:训练
- .fit的一些参数
- batch_size:对总的样本数进行分组,每组包含的样本数量
- epochs :训练次数
- shuffle:是否把数据随机打乱之后再进行训练
- validation_split:拿出百分之多少用来做交叉验证
- verbose:屏显模式 :不输出 :输出进度 :输出每次的训练结果
- '''
- (X_train, y_train), (X_test, y_test) = mnist.load_data() # 使用Keras自带的mnist工具读取数据(第一次需要联网)
- # 由于mist的输入数据维度是(num, , ),这里需要把后面的维度直接拼起来变成784维
- X_train = X_train.reshape(X_train.shape[], X_train.shape[] * X_train.shape[])
- X_test = X_test.reshape(X_test.shape[], X_test.shape[] * X_test.shape[])
- Y_train = (numpy.arange() == y_train[:, None]).astype(int)
- Y_test = (numpy.arange() == y_test[:, None]).astype(int)
- model.fit(X_train,Y_train,batch_size=,epochs=,shuffle=True,verbose=,validation_split=0.3)
- model.evaluate(X_test, Y_test, batch_size=, verbose=)
- '''
- 第五步:输出
- '''
- print("test set")
- scores = model.evaluate(X_test,Y_test,batch_size=,verbose=)
- print("")
- print("The test loss is %f" % scores)
- result = model.predict(X_test,batch_size=,verbose=)
- result_max = numpy.argmax(result, axis = )
- test_max = numpy.argmax(Y_test, axis = )
- result_bool = numpy.equal(result_max, test_max)
- true_num = numpy.sum(result_bool)
- print("")
- print("The accuracy of the model is %f" % (true_num/len(result_bool)))
深度学习:Keras入门(一)之基础篇(转)的更多相关文章
- 深度学习:Keras入门(一)之基础篇
1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深度学习框架. Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结 ...
- 深度学习:Keras入门(一)之基础篇【转】
本文转载自:http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorfl ...
- 『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言 深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内 ...
- Java入门到精通——基础篇之多线程实现简单的PV操作的进程同步
Java入门到精通——基础篇之多线程实现简单的PV操作的进程同步 一.概述 PV操作是对信号量进行的操作. 进程同步是指在并发进程之间存在一种制约关系,一个进程的执行依赖另一个进程的消 ...
- Tensorflow深度学习之十二:基础图像处理之二
Tensorflow深度学习之十二:基础图像处理之二 from:https://blog.csdn.net/davincil/article/details/76598474 首先放出原始图像: ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
- 深度学习Keras框架笔记之TimeDistributedDense类
深度学习Keras框架笔记之TimeDistributedDense类使用方法笔记 例: keras.layers.core.TimeDistributedDense(output_dim,init= ...
- 深度学习Keras框架笔记之Dense类(标准的一维全连接层)
深度学习Keras框架笔记之Dense类(标准的一维全连接层) 例: keras.layers.core.Dense(output_dim,init='glorot_uniform', activat ...
- (转)Deep Learning深度学习相关入门文章汇摘
from:http://farmingyard.diandian.com/post/2013-04-07/40049536511 来源:十一城 http://elevencitys.com/?p=18 ...
随机推荐
- 用gradle把springboot项目打包成jar
``` 用gradle把springboot项目打包成jar ```### build.gradle 中添加 buildscript { repositories { mavenLocal() mav ...
- php私有成员private的程序题目
class base { private $member; function __construct() { echo __METHOD__ . "(begin)\n"; $thi ...
- linux学习之缓存机制
linux中的缓存机制 在Linux系统中,为了提高文件系统性能,内核利用一部分物理内存分配出缓冲区,用于缓存系统操作和数据文件,当内核收到读写的请求时,内核先去缓存区找是否有请求的数据,有就直接返回 ...
- linux挂载远程windows服务器上的ISO,给内网的服务器安装软件
原文: http://blog.csdn.net/chagaostu/article/details/45195817 给内网的服务器安装软件 直接用yum install XXX的话,会告知找不到源 ...
- eclipse中mat插件使用
http://smallnetvisitor.iteye.com/blog/1826434 User.java class User { private String id; private Stri ...
- centos6 找不到 phpize
安装php-devel yum install php-devel.i686
- Emoji表情图标在iOS与PHP之间通信及MySQL存储
在某个 iOS 项目中,需要一个服务器来保存一些用户数据,例如用户信息.评论等,我们的服务器端使用了 PHP+MySQL 的搭配.在测试过程中我们发现,用户在 iOS 端里输入了 Emoji 表情提交 ...
- Git使用技巧(2)-- 基本操作
常用 Git 命令清单 作者: 阮一峰 编辑更新:shifu204 日期: 2016年9月 1日 我每天使用 Git ,但是很多命令记不住. 一般来说,日常使用只要记住下图6个命令,就可以了.但是熟练 ...
- Java HashMap中在resize()时候的rehash,即再哈希法的理解
HashMap的扩容机制---resize() 虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的. 什么时候扩容:当向容器添加元素的时候,会判断当前 ...
- 【转】Junit初体验
Junit是用来做测试的,无论是单元测试,还是接口测试,都可以通过调用Junit来验证被调用方法的正确性.当然,要验证一个方法的正确性,还可以采用main方法,通过输出每一个result,人为比对其正 ...