flink学习笔记-split & select(拆分流)
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
split
1.DataStream → SplitStream
2.按照指定标准将指定的DataStream拆分成多个流用SplitStream来表示
select
1.SplitStream → DataStream
2.跟split搭配使用,从SplitStream中选择一个或多个流
案例:
public class TestSplitAndSelect {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input=env.generateSequence(0,10);
SplitStream<Long> splitStream = input.split(new OutputSelector<Long>() {
@Override
public Iterable<String> select(Long value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});
//splitStream.print();
DataStream<Long> even = splitStream.select("even");
DataStream<Long> odd = splitStream.select("odd");
DataStream<Long> all = splitStream.select("even","odd");
//even.print();
odd.print();
//all.print();
env.execute();
}
}
1.12 project
含义:从Tuple中选择属性的子集
限制:
1.仅限event数据类型为Tuple的DataStream
2.仅限Java API
使用场景:
ETL时删减计算过程中不需要的字段

案例:
public class TestProject {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple4<String,String,String,Integer>> input=env.fromElements(TRANSCRIPT);
DataStream<Tuple2<String, Integer>> out = input.project(1,3);
out.print();
env.execute();
}
public static final Tuple4[] TRANSCRIPT = new Tuple4[] {
Tuple4.of("class1","张三","语文",100),
Tuple4.of("class1","李四","语文",78),
Tuple4.of("class1","王五","语文",99),
Tuple4.of("class2","赵六","语文",81),
Tuple4.of("class2","钱七","语文",59),
Tuple4.of("class2","马二","语文",97)
};
}
1.13 assignTimestampsAndWatermarks
含义:提取记录中的时间戳作为Event time,主要在window操作中发挥作用,不设置默认就是ProcessingTime
限制:
只有基于event time构建window时才起作用
使用场景:
当你需要使用event time来创建window时,用来指定如何获取event的时间戳
案例:讲到window时再说
1.14 window相关Operators
放在讲解完Event Time之后在细讲
构建window
1.window
2.windowAll
window上的操作
1.Window ApplyWindow Reduce
2.Window Fold
3.Aggregations on windows(sum、min、max、minBy、maxBy)
4.Window Join
5.Window CoGroup
2. 物理分区
2.1回顾 Streaming DataFlow
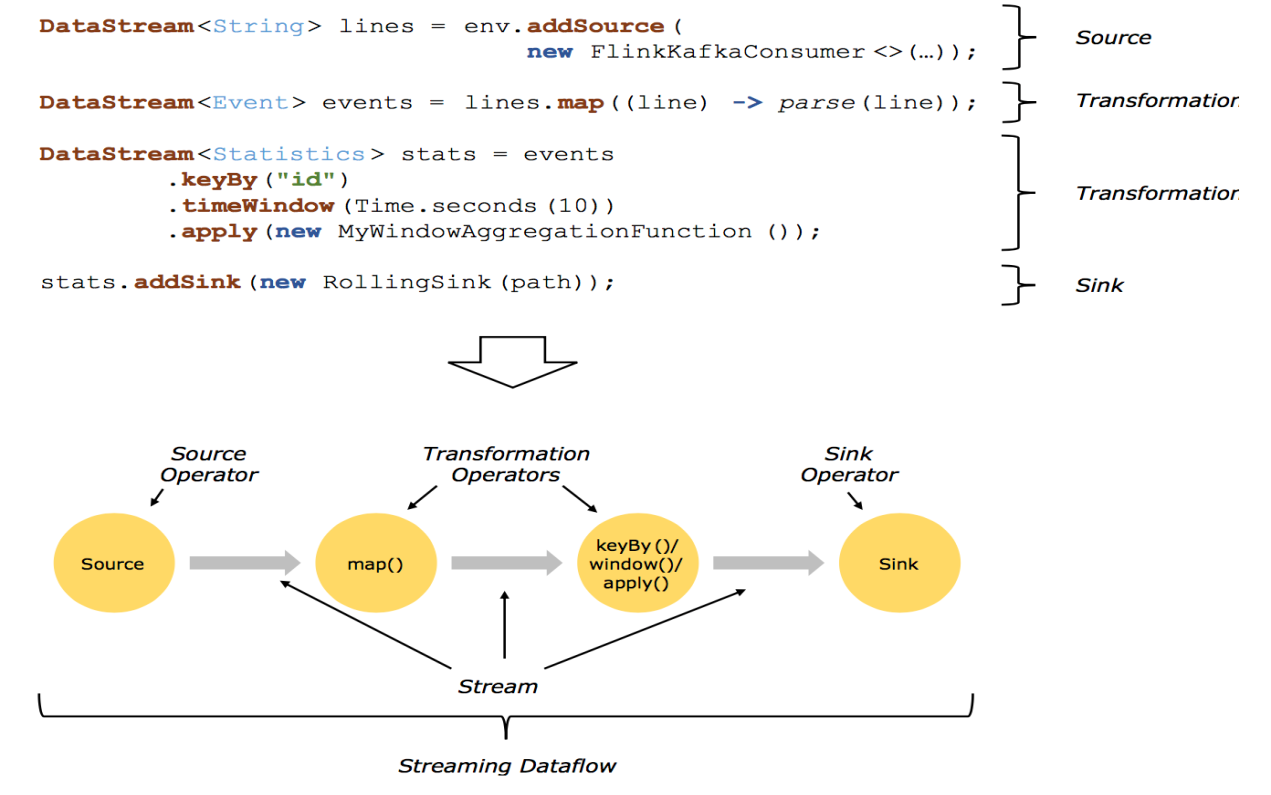
2.2并行化DataFlow
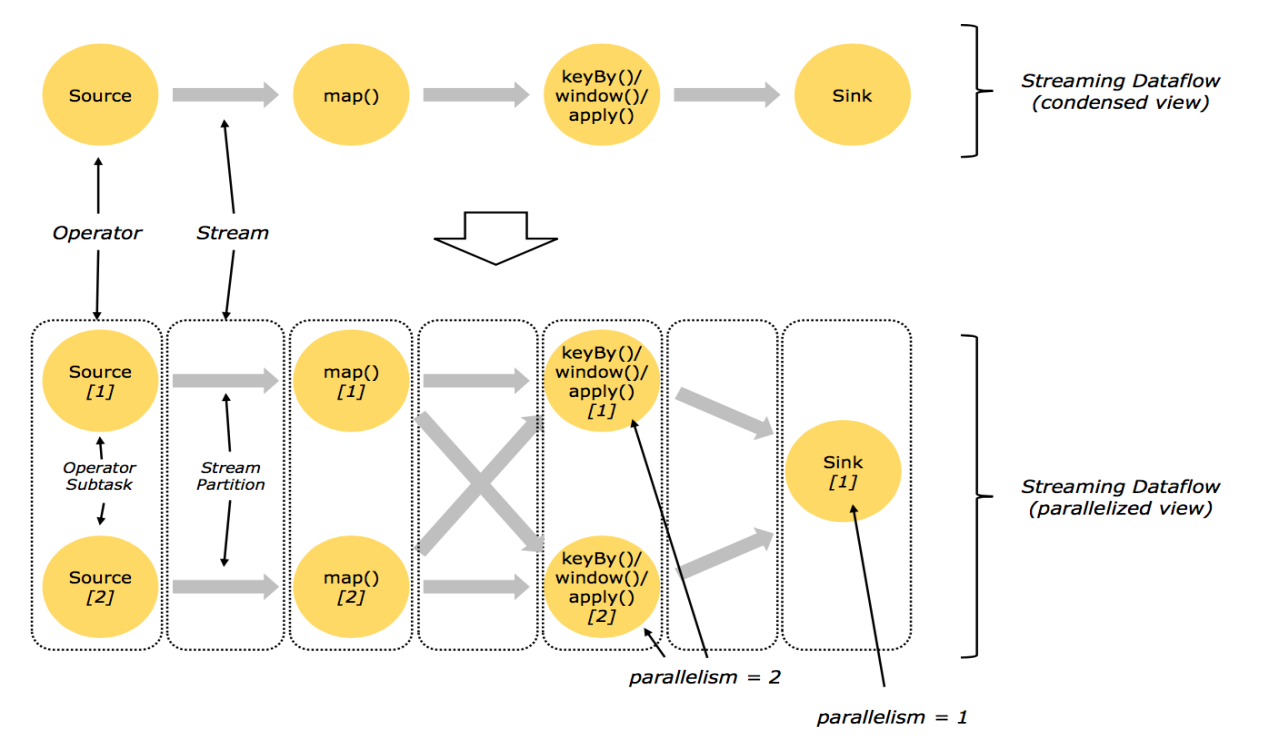
2.3算子间数据传递模式
One-to-one streams
保持元素的分区和顺序
Redistributing streams
1.改变流的分区
2.重新分区策略取决于使用的算子
a)keyBy() (re-partitions by hashing the key)
b)broadcast()
c)rebalance() (which re-partitions randomly)
2.4物理分区
能够对分区在物理上进行改变的算子如下图所示:

2.5 rescale
通过轮询调度将元素从上游的task一个子集发送到下游task的一个子集。
原理:
第一个task并行度为2,第二个task并行度为6,第三个task并行度为2。从第一个task到第二个task,Src的子集Src1 和 Map的子集Map1,2,3对应起来,Src1会以轮询调度的方式分别向Map1,2,3发送记录。从第二个task到第三个task,Map的子集1,2,3对应Sink的子集1,这三个流的元素只会发送到Sink1。假设我们每个TaskManager有三个Slot,并且我们开了SlotSharingGroup,那么通过rescale,所有的数据传输都在一个TaskManager内,不需要通过网络。

2.6任务链和资源组相关操作
startNewChain()表示从这个操作开始,新启一个新的chain。
someStream.filter(...).map(...).startNewChain().map(...)
如上一段操作,表示从map()方法开始,新启一个新的chain。
如果禁用任务链可以调用disableChaining()方法。
如果想单独设置一个SharingGroup,可以调用slotSharingGroup("name")方法。

flink学习笔记-split & select(拆分流)的更多相关文章
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-数据源(DataSource)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- linux的netstat命令详解
简介 Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Member ...
- zookeeper全局数据一致性及其典型应用(发布订阅、命名服务、帮助其他集群选举)
ZooKeeper全局数据一致性: 全局数据一致:集群中每个服务器保存一份相同的数据副本,client 无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征. 那么zookeeper集群是怎样 ...
- 使用Fuel安装openstack
一.前言 Fuel是OpenStack的开源部署和管理工具.作为OpenStack社区的开发贡献者,它为OpenStack.OpenStack相关社区项目以及OpenStack插件的部署和管理提供了直 ...
- linux su su -
本人以前一直习惯直接使用root,很少使用su,前几天才发现su与su -命令是有着本质区别的! 大部分Linux发行版的默认账户是普通用户,而更改系统文件或者执行某些命令,需要root身份才能进行, ...
- php 数据导出csv 注意问题。
总共10W数据每次下载到9.5W就停了. 加上这个就好了 ini_set('memory_limit','512M'): //脚本运行无时间限制. set_time_limit(0); 要设置一个se ...
- <c:out>标签中有一个escapeXml属性 如果为escapeXml="false",则将其中的html、xml解析出来。
<td><c:out value="${s.name}" escapeXml="false"></c:out></td ...
- Apache apachectl命令
一.简介 apachectl命令是Apache的Web服务器前端控制工具,用以启动.关闭和重新启动Web服务器进程. 二.语法 http://www.jinbuguo.com/apache/menu2 ...
- R语言的并行运算(CPU多核)
通常R语言运行都是在CPU单个核上的单线程程序.有时我们会有需求对一个向量里的元素应用相同的函数,最终再将结果合并,并行计算可以大幅节约时间. 为了支持R的并行运算, parallel包已经被纳入了R ...
- Luogu 2573 [SCOI2012]滑雪
BZOJ 2753 首先可以按照题目要求的把所有的有向边建出来,然后进去广搜就可以求出第一问的解,然后考虑如何求解第二问,我们把所有搜到的边按照到达的点的高度位第一关键字,边的长度为第二关键字排序之后 ...
- unbutu下wireshark编译安装(已更新)
今天下午在ubuntu下进行编译安装wireshark,过程中出了很多错误,但最终安装成功了,这里写下自己的安装步骤和方法,有参考博文的安装编译方法,也有自己的总结和心得. 1 安装编译工具 $sud ...