review11
public byte[] getBytes()方法使用平台默认的字符编码,将当前字符串转换为一个字节数组。如
byte d[] = "Java你好".getBytes();
如果平台默认的字符编码是GB_2312,那么调用getBytes()方法等同于调用getBytes("GB2312"),但需要注意的是带参数的getBytes(String charsetName)抛出UnsupportedEncodingException异常,因此必须在try-catch语句中调用getBytes(String charsetName)。
字节数组d其长度为8,该字节数组的d[0]、d[1]、d[2]和d[3]单元分别是字符J、a、v和a的编码,d[4]和d[5]单元存放的是字符‘你’的编码(GB_2312编码中,一个汉字占2个字节),d[6]和d[7]单元存放的是字符‘好’的编码。
String类的构造方法String(byte[])用指定的字节数组构造一个字符串对象。String(byte[], int offset, int length)构造方法用指定的字节数组的一部分,即从数组起始位置offset开始去length个字节构造一个字符串对象。
代码展示如下所示:
- public class Test02 {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- byte d[] = "Java你好".getBytes();
- String s = new String(d, 6, 2);
- System.out.println(s);
- s = new String(d, 0, 6);
- System.out.println(s);
- }
- }
运行结果如下所示:

String类的构造方法String(char a[])和String(char a[], int offset, int length)分别用数组a中的全部字符和部分字符创建字符串对象。String类也提供了将字符串存放在数组中的方法:public void getChars(int start, int end, char c[], int offset)。
字符串调用getChars()方法将当前字符串中的一部分字符复制到参数c指定的数组中,将字符串中从位置start到end-1位置上的字符复制到数组c中,并从数组c的offset处开始存放这些字符。需要注意的是,必须保证数组c能够容纳下要被复制的字符。当然追求简练的话可以使用方法: public char[] toCharArray()。
正则表达式
一个正则表达式含有一些具有特殊意义字符的字符串,这些特殊字符称作为正则表达式中的元字符。比如,"\dcat"中的\\d就是有特殊意义的元字符,代表0到9中的任何一个。
字符串对象调用public boolean matches(String regex)方法可以判断当前字符串对象是否和参数regex指定的正则表达式匹配。列出部分常用的元字符如下所示:
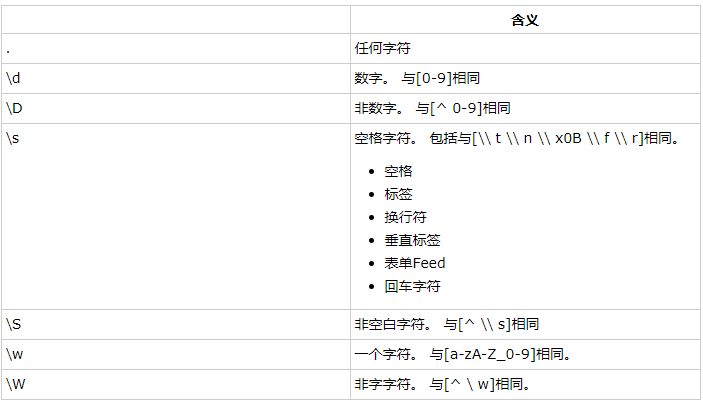
图片如下:
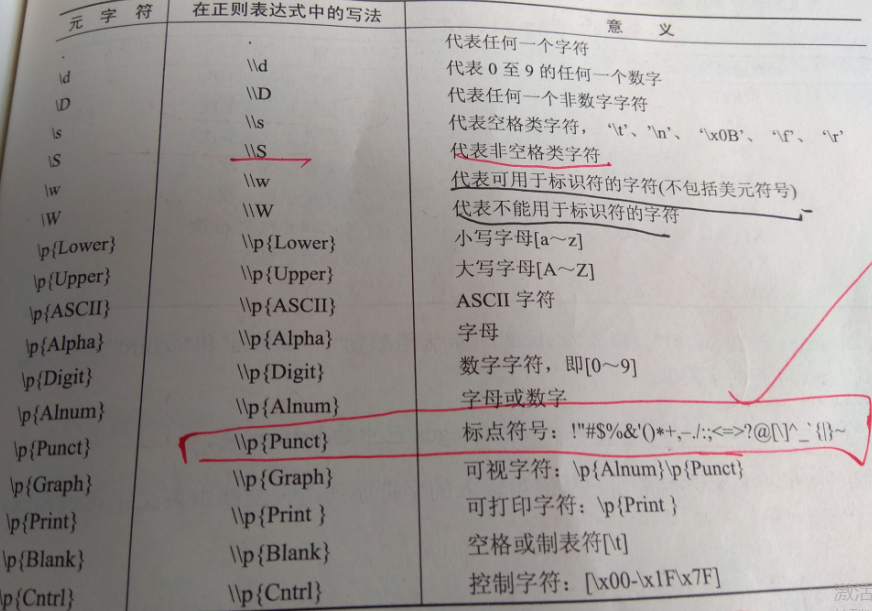
除了"."以外的元字符,在正则表达式中的写法都要在前面加上一个“\”,如元字符\d写法是“\\d”。
在正则表达式中可以用方括号括起若干个字符来表示一个元字符,该元字符代表方括号中的任何一个字符。例如regex="[159]ABC",那么"1ABC"、“5ABC”和“9ABC”都是和正则表达式regex匹配的字符串。例如,
[abc]:代表a、b、c中的任何一个;
[^abc]:代表除了a、b、c以外的任何字符;
[a-zA-Z]:代表英文字母(包括大写和小写)中的任何一个;
[a-d]:代表a至d中的任何一个。
另外,中括号里允许嵌套中括号,可以进行并、交、差运算,例如,
[a-d[m-p]]:代表a~d,或m~p中的任何字符;
[a-z&&[def]]:代表d、e或f中的任何一个(交);
[a-f&&[^bc]]:代表a、d、e、f(差)。
由于"."代表任何一个字符,所以在正则表达式中如果想使用普通意义的点字符,必须使用[.]或用\56表示普通意义的点字符。
在正则表达式中可以使用限定修饰符。比如,对于限定修饰符?,如果x代表正则表达式中的一个元字符或普通字符,那么x?就表示x出现0次或1次,例如:
regex = "hello[2468]?";
那么"hello","hello2","hello4","hello6"和"hello8"都是与正则表达式regex匹配的字符串。
常用的限定修饰符的用法如下所示:
|
带限定修饰符的模式 |
意义 |
|
X? X* X+ X{n} X{n,} X{n,m} XY X|Y |
X出现0次或1次 X出现0次或多次 X出现1次或多次 X恰好出现n次 X至少出现n次 X出现n次至m次 X的后缀是Y X或Y |
比如regex="@\\w{4}",那么"@abcd",“@天道酬勤”, "@Java“和"@bird"都是与正则表达式regex匹配的字符串。
正则表达式的细节可以在java.util.regex包中的Pattern类中查到。
matches()方法的测试结果如下所示:
- public class Testo3 {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- String regex = "[a-zA-Z]+";
- Scanner reader = new Scanner(System.in);
- String str = reader.nextLine();
- if(str.matches(regex))
- {
- System.out.println(str + "中的字符都是英文字母");
- }
- }
- }
运行结果如下所示:

字符串的替换
public String replaceAll(String regex, String replacement)方法返回一个字符串,该字符串是将当前字符中的所有和参数regex指定的正则表达式匹配的子字符串用参数replacement指定的字符串替换后的字符串,例如:
String s = "12hello567bird".replaceAll("[a-zA-Z]+","你好"};
那么s的结果就是“12你好567你好”。
replaceAll()方法返回一个字符串,但不改变当前字符串。代码展示如下所示:
- public class Test04 {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- String str = "欢迎大家访问http://www.xiaojiang.cn了解、参观公司";
- String regex = "(http://)?www[.]\\w+\56{1}\\p{Alpha}+";
- System.out.println("原字符串是:" + str + "替换后是:");
- str = str.replaceAll(regex, "***");
- System.out.println(str);
- String money = "89,235,678¥";
- System.out.println(money + "转化成数字:");
- String s = money.replaceAll("[,\\p{Sc}]" ,"");//"\\p{Sc}"可匹配任何货币符号
- long number = Long.parseLong(s);
- System.out.println(number);
- }
- }
运行结果如下所示:

字符串的分解也会用到正则表达式
String str = "1949年10月1日是中华人民共和国成立的日子";
String regex = "\\D+";
String digitWord[] = str.split(regex);
- public class Test05 {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- String str = "1949年10月1日是中华人民共和国成立的日子";
- String regex = "\\D+";
- String digitWord[] = str.split(regex);
- for(String s : digitWord)
- {
- System.out.print(s + " ");
- }
- }
- }
运行结果如下所示:

将正则表达式和split()方法结合使用情况如下所示,输入一条英语句子,分隔出每个单词。
- import java.util.Scanner;
- public class Test06 {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- System.out.println("请输入一行文本");
- Scanner reader = new Scanner(System.in);
- String str = reader.nextLine();
- String regex = "[\\s\\d\\p{Punct}]+";
- String word[] = str.split(regex);
- for(String s : word)
- {
- System.out.println(s);
- }
- }
- }
运行结果如下:

review11的更多相关文章
随机推荐
- 截取字符(pos,copy,Leftstr,MidStr,RightStr)以逗号为准把字符串拆分,判断字符串是否有数字、字母(大小写), 去掉字符串空格
1.copy(a,b,c) 举个例子: str := “123456”;str1 := Copy(Str,2,3);结果就是 str1 等于 234.Copy有3个参数,第一个是你要处理的字符串,第二 ...
- bash常见命令
pwd (Print Working Directory) 查看当前目录 cd (Change Directory) 切换目录,如 cd /etc ls (List) 查看当前目录下内容,如 ls - ...
- Mac下最好用的文本编辑器
友情提醒:图多杀猫. 曾经在Windows下一直用gVim.能够用键盘控制一切,操作起来是又快又爽,还支持一大堆插件.想怎么玩就怎么玩.后来转Mac后,也沿袭着之前的习惯.一直在用终端的Vim.偶尔会 ...
- linux 安装zip/unzip/g++/gdb/vi/vim等软件
近期公司新配置了一台64位云server.去部署的时候发现,没有安装zip/unzip压缩解压软件. 于是仅仅好自己安装这两个软件.linux最好用的还是yum. 两个指令就安装好了. 首先把软件安装 ...
- HAProxy安装及简单配置
一.HAProxy简介 代理的作用:web缓存(加速).反向代理.内容路由(根据流量及内容类型等将请求转发至特定服务器).转码器(将后端服务器的内容压缩后传输给client端).缓存的作用:减少冗余内 ...
- bolg项目
写代码要尽可能的捕获异常 模板的路径可以直接放到TEMPLATES里面的DIRS当中,TEMPLATE_DIRS可以取消掉 设置static静态文件STATICFILES_DIRS里面,这是一个元组 ...
- 通用TryParse
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Refle ...
- jQuery中的部分方法
1.empty() – jQuery 文档操作 从被选元素移除所有内容,包括所有文本和子节点. 用法:$(selector).empty(); 其中,selector可以是"#id" ...
- Linux centos开机执行JAR Shell脚本
Linux centos开机执行shell脚本 Linux centos开机执行 java jar 1.编写jar执行脚本 vim start.sh 加入如下内容(根据自己真实路径与数据进行编写) ...
- 在freescale mx6q平台上添加spi资源
1:配置管脚为SPI功能 在board-mx6q_sabresd.h的最后添加,复制被重定义 (以添加SPI2为例) <span style="font-size:18px;" ...