Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
NN工作机制
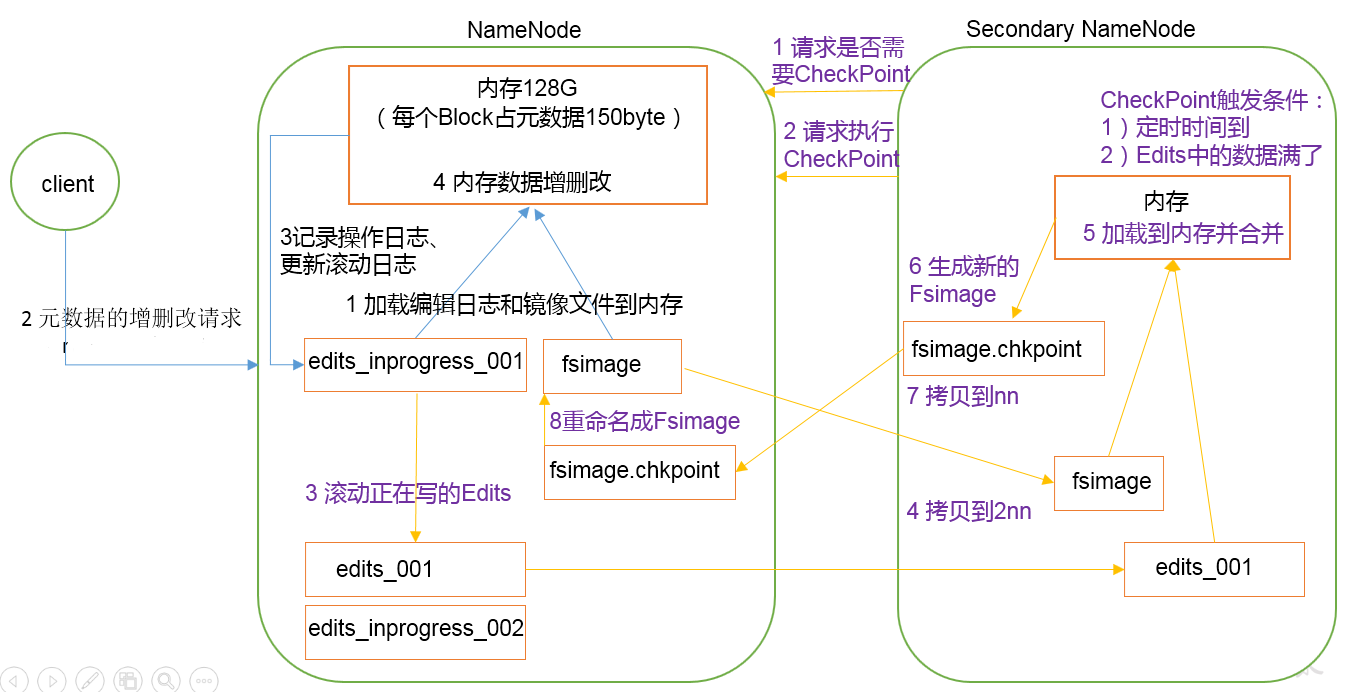
1.第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存
2.接收客户端的写操作,先记录在日志中,再对元数据进行操作
2NN工作机制
通常情况下
[hdfs-default.xml] <property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property> <property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property> <property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
通常情况下,2NN每隔一分钟检查一次,当edits日志操作次数达到1百万时或距离上次生成Fsimage一小时时,会执行一次CheckPoint.NN接收到执行CheckPonit请求时,会生成一个edits.inprogress日志文件,将后续的操作记录在这个日志里,并且将正在使用的日志重命名为edits.之后NN将未被合并的edits和FsImage拷贝到2NN.2NN将edits和Fsimage拷贝到内存中,生成新的Fsimage.checkpoint,并且拷贝到NN,NN接收到新的Fsimage.checkpoint后,重命名为Fsimage并且替换到之前的Fsimage
可以将Fsimage理解为游戏存档,游戏崩溃后,只能从存档位置再继续玩.有时候如果忘了存档,那么后果将会很凉凉.2NN就好像一个辅助软件,定时为我们存档.
但是一旦游戏崩溃,只是会进入最后的存档处,始终缺少一些~
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中
2.Edits.log和Fsimage

Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解的更多相关文章
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 H ...
- Hadoop框架:HDFS读写机制与API详解
本文源码:GitHub·点这里 || GitEE·点这里 一.读写机制 1.数据写入 客户端访问NameNode请求上传文件: NameNode检查目标文件和目录是否已经存在: NameNode响应客 ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解 hadoop有三种运行模式: 伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式. 完全分布式至少有3个节点,其中一个做master,运行名 ...
- hadoop2—namenode—HA原理详解
在hadoop1中NameNode存在一个单点故障问题,也就是说如果NameNode所在的机器发生故障,那么整个集群就将不可用(hadoop1中有个SecorndaryNameNode,但是它并不是N ...
随机推荐
- FragmentActivity的简单使用
如图是效果图 当 点击下面 不同 的按钮 进入 不同的界面 其中 要一个 主布局当做容器 , 和3个不同的 布局来对应下面的3个按钮界面 主程序的 代码和布局如下 import android.su ...
- Jmeter性能测试 入门--转载
转载: Jmeter性能测试 入门 Jmeter是一款优秀的开源测试工具, 是每个资深测试工程师,必须掌握的测试工具,熟练使用Jmeter能大大提高工作效率. 熟练使用Jmeter后, 能用Jmete ...
- 生成对抗式网络 GAN的理解
转自:https://zhuanlan.zhihu.com/p/24767059,感谢分享 生成式对抗网络(GAN)是近年来大热的深度学习模型.最近正好有空看了这方面的一些论文,跑了一个GAN的代码, ...
- Python 进程线程协程 GIL 闭包 与高阶函数(五)
Python 进程线程协程 GIL 闭包 与高阶函数(五) 1 GIL线程全局锁 线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的 ...
- # putty的使用和保存配置
putty的使用和保存配置 之前使用的xshell5,但是突然之间需要我去注册,根本无法使用.在网上看到可以到官网申请家庭和学校版本,但是我的邮箱一直没有接收到邮件.于是我放弃xshell.就拿起了之 ...
- npm 安装axios和使用增删改查
1:安装axios(建议安装淘宝镜像) npm install axios 2:项目导入 npm install --save axios vue-axios 3:页面导入 import axios ...
- codis学习
一.codis-proxy 结构 1.Topology 2.Slots 3.ServerGroup 4.Server 二.codis-proxy 启动过程 1.初始化ProxyInfo Id ...
- 读REDIS数据结构
一.DICT 主要有两个问题: 1.散列冲突,解决办法是拉链法 typedef struct dictEntry { void *key; union { void *val; uint64_t u6 ...
- html默认样式重置
几个著名的重置css goal https://meyerweb.com/eric/tools/css/reset/ 雅虎 https://yuilibrary.com/yui/docs/cssr ...
- POJ 3185 The Water Bowls 【一维开关问题 高斯消元】
任意门:http://poj.org/problem?id=3185 The Water Bowls Time Limit: 1000MS Memory Limit: 65536K Total S ...