( 转 ) mysql复合索引、普通索引总结
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。下面用几个例子对比查询条件的不同对性能影响.
create table test(
a int,
b int,
c int,
KEY a(a,b,c)
);
优: select * from test where a=10 and b>50
差: select * from test where a50
优: select * from test where order by a
差: select * from test where order by b
差: select * from test where order by c
优: select * from test where a=10 order by a
优: select * from test where a=10 order by b
差: select * from test where a=10 order by c
优: select * from test where a>10 order by a
差: select * from test where a>10 order by b
差: select * from test where a>10 order by c
优: select * from test where a=10 and b=10 order by a
优: select * from test where a=10 and b=10 order by b
优: select * from test where a=10 and b=10 order by c
优: select * from test where a=10 and b=10 order by a
优: select * from test where a=10 and b>10 order by b
差: select * from test where a=10 and b>10 order by c
索引原则
1.索引越少越好
原因:主要在修改数据时,第个索引都要进行更新,降低写速度。
2.最窄的字段放在键的左边
3.避免file sort排序,临时表和表扫描.
于是上网查了下相关的资料:(关于复合索引优化的)
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
如:建立 姓名、年龄、性别的复合索引。
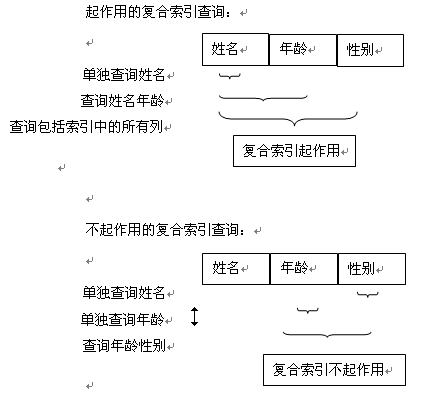
复合索引的建立原则:
如果您很可能仅对一个列多次执行搜索,则该列应该是复合索引中的第一列。如果您很可能对一个两列索引中的两个列执行单独的搜索,则应该创建另一个仅包含第二列的索引。
如上图所示,如果查询中需要对年龄和性别做查询,则应当再新建一个包含年龄和性别的复合索引。
包含多个列的主键始终会自动以复合索引的形式创建索引,其列的顺序是它们在表定义中出现的顺序,而不是在主键定义中指定的顺序。在考虑将来通过主键执行的搜索,确定哪一列应该排在最前面。
请注意,创建复合索引应当包含少数几个列,并且这些列经常在select查询里使用。在复合索引里包含太多的列不仅不会给带来太多好处。而且由于使用相当多的内存来存储复合索引的列的值,其后果是内存溢出和性能降低。
复合索引对排序的优化:
复合索引只对和索引中排序相同或相反的order by 语句优化。
在创建复合索引时,每一列都定义了升序或者是降序。如定义一个复合索引:
- CREATE INDEX idx_example
- ON table1 (col1 ASC, col2 DESC, col3 ASC)
其中 有三列分别是:col1 升序,col2 降序, col3 升序。现在如果我们执行两个查询
1:Select
col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
和索引顺序相同
2:Select
col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
和索引顺序相反
查询1,2 都可以别复合索引优化。
如果查询为:
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
排序结果和索引完全不同时,此时的查询不会被复合索引优化。
查询优化器在在where查询中的作用:
如果一个多列索引存在于 列 Col1 和 Col2 上,则以下语句:Select * from table where col1=val1 AND col2=val2 查询优化器会试图通过决定哪个索引将找到更少的行。之后用得到的索引去取值。
1. 如果存在一个多列索引,任何最左面的索引前缀能被优化器使用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
- SELECT * FROM tb WHERE col1 = val1
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2 AND col3 = val3
2. 如果列不构成索引的最左面前缀,则建立的索引将不起作用。
如:
- SELECT * FROM tb WHERE col3 = val3
- SELECT * FROM tb WHERE col2 = val2
- SELECT * FROM tb WHERE col2 = val2 and col3=val3
3. 如果一个 Like 语句的查询条件不以通配符起始则使用索引。
如:%车 或 %车% 不使用索引。
车% 使用索引。
索引的缺点:
1. 占用磁盘空间。
2. 增加了插入和删除的操作时间。一个表拥有的索引越多,插入和删除的速度越慢。如 要求快速录入的系统不宜建过多索引。
下面是一些常见的索引限制问题
1、使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select * from dept where staff_num <> 1000;
但是开发中的确需要这样的查询,难道没有解决问题的办法了吗?
有!
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
- select * from dept shere staff_num < 1000 or dept_id > 1000;
2、使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引,会在以后的blog文章里做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)
3、使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
- select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
- select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4、比较不匹配的数据类型
比较不匹配的数据类型也是难于发现的性能问题之一。
下面的例子中,dept_id是一个varchar2型的字段,在这个字段上有索引,但是下面的语句会执行全表扫描。
- select * from dept where dept_id = 900198;
这是因为oracle会自动把where子句转换成to_number(dept_id)=900198,就是3所说的情况,这样就限制了索引的使用。
把SQL语句改为如下形式就可以使用索引
- select * from dept where dept_id = '900198';
还有就是参见 老王的blog上的文章
http://hi.baidu.com/thinkinginlamp/blog/item/9940728be3986015c8fc7a85.html
http://hi.baidu.com/thinkinginlamp/blog/item/a352918fe70d96fd503d925e.html
http://blog.csdn.net/fbd2011/article/details/7341312
http://blog.csdn.net/lovelyhermione/article/details/4580866
1、普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
2、唯一索引
普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
3、主索引
在前面已经反复多次强调过:必须为主键字段创建一个索引,这个索引就是所谓的“主索引”。主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是PRIMARY而不是UNIQUE。
4、外键索引
如果为某个外键字段定义了一个外键约束条件,MySQL就会定义一个内部索引来帮助自己以最有效率的方式去管理和使用外键约束条件。
5、复合索引
索引可以覆盖多个数据列,如像INDEX(columnA,columnB)索引。这种索引的特点是MySQL可以有选择地使用一个这样的索引。如果查询操作只需要用到columnA数据列上的一个索引,就可以使用复合索引INDEX(columnA,columnB)。不过,这种用法仅适用于在复合索引中排列在前的数据列组合。比如说,INDEX(A,B,C)可以当做A或(A,B)的索引来使用,但不能当做B、C或(B,C)的索引来使用。
6、索引的长度
在为CHAR和VARCHAR类型的数据列定义索引时,可以把索引的长度限制为一个给定的字符个数(这个数字必须小于这个字段所允许的最大字符个数)。这么做的好处是可以生成一个尺寸比较小、检索速度却比较快的索引文件。在绝大多数应用里,数据库中的字符串数据大都以各种各样的名字为主,把索引的长度设置为10~15个字符已经足以把搜索范围缩小到很少的几条数据记录了。在为BLOB和TEXT类型的数据列创建索引时,必须对索引的长度做出限制;MySQL所允许的最大索引全文索引文本字段上的普通索引只能加快对出现在字段内容最前面的字符串(也就是字段内容开头的字符)进行检索操作。如果字段里存放的是由几个、甚至是多个单词构成的较大段文字,普通索引就没什么作用了。这种检索往往以的形式出现,这对MySQL来说很复杂,如果需要处理的数据量很大,响应时间就会很长。
这类场合正是全文索引(full-textindex)可以大显身手的地方。在生成这种类型的索引时,MySQL将把在文本中出现的所有单词创建为一份清单,查询操作将根据这份清单去检索有关的数据记录。全文索引即可以随数据表一同创建,也可以等日后有必要时再使用下面这条命令添加:
ALTERTABLEtablenameADDFULLTEXT(column1,column2)有了全文索引,就可以用SELECT查询命令去检索那些包含着一个或多个给定单词的数据记录了。下面是这类查询命令的基本语法:
SELECT*FROMtablename
WHEREMATCH(column1,column2)AGAINST(‘word1','word2','word3’)
上面这条命令将把column1和column2字段里有word1、word2和word3的数据记录全部查询出来。
总结:复合索引最牛C,所以你懂的。。!
原贴 : https://blog.csdn.net/csdn265/article/details/51889508
( 转 ) mysql复合索引、普通索引总结的更多相关文章
- Mysql常见四种索引的使用
提到MySQL优化,索引优化是必不可少的.其中一种优化方式 --索引优化,添加合适的索引能够让项目的并发能力和抗压能力得到明显的提升. 我们知道项目性能的瓶颈主要是在"查(select)&q ...
- DF学Mysql(三)——索引操作
概要: 数据库对象索引其实与书的目录非常相似,主要是为了提高从表中检索数据的速度. 由于数据存储在数据库表中,所以索引是创建在数据库表对象上的,由表中的一个字段或多个字段生成的键组成,这些键存储在数据 ...
- mysql建立、删除索引及使用
同步发布:http://www.yuanrengu.com/index.php/2017-01-13.html 一.索引的作用 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少 ...
- MySQL学习笔记(三)—索引
一.概述 1.基本概念 在大型数据库中,一张表中要容纳几万.几十万,甚至几百万的的数据,而当这些表与其他表连接后,所得到的新的数据数目更是要大大超出原来的表.当用户检索这么大量的数据时,经 ...
- MySQL中的联合索引学习教程
MySQL中的联合索引学习教程 这篇文章主要介绍了MySQL中的联合索引学习教程,其中谈到了联合索引对排序的优化等知识点,需要的朋友可以参考下 联合索引又叫复合索引.对于复合索引:Mysql从左到 ...
- mysql 最左匹配 联合索引
mysql建立多列索引(联合索引)有最左前缀的原则,即最左优先,如: 如果有一个2列的索引(col1,col2),则已经对(col1).(col1,col2)上建立了索引:如果有一个3列索引(col1 ...
- MySQL查询不使用索引汇总 + 如何优化sql语句
不使用索引原文 : http://itlab.idcquan.com/linux/MYSQL/918330.html MySQL查询不使用索引汇总 众所周知,增加索引是提高查询速度的有效途径,但是很多 ...
- 高性能mysql 第五章 索引部分总结
高性能索引 1.索引基础:索引的作用类似'目录'帮助Query来快速定位数据行. 1.1索引类型: 1.1.1 b-tree索引 b-tree(balance tree)索引:使用平衡树(非平衡二叉树 ...
- MYSQL索引类型+索引方法
MYSQL索引有四种 PRIMARY(唯一且不能为空:一张表只能有一个主键索引). INDEX(普通索引). UNIQUE(唯一性索引). FULLTEXT(全文索引:用于搜索很长一篇文章的时候,效果 ...
随机推荐
- BZOJ2819 Nim 【dfn序 + lca + 博弈论】
题目 著名游戏设计师vfleaking,最近迷上了Nim.普通的Nim游戏为:两个人进行游戏,N堆石子,每回合可以取其中某一堆的任意多个,可以取完,但不可以不取.谁不能取谁输.这个游戏是有必胜策略的. ...
- 安徽师大附中%你赛day4T2 演讲解题报告
演讲 题目背景: 众所周知,\(\mathrm{Zdrcl}\)是一名天天\(\mathrm{AK}\)的高水平选手. 作为一民长者,为了向大家讲述自己\(\mathrm{AK}\)的经验,他决定在一 ...
- Educational Codeforces Round 11 A
A. Co-prime Array time limit per test 1 second memory limit per test 256 megabytes input standard in ...
- CMDB资产管理系统开发【day26】:02-数据写入待存区
一.资产自动回报数据及个更新流程图 二.表结构注释(NewAssetApprovalZone) class NewAssetApprovalZone(models.Model): "&quo ...
- jwplayer 部署方案1
<body> <div id="my_player" data_src="http://xx.com/jwplayer/uploads/test.mp4 ...
- jQuery知识点:attr与prop的区别
做项目时遇到个莫名的问题,全选的时候仅第一次有效,再次点击全选按钮是无效了,查了查原因,看到篇很不错的文章,问题出在jquery中的attr属性上,这里做下笔记. 原文链接:http://www.cn ...
- C#网络编程基本字段---IPAddress、IPEndPoint
命名空间: using System.Net; PAddress类提供了对IP地址的转换.处理等功能.其Parse方法可将IP地址字符串转换为IPAddress实例. 如:IPAddress ip = ...
- sql 批量更新表中多字段为不同的值
,),,),rand()) select newid() ,) update tablename , FB,)) , ), FC,)) , )
- [bzoj1770][Usaco2009 Nov]lights 燈——Gauss消元法
题意 给定一个无向图,初始状态所有点均为黑,如果更改一个点,那么它和与它相邻的点全部会被更改.一个点被更改当它的颜色与之前相反. 题解 第一道Gauss消元题.所谓gauss消元,就是使用初等行列式变 ...
- 逐步实现python版wc命令
Python 如何处理管道输入输出 sys.stdin 等于打开了一个文件对象,所有输入的文件都会写入到标准输入文件中(键盘) sys.stdout 等于打来了一个文件对象,使用.write()把信息 ...