(4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫。
我们选从逻辑上来看,这种爬虫是如何工作的:

我们给定一个起点的url link ,进入页面之后提取所有的ur 链接,我们定义一个规则,根据规则(用正则表达式来限制)来提取我们想要的连接形式,然后爬取这些页面,进行一步的处理(数据提取或者其它动作),然后循环上述操作,直到停止,这个时候有一个潜在的问题,就是重复爬取,在scrapy 的框架下已经着手处理了这些问题,一般来说,对于爬取过滤的问题,通用的处理方式是建立一个地址表,在爬取之前查一下这个地址表,是否已经爬取过,如果是,则直接过滤掉。另一种就是使用现成的通用解决方案,bloom filter
本次讨论的是如何使用CrawlSpider 来进行爬取豆瓣标签下的所有小组的信息:
一,我们新建立一个类,继承自CrawlSpider
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from douban.items import GroupInfo class MySpider(CrawlSpider):
关于CrawlSpider的更多说明,请参考:http://doc.scrapy.org/en/latest/topics/spiders.html#crawlspider
二,为了完成命令行下的参数传递,我们需要在类的构造函数里面输入我们想要的参数
:

在命令行下这样使用:
scrapy crawl douban.xp --logfile=test.log -a target=%E6%96%87%E5%85%B7
这样就可以将自定义的参数传入到里面
这里特别说明最后的一行:super(MySpider, self).__init__()
我们转到定义,查看CrawlSpider 的定义:
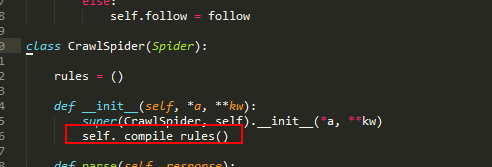
构造函数会调用私有方法编译rules变量,如果在我们自己定义的Spider里面没有调用方法,会直接报错的。
三,编写规则:
self.rules = (
Rule(LinkExtractor(allow=('/group/explore[?]start=.*?[&]tag=.*?$', ), restrict_xpaths=('//span[@class="next"]')), callback='parse_next_page',follow=True),
)
allow 定义想要提取标签样式,使用正则匹配,restrict_xpaths 严格限制这种标签的范围在指定的标签内,callback ,提取到之后的回调函数。
四,全部代码参考:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from douban.items import GroupInfo class MySpider(CrawlSpider):
name = 'douban.xp'
current = ''
allowed_domains = ['douban.com']
def __init__(self, target=None):
if self.current is not '':
target = self.current
if target is not None:
self.current = target
self.start_urls = [
'http://www.douban.com/group/explore?tag=%s' % (target)
]
self.rules = (
Rule(LinkExtractor(allow=('/group/explore[?]start=.*?[&]tag=.*?$', ), restrict_xpaths=('//span[@class="next"]')), callback='parse_next_page',follow=True),
)
#call the father base function
super(MySpider, self).__init__() def parse_next_page(self, response):
self.logger.info(msg='begin init the page %s ' % response.url)
list_item = response.xpath('//a[@class="nbg"]') #check the group is not null
if list_item is None:
self.logger.info(msg='cant select anything in selector ')
return
for a_item in list_item:
item = GroupInfo()
item['group_url'] = ''.join(a_item.xpath('@href').extract())
item['group_tag'] = self.current
item['group_name'] = ''.join(a_item.xpath('@title').extract())
yield item def parse_start_url(self, response):
self.logger.info(msg='begin init the start page %s ' % response.url)
list_item = response.xpath('//a[@class="nbg"]') #check the group is not null
if list_item is None:
self.logger.info(msg='cant select anything in selector ')
return
for a_item in list_item:
item = GroupInfo()
item['group_url'] = ''.join(a_item.xpath('@href').extract())
item['group_tag'] = self.current
item['group_name'] = ''.join(a_item.xpath('@title').extract())
yield item def parse_next_page_people(self, response):
self.logger.info('Hi, this is an the next page! %s', response.url)
五,实际运行:
scrapy crawl douban.xp --logfile=test.log -a target=%E6%96%87%E5%85%B7
实际的数据效果:

本次主要解决两个问题:
1.如何从命令行下传递参考
2.如何编写CrawlSpider
里面的演示的功能都比较有限,实际的运行中其实是需要进一步编写其它的规则,比如如何防止被ban,下一篇在简短的介绍下
(4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参的更多相关文章
- (9)分布式下的爬虫Scrapy应该如何做-关于ajax抓取的处理(一)
转载请注明出处:http://www.cnblogs.com/codefish/p/4993809.html 最近在群里频繁的被问到ajax和js的处理问题,我们都知道,现在很多的页面都是用动态加载的 ...
- (2)分布式下的爬虫Scrapy应该如何做-关于对Scrapy的反思和核心对象的介绍
本篇主要介绍对于一个爬虫框架的思考和,核心部件的介绍,以及常规的思考方法: 一,猜想 我们说的爬虫,一般至少要包含几个基本要素: 1.请求发送对象(sender,对于request的封装,防止被封) ...
- (5)分布式下的爬虫Scrapy应该如何做-windows下的redis的安装与配置
软件版本: redis-2.4.6-setup-64-bit.exe — Redis 2.4.6 Windows Setup (64-bit) 系统: win7 64bit 本篇的内容是为了给分布式下 ...
- (3)分布式下的爬虫Scrapy应该如何做-递归爬取方式,数据输出方式以及数据库链接
放假这段时间好好的思考了一下关于Scrapy的一些常用操作,主要解决了三个问题: 1.如何连续爬取 2.数据输出方式 3.数据库链接 一,如何连续爬取: 思考:要达到连续爬取,逻辑上无非从以下的方向着 ...
- scrapy框架之CrawlSpider全站自动爬取
全站数据爬取的方式 1.通过递归的方式进行深度和广度爬取全站数据,可参考相关博文(全站图片爬取),手动借助scrapy.Request模块发起请求. 2.对于一定规则网站的全站数据爬取,可以使用Cra ...
- (8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html 在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能 ...
- (1)分布式下的爬虫Scrapy应该如何做-安装
关于Scrapy的安装,网上一搜一大把,一个一个的安装说实话是有点麻烦,那有没有一键安装的?答案显然是有的,下面就是给神器的介绍: 主页:http://conda.pydata.org/docs/ 下 ...
- kvm--virsh命令行下管理虚拟机
virsh 既有命令行模式,也有交互模式,在命令行直接输入 virsh 就进入交互模式, virsh 后面跟命令参数,则是命令行模式: (1)基础操作 --- 命令行下管理虚拟机 virsh list ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
随机推荐
- HDU 3625 第一类斯特林数
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3625 题意: n个房间,房间里面放着钥匙,允许破门而入k个,拿到房间里面的钥匙后可以打开对应的门,但是 ...
- 【[SCOI2007]修车】
题目 只能做网络流度日了 当然是要对每个修车的人拆点,把每个人拆成\(n\)个点用于接收不同时刻的车 每个车\(i\)向每个时刻\(k\)的人\(j\)连边,边权为\(t[i][j]*k\)这样就是这 ...
- 【转】Mac本地生成SSH Key 的方法
1. 查看秘钥是否存在 打开终端查看是否已经存在SSH密钥:cd ~/.ssh 如果没有密钥则不会有此文件夹,有则备份删除, 也可以直接删除, 2.生成新的秘钥, 命令如下 $ssh-keygen ...
- Html5简单描述(优点与缺点)
什么是HTML5 HTML5指的是包括HTML.CSS和JavaScript在内的一套技术组合.它希望能够减少网页浏览器对于需要插件的丰富性网络应用服务(Plug-in-Based Rich Inte ...
- 【luogu P2762 太空飞行计划问题】 题解
题目链接:https://www.luogu.org/problemnew/show/P2762 算是拍照那个题的加强下. 输入真的很毒瘤.(都这么说但好像我的过了?) #include <qu ...
- 最短路问题:迪杰斯特拉算法(Dijsktra)
Dijkstra算法 1.定义概览 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Di ...
- cuda 8.0, ssd
error info and resolution: https://github.com/weiliu89/caffe/issues/38 https://github.com/weiliu89/c ...
- windows 安装pear & PHP_CodeSniffer
1. download https://pear.php.net/go-pear.phar 2. install pear(http://pear.php.net/manual/en/installa ...
- LinkedList---链表各种方法的实现
public class ListExer2 { public static void main(String[] args) { LinkList list = new LinkList(); li ...
- eclipse内存溢出解决
1 查看内存: workspace/.metadata/.plugins/org.eclipse.core.runtime/.settings/org.eclipse.ui.prefs,在里面加上SH ...