deep learning 自编码算法详细理解与代码实现(超详细)
在有监督学习中,训练样本是有类别标签的。现在假设我们只有一个没有带类别标签的训练样本集合 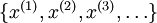 ,其中
,其中 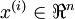 。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如
。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如 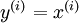 。下图是一个自编码神经网络的示例。通过训练,我们使输出
。下图是一个自编码神经网络的示例。通过训练,我们使输出 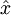 接近于输入
接近于输入  。当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张 张8*8 图像(共64个像素)的像素灰度值,于是 n=64,其隐藏层
。当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张 张8*8 图像(共64个像素)的像素灰度值,于是 n=64,其隐藏层 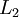 中有25个隐藏神经元。注意,输出也是64维的
中有25个隐藏神经元。注意,输出也是64维的  。由于只有25个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从25维的隐藏神经元激活度向量
。由于只有25个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从25维的隐藏神经元激活度向量  中重构出64维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出64维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入 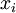 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。网络训练好以后,每一个输入对应的LayerL2
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。网络训练好以后,每一个输入对应的LayerL2  就相当于降维后的数据。(跟pca理解差不多,只是pca 是线性降维,这里因为有sigmoid非线性激活函数的原因,所以这里应该可看做是非线性的降维。)
就相当于降维后的数据。(跟pca理解差不多,只是pca 是线性降维,这里因为有sigmoid非线性激活函数的原因,所以这里应该可看做是非线性的降维。)
现在我们实验一下:我们有十张64*64的图片,十张图片如下:










我们从这十张图片中随机取出10000个小碎片,小碎片是8*8的小图片(叫做patch,或者掩模),这10000个patch就是10000个样本,我们很容易理解这10000个样本之间肯定有联系。那么接下来我们就实现这个自编码算法。
我们先得到这10000个样本(注意样本都约束在了[0.1,0.9]之间,不是说只要用神经网络就要把数据归一化把数据弄到0~1之间,而是因为这里是自编码算法,神经网络最后输出的应该是原样本,如果你样本向量的元素有大于1的数,最后输出怎么也不可能等于原样本,因为sigmoid函数最大也才是趋近于1,所以这里需要先把数据约束到[0.1,0.9]之间。如果不是自编码算法,那么是可以不用这样归一化到0~1之间的,你也不用担心如果样本的数值过大会使sigmoid函数输出都是1,可能一开始你任意取的参数的时候会产生第二层很多神经元的激活值都是1,但是经过不断的迭代,如果样本值很大,那么参数w就会很小,最后肯定不会激活值都是1,并且由于加了稀疏项,第二层神经元激活值都会很小,这些会通过训练调节w的大小还调节激活值的大小,进而调节最后输出的大小。但注意最后神经网络的输出都在(0,1)之间)。
得到样本的程序如下:
1: function patches = sampleIMAGES()
2: % sampleIMAGES
3: % Returns 10000 patches for training
4: load IMAGES; % load images from disk IMAGES是一个512*512*10的数组。
5: patchsize = 8; % we'll use 8x8 patches
6: numpatches = 10000;
7: patches = zeros(patchsize*patchsize, numpatches);%这个patches是一个矩阵
8: %每一列是一个64的列向量,是把每一个8*8的掩模变成这样一个向量,然后这个矩阵有
9: %10000个列。也就是说从10幅512*512的图像中弄出来10000个掩模。现在初始化它。
10: %% 从10幅512*512的图像中随机选出10000个8*8的掩模,然后制作 patches
11: image_size=size(IMAGES);
12: i=randi(image_size(1)-patchsize+1,1,numpatches);
13: %在开区间(0,image_size(1)-patchsize+1)之间生成一个1行10000列的向量
14: %也就是在一副512*512的图像中的行号中(不包括最后的7行,因为选了也构不成8*8的掩模了)
15: %随意选出10000个数字组成向量A。下面这行是在列号中选10000个元素的向量B,
16: %这样每一次从A和B中选出一个数a,b,然后a+7,b+7,这样a,b,a+7,b+7就组成了一个
17: %8*8的掩模。(注意是选择哪个地方的掩模之前,要先从十幅图像中选一幅图像)
18: %然后依次这么做,就得到了10000个掩模,然后把每个掩模弄成8*8的向量,
19: %依次排到 patches的每一列上就得到了 patches。
20: j=randi(image_size(2)-patchsize+1,1,numpatches);
21: k=randi(image_size(3),1,numpatches);
22: for num=1:numpatches
23: patches(:,num)=reshape(IMAGES(i(num):i(num)+patchsize-1,j(num):j(num)+patchsize-1,k(num)),1,patchsize*patchsize);
24: end
25: %% ---------------------------------------------------------------
26: % For the autoencoder to work well we need to normalize the data
27: % Specifically, since the output of the network is bounded between [0,1]
28: % (due to the sigmoid activation function), we have to make sure
29: % the range of pixel values is also bounded between [0,1]
30: patches = normalizeData(patches);
31: display_network(patches(:,randi(size(patches,2),200,1)),8);%这个是随机从那10000个patch里面选出来200个patch,看看是不是
32: %弄对了。
33: end %这个end是说明patches这个function结束了,因为下面还有一个function,在一个文件里,所以一个function完了必须写end
34:
35: %% ---------------------------------------------------------------
36: function patches = normalizeData(patches)
37: % Remove DC (mean of images).
38: patches = bsxfun(@minus, patches, mean(patches));
39: % mean(patches)对patches每一列算出一个平均值。也就是每一组样本算出一个平均值。
40: %mean(patches)是一个1*10000的行向量,这里 patches是一个64*10000的矩阵,按理说
41: %不能相减,但这里 用到了bsxfun(@minus,),那么mean(patches)会自动复制64行,
42: %然后也变成一个64*10000的矩阵,然后相减。
43:
44: % Truncate to +/-3 standard deviations and scale to -1 to 1
45: pstd = 3 * std(patches(:));%patches(:)是把这个矩阵变成一个向量。然后std,也就是
46: %求所有10000个掩模所有像素值的标准差,这里如果你不是很明白为什么要把所以样本一块求标准差,
47: %而不是一个样本组一个样本组的求标准差。并且还最后把所有像素的标准差*3。解释一下,以前求
48: %数据都是一个样本组一个样本组进行归一化,那是把数据进行归一化,也就是均值为0,方差为1,但是
49: %这样并不能保证所有的数据都在[-1,1]之间,只是方差为1。但是我们知道我们把所有数据减去均值
50: %的话,那么所有数据的99.7%都会落在[-3*标准差,3*标准差]之间,所以我们只需要把剩下的0.03%的数据都
51: %置成-3*标准差或3*标准差即可。这样所有数据都在[-3*标准差,3*标准差]之间,然后我们除以
52: %3*标准差,那么素有数据都会在[-1,1]之间了。注意这里是将所有数据一块处理,而不需要一组一组样本处理,
53: %因为这里并不需要处理后的每个样本满足标准正态分布:均值为0,方差为1那种关系,也不可能满足,所以
54: %数据一块处理即可。
55: patches = max(min(patches, pstd), -pstd) / pstd;
56: %min(patches, pstd)意思是patches这个矩阵中元素如果大于pstd,那么这个元素就是prsd。
57: %也就是上限是pstd,然后这里再max,也就是矩阵元素的下限是-petd。
58:
59: % Rescale from [-1,1] to [0.1,0.9]
60: patches = (patches + 1) * 0.4 + 0.1;
61: end
随机选出200个样本/pitch(也就是从那10幅图像中随机取出的8*8的小碎片)可以看一下:

接下来要做的就是求出cost function函数,那么这里的cost function是什么那?我们已经从上一节中知道cost function(加了L2正则项):

那么我们通过梯度下降法就可以得到收敛的参数。那么关键就是求cost function的偏导数。
并且我们知道代价函数 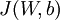 对每一个参数的偏导数可通过如下公式求:
对每一个参数的偏导数可通过如下公式求:
 ……………………………………………….………(1)
……………………………………………….………(1)
而每一个样本的 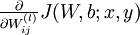 和
和 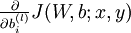 可以通过如下公式求出:
可以通过如下公式求出:
 ………………………………………………………………………………………………….(2)
………………………………………………………………………………………………….(2)
而 即为每个单元的残差。
即为每个单元的残差。 为每个单元的激活值,所以说,利用前向算法和后向算法就可以求出每个单元的激活值和残差。
为每个单元的激活值,所以说,利用前向算法和后向算法就可以求出每个单元的激活值和残差。
那么任务就完成了。
但是这里我们在刚才cost function中还想添加一项。正如我们添加的L2正则项为了防止过拟合产生一样,我们添加的这一项是为了让隐藏层的激活值大多数都在0附近。(注意L2正则项会使大部分参数在0附近,而不是激活值)这样做有什么好处呢? 我们这里定义如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,这里我们限制让隐藏层的激活值大部分都在0附近,也就是说训练好以后,当输入一个后,进行前向算法大部分的隐藏层神经元都是处于被抑制状态,只是很少的神经元被激活(你可能会说现在的输入不都限制在[0.1,0.9]之间了吗,而我们知道sigmoid函数的图像如下图,[0.1,0.9]对应的函数值不可能接近1啊?你忽略了一点,这里sigmoid输入是前一层所有神经元的线性叠加,而不是只有一个,[0.1,0.9]的值输入,所有激活函数肯定是可以接近1的。)

回答一下为什么要加这种洗属性约束呢?因为这个网络是模拟的人脑,而人脑也是一个神经元分层工作的系统,进来一个图像后,首先第一层的神经元开始工作,因为神经元被激活是需要能量的,所以只有很少的神经元被激活,工作,大部分都处于被抑制状态。
然后,这个稀疏约束项是什么呢?首先对于隐藏层的一个神经元,我们使用 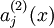 来表示在给定输入为 情况下,自编码神经网络隐藏神经元
来表示在给定输入为 情况下,自编码神经网络隐藏神经元  的激活度,隐藏神经元 的平均活跃度就是:
的激活度,隐藏神经元 的平均活跃度就是:
 ,m是样本的个数。
,m是样本的个数。
现在我们想把这个隐藏神经元 的平均激活度限制在比如 =0.2,那么我们怎么让
=0.2,那么我们怎么让 等于或接近
等于或接近 呢?我们使用这个公式:
呢?我们使用这个公式:
 作为这个隐藏神经元的惩罚因子。为什么选择这个作为惩罚项呢?我们看这个公式的图像为:
作为这个隐藏神经元的惩罚因子。为什么选择这个作为惩罚项呢?我们看这个公式的图像为:

 是自变量,
是自变量, =0.2,所以从图像可以当到
=0.2,所以从图像可以当到 为0.2附近的时候,这个惩罚项最小,而与0.2离的越远,惩罚项值越大。所以如果把这个当这个隐藏神经元的惩罚项加到cost function中,那么最小化这个cost function,就可以使
为0.2附近的时候,这个惩罚项最小,而与0.2离的越远,惩罚项值越大。所以如果把这个当这个隐藏神经元的惩罚项加到cost function中,那么最小化这个cost function,就可以使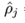 等于或接近
等于或接近 。当然我们不能只是限制隐藏层的这一个神经元,而是所有的神经元都必须约束,即:
。当然我们不能只是限制隐藏层的这一个神经元,而是所有的神经元都必须约束,即:
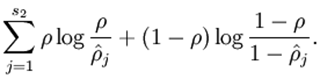
为了书写方面,我们令 ,
,
加入稀疏惩罚项以后,我们的cost function 就变成了:

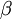 控制稀疏性惩罚因子的权重。
控制稀疏性惩罚因子的权重。
现在我们该如何对新的cost function 求各参数的偏导呢?
我们之前在没有加稀疏项时,我们是一个样本一个样本进行前向算法求各单元激活值,进行后项算法求各单元残差,然后根据公式(2),求每个样本的小cost function 对各参数的偏导,然后利用公式(1)求出大的 cost function对各参数的偏导(是在这一步对L2正则项求导的)。
加入稀疏项后,我们不改变之前的步骤和程序,我们只需要将前面在后向传播算法中计算的隐藏层的残差
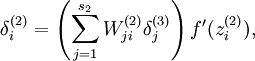
换成
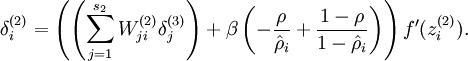
就可以了。
有一个需要注意的地方就是我们需要知道 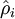 来计算这一项更新。所以在计算每个样本的后向传播之前,你需要对所有的训练样本计算一遍前向传播(注意是所有训练样本都计算一遍前向传播,因为要获取平均激活度,而不像之前没加稀疏项的时候,只需要一个样本一个样本的计算前向后向即可。),从而获取平均激活度。如果你的训练样本可以小到可以整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度
来计算这一项更新。所以在计算每个样本的后向传播之前,你需要对所有的训练样本计算一遍前向传播(注意是所有训练样本都计算一遍前向传播,因为要获取平均激活度,而不像之前没加稀疏项的时候,只需要一个样本一个样本的计算前向后向即可。),从而获取平均激活度。如果你的训练样本可以小到可以整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度 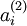 被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
下面我们来实现一个函数,函数功能:给定神经网络的结构,网络参数值,L2正则项、稀疏约束项的权重,稀疏性参数。这个函数就会给出这个神经网络的cost function的值,和cost function对各个参数的偏导。代码如下:
1: function [cost,grad] = sparseAutoencoderCost(theta, visibleSize, hiddenSize, ...
2: lambda, sparsityParam, beta, data)
3: %这个sparseAutoencoderCost函数的作用是:你给定神经网络的结构,网络参数值,L2正则项、稀疏约束项的权重,稀疏性参数。
4: %那么这个函数就会给出这个神经网络的cost function的值,和cost function对各个参数的偏导。注意这个函数不优化各参数的
5: %值,那个是优化minfun的活,这里是你给定这些参数,然后给出cost function 和偏导。如果你用优化算法比如梯度下降法优化参数
6: %时,每一次迭代,你都要通过给出当下的参数,然后通过这个函数得到偏导,然后利用优化算法得到新的参数值,再带入这个函数
7: %得到偏导,不停迭代,直到收敛。
8: %注意visibleSize 应该是data的行数,既然data矩阵有了,就应该不需要再输入visibleSize了,确实
9: %是这样,但是这里因为需要使用 visibleSize这个量,所以就又给出了一遍。你输入的visibleSize要保证等于
10: %size(data,1)。
11: % visibleSize: the number of input units (probably 64)
12: % 输入层神经元个数,不包括始终为1的偏置节点
13: % hiddenSize: the number of hidden units (probably 25) 这里神经元网络隐藏层是1层,
14: %hiddenSize是这层神经元的个数,同样不包括始终为1的偏置节点
15: % lambda: weight decay parameter L2正则项权重系数
16: % sparsityParam: 就是稀疏性参数,一个标量,一般取为0.2等等
17: % beta: weight of sparsity penalty term 稀疏项权重系数
18: % data: Our 64x10000 matrix containing the training data. So, data(:,i) is
19: % the i-th training example. 样本数据
20: % The input theta is a vector (because minFunc expects the parameters to be a vector).
21: % We first convert theta to the (W1, W2, b1, b2) matrix/vector format, so that this
22: % follows the notation convention of the lecture notes. W1指第一层的参数W2第二层参数
23: %输入的theta是个向量,向量元素的个数是神经元网络所有参数的个数。在这里是按这个顺序给参数的,theta的前
25: %hiddenSize*visibleSize是神经网络第一层和W有关的参数,如果W下标的编号和
26: %http://www.cnblogs.com/happylion/p/4193527.html第一个图中的w下标的编号一样,再结合下面reshape“按列”
27: %进行重组成矩阵的该函数特性,这里把theta向量的前hiddenSize个元素给了W1矩阵的第一列,而W1矩阵的第一列各元素的含义是
28: %输入层第一个神经元分别对应第二层隐藏层的各单元(不包括第二层偏置节点)的参数。W1矩阵的列数就是输入层神经元的个数
31: W1 = reshape(theta(1:hiddenSize*visibleSize), hiddenSize, visibleSize);%W1是一个hiddenSize*visibleSize的矩阵
32: W2 = reshape(theta(hiddenSize*visibleSize+1:2*hiddenSize*visibleSize), visibleSize, hiddenSize);
%因为这个神经网络是稀疏编码,所以输出层的神经元个数和输入相同,所以W1和为W2参数个数相同
33: b1 = theta(2*hiddenSize*visibleSize+1:2*hiddenSize*visibleSize+hiddenSize);
34: b2 = theta(2*hiddenSize*visibleSize+hiddenSize+1:end);
35: %注意这里不是对神经网络的参数初始化,这里的参数都是在每一次迭代中特定给出的,每一次迭代不能每次都进行初始化,
%只有第一次进行初始化。这里只是把给定的特定参数分配给网络
38: % Cost and gradient variables (your code needs to compute these values).
39: % Here, we initialize them to zeros.
40: cost = 0;
41: W1grad = zeros(size(W1)); %W1grad 也是一个矩阵,跟W1的行列数是一样的。里面的元素与神经网络里面的参数对应的情况和W1
42: %里元素与神经网络参数对应的情况是一样的。第一列各元素的含义是cost function 对输入层第一个神经元分别对应第二层隐藏层的
43: %各单元(不包括第二层偏置节点)的参数的偏导。
44: W2grad = zeros(size(W2));
45: b1grad = zeros(size(b1));
46: b2grad = zeros(size(b2));
47:
48: %% 求cost function 对各参数的偏导数
49: % Instructions: Compute the cost/optimization objective J_sparse(W,b) for the Sparse Autoencoder,
50: % and the corresponding gradients W1grad, W2grad, b1grad, b2grad.
51: %
52: % W1grad, W2grad, b1grad and b2grad should be computed using backpropagation.
53: % Note that W1grad has the same dimensions as W1, b1grad has the same dimensions
54: % as b1, etc. Your code should set W1grad to be the partial derivative of J_sparse(W,b) with
55: % respect to W1. I.e., W1grad(i,j) should be the partial derivative of J_sparse(W,b)
56: % with respect to the input parameter W1(i,j). Thus, W1grad should be equal to the term
57: % [(1/m) \Delta W^{(1)} + \lambda W^{(1)}] in the last block of pseudo-code in Section 2.2
58: % of the lecture notes (and similarly for W2grad, b1grad, b2grad).
59: %
60: % Stated differently, if we were using batch gradient descent to optimize the parameters,
61: % the gradient descent update to W1 would be W1 := W1 - alpha * W1grad, and similarly for W2, b1, b2.
62: %
63: %1.forward propagation
64: data_size=size(data);
65: biasPara_1=repmat(b1,1,data_size(2));%b1是第1层(输入层)总是1的那个偏置节点
66: %与第二层各单元(不包括第二层偏置节点)对应的各个参数,b1这个向量元素的个数是第二层单元数-1个第二层偏置节点数
67: %所以这里的biasPara_1这个矩阵是hiddenSize*样本个数的矩阵,并且矩阵每一列都是一样的。为什么要这么做,复制那么多列,
68: %因为这里是所有样本一块处理的,不是一个样本一个样本的处理。因为data也是所有样本的数据,所以,你就能看出来下面的
69: %W1*data+biasPara_1,所有样本是一块处理的:W1*data得到的矩阵第一列第一个元素是第一个样本各子元素在第二层
70: %第一个元素上的线性叠加,所以还要加上b1的第1个元素;W1*data得到的矩阵第一列第2个元素是第一个样本各子元素在第2层
71: %第1个元素上的线性叠加,所以还要加上b1的第2个元素;以此类推得到完整第一列,就是处理完第一个样本,然后处理第二列,
72: %就是处理第二个样本,以此类推..所以W1*data+biasPara_1这个矩阵第m列第n行的元素就是第m个样本,对第二层第n单元
73: %(不包括偏置节点,因为偏置节点不需要什么sigmoid函数,也不需要有输入,它始终是1,可以认为激活值始终是1)
74: %的sigmoid函数的输入Z。
75: biasPara_2=repmat(b2,1,data_size(2));
76: active_value2=sigmoid(W1*data+biasPara_1);
77: active_value3=sigmoid(W2*active_value2+biasPara_2);
78: %W2*active_value2+biasPara_2这个矩阵第m列第n行的元素就是第m个样本,对第3层第n单元的sigmoid函数的输入Z。
79: %active_value2这个矩阵每一列是每一个样本前向算法中第二层各单元的激活值(不包括偏置节点,因为偏置节点
80: %相当于激活值始终为1)。
81: %active_value3是第三层各单元的激活值。
82:
83: %2.computing cost function
84: ave_square=sum(sum((active_value3-data).^2)./2)/data_size(2);
85: %这是cost
86: %function的均方误差项,因为这里data的label还相当于是data(自编码),首先说一下一个矩阵“.^2”是矩阵里每个元素都平方。
87: %sum((active_value3-data).^2)得到的是一个行向量,每一个元素是每一个样本通过神经网络得到的输出层单元激活值(是一个向量)
88: %与每一个样本的label(也就是它自身)(也是一个向量)的误差平方(计算是通过两个向量对应的各个元素分别对应做差然后平方和)
89: %然后sum((active_value3-data).^2)得到的这个向量各元素都乘以1/2(也就是每个样本的误差平方乘以一个系数1/2),然后再sum
90: %一下,就是把所有样本的误差平方累加起来,最后再除以样本的个数data_size(2),就是cost function的均方误差项。
91: weight_decay=lambda/2*(sum(sum(W1.^2))+sum(sum(W2.^2)));
92: %这是const function 中的L2正则项
93: active_average=sum(active_value2,2)./data_size(2);%sum(active_value2,2)这里是active_value2按行相加,也就是对隐藏层每一个
94: %神经元,将所有样本关于这个神经元的激活值累加起来。sum(,2)是按行相加,如果只是sum(),就是默认的按列相加。matlab中
95: %很多函数默认的都是按列进行某种操作。因此这里得到的是一个列向量。然后点除data_size(2)就是向量每个元素都除以样本个数
96: %这样得到的列向量active_average的每个元素就是隐藏层每一个神经元对于所有样本的平均激活度。
97: p_para=repmat(sparsityParam,hiddenSize,1);
98: %因为下面那行代码中有p_para./active_average所以要弄成和active_average一样size的列向量,才能与active_average里的元素点除。
99: sparsity=beta.*sum(p_para.*log(p_para./active_average)+(1-p_para).*log((1-p_para)./(1-active_average)));
100: %这是稀疏项
101: cost=ave_square+weight_decay+sparsity;%cost function就完成了。
102:
103: %求残差
104: delta3=(active_value3-data).*(active_value3).*(1-active_value3);
105: %首先说博客中求残差的公式是按一个样本的一个神经元来定位的,而这里用matlab求的时候是所有的样本(一列是一个样本),
106: %一层所有的神经元一块运算的,这是matlab 矩阵运算的特点,避免了for循环。所以这里跟公式中略有不同。虽然是一起运算的,
107: %但每一个神经元残差的计算还是要根据公式来,所以这里用到了点乘:矩阵对应元素之间运算。
108: %公式在http://www.cnblogs.com/happylion/p/4193527.html可以看到。
109: %这里得到的delta3是一个矩阵,每一列是一个样本输入神经网络后,第三层各个神经元的残差,列数代表样本数。
110: active_average_repmat=repmat(sum(active_value2,2)./data_size(2),1,data_size(2));
111: %sum(active_value2,2)./data_size(2)就是active_average,然后repmat,因为active_average是一个列向量,再平铺
112: %data_size(2)列,那么active_average_repmat就是一个矩阵,弄成矩阵的的形式是为了后面所有样本第二层所有神经元
113: %一起运算。
114: default_sparsity=repmat(sparsityParam,hiddenSize,data_size(2));
115: %default_sparsity也是一个hiddenSize*data_size(2)矩阵,弄成这个形式也是为了下面所有样本第二层所有神经元一起的矩阵
116: %运算。
117: sparsity_penalty=beta.*(-(default_sparsity./active_average_repmat)+((1-default_sparsity)./(1-active_average_repmat)));
118: delta2=(W2'*delta3+sparsity_penalty).*((active_value2).*(1-active_value2));
119: %求第二层的残差的时候跟输出层略有不同,因为第二层是隐藏层,又因为稀疏项中是关于隐藏层的内容,所以这里把稀疏项的内容
120: %融入到残差里面。这样由残差计算偏导的公式就不用改变了。同样这里是所有样本第二层所有神经元的一起计算的矩阵计算,
121: %所以也用到了点乘,矩阵之间对应元素的运算就是博客中的公式。((active_value2).*(1-active_value2))这一项是f'(z(i))
122: %W2'*delta3得到的是一个矩阵,矩阵的每一列是一个样本输入神经网络后,第二层各个神经元的残差公式的第一项部分(可以看
123: %http://www.cnblogs.com/happylion/p/4193527.html中第二个图就会很明白了),列数代表样本数。
124:
125: %求各参数偏导
126: W2grad=delta3*active_value2'./data_size(2)+lambda.*W2;
127: %delta3*active_value2'得到的是一个矩阵,矩阵的第一个元素是所有样本对应的 小cost function
128: %对第二层的W11的偏导 的累加形成的总cost function对第二层的W11的偏导。矩阵第一行第二个元素是
129: %总cost function对第二层的W21的偏导。所以你看这里的W下标的顺序和前面的W矩阵是一样的。然后这个矩阵的元素都除以样本
130: %个数,得到的就是cost function中只有均方误差项时,对第二层各个参数的偏导。然后这个矩阵每个元素加上lambda倍的W2这个
131: %矩阵对应的元素,得到的W2grad矩阵的元素是总cost function对第二层各参数的偏导。
132: W1grad=delta2*data'./data_size(2)+lambda.*W1;
133: b2grad=sum(delta3,2)./data_size(2);%b2grad向量是总cost function对第二层偏置节点各参数的偏导
134: b1grad=sum(delta2,2)./data_size(2);
135:
136: %-------------------------------------------------------------------
137: % After computing the cost and gradient, we will convert the gradients back
138: % to a vector format (suitable for minFunc). Specifically, we will unroll
139: % your gradient matrices into a vector.
140:
141: grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)];%正好矩阵(:)这种形式变成一个向量也是按列的,正好和
142: %reshape()按列的方式一样。所以元素与网络参数对应的顺序没有变化。
143:
144: end
145:
146: %-------------------------------------------------------------------
147: % Here's an implementation of the sigmoid function, which you may find useful
148: % in your computation of the costs and the gradients. This inputs a (row or
149: % column) vector (say (z1, z2, z3)) and returns (f(z1), f(z2), f(z3)).
150: %若果x是个矩阵,也是可以的,igmoid(x)也是一个矩阵,里面的每个元素就是对应x矩阵对应的元素进行sigmoid计算。
152: function sigm = sigmoid(x)
154: sigm = 1 ./ (1 + exp(-x));
155: end
当我们得到这个神经网络的cost function 对各参数的偏导数时候,我们想知道这个求得的偏导数是不是正确,我们可以用求导的定义公式来求得,具体内容可以参考这里。具体的代码如下:
1: function numgrad = computeNumericalGradient(J, theta)
2: %% computeNumericalGradient函数的功能是:给定一个方程J(theta),给定的方式是@你想使用的方程,
3: %然后你再给一个theta的值,那么这个函数就可以利用求导定义的那个公式来求出这个J方程在theta这点的导数,如果
4: %theta是一个向量,那么就是求出J方程在theta这点所有未知量的偏导数,因此得出的结果是一个向量,以 numgrad
5: %给出。
6: numgrad = zeros(size(theta));%初始化
7: EPSILON=0.0001;
8: for i=1:size(theta) %每一个i是J方程对theta的第i个变量求偏导数。
9: theta_plus=theta;
10: theta_minu=theta;
11: theta_plus(i)=theta_plus(i)+EPSILON;%用定义公式求偏导,那么theta这点的很小的增量或减量中只有第i个
12: %变量增加或减少了EPSILON
13: theta_minu(i)=theta_minu(i)-EPSILON;
14: numgrad(i)=(J(theta_plus)-J(theta_minu))/(2*EPSILON);
15: end
16: end
现在我们就检验一下:
1: %% 当我们检查sparseAutoencoderCost函数写的对不对或这个函数得到的偏导数是不是跟导数的定义一致,
2: %我们随机给定一个theta 即可,如果这个随机给出的theta使上述两个函数的偏导数求得的一致,那么我们就认为任何theta
3: %都会使之相应的一致。并且我们不必把所有样本都拿来检验,只需要把其中的10个做为样本,把隐藏层单元弄成2,3个即可。
4: %但输入层单元个数不能改变,因为它等于样本矩阵的行数。最后我们用norm(numgrad-grad)/norm(numgrad+grad)
5: %进行判定numgrad、grad两个向量的相似程度,如果结果 <1e-9,那么就说他们相似到我们希望的程度了,即检查结果满意!
6: visibleSize = 8*8;
7: hiddenSize = 3;
8: sparsityParam = 0.01;
9: lambda = 0.0001;
10: beta = 3;
11: patches = sampleIMAGES;
12: theta = initializeParameters(hiddenSize, visibleSize);
13: [cost, grad] = sparseAutoencoderCost(theta, visibleSize, hiddenSize, lambda, ...
14: sparsityParam, beta, patches(:,1:10));
15: numgrad = computeNumericalGradient( @(x) sparseAutoencoderCost(x, visibleSize, ...
16: hiddenSize, lambda, ...
17: sparsityParam, beta, ...
18: patches(:,1:10)), theta);
19: disp([numgrad grad]);
20: diff = norm(numgrad-grad)/norm(numgrad+grad);
21: disp(diff);
检验结果为:3.8100e-11
所以检验满意!
下面我们要做的就是寻找最优的神经网络(隐藏层是25,不是测验时候的3个了)参数。我们要先初始化一个任意的参数向量。我们可以选定好一个优化算法,比如梯度下降法:

那么我们就将这个任意的参数向量代入sparseAutoencoderCost函数,得到这个参数向量下的cost function的值和cost function 对这个参数向量各参数的偏导数。然后利用上面的这个梯度下降公式得到新的参数向量。然后再带入sparseAutoencoderCost函数等得到新的cost function的值和cost function 对这个参数向量各参数的偏导数。不停的迭代cost function 值 不断下降,直到几乎不下降为止,那么这时候得到的参数向量就是我们要求的神经网络的参数。
我们这里不用梯度下降法,而是用一种比较流行的拟牛顿法 L-BFGS进行优化。而上面说的梯度下降法工作模式类似,这里也是依靠sparseAutoencoderCost得到的cost function的值和cost function 对这个参数向量各参数的偏导数,并且这个L-BFGS算法代码(minfun文件代码里面的一种优化算法,下载地址: minfun下载,并把它放到上面那些代的.m文件的同一文件夹)还会将cost function和偏导数加工得到更高阶的偏导数,这样收敛速度更快。
代码如下:
1: visibleSize = 8*8;
2: hiddenSize = 25;
3: sparsityParam = 0.01;
4: lambda = 0.0001;
5: beta = 3;
6: patches = sampleIMAGES;
7: theta = initializeParameters(hiddenSize, visibleSize);
8: % Use minFunc to minimize the function
9: addpath minFunc/
10: options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
11: % function. Generally, for minFunc to work, you
12: % need a function pointer with two outputs: the
13: % function value and the gradient. In our problem,
14: % sparseAutoencoderCost.m satisfies this.
15: options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
16: options.display = 'on';
17: [opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
18: visibleSize, hiddenSize, ...
19: lambda, sparsityParam, ...
20: beta, patches), ...
21: theta, options);
22: %因为每次迭代在sparseAutoencoderCost函数只需要更改参数网络,网络结构不变,所以用到了
23: %@(p) sparseAutoencoderCost(p, visibleSize, hiddenSize, lambda, sparsityParam, beta, patches), theta, options)
运行结果cost function 在0.1248 附近得到收敛,部分如图:

最后程序中的opttheta就是我们训练好的神经网络参数。
我们既然训练好了,我们就想好好我们的训练学习好了什么东西、怎么看呢?

我们之前说过,第二层神经元与第一层的关系相当于Pca一样,第二层神经元值的向量以原始的样本向量相当于降维以后的结果。只是pca是线性的,而这里因为有logistic函数,所以是非线性的降维。那么隐藏层那一层的每一个神经元 的值代表的含义是什么呢?我们仍然可以类比pca,如图所示:
的值代表的含义是什么呢?我们仍然可以类比pca,如图所示:

我们看到pca是将原来的数据在新坐标系下表示,并且把某些坐标轴去掉(把区分数据不明显的坐标轴去掉),而使数据降维的过程。所以降维后样本每一维的数据可以看成:在新的基下或新的特征下,样本在这个特征表达多少或程度多少。
所以类别一下:隐藏层那一层的每一个神经元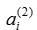 的值代表的就是在新选择的某一个特征下(因为隐藏层有25个神经元,所以新选了25个特征,然后将样本用这25个特征表示出来(应该不是线性叠加),新的数据就有25维,每一维的数值就是样本在这个特征的表达式多少。),原样本数据在这个样本表达了多少。那么我们应该如何找到这个新特征是什么呢?肯定不是
的值代表的就是在新选择的某一个特征下(因为隐藏层有25个神经元,所以新选了25个特征,然后将样本用这25个特征表示出来(应该不是线性叠加),新的数据就有25维,每一维的数值就是样本在这个特征的表达式多少。),原样本数据在这个样本表达了多少。那么我们应该如何找到这个新特征是什么呢?肯定不是 的值,因为它是样本在某个特征下的表达程度,因为样本可以用这25个特非线性性叠加起来。所以这些特征应该和原样本pitch大小相同,类似于特征量一样。那么应该怎么求呢? 做法是对下面这个方程求最大值。
的值,因为它是样本在某个特征下的表达程度,因为样本可以用这25个特非线性性叠加起来。所以这些特征应该和原样本pitch大小相同,类似于特征量一样。那么应该怎么求呢? 做法是对下面这个方程求最大值。

因为参数是已知的,如果我们求隐藏层某一个神经元的激活值求最大值,那么就可以找到使这个神经元激活的输入是多少,那么这个输入就是其中的一个特征。一般来说使其中的一个神经元激活,另外其他的就不一定激活了,因为我们已经加入了激活值的稀疏项。还有一个问题需要注意:如果你的样本xi的值都很大的话, 得到平凡解,所以必须给加约束,若假设输入有范数约束
得到平凡解,所以必须给加约束,若假设输入有范数约束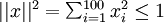 ,则令隐藏单元
,则令隐藏单元 得到最大激励的输入应由下面公式计算的像素
得到最大激励的输入应由下面公式计算的像素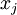 给出(共需计算100个像素,j=1,…,100):
给出(共需计算100个像素,j=1,…,100):
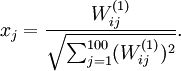
- 具体的推导过程见下一个博客
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们面前之时,那么这个特征我们就可以看到了。并且我们看到的这个图像是带有有界范数的图像。注意我们这是为了向可视化特征才给输入x加了范数约束,因为不加约束会得到平凡解,(平凡解就是说根本不用解谁都知道某个量是这个方程的解,比如AX=0,谁都知道X=0是这个方程的解,所以X=0就是平凡解)但是一般的情况你的输入样本是不需要约束这种的约束。不过样本应该也要进行归一化,把数据归一到[0,1]之间。
可视化特征的程序为:
W1 = reshape(opttheta(1:hiddenSize*visibleSize), hiddenSize, visibleSize);
display_network(W1', 12); %display_network函数中已经包括对输入加了范数约束。
那么25个特征如图所示:

我们可以看出来这25个特征都是一些“边缘”特征,为什么会是边缘特征呢?
因为人的神经系统也是分层的,第一层的神经层也是对一幅图像的边缘特征处于激活。详细并且很经典的讲解特征的是这一篇博客,可以参考这里。
参考:http://deeplearning.stanford.edu/wiki/index.php
http://www.cnblogs.com/hrlnw/archive/2013/06/08/3127162.html
http://deeplearning.stanford.edu/wiki/index.php/Exercise:Sparse_Autoencoder
deep learning 自编码算法详细理解与代码实现(超详细)的更多相关文章
- Github上传代码菜鸟超详细教程【转】
最近需要将课设代码上传到Github上,之前只是用来fork别人的代码. 这篇文章写得是windows下的使用方法. 第一步:创建Github新账户 第二步:新建仓库 第三部:填写名称,简介(可选), ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
- Transferable Joint Attribute-Identity Deep Learning for Unsupervised Person Re-Identification理解
简介:这篇文章属于跨域无监督行人再识别,不同于大部分文章它使用了属性标注.旨在于能够学习到有属性语义与有区分力的身份特征的表达空间(TJ-AIDL),并能够转移到一个没有看到过的域. 贡献: 提出了一 ...
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- 【Deep Learning】RNN的直觉理解
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- 【智能算法】粒子群算法(Particle Swarm Optimization)超详细解析+入门代码实例讲解
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 01 算法起源 粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由E ...
- 在虚拟机中安装Linux系统CentOS7详细教程!!!超详细!!!!一看就会!!!手把手教学!!!
一.CentOS的下载 CentOS是免费版,推荐在官网上直接下载.https://www.centos.org/download/ DVD ISO:普通光盘完整安装版镜像,可离线安装到计算机硬盘上, ...
- Github上传代码菜鸟超详细教程
最近需要将课设代码上传到Github上,之前只是用来fork别人的代码. 这篇文章写得是windows下的使用方法. 第一步:创建Github新账户 第二步:新建仓库 第三部:填写名称,简介(可选 ...
- 代码生成java连接数据库的所需代码(超详细)
开始学习: round 1:(一开始学习当然还是要一步一步学习的啦,哪有什么一步登天!!!) a.准备工作:1.eclipse,mysql(这两个软件肯定要的啦,不然学什么把它们连接起来) 2.加载驱 ...
随机推荐
- ShutIt:一个基于 Python 的 shell 自动化框架
ShutIt是一个易于使用的基于shell的自动化框架.它对基于python的expect库(pexpect)进行了包装.你可以把它看作是“没有痛点的expect”.它可以通过pip进行安装. Hel ...
- 博客没内容可写了怎么办?找BD!
博客写了一段时间可能会感觉没内容可以写了,或者说同一个领域的内容写多了感觉有点千篇一律,这时要考虑扩展自己的写作领域,怎么去扩展呢?利用关键词工具可以衍生很多长尾词,当然这个有点牵强,有点为优化而优化 ...
- 74LS85 比較器 【数字电路】
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/u011368821/article/details/27959219 74LS85 demo: 11 ...
- Tomcat日志备份脚本
#!/bin/bash #Author:fansik #Description:backup tomcat logs #Date:-- directory=/usr/local/tomcat/logs ...
- MySQL数据库(8)_MySQL数据库总结
sql语句规范 sql是Structured Query Language(结构化查询语言)的缩写.SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言. 在使用它时,只需要发出“做什么” ...
- formatblock 块及
有标签,执行标签替换,只是替换标签,属性不改变. 在无标签外部添加标签
- python有哪些好的学习资料或者博客?
推荐Full Stack Python 有各种python资源汇总,从基础入门到各种框架web应用开发和部署,再到高级的ORM.Docker都有.以下是Full Stack Python 上总结的一些 ...
- Loadrunder脚本篇——关联数组(参数数组)
导言 前面说过可以用关联取出服务器相关的一些动态变化的信息,前面也提过web_reg_save_param中可以设置ord=all,代表从服务器中取出的是一个数组,它试用的场景是当我访问一个发帖网站, ...
- Spring AOP 学习(一) 代理模式
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程(也叫面向方面),可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术. ...
- Linux查看某个端口+gcc动态编译
Linux下就: 1.lsof -i:端口号 2.netstat -tunlp|grep 端口号 gcc:动态编译 gcc –fpic –c file.c –o file.o gcc –shared ...