原生MapReduce开发样例
一、需求
data: 将相同名字合并为一个,并计算出平均数 tom
小明
jerry
2哈
tom
tom
小明
二、编码
1.导入jar包
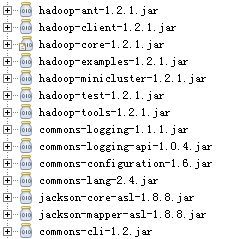
2.编码
2.1Map编写
package com.wzy.studentscore; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author:吴兆跃
* @version 创建时间:2018年6月5日 下午5:58:55
* 类说明:
*/
public class ScoreMap extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException,InterruptedException{ String line = value.toString(); //一行的数据
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n"); System.out.println("key: "+key);
System.out.println("value-line: "+line);
System.out.println("count: "+tokenizerArticle.countTokens()); while(tokenizerArticle.hasMoreTokens()){
String token = tokenizerArticle.nextToken();
System.out.println("token: "+token); StringTokenizer tokenizerLine = new StringTokenizer(token);
String strName = tokenizerLine.nextToken(); // 得到name
String strScore = tokenizerLine.nextToken(); // 得到分数 Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
context.write(name, new IntWritable(scoreInt)); }
System.out.println("context: "+context.toString());
} }
2.2Reduce编写
package com.wzy.studentscore; import java.io.IOException;
import java.util.Iterator; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* @author:吴兆跃
* @version 创建时间:2018年6月5日 下午6:50:28
* 类说明:
*/
public class ScoreReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException{ int sum = ;
int count = ;
Iterator<IntWritable> iterator = values.iterator();
while(iterator.hasNext()){
sum += iterator.next().get(); //求和
count++;
}
int average = (int)sum / count; //求平均数
context.write(key, new IntWritable(average));
} }
2.3运行类编写
package com.wzy.studentscore; import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* @author:吴兆跃
* @version 创建时间:2018年6月5日 下午6:59:29
* 类说明:
*/
public class ScoreProcess extends Configured implements Tool{ public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new ScoreProcess(), new String[]{"input","output"});
System.exit(ret);
} @Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf());
job.setJarByClass(ScoreProcess.class);
job.setJobName("score_process"); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(ScoreMap.class);
job.setCombinerClass(ScoreReduce.class);
job.setReducerClass(ScoreReduce.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); boolean success = job.waitForCompletion(true);
return success ? : ;
} }
3.打包


三、调试
1. java本地运行
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ls
input part scoreProcess.jar
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# java -jar scoreProcess.jar
Jun , :: AM org.apache.hadoop.util.NativeCodeLoader <clinit>
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Jun , :: AM org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
INFO: Total input paths to process :
Jun , :: AM org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>
WARNING: Snappy native library not loaded
Jun , :: AM org.apache.hadoop.mapred.JobClient monitorAndPrintJob
INFO: Running job: job_local1903623691_0001
Jun , :: AM org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable run
INFO: Starting task: attempt_local1903623691_0001_m_000000_0
Jun , :: AM org.apache.hadoop.mapred.LocalJobRunner$Job run
INFO: Waiting for map tasks
Jun , :: AM org.apache.hadoop.util.ProcessTree isSetsidSupported
INFO: setsid exited with exit code
Jun , :: AM org.apache.hadoop.mapred.Task initialize
INFO: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@5ddf714a
Jun , :: AM org.apache.hadoop.mapred.MapTask runNewMapper
INFO: Processing split: file:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess/input/data:+
Jun , :: AM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
INFO: io.sort.mb =
Jun , :: AM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
INFO: data buffer = /
Jun , :: AM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
INFO: record buffer = /
key:
value-line: tom
count:
token: tom
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: 小明
count:
token: 小明
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: jerry
count:
token: jerry
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: 哈2
count:
token: 哈2
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: tom
count:
token: tom
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: tom
count:
token: tom
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
key:
value-line: 小明
count:
token: 小明
context: org.apache.hadoop.mapreduce.Mapper$Context@41b9bff9
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ls
input output part scoreProcess.jar
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# cd output/
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess/output# ls
part-r- _SUCCESS
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess/output# cat part-r-
jerry
tom
哈2
小明
2. 在hadoop hdfs上运行
2.1 data文件上传到hdfs
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -mkdir /user
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -mkdir /user/root
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -mkdir /user/root/input
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -put input/data /user/root/input
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -ls /user/root/input
Found items
-rw-r--r-- root supergroup -- : /user/root/input/data
2.2 运行
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop jar scoreProcess.jar
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapred.JobClient: Running job: job_201806060358_0002
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: Job complete: job_201806060358_0002
// :: INFO mapred.JobClient: Counters:
// :: INFO mapred.JobClient: Map-Reduce Framework
// :: INFO mapred.JobClient: Combine output records=
// :: INFO mapred.JobClient: Spilled Records=
// :: INFO mapred.JobClient: Reduce input records=
// :: INFO mapred.JobClient: Reduce output records=
// :: INFO mapred.JobClient: Map input records=
// :: INFO mapred.JobClient: Map output records=
// :: INFO mapred.JobClient: Map output bytes=
// :: INFO mapred.JobClient: Reduce shuffle bytes=
// :: INFO mapred.JobClient: Combine input records=
// :: INFO mapred.JobClient: Reduce input groups=
// :: INFO mapred.JobClient: FileSystemCounters
// :: INFO mapred.JobClient: HDFS_BYTES_READ=
// :: INFO mapred.JobClient: FILE_BYTES_WRITTEN=
// :: INFO mapred.JobClient: FILE_BYTES_READ=
// :: INFO mapred.JobClient: HDFS_BYTES_WRITTEN=
// :: INFO mapred.JobClient: Job Counters
// :: INFO mapred.JobClient: Launched map tasks=
// :: INFO mapred.JobClient: Launched reduce tasks=
// :: INFO mapred.JobClient: Data-local map tasks=
2.3 查看结果
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -ls /user/root/output/
Found items
drwxr-xr-x - root supergroup -- : /user/root/output/_logs
-rw-r--r-- root supergroup -- : /user/root/output/part-r-00000
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ../../bin/hadoop fs -get /user/root/output/part-r- part
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# ls
input output part scoreProcess.jar
root@master:/home/wzy/software/hadoop-0.20./testfile/ScoreProcess# cat part
jerry
tom
2哈
小明
原生MapReduce开发样例的更多相关文章
- spring+springmvc+hibernate架构、maven分模块开发样例小项目案例
maven分模块开发样例小项目案例 spring+springmvc+hibernate架构 以用户管理做測试,分dao,sevices,web层,分模块开发測试!因时间关系.仅仅測查询成功.其它的准 ...
- hadoop学习;block数据块;mapreduce实现样例;UnsupportedClassVersionError异常;关联项目源代码
对于开源的东东,尤其是刚出来不久,我认为最好的学习方式就是能够看源代码和doc,測试它的样例 为了方便查看源代码,关联导入源代码的项目 先前的项目导入源代码是关联了源代码文件 block数据块,在配置 ...
- hadoop得知;block数据块;mapreduce实现样例;UnsupportedClassVersionError变态;该项目的源代码相关联
对于开源的东西.特别是刚出来不久.我认为最好的学习方法是能够看到源代码,doc,样品测试 为了方便查看源代码,导入与项目相关的源代码 watermark/2/text/aHR0cDovL2Jsb2cu ...
- PyQt开发样例: 利用QToolBox开发的桌面工具箱Demo
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 toolBox工具箱是一个容器部件,对应类为QToolBox,在其内有一列从上到下顺序排列 ...
- OpenHarmony 3.1 Beta 样例:使用分布式菜单创建点餐神器
(以下内容来自开发者分享,不代表 OpenHarmony 项目群工作委员会观点) 刘丽红 随着社会的进步与发展,科技手段的推陈出新,餐饮行业也在寻求新的突破与变革,手机扫描二维码点餐系统已经成为餐饮行 ...
- AppCan移动应用开发平台新增9个超有用插件(内含演示样例代码)
使用AppCan平台进行移动开发.你所须要具备的是Html5+CSS +JS前端语言基础.此外.Hybrid混合模式应用还需结合原生语言对功能模块进行封装,对于没有原生基础的开发人员,怎样实现App里 ...
- [b0010] windows 下 eclipse 开发 hdfs程序样例 (二)
目的: 学习windows 开发hadoop程序的配置 相关: [b0007] windows 下 eclipse 开发 hdfs程序样例 环境: 基于以下环境配置好后. [b0008] Window ...
- 构造Scala开发环境并创建ApiDemos演示样例项目
从2011年開始写Android ApiDemos 以来.Android的版本号也更新了非常多,眼下的版本号已经是4.04. ApiDemos中的样例也添加了不少,有必要更新Android ApiDe ...
- 让你提前认识软件开发(19):C语言中的协议及单元測试演示样例
第1部分 又一次认识C语言 C语言中的协议及单元測试演示样例 [文章摘要] 在实际的软件开发项目中.常常要实现多个模块之间的通信.这就须要大家约定好相互之间的通信协议,各自依照协议来收发和解析消息. ...
随机推荐
- python ipython notebook或者 jupyter notebook 的安装
IPython Notebook使用浏览器作为界面,向后台的IPython服务器发送请求,并显示结果.在浏览器的界面中使用单元(Cell)保存各种信息.Cell有多种类型,经常使用的有表示格式化文本的 ...
- Spark架构解析(转)
Application: Application是创建了SparkContext实例对象的Spark用户,包含了Driver程序, Spark-shell是一个应用程序,因为spark-shell在启 ...
- springboot springmvc 支持 https
Spring Mvc和Spring Boot配置Tomcat支持Https 背景 最近在项目开发中需要让自己的后端Restful接口支持https,在参考了很多前辈们的博客后总结了一些. Spring ...
- vue+django前后端分析解决csrf token问题
vue-resource post数据 参考:https://www.cnblogs.com/linxizhifeng/p/8995077.html 阅读django CsrfViewMiddlewa ...
- List contents of directories in a tree-like format
Python programming practice. Usage: List contents of directories in a tree-like format. #!/usr/bin/p ...
- python常用模块-1
一.认识模块 1.什么是模块:一个模块就是一个包含了python定义和声明的文件,文件名就是加上.py的后缀,但其实import加载的模块分为四个通用类别 : 1.使用python编写的代码(.py文 ...
- iOS9 Search API 之 Spotlight
iOS9以后 有三种api提供搜搜方式 加强引导用户关注 我们的app及相关内容的方式 NSUserActivity Web Markup Core Spotlight 用法 前两种 实战操作性不够 ...
- ETL应用:一种一次获取一个平台接口文件的方法
ETL应用场景中,若对端接口文件未能提供,任务会处于循环等待,直到对端提供为止,该方法极大的消耗了系统资源.为此想到了一种方法,一次获取一个平台的文件,实现思路如下: 1.第一次获取对端平台提供目录下 ...
- hi3515 rtc驱动(ds1307/1339)驱动和示例
将驱动放入/extdrv中编译 部分驱动如下: #include <linux/module.h> #include <linux/miscdevice.h>#include ...
- Linux下SPI测试程序
/** 说明:SPI通讯实现* 方式一: 同时发送与接收实现函数: SPI_Transfer()* 方式二:发送与接收分开来实现* SPI_Write() 只发送* SPI_Read() 只接收* 两 ...