DDCA —— 片上网络互联
1. 路由
1.1 网络拓扑示例
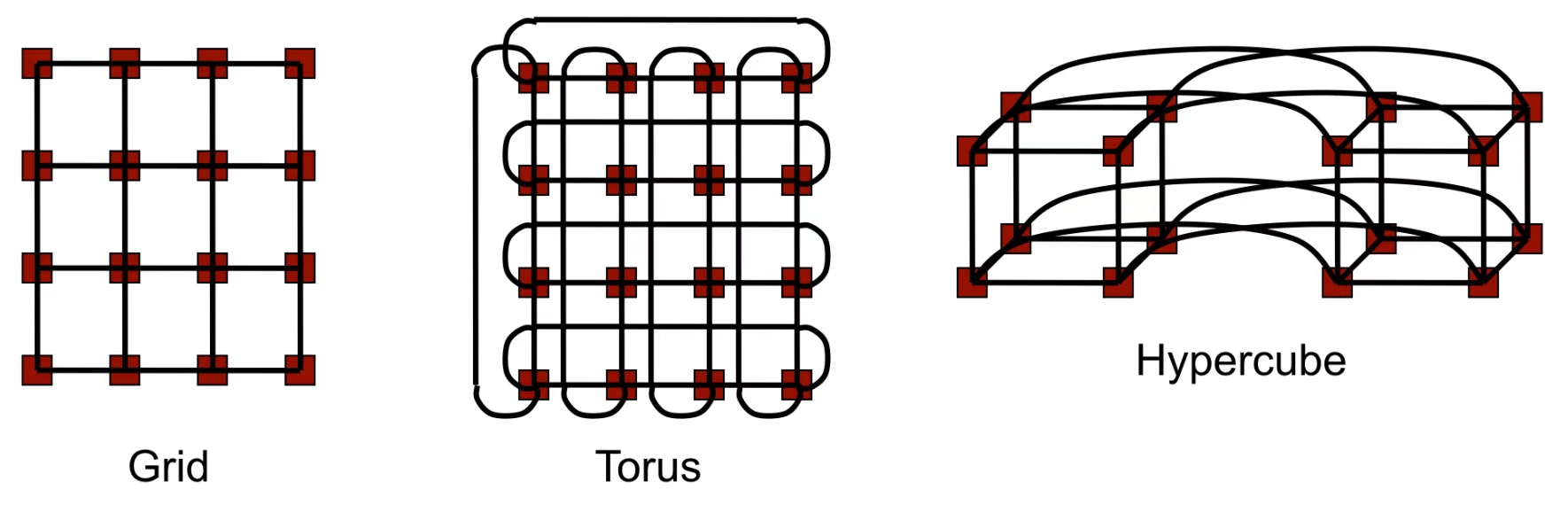
Grid(网格)
网络拓扑通常是一个二维矩阵形式,每个节点(处理器)与其上下左右相邻的节点相连。
如果节点在边缘,某些方向上可能没有相邻节点(边界节点)。
Torus(环形网格)
Torus是网格的改进版本,通过将网格的边界节点相连,形成一个环状结构。
每个节点都与上下左右相邻的节点连接,同时网格边缘节点环绕连接,形成闭合路径。
Hypercube(超立方体)
超立方体是一种高维网络拓扑,具有\(d\)-维结构,其中节点数 \(P=2^d\)。
每个节点通过 \(d\) 条链接与其他节点相连,节点的编号之间的 Hamming 距离为 1。
例如,三维超立方体有 8 个节点,四维超立方体有 16 个节点。
1.2 Routing(路由)
确定性路由(Deterministic Routing):给定源节点和目标节点时,存在唯一的一条路由路径。
自适应路由(Adaptive Routing):交换节点可以根据意外事件(例如故障、拥塞)动态调整路由路径。这种方式会增加路由器的复杂性,但可能提升网络性能。!!!仍可能造成死锁!!!
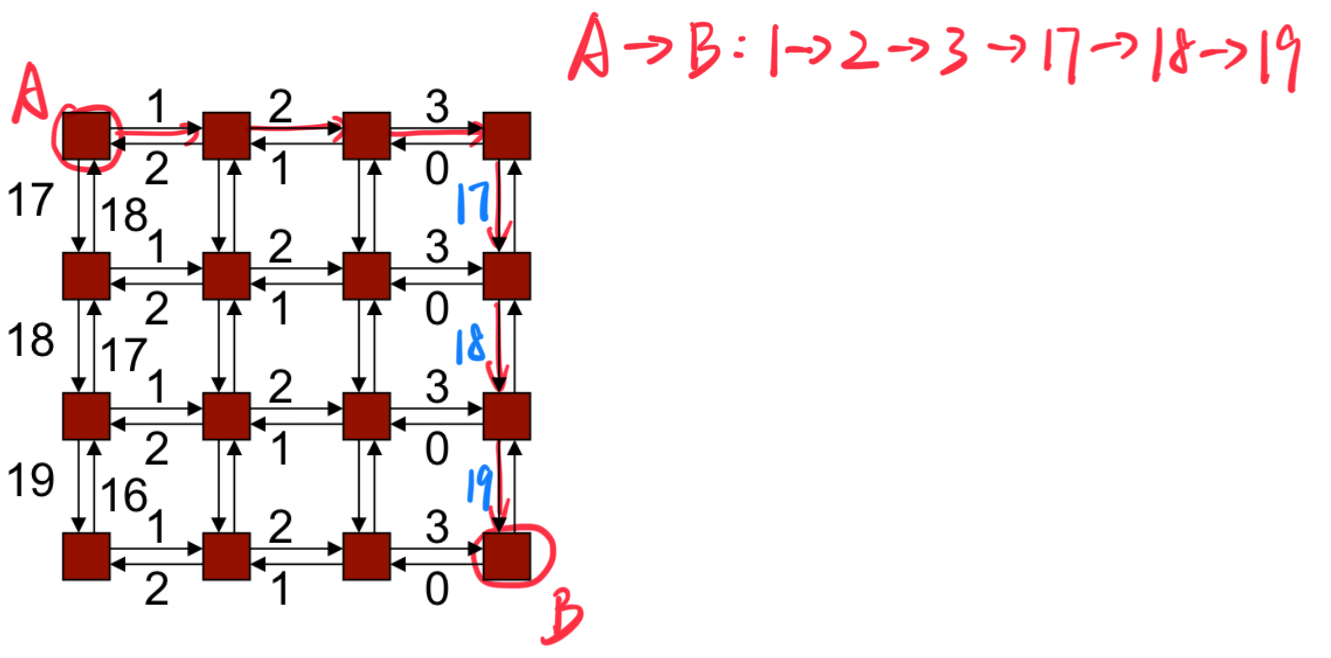
确定性路由示例:维度顺序路由(Dimension Order Routing):数据包沿着第一维度发送,直到到达目标在该维度上的坐标,然后继续在下一维度上发送,以此类推,直到数据包到达目标节点。
2. Deadlock(死锁)
死锁发生在资源依赖形成循环的情况下:一个进程占有某个资源(A)并试图获取另一个资源(B),而资源 A 不会被释放,直到获取到资源 B。


如上图所示,每个 message packets 试图进行左转操作,从而造成死锁。
2.1 Deadlock-Free Proofs(无死锁证明)
给边编号,并证明所有路由将按递增(或递减)顺序遍历边
- 在网络中,可以为路径中的边进行编号。
- 如果我们能确保所有数据包的路径都按照边的编号顺序递增(或递减)进行移动,就不会产生循环依赖,从而避免死锁。
- 原因:如果所有路径都按顺序遍历边,那么不会存在“回到之前的边”或形成循环依赖的情况。
示例:k-ary二维数组(k-ary 2-d array)使用维度路由
- 在二维网格结构中,数据包通过维度顺序路由进行传输。
- 维度顺序路由规则:
- 首先沿 X 维度传输,直到目标位置的 X 坐标到达;
- 然后沿 Y 维度传输,直到目标位置的 Y 坐标到达。
- 这种路由方法的特点:
- 数据包严格按照先 X 轴后 Y 轴的顺序移动。
- 因为路径中不会出现“回头”或任意的转弯方向,路径边的编号始终是递增顺序,因此不会形成循环依赖。
2.2 Breaking Deadlock(打破死锁)
考虑二维网格中的 8 种可能的转弯(注意:转弯会导致循环)
- 在二维网格中,数据包可以沿四个方向(东南西北)移动。
- 每个方向之间的转弯(左转、右转)会导致路径形成循环,从而引发死锁。
通过阻止两个特定的转弯,可以消除循环
- 如果禁止数据包进行两个特定方向的转弯,就可以有效地消除路径中的循环依赖,从而避免死锁。
维度顺序路由(Dimension Order Routing)禁止四种转弯
如下图所示,维度顺序路由对于从左边或从右边跳转的 Packets,只允许进行两个方向的转弯,从而避免死锁的产生。
即使在自适应路由中也可以避免死锁
- 通过限制转弯方向,可以在自适应路由中防止死锁。
下方图示展示了几种常见的死锁避免策略:

West-First(西优先)
数据包不能先向东转弯,只能先向西移动。

North-Last(北最后)
数据包一开始不能向北走,最后才向北走。

Negative-First(负向优先)
数据包的移动方向被分为两类:
- 负方向(Negative Direction):沿着坐标轴朝负数方向移动。
- 正方向(Positive Direction):沿着坐标轴朝正数方向移动。
数据包必须先移动负方向(例如 X 轴负方向或 Y 轴负方向),直到不能再移动为止,然后才能开始移动正方向。

会造成死锁(Deadlock)

3. Packets/Flits(数据包/流控单元)
一条消息会被拆分成多个数据包(packets)(每个数据包都包含头部信息,允许接收端重新构建原始消息)。

一个数据包本身可以进一步被拆分成流控单元(Flits)——流控单元不包含额外的头部信息。
两个数据包可以沿着不同的路径到达目的地;而流控单元始终是有序的,并且沿着相同的路径传输。

这种架构允许使用较大的数据包(从而减少头部开销),同时可以基于流控单元(Flits)实现细粒度的资源分配。
4. Flow Control(流量控制)
消息(Message)的路由(route)需要分配多种资源:
- 信道(或链路)
- 缓冲区
- 控制状态
无缓冲流控(Bufferless):
如果发生链路争用,数据单元(flits)会被丢弃。
系统会发送否定确认(NACK),通知原始发送方。
发送方需要重新传输该数据包。
偏转路由:

电路交换(Circuit Switching):
发送方首先发送一个请求(探测 message)来预留信道。
如果中间路由器的信道暂时不可用,请求会被阻塞(因此不是真正的无缓冲机制)。
一旦信道预留完成,会发送确认消息(ACK)。
随后的数据包或数据单元(flits)能够以较小的开销进行传输(适合大规模数据传输)。

4.1 Buffered Flow Control(带缓冲的控制流)
两个信道之间的缓冲区可以使每个信道的资源分配相互解耦。

数据包缓冲流控(Packet-buffer flow control):数据包缓冲流控是将资源(如信道和缓冲区)按数据包的单位进行分配

存储-转发(Store-and-forward):
- 数据包必须完全接收,才能被传输到下一个节点。
- 优点: 较为简单,易于实现。
- 缺点: 每个节点都会引入传输延迟,因为数据包必须完全存储后才能继续传输。
切割传输(Cut-through):
- 数据包在尚未完全接收的情况下,就会开始向下一个节点传输。
- 优点: 减少了延迟,因为数据包不必完全存储在中间节点。
- 缺点: 如果链路拥塞,部分数据包(flits)可能无法前进,造成资源浪费。
虫洞路由(Wormhole Routing):
虫洞路由是切割传输的一种优化,它的特点是缓冲区按数据单元(flit)进行分配,而不是按整个数据包。
- Flit(流控制单元):
- 一个数据包被分解成多个较小的单位,称为flits(Flow control units)。
- 头flit包含路由信息,用于引导数据包的路径。
- 尾flit标志着数据包的结束。
- 工作原理:
- 头flit到达一个节点并确定路径,其他flits沿着同一路径传输。
- 由于flits被分成较小的单元,缓冲区占用较少,延迟更低。
- 优点:
- 减少了缓冲区的需求,因为每次只存储一部分(flit)而不是整个数据包。
- 减少了传输延迟,适用于高性能网络。
- 缺点:
- 如果路径上某个节点的缓冲区满了,整个数据包都会停滞,导致网络拥塞。
虫洞路由(Wormhole Routing)和切割传输(Cut-through)的区别:
切割传输从路由 1 跳转到路由 2 时,它需要在路由 2 分配整个数据包的缓存空间。
虫洞路由从路由 1 跳转到路由 2 时,它只需要在路由 2 分配一个 flit 的缓存空间。
5. Virtual Channels(虚拟信道)
传统信道的局限性:
传统情况下,数据包(packet)占用一个物理信道进行传输。
数据包被拆分为多个 flits(流控制单元),这些 flits 按顺序通过信道传输。
问题:
- 阻塞问题: 如果一个数据包在某个路由器的缓冲区被阻塞,其他数据包无法使用该物理信道,导致信道资源被浪费。
- 混淆问题: 如果其他数据包的 flits 插入当前信道,接收端无法正确区分这些 flits 属于哪个数据包。

虚拟信道(Virtual Channel)的解决方案:
多缓冲区设计: 每个物理信道被虚拟化为 N 个逻辑虚拟信道,每个虚拟信道都有自己的缓冲区。
多路复用: 允许多个数据包共享同一个物理信道(Physical Channel),但逻辑上各自独立。
虚拟信道 ID: 数据包中的 flits 携带一个 虚拟信道 ID,用于标识其所属的虚拟信道。
优势:
- 即使某个虚拟信道被阻塞,其他虚拟信道仍可以继续传输数据。
- 提高了物理信道的利用率,避免了信道资源被完全占用。
- 有助于缓解拥塞,减少死锁的风险。

5.1 Example
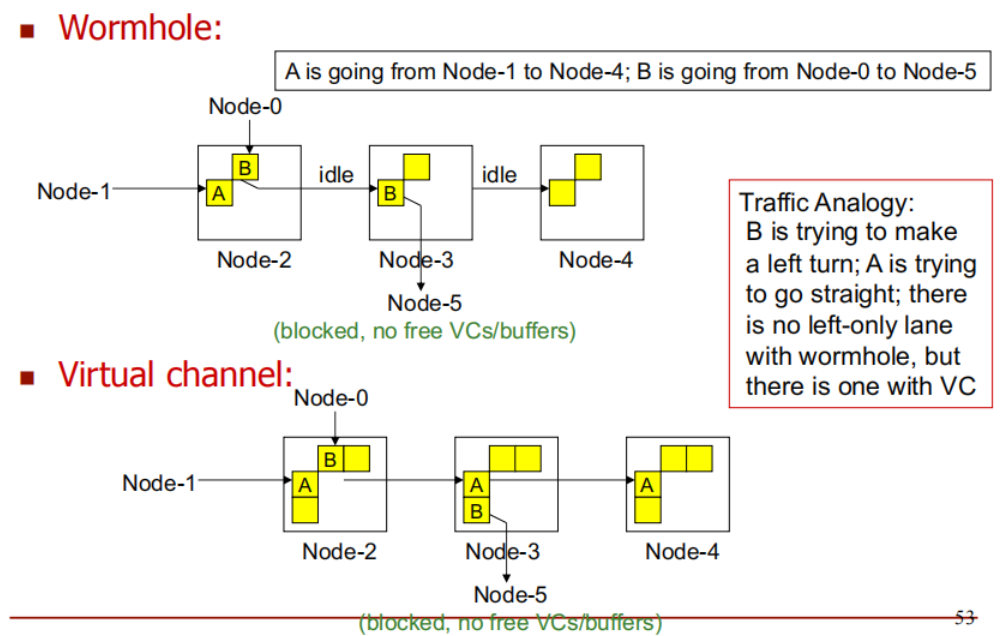
流量类比(Traffic Analogy):
A 和 B 分别代表两种不同的数据流,它们在网络中传输,想要到达不同的目的地。
数据包 B 需要转弯才能到达目的地,而数据包 A 需要直行。
在虫洞路由中,没有左转专用车道。这意味着,尽管数据包 B 需要转弯,它仍然会在传输过程中与直行的数据包 A 分享同一个物理信道。这可能导致冲突或阻塞,类似于左转的车辆与直行的车辆在同一车道上发生干扰。
在虚拟信道机制下,有左转专用车道。这意味着,数据包 B 可以通过专门的信道(虚拟信道)来完成左转,而不会干扰到数据包 A 的直行。虚拟信道为不同的数据流提供了独立的缓冲区,使得即使数据流的路径有所不同,它们也不会发生冲突。
5.2 虚拟信道流量控制(Virtual Channel Flow Control)
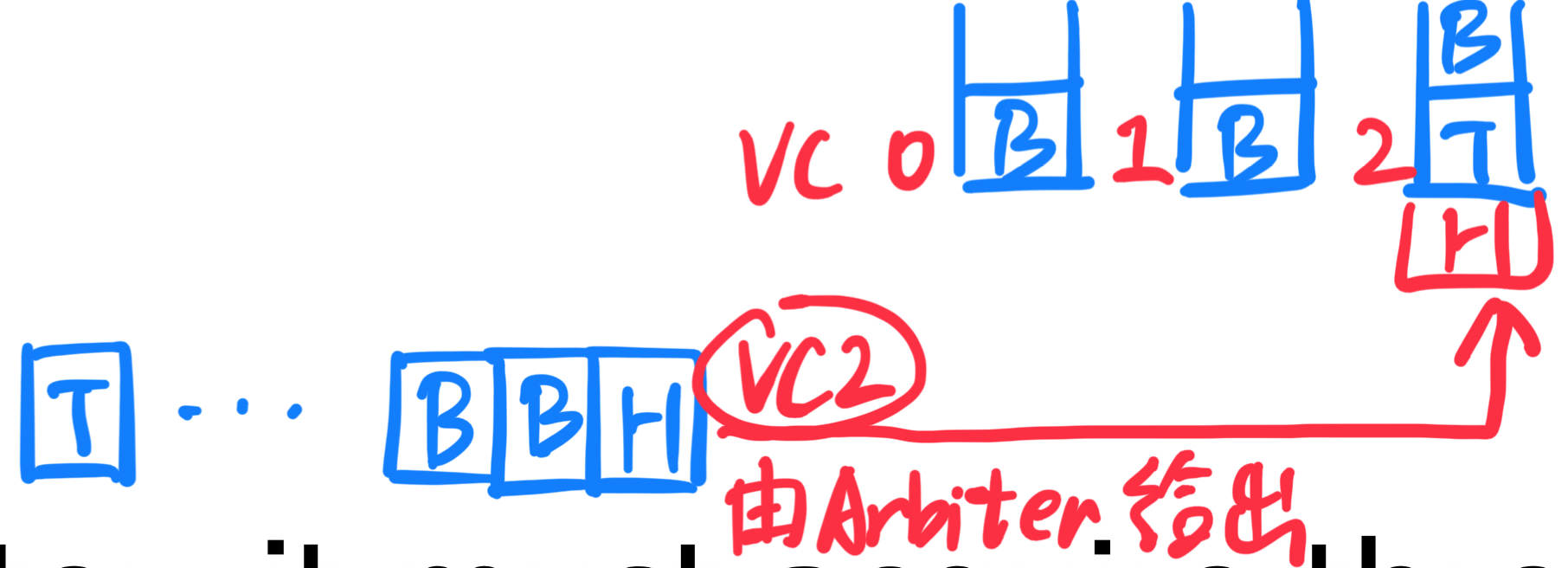
传入的 flit 和缓冲区:
- 每个传入的 flit 被放入相应的缓冲区,等待传输到下一个路由器。缓冲区的管理确保了每个 flit 在等待传输时不会发生数据丢失。
三个资源的竞争:为了将 flit 从当前路由器传输到下一个路由器,需要竞争以下三个资源:
- 空闲的虚拟信道:
虚拟信道是物理信道的一个分区,它使得多个数据包可以在同一物理信道上独立传输。每个虚拟信道有一个“尾部 flit”标识,当尾部 flit 成功传输过该信道时,信道被认为空闲,可以供下一个数据包使用。 - 空闲的缓冲区条目:
每个虚拟信道都有对应的缓冲区,存储传输中的 flit。通过信用管理(credit management)或者开关管理(on/off management)来控制缓冲区的分配。信用管理通过让接收端发送“信用信号”告知发送端缓冲区的空闲情况。 - 空闲的物理信道周期:
物理信道是实际的数据传输路径。多个数据包可能会竞争同一物理信道的传输周期,因此需要协调以避免冲突。物理信道周期的空闲情况决定了传输的顺利进行。
5.3 缓冲区管理(Buffer Management)
基于信用的缓冲区管理(Credit-based)
原理:在这种模式下,下游节点(即接收端)会持续追踪它的空闲缓冲区数量,并将该数量的信息反馈给上游节点(即发送端)。
过程:
- 上游节点每次发送数据包时,会根据下游节点的可用缓冲区数量来决定是否可以继续发送数据。
- 当下游节点有空闲缓冲区时,它会通过发送信号来通知上游节点,表明它可以接收更多数据。
- 信号的传递和缓冲区计数有助于避免下游节点的缓冲区溢出,同时保证数据流动的平稳。
- 为了防止往返延迟(即信号来回传递的时间)影响数据流,必须确保系统中有足够的缓冲区来隐藏这种延迟。
优点:
- 提供更精确的缓冲区利用率,减少了上游和下游节点的资源浪费。
- 可以在缓冲区有空闲空间时继续传输,优化了带宽使用。

开/关缓冲区管理(On/Off)
- 原理:在这种模式下,上游节点会跟踪自己的缓冲区使用情况,并在缓冲区快满时发送一个“关”信号给下游节点。
- 过程:
- 上游节点会通过这种方式告知下游节点它接近满载,暂时不再接受新的数据包。
- 与基于信用的管理方式相比,开/关方式减少了缓冲区的计数工作和上游节点的信号传递。
- 优点:减少了上游节点的信号发送和计数操作,降低了系统复杂性。
- 缺点:容易浪费缓冲区空间:在上游节点的缓冲区并未完全占满时,信号已经发出,导致上游节点停止发送数据,浪费了一部分缓冲区空间。
5.4 使用虚拟信道(VCs)避免死锁
基于虚拟信道的递增链路编号法
原理:
- 每个虚拟信道可以分配一个编号,通过对链路(物理通道)进行编号,确保数据包在传输过程中始终遵循递增编号的链路进行路由。
- 这种机制打破了形成死锁的资源循环依赖,因为数据包不会回到较低编号的链路上。
作用:通过链路编号的单调递增特性,保证了数据流动不会陷入死锁状态。

双平面(Two-Plane)路由法
- 平面1:West-first 路由策略
- 在第一个路由平面中,数据包遵循 West-first(优先向西)规则,即:
- 数据包如果需要向西移动,就必须先完成向西移动,不能在未完成西向移动时转向其他方向。
- 这种方法可以避免部分方向转弯所导致的死锁。
- 在第一个路由平面中,数据包遵循 West-first(优先向西)规则,即:
- 平面2:North-last 路由策略
- 如果数据包需要再次向西,但在第一平面无法继续时,它可以切换到第二平面。
- 第二平面使用不同的规则(例如North-last),即禁止在某些情况下向北转弯。
- 切换机制:数据包在两个平面之间进行切换,遵循不同的路由规则,进一步减少了死锁的可能性。
6. Router Pipeline(路由器流水线)
6.1 路由器功能
路由器功能模块:
交叉开关(Crossbar):负责数据在输入端口和输出端口之间的交换,是数据传输的核心组件。
缓冲器(Buffer):用于存储临时数据(flits),防止数据包因通道繁忙而丢失。
仲裁器(Arbiter):当多个数据流争用同一个输出端口或资源时,仲裁器决定哪个数据流优先传输。
虚拟信道状态与分配(VC State and Allocation):管理虚拟信道(VC)的状态,分配虚拟信道资源,确保多个数据流共享物理通道时不会混淆。
缓冲管理(Buffer Management):控制缓冲区的使用,确保数据流在缓冲区中高效存储与传输。
算术逻辑单元(ALUs):处理与数据传输有关的计算逻辑(例如计数、状态更新等)。
控制逻辑(Control Logic):负责整个路由器的协调与控制,确保各模块协同工作。
路由(Routing):计算数据包的下一跳路径,决定数据传输的方向。

片上网络的能耗:
- 片上网络(NoC,Network-on-Chip)是芯片中多个核心之间通信的基础结构,它对芯片的整体能耗有很大影响。
- 能耗占比高达10-35%,这使得优化片上网络的能效非常关键,特别是在高性能计算和低功耗设备中。
网络延迟:
- 由于数据传输需要经历多个网络跳(hops)和路由器处理,这可能引入数十个周期的延迟。
- 这种延迟对于缓存访问和内存访问来说尤为重要,因为高延迟会显著影响系统的整体性能。
功耗分布:
- 链路(Link): 数据通过物理链路传输时的功耗,通常与链路的长度和频率相关。
- 缓冲器(Buffers): 用于存储和管理数据包的缓冲区功耗,缓冲区越多,功耗越大。
- 交叉开关(Crossbar): 数据交换时消耗的功耗,主要取决于交换路径的复杂度。
每部分都占30%,这说明优化任何一个组件的功耗,都可以对片上网络的整体能效产生显著影响。
6.2 Router Pipeline(路由器流水线)
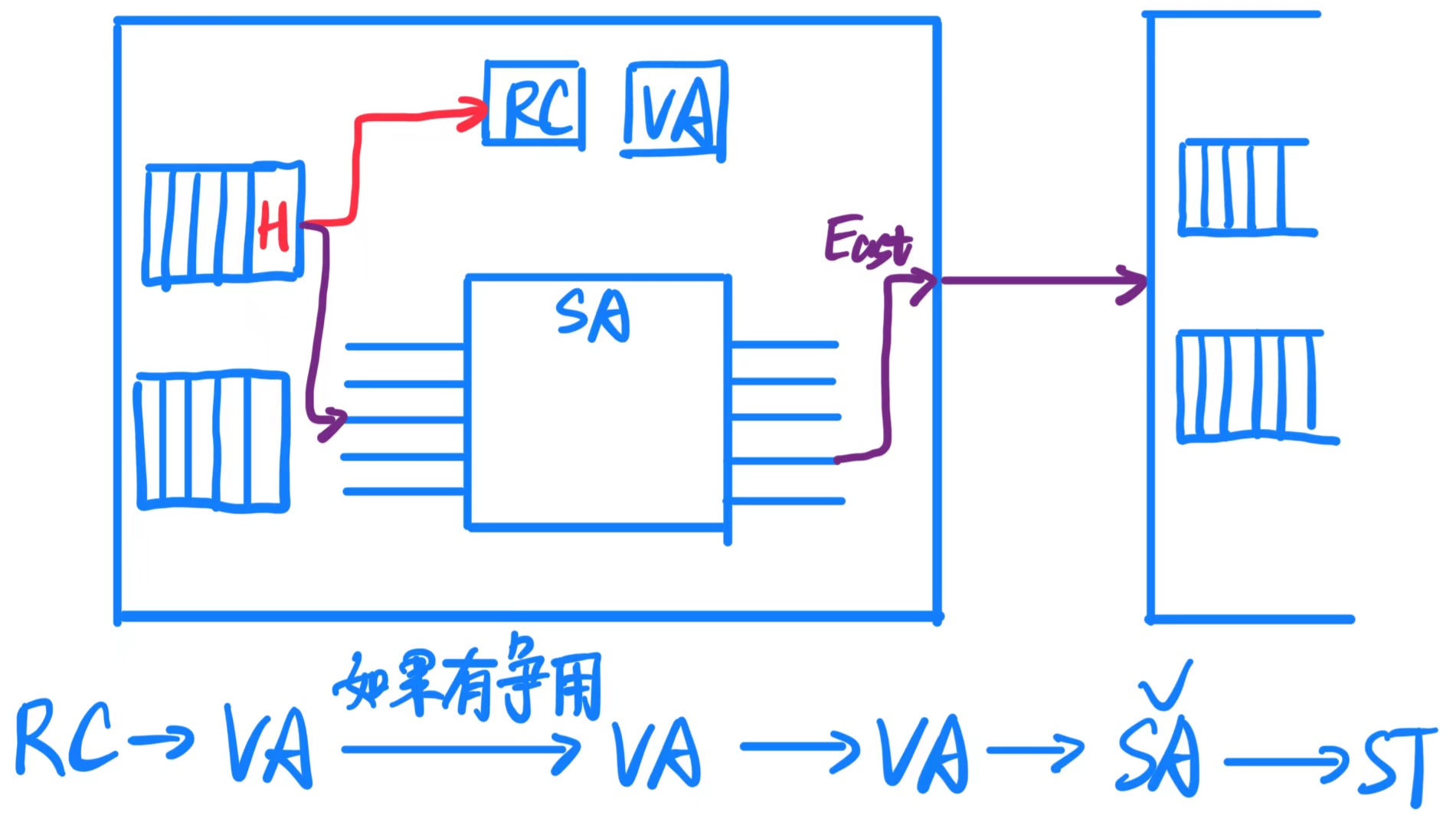
路由器流水线 是网络中路由器处理数据传输时采用的一种高效方法。它将数据包(packet)处理分为四个典型阶段,确保高吞吐量和低延迟。下面详细解释各个阶段:
- RC 路由计算(Routing Computation)
- 头部 flit(数据包的第一个部分)携带路由信息,它负责决定数据包的下一个传输路径。
- 路由器会检查头部 flit 的包头信息,计算出数据包应该传输到的下一个输出通道。
- 这个阶段必须针对所有到达路由器的输入通道进行,并且只对头部 flit 起作用。
- VA 虚拟信道分配(Virtual-Channel Allocation)
- 在这里,头部 flit 会竞争其目标输出通道上的可用虚拟信道。
- 由于物理通道可能需要被多个数据流共享,虚拟信道(VC)通过分配多个逻辑通道来解决资源争用问题。
- 一旦成功分配到虚拟信道,后续的 flit 就可以使用该通道,直到尾部 flit 释放资源。
- SA 交换分配(Switch Allocation)
- 在确定了目标输出通道后,多个输入端口的 flits 会竞争同一个输出通道(比如多个输入请求访问同一个北方向通道)。通过仲裁机制(Arbitration),决定哪个输入端口的 flit 可以成功获得输出通道的使用权。
- 只有获得交换分配的 flit 才能进入下一阶段,进行物理通道的传输。
- 通常存在多个输入端口 和 输出端口,它们代表数据流进入和离开路由器的路径。在一个 2D 网格网络结构中,典型的 5个输入端口 分别是:
- 北输入端口 (North Input):数据从网络中北侧的路由器流入当前路由器。
- 南输入端口 (South Input):数据从网络中南侧的路由器流入当前路由器。
- 西输入端口 (West Input):数据从网络中西侧的路由器流入当前路由器。
- 东输入端口 (East Input):数据从网络中东侧的路由器流入当前路由器。
- 本地输入端口 (Local Input):数据来自本地处理器核心(或者本地终端节点)。
- 典型的 5个输出端口 分别是:
- 北输出端口 (North Output):数据从当前路由器发送到北侧的路由器。
- 南输出端口 (South Output):数据从当前路由器发送到南侧的路由器。
- 西输出端口 (West Output):数据从当前路由器发送到西侧的路由器。
- 东输出端口 (East Output):数据从当前路由器发送到东侧的路由器。
- 本地输出端口 (Local Output):数据被发送到本地处理器核心(或终端节点)。
- ST 交换传输(Switch Traversal)
- 在交换传输阶段,flit 实际通过物理通道传输到下一个路由器或目的地。
- 这个阶段是数据包在网络中传输的物理执行步骤。
流水线规则:
- 数据包的头部 flit 需要经历这四个阶段,以确保路径的正确分配和传输。
- 数据包的中间 flit 和尾部 flit 不参与路由计算(RC)和虚拟信道分配(VA),因为路径已经由头部 flit 确定。
- 尾部 flit 通过释放虚拟信道资源(VC)来完成数据包的传输,这样其他数据流就可以使用这些资源。

6.3 Speculative Pipelines(推测性流水线)
推测性流水线是一种优化路由器性能的方法,通过同时尝试多个步骤,来减少流水线延迟,提高吞吐量。
- 推测性并行执行 VA 和 SA
- 在传统流水线中,VA(虚拟通道分配) 必须在 SA(交换分配) 之前完成,因为 SA 需要知道哪个虚拟通道被分配成功。
- 推测性并行执行允许 VA 和 SA 同时进行,假设虚拟通道会分配成功,这样可以节省时间。
- 缺点:如果 VA 最终失败,则之前成功分配的物理通道(SA 阶段分配)将被浪费。
- 完全并行:VA、SA 和 ST
- 在更加激进的推测性流水线中,可以同时执行 VA(虚拟通道分配)、SA(交换分配)和 ST(交换传输)。
- 优势:进一步减少延迟,提高吞吐量。
- 缺点:可能导致冲突或重试,例如多个 flits 同时竞争同一资源,导致部分分配需要重新计算。
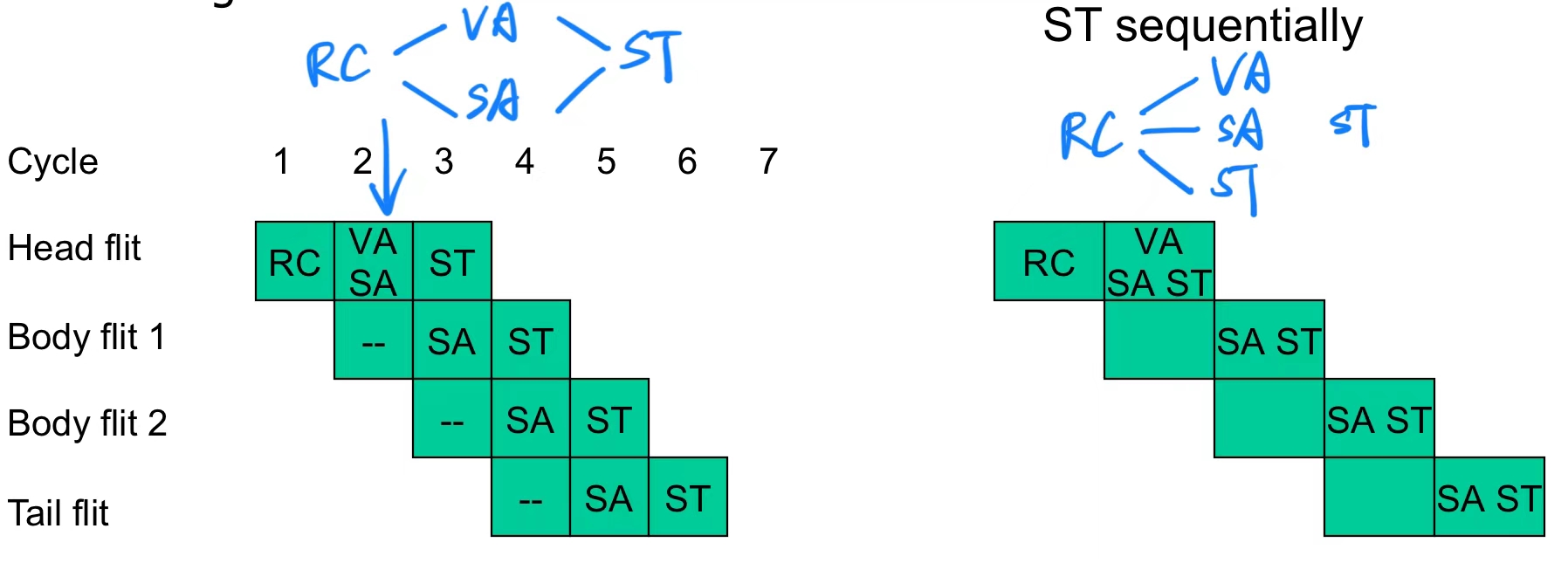
- VA 是关键路径
- 在多数情况下,VA(虚拟通道分配) 是路由器流水线的瓶颈,因为它涉及复杂的资源分配和冲突解决。
- 优化策略:可以顺序执行 SA 和 ST,以减少整体延迟。
- 推测性策略适用场景
- 当网络中数据包的争用较少时(例如负载较轻时),推测性策略更可能成功,因此这种优化策略的效果更好。
- 在这种情况下,路由器的流水线延迟会成为主要瓶颈,而不是通道争用。
- 单阶段流水线的可能性
理想情况下,推测性策略可以使整个路由器的流水线缩短为单阶段,将 RC、VA、SA 和 ST 合并在一起。
但实际上,由于冲突和硬件限制,完全单阶段流水线很难实现,只在一些特定网络结构和负载下可行。

7. Trends(趋势)
越来越关注消除路由器缓冲区带来的面积/功耗开销;由于流量水平相对较低,基于虚拟通道的有缓冲路由网络可能显得过于复杂。
Option 1:对于短距离通信(如 16 个核心),可以使用总线;对于长距离通信,采用分层总线结构。
Option 2:采用热土豆路由(hot-potato routing)或无缓冲路由(bufferless routing)。
8. Crossbar
8.1 Centralized Crossbar Switch(集中式交叉开关)
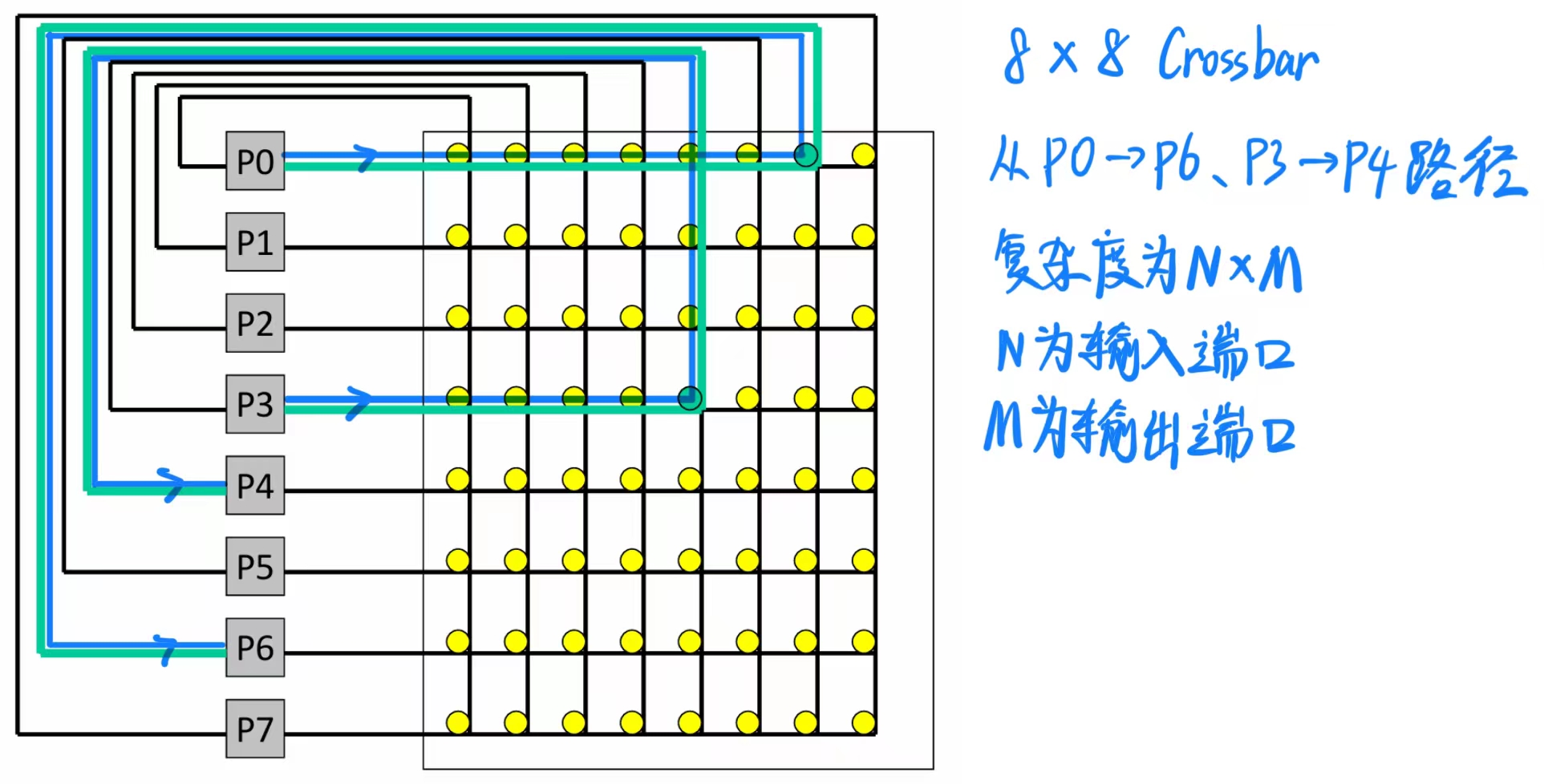
假设每个节点有一个输入端口和一个输出端口,交叉开关可以提供最大带宽:只要有 N 个唯一的源节点和 N 个唯一的目标节点,可以同时发送 N 条消息。
最大开销:交叉开关内部需要 WN² 个开关,其中 W 是数据宽度,N 是节点数量。
为了减少开销,可以使用较小的开关作为构建模块——这样会用更低的开销换取较低的有效带宽。
8.2 Omega 网络式开关
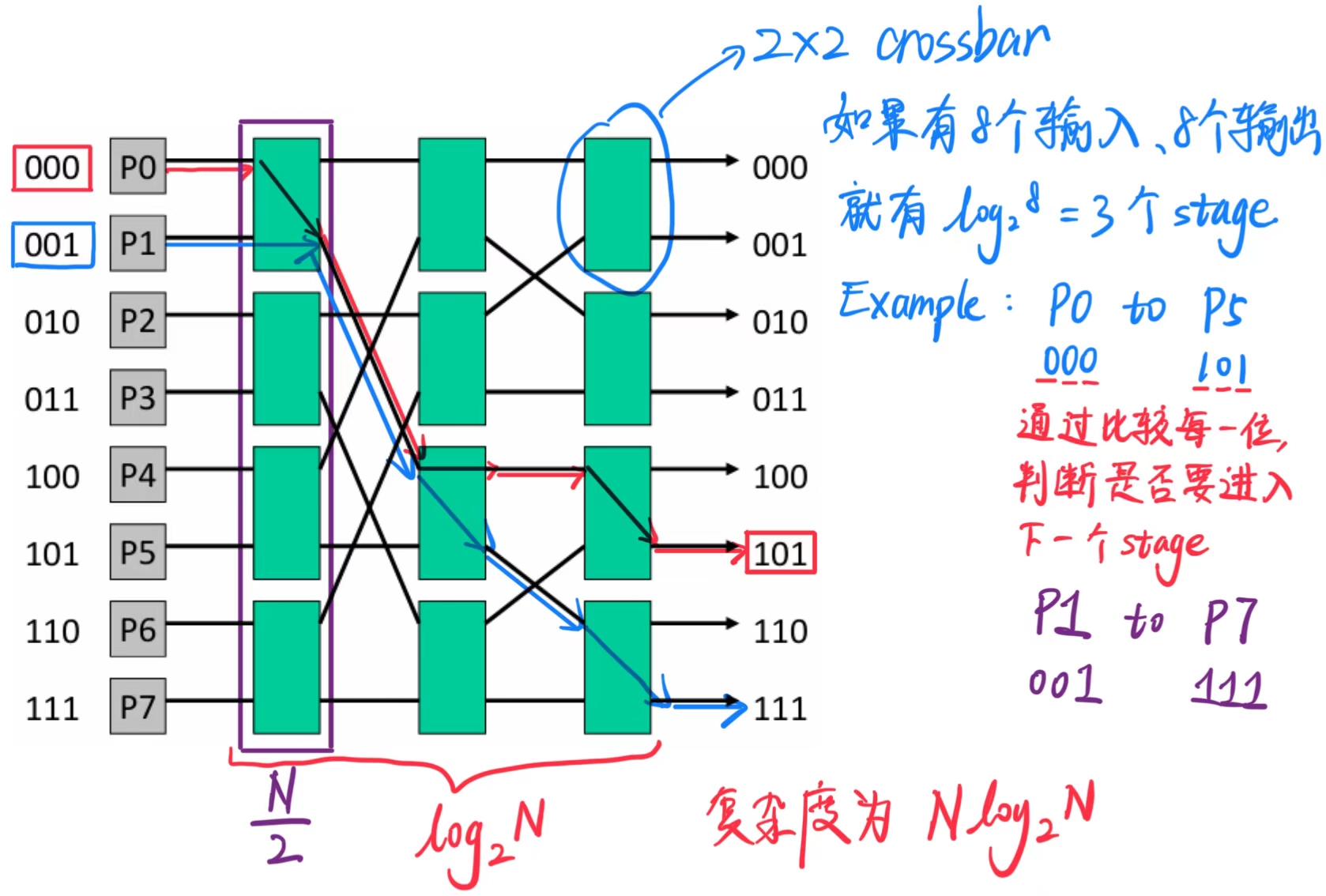
交换机的复杂度现在是 O(N log N)。
争用增加:P0 - P5 和 P1 - P7 无法同时发生(在交叉开关中是可能的)。
为了应对争用,可以增加网络的层数(冗余路径):通过镜像网络,我们可以通过 N 个中间节点从 P0 路由到 P5,同时将复杂度增加一个 2 倍。
8.3 Tree Network(树形网络)
复杂度为 O(N)。
在与邻近节点通信时可以实现低延迟。
通过增加多个输入和输出链接可以构建胖树(Fat Tree)。

9. 双向带宽
双向带宽的定义

双向带宽是评估网络结构性能的重要指标之一。它衡量了网络在最糟糕的情况下,两个部分之间的数据传输能力。
- 通过将节点划分为两组,寻找两个部分之间连接的最小带宽。
- 理想情况下,双向带宽越高,网络在高流量情况下的性能越好。
- 双向带宽的重要性
- 随机流量(Random Traffic):
- 如果消息在网络中随机传递,每个消息有 \(1/2\) 的概率需要跨越两个组。
- 如果所有节点都发送消息,总流量中大约一半会跨越组间带宽。
- 因此,组间的最小带宽决定了网络是否能支持这种负载而不出现瓶颈。
- 比如组间的最小带宽为 100MB/s,那么该网络可以支持 200MB/s 的带宽。
- 公式分析:在 \(N\) 个节点中,跨越带宽的流量大约为 \(N/2\),这就是双向带宽在随机流量下的需求。
- 树形网络的局限性
- 树形网络的特点:
- 树形网络中,不同分支之间的通信需要经过较少的主干连接。
- 如果流量是局部的(只在同一分支内传递),树形网络效率高。
- 不适合随机流量:
- 随机流量需要大量跨分支通信,导致主干带宽不足。
- 树形网络的双向带宽通常较低,无法支持高随机性负载。
DDCA —— 片上网络互联的更多相关文章
- CCNA 第一章 网络互联
1: 网络互联基础 互联网络定义:使用路由器将多个网络连接起来,并配置IP或者IPV6协议的逻辑网络编址方案,便组成了互联网络. 导致LAN(局域网)拥塞的常见原因: (1):广播域或者冲突域中的主机 ...
- TCP/IP概述(网络互联与TCP/IP)
TCP/IP概述(网络互联与TCP/IP) 用IP实现异构网络互联 从用户角度如何实现异构网络互联: 从用户角度看,实现异构网络互联的关键点就是使各种网络类型之间的差异对自己透明.在TCP/IP协议中 ...
- [VM workstation]VM workstation 中的虚拟机连不上网络
之前一直没有想到虚拟机连不上网络是VM workstationg 自身的原因. 突然在进入虚拟机时看见提示:VM 桥接网桥无法正常工作 于是便进入 编辑→虚拟网络编辑器 中将虚拟网卡都重置了一下就可以 ...
- Fiddler的钩子hook导致电脑无法连上网络
今天,电脑怎么都无法连上网络,重启了几次电脑也不行,网络环境是没有问题的,后来同事告诉我,Fiddler有一个BUG,就是Fiddler获取钩子之后没有释放掉,必须启动Fiddler,再关闭Fiddl ...
- CentOS7安装后连不上网络无法使用yum
更新日期:2018年5月31日 笔者今天在本地VMware中安装了CentOS7后,使用yum安装wget的时候发现不能下载,并有下图所示的提示: 于是,笔者就去问度娘,然后就找到了如下各种回复: 1 ...
- IP和网络互联
IP和网络互联 IP网络互连机制: IP地址分类方法及原因: CIDR地址(无分类地址): IP分组首部格式: 数据分片方法: IP分组传输思路:
- mac 解决安卓模拟器链接不上网络
方法1.临时方法,每次启动都要加114.114.114.114 1.进入到下面的目录 /Users/anxiaodong/Library/Android/sdk/emulator 2.执行以下命令 e ...
- Linux 上网络监控工具 ntopng 的安装
当今世界,人们的计算机都相互连接,互联互通.小到你的家庭局域网(LAN),大到最大的一个被我们称为互联网.当你管理一台联网的计算机时,你就是在管理最关键的组件之一.由于大多数开发出的应用程序都基于网络 ...
- Docker容器间网络互联原理,讲不明白算我输....
@ 目录 一.今天我们要搞明白的实验 二.前置网络知识 2.1.docker默认为我们创建的网络 2.2.怎么理解docker0网桥 2.3.什么是veth-pair技术? 三.同一个局域网中不同主机 ...
- vmware centos nat模式下连不上网络解决办法
简单来讲,当你创建一台虚拟机时,VMware为你虚拟了三种接入网络的方式:桥连接,NAT,使用主机网络,Vmware 10中默认对应 VMnet0,VMnet1,VMnet8 . 当选择桥连接方 ...
随机推荐
- JDK,JRE和JVM的区别和联系
一.JDK,JRE和JVM的区别和联系 JDK JDK:Java Development Kit,是java开发工具包,是程序员使用java语言编写java程序所需的开发工具包. JDK:普通用户只需 ...
- 暑假集训CSP提高模拟8
一看见题目列表就吓晕了,还好我是体育生,后面忘了 唉这场比赛没啥好写的,要不就是太难要不就是太简单要不就是拉出去写在专题里了 A. 基础的生成函数练习题 考虑到只有奇偶性相同才能尝试加二,因此先用加一 ...
- 配置windows update失败还原更改
配置windows update失败还原更改_解决方案 解决方法: 方法1: 重启,按F8,选择最后一次正常启动. 如果还是需要等待.可采用方法2: 方法2: 重启,按F8,选 ...
- 高通ADSP USB流程
在高通平台上,ADSP(Audio Digital Signal Processor,音频数字信号处理器)可以通过 USB 接口与主机进行数据传输,以下是大致的 ADSP USB 流程: 主机发起 U ...
- CPU缓存伪共享
CPU缓存什么东西?当然这个问题很多人有可能觉得比较傻,CPU缓存什么,肯定是缓存数据(代码)啊,要不然还能缓存啥,这个确实没问题,但是CPU到底缓存什么样的数据呢?因为对CPU来说,无论是指令,还是 ...
- MongoDB安装及配置Navicat MongoDB Tools
一.下载MongoDB 1.下载网址:https://www.mongodb.com/try/download/community 注:本文档以Windows和msi安装为例 二.安装MongoDB ...
- python中队列deque的使用
队列,堆栈是程序开发中常用的两种数据存储模型.python中队列怎么运用呢?以下内容介绍了队列的使用和队列的函数. from collections import deque q = deque() ...
- docker常用命令与应用
docker入门与docker file介绍 原文地址 docker常用命令 https://blog.csdn.net/leilei1366615/article/details/106267225 ...
- 重构案例:将纯HTML/JS项目迁移到Webpack
我们已经了解了许多关于 Webpack 的知识,但要完全熟练掌握它并非易事.一个很好的学习方法是通过实际项目练习.当我们对 Webpack 的配置有了足够的理解后,就可以尝试重构一些项目.本次我选择了 ...
- 想玩Steam游戏,但配置太低?ToDesk云电脑一招搞定!
在游戏爱好者的世界里,汇集了许多游戏大作的Steam平台无疑是一座宝库.但对于许多玩家来说,拥有一颗渴望畅玩游戏的心,却常常被低配置的电脑设备所束缚.尤其是面对硬件要求极高的3A大作时,低配置的电脑往 ...