SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff
CREATE TABLE [dbo].[Staff](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](50) NULL,
[Sex] [varchar](50) NULL,
[Department] [varchar](50) NULL,
[Money] [int] NULL,
[CreateDate] [datetime] NULL
) ON [PRIMARY] GO
2.为Staff表填充数据
INSERT INTO [dbo].[Staff]([Name],[Sex],[Department],[Money],[CreateDate])
SELECT 'Name1','男','技术部',3000,'2011-11-12'
UNION ALL
SELECT 'Name2','男','工程部',4000,'2013-11-12'
UNION ALL
SELECT 'Name3','女','工程部',3000,'2013-11-12'
UNION ALL
SELECT 'Name4','女','技术部',5000,'2012-11-12'
UNION ALL
SELECT 'Name5','女','技术部',6000,'2011-11-12'
UNION ALL
SELECT 'Name6','女','技术部',4000,'2013-11-12'
UNION ALL
SELECT 'Name7','女','技术部',5000,'2012-11-12'
UNION ALL
SELECT 'Name8','男','工程部',3000,'2012-11-12'
UNION ALL
SELECT 'Name9','男','工程部',6000,'2011-11-12'
UNION ALL
SELECT 'Name10','男','工程部',3000,'2011-11-12'
UNION ALL
SELECT 'Name11','男','技术部',3000,'2011-11-12'
GROUP BY 分组查询, 一般和聚合函数配合使用
SELECT [DEPARTMENT],SEX, COUNT(1)
FROM DBO.[STAFF]
GROUP BY SEX, [DEPARTMENT]
该段SQL是用于查询 某个部门下的男女员工数量 其数据结果如下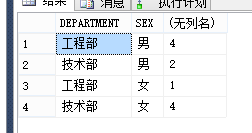

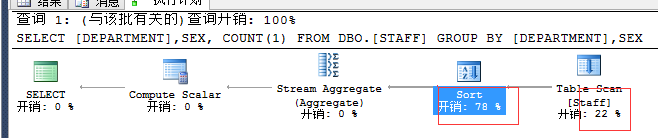
开销比较大
GROUPING SETS
使用 GROUPING SETS 的 GROUP BY 子句可以生成一个等效于由多个简单 GROUP BY 子句的 UNION ALL 生成的结果集,并且其效率比 GROUP BY 要高,SQL Server 2008引入。
1.使用GROUP BY 子句的 UNION ALL 来统计 Staff 表中的性别、部门、薪资、入职年份
SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT N'总人数' ,'',COUNT(0) FROM [DBO].[STAFF]
UNION ALL
SELECT N'按性别划分', SEX,COUNT(0) FROM [DBO].[STAFF] GROUP BY SEX
UNION ALL
SELECT N'按部门统计',[DEPARTMENT],COUNT(0) FROM [DBO].[STAFF] GROUP BY [DEPARTMENT]
UNION ALL
SELECT N'按薪资统计',CONVERT(VARCHAR(10),[MONEY]),COUNT(0) FROM [DBO].[STAFF] GROUP BY [MONEY]
UNION ALL
SELECT N'按入职年份',CONVERT(VARCHAR(10),YEAR([CREATEDATE])),COUNT(0) FROM [DBO].[STAFF] GROUP BY YEAR([CREATEDATE])
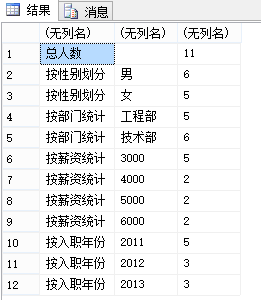


2.换成GROUPING SETS的写法
SET STATISTICS IO ON
SET STATISTICS TIME ON
GO
SELECT (CASE
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=15 THEN N'总人数'
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=7 THEN N'按性别划分'
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=11 THEN N'按部门统计'
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=13 THEN N'按薪资统计'
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=14 THEN N'按入职年份'
END
),
(CASE
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=15 THEN ''
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=7 THEN SEX
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=11 THEN [DEPARTMENT]
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=13 THEN CONVERT(VARCHAR(10),[MONEY])
WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=14 THEN CONVERT(VARCHAR(10),YEAR([CREATEDATE]))
END
)
,
COUNT(1)
FROM DBO.[STAFF]
GROUP BY GROUPING SETS (SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]),())
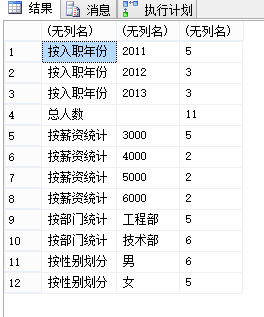

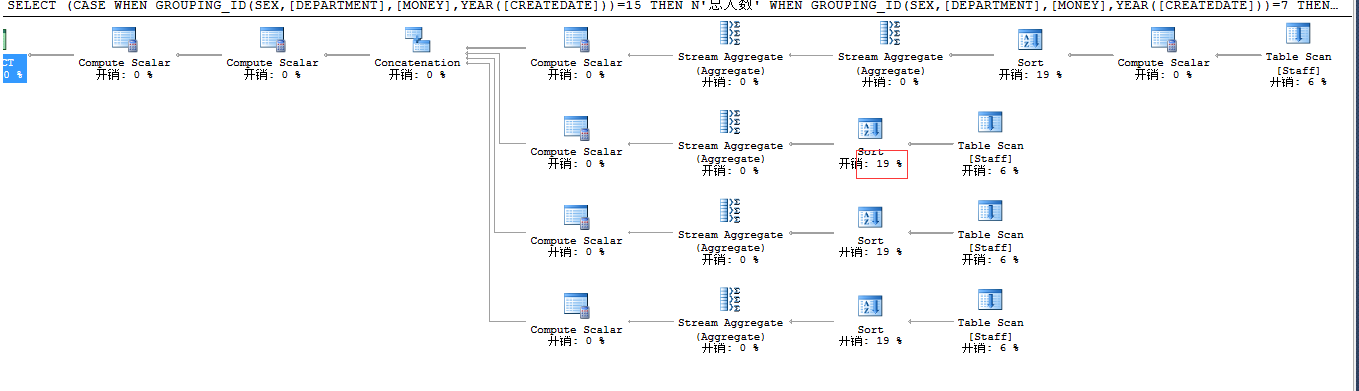
从上述结果中可以看出,采用UNION ALL 是多次扫描表,并将扫描后的查询结果进行组合操作,会增加IO开销,减少CPU和内存开销。
采用GROUPING SETS 是一次性读取所有数据,并在内存中进行聚合操作生成结果,减少IO开销,对CPU和内存消耗增加。但GROUPING SETS 在多列分组时,其性能会比group by高。
这里扫描四次是因为我 GROUP BY GROUPING SETS (SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]),()) 了四列
ROLLUP与CUBE
ROLLUP与CUBE 按一定的规则产生多种分组,然后按各种分组统计数据
ROLLUP与CUBE 区别:
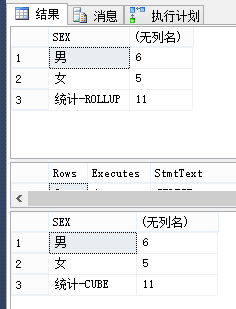
CUBE 会对所有的分组字段进行统计,然后合计。
SELECT
CASE WHEN (GROUPING(SEX) = 1) THEN '统计-ROLLUP'
ELSE ISNULL(SEX, 'UNKNOWN')
END AS SEX ,
COUNT(0)
FROM DBO.[STAFF]
GROUP BY SEX WITH ROLLUP SELECT
CASE WHEN (GROUPING(SEX) = 1) THEN '统计-CUBE'
ELSE ISNULL(SEX, 'UNKNOWN')
END AS SEX ,
COUNT(0)
FROM DBO.[STAFF]
GROUP BY SEX WITH CUBE
SELECT
CASE WHEN (GROUPING(SEX) = 1) THEN '统计-ROLLUP'
ELSE ISNULL(SEX, 'UNKNOWN')
END AS SEX ,
CASE WHEN (GROUPING([DEPARTMENT]) = 1) THEN '统计-ROLLUP'
ELSE ISNULL([DEPARTMENT], 'UNKNOWN')
END AS [DEPARTMENT],
COUNT(0)
FROM DBO.[STAFF]
GROUP BY SEX,[DEPARTMENT] WITH ROLLUP SELECT
CASE WHEN (GROUPING(SEX) = 1) THEN '统计-CUBE'
ELSE ISNULL(SEX, 'UNKNOWN')
END AS SEX ,
CASE WHEN (GROUPING([DEPARTMENT]) = 1) THEN '统计-CUBE'
ELSE ISNULL([DEPARTMENT], 'UNKNOWN')
END AS [DEPARTMENT],
COUNT(0)
FROM DBO.[STAFF]
GROUP BY SEX,[DEPARTMENT] WITH CUBE
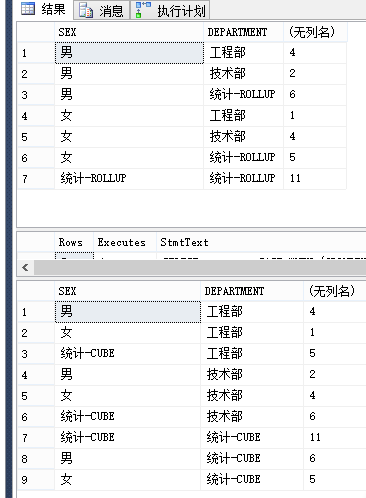
可以看出 使用 ROLLUP 会先统计分组下的,然后在对GROUP BY的第一列字段进行统计,最后计算总数,而 CUBE 则是先分组统计,然后统计GRUOP BY 的每个字段,最后进行汇总。
http://www.cnblogs.com/woxpp/p/4688715.html
SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE的更多相关文章
- SQL GROUP BY GROUPING SETS,ROLLUP,CUBE(需求举例)
实现按照不同级别分组统计 关于GROUP BY 中的GROUPING SETS,ROLLUP,CUBE 从需求的角度理解会更加容易些. 需求举例: 假如一所学校只有两个系, 每个系有两个专业, 每个专 ...
- Oracle PL/SQL之GROUP BY GROUPING SETS
[转自] http://blog.csdn.net/t0nsha/article/details/6538838 使用GROUP BY GROUPING SETS相当于把需要GROUP的集合用UNIO ...
- GROUPING SETS、CUBE、ROLLUP
其实还是写一个Demo 比较好 USE tempdb IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; G ...
- group by <grouping sets(...) ><cube(...)>
GROUP BY GROUPING SETS() 后面将还会写学习 with cube, with rollup,以及将它们转换为标准的GROUP BY的子句GROUP SET(), CU ...
- SQL server 关于 GROUP BY 详细讲解和用法
1. Group By 语句简介: Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若 ...
- Group By Grouping Sets
Group by分组函数的自定义,与group by配合使用可更加灵活的对结果集进行分组,Grouping sets会对各个层级进行汇总,然后将各个层级的汇总值union all在一起,但却比单纯的g ...
- GROUP BY GROUPING SETS 示例
--建表 create table TEst1 ( ID ), co_CODE ), T_NAME ), Money INTEGER, P_code ) ); --插入基础数据 insert into ...
- Hive高级聚合GROUPING SETS,ROLLUP以及CUBE
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContext s ...
- (4.6)sql2008中的group by grouping sets
最近遇到一个情况,需要在内网系统中出一个统计报表.需要根据不同条件使用多个group by语句.需要将所有聚合的数据进行UNION操作来完成不同维度的统计查看. 直到发现在SQL SERVER 200 ...
随机推荐
- java文件末尾追加内容的两种方式
java 开发中,偶尔会遇到在文件末尾对文件内容进行追加,实际上有多种方式可以实现,简单介绍两种: 一种是通过RandomAccessFile类实现,另一种是通过FileWriter类来实现. 实现方 ...
- grep 和 wc命令 --- !管道命令!
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expr ession Print,表示全局正则表 ...
- 手把手教你用axis1.4搭建webservice(转)
1.先下载axis jar包:axis-bin-1_4.zip.下载地址: http://ws.Apache.org/axis/. 当然这个包其实是不全面的,像activation.jar之类的,完全 ...
- libcurl多线程超时设置不安全(转)
from http://www.cnblogs.com/kex1n/p/4135263.html (1), 超时(timeout) libcurl 是 一个很不错的库,支持http,ftp等很多的协议 ...
- IIS mime类型 任意类型
HTTP头 任意mime类型 .* application/octet-stream
- docker 安装
Docker使用了一种叫AUFS的文件系统,这种文件系统可以让你一层一层地叠加修改你的文件,最底下的文件系统是只读的,如果需要修改文件,AUFS会增加一个可写的层(Layer),这样有很多好处,例如不 ...
- coreseek实战(二):windows下mysql数据源部分配置说明
coreseek实战(二):windows下mysql数据源部分配置说明 关于coreseek在windows使用mysql数据源的配置,以及中文分词的详细说明,请参考官方文档: mysql数据源配置 ...
- 包含min函数的栈
题目描述 定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数 解法一: 思路:采用java中自带的迭代函数进行处理. public class Solution{ /** * @pa ...
- 有些网站为什么要使用CDN,CDN又是什么呢
如果你有一个小站,经过细心经营,流量慢慢变大,或者你想搞个活动,请求量会比平时多很多.你租的虚拟主机网络可能会被打爆,导致整个网站打开变慢.想扩大带宽却发现独享带宽很贵,这个时候你可以使用CDN. 如 ...
- JAVA -Xms -Xmx -XX:PermSize -XX:MaxPermSize 区别
java -Xms -Xmx -XX:PermSize -XX:MaxPermSize 在做java开发时尤其是大型软件开发时经常会遇到内存溢出的问题,比如说OutOfMemoryError ...