Flink - Juggling with Bits and Bytes
http://www.36dsj.com/archives/33650
http://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-Bytes.html
http://www.bigsynapse.com/addressing-big-data-performance ,addressing-big-data-performance
第一篇描述,当前JVM存在的问题,
1. Java对象开销
Java对象的存储密度相对偏低,对于“abcd”这样简单的字符串在UTF-8编码中需要4个字节存储,但Java采用UTF-16编码存储字符串,需要8个字节存储
同时Java对象还有header等其他额外信息,一个4字节字符串对象,在Java中需要48字节的空间来存储
2. 对象存储结构引发的cache miss
当CPU访问的数据如果是在内存中连续存储的话,访问的效率会非常高。如果CPU要访问的数据不在当前缓存所有的cache line中,则需要从内存中加载对应的数据,这被称为一次cache miss。
当cache miss非常高的时候,CPU大部分的时间都在等待数据加载,而不是真正的处理数据
Java对象并不是连续的存储在内存上,同时很多的Java数据结构的数据聚集性也不好,在Spark的性能调优中,经常能够观测到大量的cache miss
3. 大数据的垃圾回收
秒级甚至是分钟级的gc,尤其是full gc,极大的影响了Java应用的性能和可用性
4. OOM问题
OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会fOutOfMemoryError错误,JVM崩溃,分布式框架的健壮性和性能都会受到影响
解决方法,
定制的序列化工具
前面说了java对象的开销很大,如果使用Java Serialization和Kryo,会把所有的信息完整的进行序列化,会很占空间
一般如果是放内存是不需要序列化的,只有网络传输或存储的时候,需要做序列化,这样如果以java对象的开销,大大增加了网络和磁盘的开销
当前由于memory资源很紧张,就算在内存中,我们也不能存放java对象本身,而是通过内存管理,存储经过序列化的Java对象
这样带来的问题,如果序列化完后,如果数据没有明显变小就没有意义
序列化带来的最大的问题是,如果每次使用的时候都需要做反序列化,这个性能也好不到哪去
所以传统的序列化的问题,
- 占用较多内存。
- 反序列化时,必须反序列化整个Java对象。
- 无法直接操作序列化后的二进制数据。
对于大数据方案,序列化的思路,基本是,对于一个数据集,schema是固定的,那么我们没有必要在每个对象里面都记录元数据,只要记录一份就好,而在序列化的时候只需要记录真正的数据就好
比如spark的方案,Project Tungsten
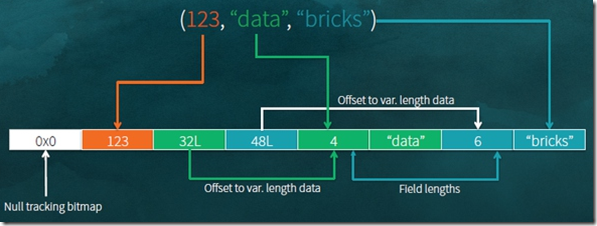
图中,显示出对于上面3个数据,如果高效的进行序列化的,
对于123,整形,直接以4byte存入
对于‘data’,可变长的数据,只存入真正数据所在的地址32L,在32L先存储数据length,接着是真正的数据
这样大大降低了存储的空间,并且更关键的是,在读取某个数据时,不需要反序列化整行,只需要根据offset偏移找到相应的数据,只序列化你需要的字段
当然对于这段数据的元数据,你是要单独存储的,但是对于比如10000行,只需要保存一份元数据,就显得很高效
第二篇文章会详细的描述Flink的方案
显式的内存管理
不依赖JVM的GC进行内存管理,显示的自己进行管理
有两种方式,
on-heap,仍然是用JVM的内存,但是使用Memory Manager pool的方式,
Memory Manager pool由多个MemorySegment组成,每个MemorySegment代表一块连续的内存,底层存储是byte[],默认32KB大小
你使用的时候,申请一个MemorySegment,然后把你的数据序列化后放到这个byte[]中,用完就把MemorySegment释放回Memory Manager pool
这样,你虽然不停的产生和销毁对象,但是在JVM看来,存在是只是pool中的那几个MemorySegment,这样gc的工作量和频度都会小很多
off-heap,干脆不使用JVM的内存,使用java unsafe接口直接使用系统的内存,就完全和c一样
这样做的好处,
on-heap方式,启动时分配大内存(例如100G)的JVM仍然很耗时间,垃圾回收也很慢
更有效率的IO操作。在off-heap下,将MemorySegment写到磁盘或是网络,可以支持zeor-copy技术,而on-heap的话,则至少需要一次内存拷贝(从内存中byte[]对象copy到设备的cache)
off-heap可用于错误恢复,比如JVM崩溃,在on-heap时,数据也随之丢失,但在off-heap下,off-heap的数据可能还在。
off-heap上的数据是进程间共享的,不同的JVM可以通过off-heap共享
缓存友好的计算
由于CPU处理速度和内存访问速度的差距,提升CPU的处理效率的关键在于最大化的利用L1/L2/L3/Memory,减少任何不必要的Cache miss。
定制的序列化工具给Spark和Flink提供了可能,通过定制的序列化工具,Spark和Flink访问的二进制数据本身,因为占用内存较小,存储密度比较大,而且还可以在设计数据结构和算法时,尽量连续存储,减少内存碎片化对Cache命中率的影响,甚至更进一步,Spark与Flink可以将需要操作的部分数据(如排序时的Key)连续存储,而将其他部分的数据存储在其他地方,从而最大可能的提升Cache命中的概率。
Juggling with Bits and Bytes
Data Objects? Let’s put them on the heap!
The most straight-forward approach to process lots of data in a JVM is to put it as objects on the heap and operate on these objects.
Caching a data set as objects would be as simple as maintaining a list containing an object for each record.
An in-memory sort would simply sort the list of objects.
However, this approach has a few notable drawbacks.
First of all it is not trivial to watch and control heap memory usage when a lot of objects are created and invalidated constantly. Memory overallocation instantly kills the JVM with an OutOfMemoryError.
Another aspect is garbage collection on multi-GB JVMs which are flooded with new objects. The overhead of garbage collection in such environments can easily reach 50% and more.
Finally, Java objects come with a certain space overhead depending on the JVM and platform. For data sets with many small objects this can significantly reduce the effectively usable amount of memory.
Given proficient system design and careful, use-case specific system parameter tuning, heap memory usage can be more or less controlled andOutOfMemoryErrors avoided. However, such setups are rather fragile especially if data characteristics or the execution environment change
直接把对象放在heap里面用好不好?当然好,不然了
但这样对于海量数据,是有性能问题的,比如比较容易OutOfMemoryError, gc的效率,java对象的overhead
What is Flink doing about that?
Apache Flink has its roots at a research project which aimed to combine the best technologies of MapReduce-based systems and parallel database systems.
Coming from this background, Flink has always had its own way of processing data in-memory.
Instead of putting lots of objects on the heap, Flink serializes objects into a fixed number of pre-allocated memory segments.
Flink致力于研究将DAG和MPP中最好的技术combine起来,Flink不是直接把对象放入heap,而是把对象进行序列化放入事先分配好的memeory segments中
Its DBMS-style sort and join algorithms operate as much as possible on this binary data to keep the de/serialization overhead at a minimum.
If more data needs to be processed than can be kept in memory, Flink’s operators partially spill data to disk.
In fact, a lot of Flink’s internal implementations look more like C/C++ rather than common Java.
Flink采用类似DBMS的sort和join算法,会直接操作二进制数据,而使de/serialization overhead 达到最小;
所以从Flink的内部实现看,更像C/C++而非java
The following figure gives a high-level overview of how Flink stores data serialized in memory segments and spills to disk if necessary.
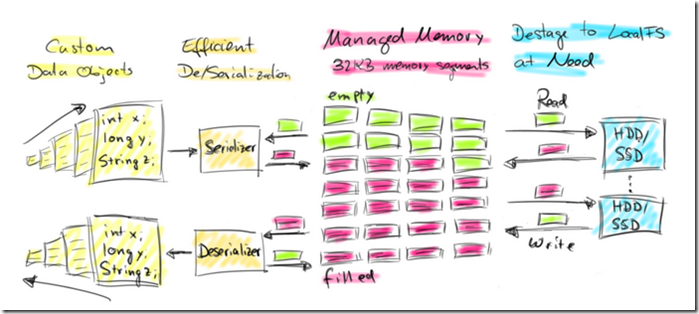
Flink’s style of active memory management and operating on binary data has several benefits:
- Memory-safe execution & efficient out-of-core algorithms. Due to the fixed amount of allocated memory segments, it is trivial to monitor remaining memory resources. In case of memory shortage, processing operators can efficiently write larger batches of memory segments to disk and later them read back. Consequently,
OutOfMemoryErrorsare effectively prevented. - Reduced garbage collection pressure. Because all long-lived data is in binary representation in Flink’s managed memory, all data objects are short-lived or even mutable and can be reused. Short-lived objects can be more efficiently garbage-collected, which significantly reduces garbage collection pressure. Right now, the pre-allocated memory segments are long-lived objects on the JVM heap, but the Flink community is actively working on allocating off-heap memory for this purpose. This effort will result in much smaller JVM heaps and facilitate even faster garbage collection cycles.
- Space efficient data representation. Java objects have a storage overhead which can be avoided if the data is stored in a binary representation.
- Efficient binary operations & cache sensitivity. Binary data can be efficiently compared and operated on given a suitable binary representation. Furthermore, the binary representations can put related values, as well as hash codes, keys, and pointers, adjacently into memory. This gives data structures with usually more cache efficient access patterns.
这样做的好处有:
不会出现OutOfMemoryErrors ,当内存不够的时候,会批量把memory segments写入磁盘,后续再read back
降低gc压力,这个显而易见,因为所有all long-lived data 都已经以二进制的方式存在flink的memory segments,并且这些segments都是可mutable的,可重用的;
节省空间,这个也显而易见,因为不需要存储java对象的overhead
有效的二进制操作和cache,二进制数据可以有效的被compared和操作
These properties of active memory management are very desirable in a data processing systems for large-scale data analytics but have a significant price tag attached. Active memory management and operating on binary data is not trivial to implement, i.e., using java.util.HashMap is much easier than implementing a spillable hash-table backed by byte arrays and a custom serialization stack.
Of course Apache Flink is not the only JVM-based data processing system that operates on serialized binary data. Projects such as Apache Drill, Apache Ignite (incubating) or Apache Geode (incubating) apply similar techniques and it was recently announced that also Apache Spark will evolve into this direction with Project Tungsten.
当然这种使用java的方式,个人看来,从技术上将,不是一种进步,而是一种倒退
这是JVM内存管理技术的发展无法跟上大数据时代的脚步导致的。。。。。。
所以问题是,你要用原始的方式,就会很麻烦
后面列出,其他的开源项目也在做类似的努力
How does Flink allocate memory?
A Flink worker, called TaskManager, is composed of several internal components such as an actor system for coordination with the Flink master, an IOManager that takes care of spilling data to disk and reading it back, and a MemoryManager that coordinates memory usage. In the context of this blog post, the MemoryManager is of most interest.
The MemoryManager takes care of allocating, accounting, and distributing MemorySegments to data processing operators such as sort and join operators.
A MemorySegment is Flink’s distribution unit of memory and is backed by a regular Java byte array (size is 32 KB by default).
A MemorySegment provides very efficient write and read access to its backed byte array using Java’s unsafe methods. You can think of a MemorySegment as a custom-tailored version of Java’s NIO ByteBuffer.
In order to operate on multiple MemorySegments like on a larger chunk of consecutive memory, Flink uses logical views that implement Java’s java.io.DataOutput and java.io.DataInput interfaces.
MemoryManager 负责管理所有的MemorySegments,一个MemorySegments 是一个32KB大小的byte数组
MemorySegment 用java的unsafe method提供有效的基于byte数组的读写,你可以认为MemorySegment 就是一个用户裁剪版的NIO的ByteBuffer
如果要操作多块MemorySegment就像操作一块大的连续内存,Flink会使用逻辑view来实现java的dataOutput或dataInput接口
MemorySegments are allocated once at TaskManager start-up time and are destroyed when the TaskManager is shut down.
Hence, they are reused and not garbage-collected over the whole lifetime of a TaskManager.
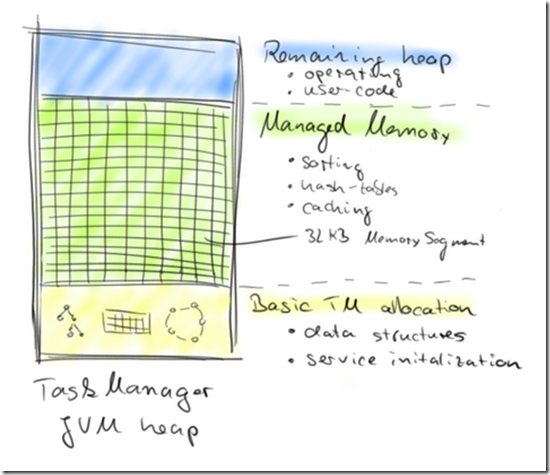
After all internal data structures of a TaskManager have been initialized and all core services have been started, the MemoryManager starts creating MemorySegments.
By default 70% of the JVM heap that is available after service initialization is allocated by the MemoryManager. It is also possible to configure an absolute amount of managed memory.
The remaining JVM heap is used for objects that are instantiated during task processing, including objects created by user-defined functions.
MemorySegments 在TaskManager启动的时候被分配,在TaskManager关闭的时候被销毁
他们在TaskManager 整个生命周期中可以被重用,而不会被gc掉
Default设置,会有70%的JVM heap会被MemoryManager申请分配成MemorySegments,
剩下的JVM heap用于在task执行中的临时对象实例化,比如udf中创建的对象
The following figure shows the memory distribution in the TaskManager JVM after startup.
How does Flink serialize objects?
The Java ecosystem offers several libraries to convert objects into a binary representation and back.
Common alternatives are standard Java serialization, Kryo, Apache Avro, Apache Thrift, or Google’s Protobuf.
Flink includes its own custom serialization framework in order to control the binary representation of data.
This is important because operating on binary data such as comparing or even manipulating binary data requires exact knowledge of the serialization layout.
Further, configuring the serialization layout with respect to operations that are performed on binary data can yield a significant performance boost.
Flink’s serialization stack also leverages the fact, that the type of the objects which are going through de/serialization are exactly known before a program is executed.
在java ecosystem中,除了java serialization,还有一堆序列化方案,Kryo, Apache Avro, Apache Thrift, or Google’s Protobuf.
但是Flink还是使用一套自己的serialization framework,以便于控制数据的二进制表示方式
因为对于二进制数据的操作,比如comparing甚至是直接操作,需要确切的知道二进制数据的layout
Flink programs can process data represented as arbitrary Java or Scala objects. Before a program is optimized, the data types at each processing step of the program’s data flow need to be identified.
For Java programs, Flink features a reflection-based type extraction component to analyze the return types of user-defined functions. Scala programs are analyzed with help of the Scala compiler.
Flink需要明确的知道处理过程每步的,数据流的数据类型,比如通过Java的reflection-based type extraction或Scala compiler
然后Flink会使用自己的类型系统来表示数据类型,TypeInformation
Flink represents each data type with a TypeInformation. Flink hasTypeInformations for several kinds of data types, including:
- BasicTypeInfo: Any (boxed) Java primitive type or java.lang.String.
- BasicArrayTypeInfo: Any array of a (boxed) Java primitive type or java.lang.String.
- WritableTypeInfo: Any implementation of Hadoop’s Writable interface.
- TupleTypeInfo: Any Flink tuple (Tuple1 to Tuple25). Flink tuples are Java representations for fixed-length tuples with typed fields.
- CaseClassTypeInfo: Any Scala CaseClass (including Scala tuples).
- PojoTypeInfo: Any POJO (Java or Scala), i.e., an object with all fields either being public or accessible through getters and setter that follow the common naming conventions.
- GenericTypeInfo: Any data type that cannot be identified as another type.
Each TypeInformation provides a serializer for the data type it represents.
For example, a BasicTypeInfo returns a serializer that writes the respective primitive type, the serializer of a WritableTypeInfo delegates de/serialization to the write() and readFields() methods of the object implementing Hadoop’s Writable interface, and a GenericTypeInfo returns a serializer that delegates serialization to Kryo.
Object serialization to a DataOutput which is backed by Flink MemorySegments goes automatically through Java’s efficient unsafe operations.
For data types that can be used as keys, i.e., compared and hashed, the TypeInformation provides TypeComparators. TypeComparators compare and hash objects and can - depending on the concrete data type - also efficiently compare binary representations and extract fixed-length binary key prefixes.
在TypeInformation中,主要包含serializer,类型会自动通过serializer进行序列化,然后用java unsafe接口写入MemorySegments
当然对于可以用作key的数据类型,还包含TypeComparators,用于compared和hashed
Tuple, Pojo, and CaseClass types are composite types, i.e., containers for one or more possibly nested data types. As such, their serializers and comparators are also composite and delegate the serialization and comparison of their member data types to the respective serializers and comparators. The following figure illustrates the serialization of a (nested)Tuple3<Integer, Double, Person> object where Person is a POJO and defined as follows:
public class Person {
public int id;
public String name;
}对于Pojo对象,我们具体看看是如何被存入MemorySegments的,
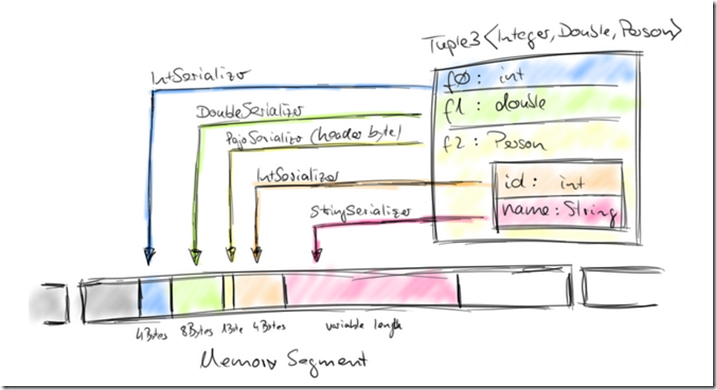
可以看出,存储是相当紧凑的,
int占4个字节,double占8个字节
pojo,也只多了1个字节的header
serializer也是经过优化的,Pojo Serializer只负责序列化Pojo head
How does Flink operate on binary data?
Similar to many other data processing APIs (including SQL), Flink’s APIs provide transformations to group, sort, and join data sets. These transformations operate on potentially very large data sets.
Relational database systems feature very efficient algorithms for these purposes since several decades including external merge-sort, merge-join, and hybrid hash-join.
Flink builds on this technology, but generalizes it to handle arbitrary objects using its custom serialization and comparison stack.
In the following, we show how Flink operates with binary data by the example of Flink’s in-memory sort algorithm.
Flink提供如group,sort,join等操作,这些操作可能需要access海量的数据集,关系型数据库在过去几十年中积累的大量有效的算法来解决这类问题;
Flink基于这些技术,并使其通用化,用于处理flink中的非关系型数据
下面就看看Flink是如何进行in-memory sort
Flink assigns a memory budget to its data processing operators.
Upon initialization, a sort algorithm requests its memory budget from the MemoryManager and receives a corresponding set of MemorySegments.
The set of MemorySegments becomes the memory pool of a so-called sort buffer which collects the data that is be sorted.
首先,Flink会从MemorySegmentPool里面来申请MemorySegments来进行存放排序的结果,
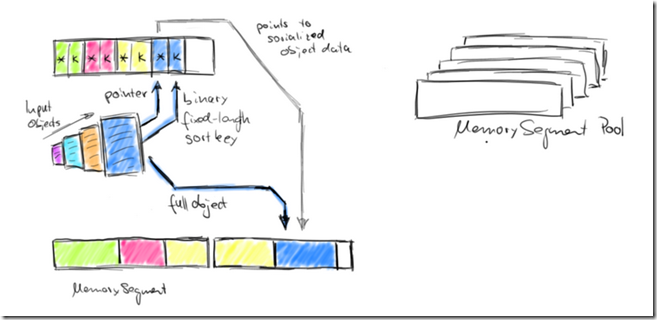
The sort buffer is internally organized into two memory regions.
The first region holds the full binary data of all objects. The second region contains pointers to the full binary object data and - depending on the key data type - fixed-length sort keys.
When an object is added to the sort buffer, its binary data is appended to the first region, and a pointer (and possibly a key) is appended to the second region.
The separation of actual data and pointers plus fixed-length keys is done for two purposes.
It enables efficient swapping of fix-length entries (key+pointer) and also reduces the data that needs to be moved when sorting.
If the sort key is a variable length data type such as a String, the fixed-length sort key must be a prefix key such as the first n characters of a String. Note, not all data types provide a fixed-length (prefix) sort key. When serializing objects into the sort buffer, both memory regions are extended with MemorySegments from the memory pool.
我们排序的时候,在内存中把数据的key和真实的数据object,分成两部分存放;
这样做有两个好处,第一是排序的时候,需要做swap,这样只需要swap key而不需要swap真实的数据;
第二,这样是cache友好的,key都是连续的存储在内存中,大大减少cache miss
Once the memory pool is empty and no more objects can be added, the sort buffer is completely filled and can be sorted.
Flink’s sort buffer provides methods to compare and swap elements. This makes the actual sort algorithm pluggable. By default, Flink uses a Quicksort implementation which can fall back to HeapSort. The following figure shows how two objects are compared.
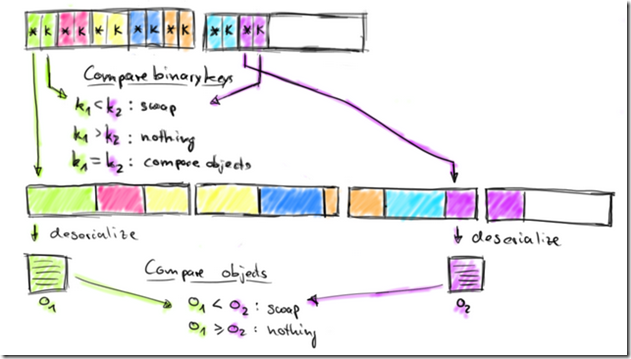
The sort buffer compares two elements by comparing their binary fix-length sort keys.
The comparison is successful if either done on a full key (not a prefix key) or if the binary prefix keys are not equal.
If the prefix keys are equal (or the sort key data type does not provide a binary prefix key), the sort buffer follows the pointers to the actual object data, deserializes both objects and compares the objects. Depending on the result of the comparison, the sort algorithm decides whether to swap the compared elements or not.
The sort buffer swaps two elements by moving their fix-length keys and pointers. The actual data is not moved.
Once the sort algorithm finishes, the pointers in the sort buffer are correctly ordered. The following figure shows how the sorted data is returned from the sort buffer.
上面的图,给出排序的过程,排序首先是要比大小
这里可以先用key比大小,这样就可以直接用二进制的key而不需要做反序列化
如果,通过二进制的key无法比出大小,或者根本就没有二进制的key,那就必须要把object数据,反序列化出来,然后再比较
然后,只需要swap key,就可以达到排序的效果
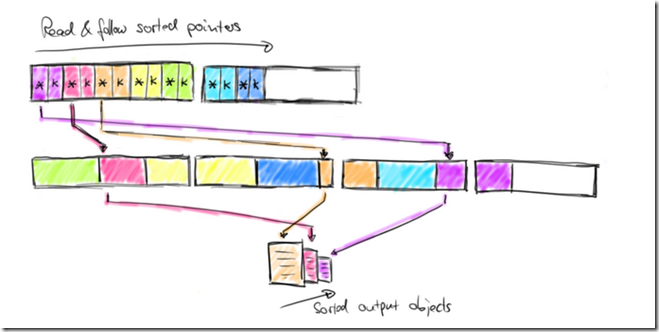
The sorted data is returned by sequentially reading the pointer region of the sort buffer, skipping the sort keys and following the sorted pointers to the actual data.
This data is either deserialized and returned as objects or the binary representation is copied and written to disk in case of an external merge-sort (see this blog post on joins in Flink).
然后最终,安装排好序key,通过point找到相应的data,相应的存入文件中
Flink - Juggling with Bits and Bytes的更多相关文章
- 深入理解Apache Flink核心技术
深入理解Apache Flink核心技术 2016年02月18日 17:04:03 阅读数:1936 标签: Apache-Flink数据流程序员JVM 版权声明:本文为博主原创文章,未经博主允许 ...
- 脱离JVM? Hadoop生态圈的挣扎与演化
本文由知乎<大数据应用与实践>专栏 李呈祥授权发布,版权所有归作者,转载请联系作者! 新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出 ...
- Java Primitives and Bits
Integer when processors were 16 bit, an int was 2 bytes. Nowadays, it's most often 4 bytes on a 32 b ...
- 为什么要用base64编码
1.需求 了解为什么要使用base64对数据编码 2.理由 因为传输二进制数据的时候,网络中间的有些路由会把ascii码中的不可见字符删了,导致数据不一致.一般也会对url进行base64编码 Whe ...
- HTTrack 网站备份工具
HTTrack可以克隆指定网站-把整个网站下载到本地.可以用在离线浏览上,免费的噢! 强大的Httrack类似于搜索引擎的爬虫,也可以用来收集信息.记得之前写过篇http://www.cnblogs. ...
- 有关binlog的那点事(三)(mysql5.7.13)
这次我们要探索更精细的binlog内容,上次讨论的Query_event和Rows_event肯定有让你疑惑不解的问题.Query_event中的status-vars环境变量有哪些,Rows_eve ...
- What does "size" in int(size) of MySQL mean?
What does "size" in int(size) of MySQL mean? https://alexander.kirk.at/2007/08/24/what-doe ...
- Assembler : The Basics In Reversing
Assembler : The Basics In Reversing Indeed: the basics!! This is all far from complete but covers ab ...
- Linux Overflow Vulnerability General Hardened Defense Technology、Grsecurity/PaX
Catalog . Linux attack vector . Grsecurity/PaX . Hardened toolchain . Default addition of the Stack ...
随机推荐
- phpcms如何使用推荐位调用自定义字段
默认phpcms是无法使用推荐位调用自定义字段的 一般自定义字段默认添加在附表里(也可以添加在主表里),调用自定义字段时 加上moreinfo="1" 直接写{pc:content ...
- Android适配器之ArrayAdapter、SimpleAdapter和BaseAdapter的简单用法与有用代码片段(转)
摘自:http://blog.csdn.net/shakespeare001/article/details/7926783 Adapter是连接后端数据和前端显示的适配器接口,是数据Data和UI( ...
- Codeforces Round #313 (Div. 2) A. Currency System in Geraldion
A. Currency System in Geraldion Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/co ...
- Java的内存模型
"让计算机并发执行若干个运算任务"与"更充分地利用计算机处理器的效能"之间的因果关系,看起来顺理成章,实际上它们之间的关系并没有想象中的那么简单,其中一个重要的 ...
- Task加入取消功能
参考:http://www.cnblogs.com/scy251147/archive/2013/01/04/2843875.html static void TaskWithCancellati ...
- Open Xml SDK Word模板开发最佳实践(Best Practice)
1.概述 由于前面的引文已经对Open Xml SDK做了一个简要的介绍. 这次来点实际的——Word模板操作. 从本质上来讲,本文的操作都是基于模板替换思想的,即,我们通过替换Word模板中指定元素 ...
- PHP中常见的页面跳转方法
转载自冠威博客 [ http://www.guanwei.org/ ]本文链接地址:http://www.guanwei.org/post/PHPnotes/04/php-redirect-metho ...
- CC150 - 11.5
Question: Given a sorted array of strings which is interspersed with empty strings, write a method t ...
- 编译gcc4.7.3 其他版本的应该也可以
编译它真麻烦啊..耗费了我一下午..我是ubuntu10.10环境的.内置的gcc版本很老了,好像是4.2吧.源里又没有高版本的,于是自己编译了. 准备 下载gcc:点我打开 //源,找个最快的.下你 ...
- 【wikioi】1034 家园(最大流+特殊的技巧)
http://wikioi.com/problem/1034/ 太神了这题. 其实一开始我以为是费用流,但是总感觉不对. 原因是我没看到一句话,特定的时刻到达特定的点!! 也就是说,并不是每艘船每次都 ...