mysql高可用方案总结性说明
MySQL的各种高可用方案,大多是基于以下几种基础来部署的(也可参考:Mysql优化系列(0)--总结性梳理 该文后面有提到)
1)基于主从复制;
2)基于Galera协议(PXC);
3)基于NDB引擎;
4)基于中间件/proxy;
5)基于共享存储;
6)基于主机高可用;
在这些可选项中,最常见的就是基于主从复制的方案,其次是基于Galera的PXC方案,我们重点说说这两种方案。其余几种方案在生产上用的并不多,我们只简单说下。
一、主从复制的高可用方案:
(1)双节点主从+keepalived/heartbeat
一般来说,中小型规模的时候,采用这种架构是最省事的。
两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。
在这个方案里,有几个需要注意的地方:
1)采用keepalived作为高可用方案时,两个节点最好都设置成BACKUP模式,避免因为意外情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;
2)把两个节点的auto_increment_increment(自增步长)和auto_increment_offset(自增起始值)设成不同值。其目的是为了避免master节点意外宕机时,可能会有部分binlog未能及时复制到slave上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增ID冲突的话,也可以不这么做;
3)slave节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,硬件配置不能低于master节点;
4)如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7最新版本,利用多线程复制的方式可以很大程度降低复制延迟;
5)对复制延迟特别敏感的另一个备选方案,是采用semi sync replication(就是所谓的半同步复制)或者后面会提到的PXC方案,基本上无延迟,不过事务并发性能会有不小程度的损失,需要综合评估再决定;
6)keepalived的检测机制需要适当完善,不能仅仅只是检查mysqld进程是否存活,或者MySQL服务端口是否可通,还应该进一步做数据写入或者运算的探测,判断响应时间,如果超过设定的阈值,就可以启动切换机制;
7)keepalived最终确定进行切换时,还需要判断slave的延迟程度。需要事先定好规则,以便决定在延迟情况下,采取直接切换或等待何种策略。直接切换可能因为复制延迟有些数据无法查询到而重复写入;
8)keepalived或heartbeat自身都无法解决脑裂的问题,因此在进行服务异常判断时,可以调整判断脚本,通过对第三方节点补充检测来决定是否进行切换,可降低脑裂问题产生的风险。
双节点主从+keepalived/heartbeat方案架构示意图见下:
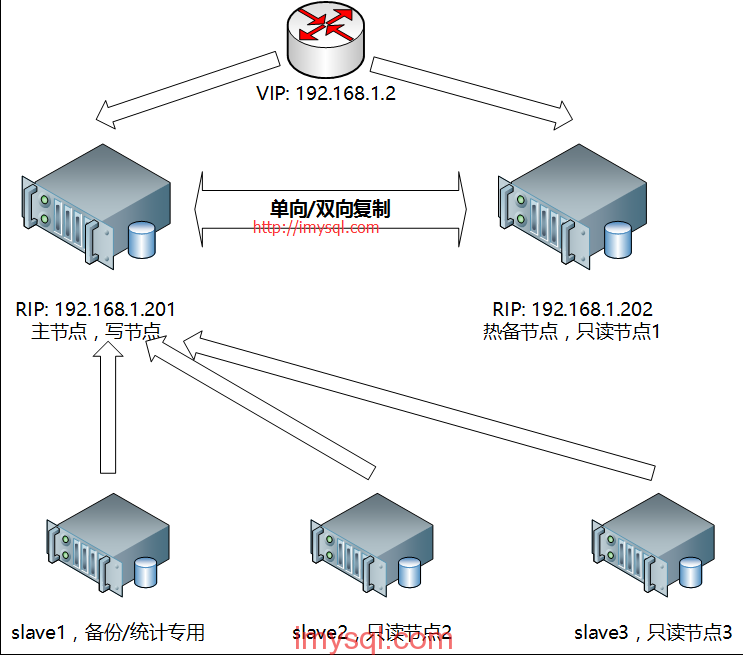
图解:MySQL双节点(单向/双向主从复制),采用keepalived实现高可用架构。
(2)多节点主从+MHA/MMM
多节点主从,可以采用一主多从,或者双主多从的模式。
这种模式下,可以采用MHA或MMM来管理整个集群,目前MHA应用的最多,优先推荐MHA,最新的MHA也已支持MySQL 5.6的GTID模式了,是个好消息。
MHA的优势很明显:
1)开源,用Perl开发,代码结构清晰,二次开发容易;
2)方案成熟,故障切换时,MHA会做到较严格的判断,尽量减少数据丢失,保证数据一致性;
3)提供一个通用框架,可根据自己的情况做自定义开发,尤其是判断和切换操作步骤;
4)支持binlog server,可提高binlog传送效率,进一步减少数据丢失风险。
不过MHA也有些限制:
1)需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃;
2)自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
(3)多节点主从+etcd/zookeeper
在大规模节点环境下,采用keepalived或者MHA作为MySQL的高可用管理还是有些复杂或麻烦。
首先,这么多节点如果没有采用配置服务来管理,必然杂乱无章,线上切换时很容易误操作。
在较大规模环境下,建议采用etcd/zookeeper管理集群,可实现快速检测切换,以及便捷的节点管理。
二、基于Galera协议的高可用方案
Galera是Codership提供的多主数据同步复制机制,可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。
基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。
PXC的架构示意图见下:
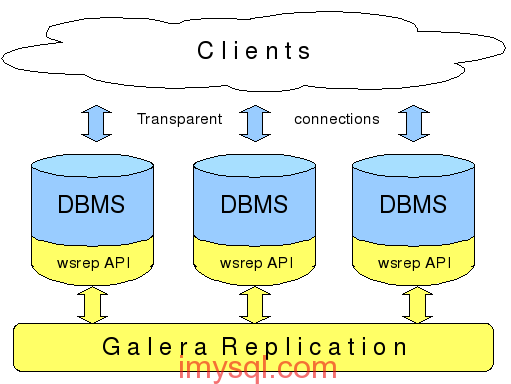
(图片源自网络),图解:在底层采用wsrep接口实现数据在多节点间的同步复制。
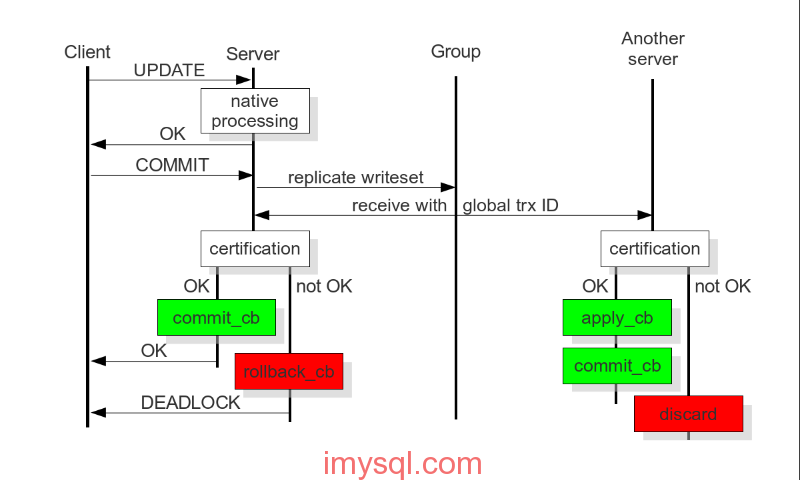
(图片源自网络),图解:在PXC中,一次数据写入在各个节点间的验证/回滚流程。
PXC的优点:
1)服务高可用;
2)数据同步复制(并发复制),几乎无延迟;
3)多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;
4)新节点可以自动部署,部署操作简单;
5)数据严格一致性,尤其适合电商类应用;
6)完全兼容MySQL;
虽然有这么多好处,但PXC也有些局限性:
1)只支持InnoDB引擎;
2)所有表都要有主键;
3)不支持LOCK TABLE等显式锁操作;
4)锁冲突、死锁问题相对更多;
5)不支持XA;
6)集群吞吐量/性能取决于短板;
7)新加入节点采用SST时代价高;
8)存在写扩大问题;
9)如果并发事务量很大的话,建议采用InfiniBand网络,降低网络延迟;
事实上,采用PXC的主要目的是解决数据的一致性问题,高可用是顺带实现的。因为PXC存在写扩大以及短板效应,并发效率会有较大损失,类似semi sync replication机制。
其他高可用方案
1)基于NDB Cluster,由于NDB目前仍有不少缺陷和限制,不建议在生产环境上使用;
2)基于共享存储,一方面需要不太差的存储设备,另外共享存储可也会成为新的单点,除非采用基于高速网络的分布式存储,类似RDS的应用场景,架构方案就更复杂了,成本也可能更高;
3)基于中间件(Proxy),现在可靠的Proxy选择并不多,而且没有通用的Proxy,都有有所针对,比如有的专注解决读写分离,有的专注分库分表等等,真正好用的Proxy一般要自行开发;
4)基于主机高可用,是指采用类似RHCS构建一个高可用集群后,再部署MySQL应用的方案。老实说,我没实际用过,但从侧面了解到这种方案生产上用的并不多,可能也有些局限性所致吧;
mysql高可用方案总结性说明的更多相关文章
- [转]MYSQL高可用方案探究(总结)
前言 http://blog.chinaunix.net/uid-20639775-id-3337432.htmlLvs+Keepalived+Mysql单点写入主主同步高可用方案 http://bl ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
- mysql高可用方案MHA介绍
mysql高可用方案MHA介绍 概述 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA, ...
- Heartbeat+DRBD+MySQL高可用方案【转】
转自Heartbeat+DRBD+MySQL高可用方案 - yayun - 博客园 http://www.cnblogs.com/gomysql/p/3674030.html 1.方案简介 本方案采用 ...
- MySQL高可用方案MHA的部署和原理
MHA(Master High Availability)是一套相对成熟的MySQL高可用方案,能做到在0~30s内自动完成数据库的故障切换操作,在master服务器不宕机的情况下,基本能保证数据的一 ...
- MySQL高可用方案MHA自动Failover与手动Failover的实践及原理
集群信息 角色 IP地址 ServerID 类型 Master ...
- MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解
MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解 Percona XtraDB Cluster简称PXC.Percona Xtradb Cluster的实现是在 ...
- MySQL高可用方案--MHA部署及故障转移
架构设计及必要配置 主机环境 IP 主机名 担任角色 192.168.192.128 node_master MySQL-Master| ...
- MySQL高可用方案MHA在线切换的步骤及原理
在日常工作中,会碰到如下的场景,如mysql数据库升级,主服务器硬件升级等,这个时候就需要将写操作切换到另外一台服务器上,那么如何进行在线切换呢?同时,要求切换过程短,对业务的影响比较小. MHA就提 ...
随机推荐
- C++调用C#dll类库中的方法(非显性COM)
一般在网上搜C++如何调用C#的函数,出来的结果都是做成COM组件,但是这种方法dll安装麻烦,需要注册COM组件,需要管理员权限,调试麻烦,经常需要重启机器,反正有诸多不便. 然后在看<CLR ...
- Linux0.11内核剖析--初始化程序(init)
1.概述 在内核源代码的 init/目录中只有一个 main.c 文件. 系统在执行完 boot/目录中的 head.s 程序后就会将执行权交给 main.c.该程序虽然不长,但却包括了内核初始化的所 ...
- IOS字典NSDictionary与NSMutableDictionary知识点
字典中的元素是以键值对的形式存储的,键值对的键和值,都是任意的对象,但是键往往使用字符串,字典存储对象的地址没有顺序,字典的遍历分为:键的遍历和值的遍历,字典与数组的区别:数组讲究顺序,而字典可以快速 ...
- android 学习运用海马模拟器教程与android环境的搭建
第三方海马玩模拟器 第一天的学习android采用的模拟器是海马,因此就分享给大家海马模拟器的相关步骤: 海马玩模拟器官网: http://droid4x.haimawan.com 下载相关平台的模拟 ...
- iOS Technology Overview_Introduction
关于iOS技术 iOS是运行在iPad,iPhone和iPod touch设备上的操作系统.这个操作系统管理着这些设备的硬件并且提供了实现原生APP所需的技术.这个操作系统也附带许多系统APP,例如P ...
- Linux平台卸载MySQL总结【转】
最近用到了mysql主从,顺手看到了这篇文章,拿出来分享一下. 转自:http://www.cnblogs.com/kerrycode/p/4364465.html 潇湘隐者 RPM包安装方式的MyS ...
- Linux 环境变量的配置
一. 环境变量相关的几个配置文件(针对bash): 1. /etc/profile 系统环境变量配置文件:针对整个系统的所有用户生效,系统启动后用户第一次登陆时,此文件被执行,并从/etc/prof ...
- cocos2d-x之value
bool HelloWorld::init() { if ( !Layer::init() ) { return false; } Size visibleSize = Director::getIn ...
- nyoj 284 坦克大战 简单搜索
题目链接:http://acm.nyist.net/JudgeOnline/problem.php?pid=284 题意:在一个给定图中,铁墙,河流不可走,砖墙走的话,多花费时间1,问从起点到终点至少 ...
- 【ubuntu】中文输入法安装二三事
本来很愉快地刷着JS程序,很有感慨啊,想写篇博客记一下学习笔记,结果忘记了博客账号,后来通过邮箱找回了之后想要开始写..发现ubuntu的中文输入法不能用啊(其实不是不能用,就是小白没搞清楚状况,双系 ...