论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf
code链接:https://github.com/YangZhang4065/AdaptationSeg
摘要:
在过去的5年里面,卷积神经网络在语义分割领域大获全胜,语义分割是许多其他应用的核心任务之一,这其中包括无人驾驶、增强现实。然而,训练一个卷积神经网络需要大量的数据,而对于这些数据的收集和标注是极其困难的。计算机图形学领域的最新研究进展使得利用计算机生成的注释在接近真实照片的合成图像上训练CNN成为可能。尽管如此,真实图像和合成数据之间的域不匹配阻碍了模型的性能。鉴于此,我们提出了一种课程式( curriculum-style )学习方法,以最小化城市场景语义分割中的域差距。课程域适应方法首先解决简单的任务,以推断关于目标域的必要属性; 第一项任务是学习图像上的全局标签分布和地标超像素( landmark superpixels),这些很容易估计,因为城市场景的图像具有强烈的特性(例如,建筑物,街道,汽车等的大小和空间关系)。然后,我们训练分段网络,同时在目标域中规范其预测以遵循那些推断的属性。在实验中,我们的方法优于两个数据集和两个骨干网络的baseline。 文章还报告了有关我们所提方法的大量消融研究。
1、Introduction
语义分割是计算机视觉领域最具挑战性也最基础的问题之一。它为一幅图像的每个像素分配语义标签。其输出结果是针对图像的一个密集而丰富的注释,每一个像素都有一个属于自己的语义标签。语义分割对一些下游应用很有帮助,在无人驾驶方面取得了重大进展。实际上,已经开发了几种用于自动驾驶研究的数据集和测试套件,其中,语义分割通常被认为是关键任务之一。
在过去的几年中,卷积神经网络已经成为解决大规模图像集的语义分割问题的一个标志性主干模式。所有的最先进方法都依赖于卷积神经网络。卷积神经网络能够取得很高准确率的原因在于,训练集足够大且每幅图片均被良好的标注。然而,在实际应用中的现实生活场景中,想要获取满足这些要求的数据集是十分困难的。即使能够得到如此大的数据集,对每幅图进行逐像素的语义标注也是枯燥而困难的。例如,在 Cityscapes数据集中,平均一幅图片的像素级标注耗时1.5小时,其工作量可想而知。
这些挑战促使研究人员通过使用补充合成数据来应对这一分割问题。使用现代图形引擎,自动合成多样化的城市场景图像以及像素标签将需要非常少量的甚至零人工操作。但是,它并不能完全达到与真实数据一样的效果,甚至在合成图像和真实图像之间会出现严重的不匹配问题。导致不匹配的因素有很多,例如场景布局、获取图像的设备、观察视角、光照条件、阴影、纹理等等。
本文中,我们的主要目标是研究域自适应技术的使用,以更有效地将使用合成图像训练的语义分割网络转移到用于真实图像的高质量分割网络。我们在之前的工作[11]的基础上进行改进,之前的那篇工作我们提出了一种新的域适应方法来进行城市场景的语义分割。
域适应,旨在当感兴趣的目标域不同于模型训练的域时提高模型的性能,长期以来一直是机器学习和计算机视觉领域的热门话题。由于深度神经网络的普遍存在,它最近甚至引起了更多的关注乃至于迁移学习,而这些网络通常是“数据饥饿”的。直观的域自适应策略是学习两个域的图像的域不变特征表示,其中源域提供标记的训练集,目标域在众多未标记是图像中显示零到若干标记图像。在这种情况下,源域特征将类似于目标域的特征。因此,在标记的源域上训练的模型可以推广到目标域。早期的“浅层”方法通过利用数据的各种内在结构来实现这些目标。与之相反,最近的“深层”方法则主要设计新的损失函数和/或网络结构,以向通过神经网络反向传播的梯度添加域不变成分。
在观察到先前域自适应任务中学习域不变特征的成功之后,遵循相同的原则来适应语义分割模型变成了普遍的趋势。然而,该原理的基本假设可能阻止围绕它设计的方法实现高适应性能。通过学习域不变特征X(假定条件分布P(Y|X),其中Y表示像素标签),多多少少被两个域所共享。当分类边界变得越来越复杂时,该假设不太可能成立 - 用于语义分割的预测函数必定是复杂的。像素标签集是高维的,高度结构化的和相互依赖的,这意味着学习者必须在指数大的标签空间中解决预测问题。此外,如果不仔细考虑结构化标签而匹配两个域的特征表示,那么数据中的一些判别性提示将被抑制。最后,数据实例是衡量域差异的替代品。然而,目前尚不清楚语义分割中所包含实例的内容,特别是考虑到最佳表现的分割方法是建立在深度神经网络上的。霍夫曼将全卷积网络(FCN)中的每个空间单元作为实例。我们认为这样的实例实际上是非独立同分布的( non-i.i.d)。因为在任何一个域中,它们的感受野(感受野:在卷积神经网络CNN中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野receptive field。)彼此重叠。
那么,我们如何避免源域和目标域在转换的域不变特征空间中共享相同的预测函数这一假设呢?我们提出的解决方案基于两个关键的观察。其一,城市交通场景图像具有很强的特质,因此,由于域差异而受到的影响较小,一些任务实现起来比较简单。例如,很容易从交通场景图像推断出道路经常占据比交通标志更多的像素。其二,与模型参数上的通用正则化相反,语义分割中的结构化输出使得实现便利的后验正则化成为可能。
因此,我们提出了一种课程式( curriculum-style )的学习方法。回顾一下,在域适应方法中,当目标域几乎没有或只有稀少的标签时,唯有源域能够提供大量已被标注好的数据。我们的课程式域适应始于简单的方法,目的在于为每一个目标图片取得若干关于未知像素级标签的高质量属性。
为了进一步发展课程的简单任务,我们考虑在全局图像和目标域的一些标志性超像素上估计标签分布。以前者为例,标签分布揭示了图像中与每个类别对应的像素百分比。尽管存在域不匹配的问题,我们仍然认为,这些任务比预测像素标签更容易。标签分布仅是关于标签统计数据的粗略估计。此外,道路,建筑物,天空,人等之间的大小关系约束了分布的形状,有效地减少了搜索空间。最后,用于估计超像素标签分布的模型或受益于城市场景超越领域的规范布局,例如,建筑常常分布于街道两边。
这些似乎简单的标签分布对语义分割的域适应有用,那么是何原因,又是何时起作用的呢?在实验中,我们发现在源域上训练得到的分割网络在许多目标图片上表现并不好,这引起了不成比例的标签分配,例如,更多像素被分类为人行道而不是街道。为修正这一问题,图像级别的标签分布通知分段网络如何更新预测,而锚超像素( anchor superpixels)的标签分布告诉网络更新的位置。它们共同指导网络适应目标域,生成合理的标签预测。请注意,将来可以将其他“简单任务”纳入我们的方法中。
我们的主要贡献在于提出了针对城市场景的课程式的域适应方法。我们为课程选择了推断目标图像和地标超像素的标签分布的简单有用的任务,以获得关于目标域的一些必要属性。基于以上这些,我们从已被标注好的源数据中学习到了一个像素级的判别分割网络,与此同时,我们进行“健全性检查”以确保网络表现与先前学习的关于目标域的知识一致。我们的方法有效地避免了关于在变换的特征空间中存在两个域的共同预测函数的假设。它也容易应用于不同的分割网络,因为它并不会改变网络架构,也不会影响任何的中间层。
除了我们先前的工作[11],我们提供了更多关于所提方法的算法细节和实验研究,包括使用GTA数据集的新实验以及关于超像素数量,超像素特征表示,各种主干神经网络,预测混淆矩阵等的消融研究。此外,我们在我们的框架中引入了颜色恒常性方案,这显着提高了自适应性能,并且可以作为独立的图像预处理步骤加入到任何域自适应方法中。我们还定量地测量合成数据的“市场价值(market value)”,以揭示它可以从实际图像的标签中节省多少成本。最后,我们提供了一个关于我们提出的成果[11]之后发表的关于语义分割领域适应性的著作的综合调查。我们将它们分组为不同的类别,并且通过实验证明其他方法是我们方法的补充。
2、Related work
在这一部分,我们主要讨论了域适应和语义分割方面的相关工作。第5部分提供了用于语义分割的域适应方法的更具针对性的综述,以及其他方法和我们方法中不同类别之间的互补效应的实验研究。
2.1 域适应(Domain adaptation)
卷积机器学习算法依赖于训练数据和测试数据被刻画为来自同一基础分布的独立同分布这一假设。然而,通常情况是训练和测试阶段之间存在一些差异。域适应旨在修正这些不匹配,并且在测试阶段精调算法模型,使之具有更优的泛化能力。
目前的域适应方面的工作大多集中在分类和回归问题上。
2.2 语义分割
语义分割,即为一幅图的每个像素分配目标标签类别。
3、Approach
该部分,我们展示了我们的课程领域适应方法的细节,用于城市场景图像的语义分割。之前的一些工作,通过中间特征空间对齐域并由此隐含地假设存在两个域的单个决策函数,我们的直觉是,对于结构化预测(即,这里的语义分割),如果我们避免这种假设,而是根据他们应该保留在目标域中的必要属性来训练它们,则可以更有效地改进机器学习模型的跨域泛化能力。针对准备工作简洁的介绍之后,我们将介绍如何使用估计的目标域属性来促进训练期间的语义分割自适应。接着,我们会将目光集中于目标域属性的类别以及如何估计它们。
3.1 准备工作(Preliminaries)
特别地,感兴趣的属性涉及来自目标域的任意图像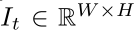 的像素级类别标签
的像素级类别标签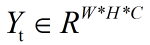 ,其中W、H分别表示输入图片的宽和高,C为类别个数。我们对groundtruth标签使用one-hot vector编码,比如,Yt (i,j,c)取值非0即1,字母意思为,第c个标签由人类标注者分配给(i,j)处的像素。相应的,通过一个分割网络之后的预测值
,其中W、H分别表示输入图片的宽和高,C为类别个数。我们对groundtruth标签使用one-hot vector编码,比如,Yt (i,j,c)取值非0即1,字母意思为,第c个标签由人类标注者分配给(i,j)处的像素。相应的,通过一个分割网络之后的预测值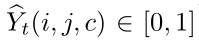 通过逐像素的softmax函数来实现。
通过逐像素的softmax函数来实现。
我们以类别C的分布pt的形式表达每个目标属性,其中,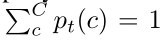 ,且
,且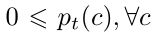 。pt(c)表示类别c相对于第t个目标图像或该图像的超像素的占有率。因此,我们可以在给定图像的人工注释Yt的情况下立即计算出分布pt。例如,图像级标签分布由下面公式(1)计算:
。pt(c)表示类别c相对于第t个目标图像或该图像的超像素的占有率。因此,我们可以在给定图像的人工注释Yt的情况下立即计算出分布pt。例如,图像级标签分布由下面公式(1)计算:
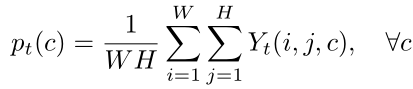
类似的,我们可以计算估计出来自网络预测值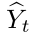 的目标属性或者分布,并且通过
的目标属性或者分布,并且通过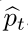 来表示目标属性或者分布,见下面公式(2):
来表示目标属性或者分布,见下面公式(2):
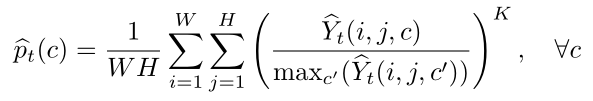
其中K> 1是一个大常数,其效果是“锐化”每个像素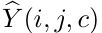 的softmax激活函数,使得summand(被加数)为1或非常接近0,其形状与式(1)的summad
的softmax激活函数,使得summand(被加数)为1或非常接近0,其形状与式(1)的summad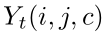 相似。在实验中,我们设置K值为6,因为较大的K值会导致数值不稳定。最后,我们正则化向量
相似。在实验中,我们设置K值为6,因为较大的K值会导致数值不稳定。最后,我们正则化向量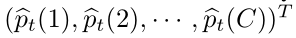 ,这样以来,它的元素都大于0并且总和为1——换句话说,向量保持在有效的分布状态。
,这样以来,它的元素都大于0并且总和为1——换句话说,向量保持在有效的分布状态。
3.2 域自适应观察目标属性
理想情况下,我们希望有一个分割网络来模仿目标域的人类注释器。 因此,其注释结果属性也必然应该相同。我们通过在训练阶段最小化一个交叉熵来捕捉这一概念,下面等式中,右边第一项是熵,第二项是KL-散度:
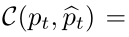
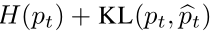
给定由源图像(S)和目标图像(T)组成的 mini-batch,用于训练跨域概泛化分割网络的总体目标函数是
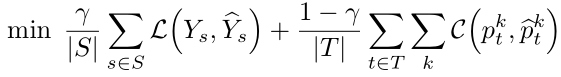
其中, 是由全部标注的源域图像的像素级交叉熵损失,赋予网络以像素级的判别能力,第二项是未标记的目标域图像,指示网络预测应该在目标域中具有哪些必要的属性。我们使用
是由全部标注的源域图像的像素级交叉熵损失,赋予网络以像素级的判别能力,第二项是未标记的目标域图像,指示网络预测应该在目标域中具有哪些必要的属性。我们使用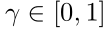 来平衡训练中的两股力量。上标k用于索引不同类型的标签分布。
来平衡训练中的两股力量。上标k用于索引不同类型的标签分布。
请注意,在无监督域自适应上下文中,我们实际上无法直接计算标签分布,因为目标域的groundtruth注释是未知的。 尽管如此,使用标记的源域数据,这些分布比目标图像的每个像素的标签更容易估计。
Remarks.从数学上说,目标函数和模型压缩具有相似的形式。因此,我们借用更多的概念,以对我们的域适应过程进行更加直观的解读和理解。“学生”网络遵循课程,以便在解决目标域的简单知识之前解决语义分割图像的难度。 推断目标属性的模型就像“教师”一样,因为它们暗示了最终解决方案(图像注释)在图像和超像素级别的目标域中可能具有的标签分布。
另一视角是将目标属性理解为网络的后正则化。后正则化可以将先验知识方便的解码为目标函数。一些应用会使用这一方法,包括弱监督分割和检测,神经网络的ReLU正则化训练。除了域适应设置和新的目标属性之外,我们工作的另一个关键区别是我们将标签分布与网络预测分离,从而避免EM类型的优化,这通常涉及并且引起额外的计算开销。 我们的方法通过对流行的深度学习工具进行几乎毫不费力的改变来学习分割网络。
3.3 推测目标属性
到目前为止,我们已经在课程领域适应中提出了“困难”任务 - 学习分割神经网络。在这一部分,我们将描述“简单”任务,比如,如何在没有任何来自目标域的标注的情况下推测目标域的属性。我们的贡献也包括选择标签分布的特定形式来组成简单的任务。
3.3.1 图像的全局标签分布
由于域差距,可以训练源域上的基线分割网络,由于目标图像的原因,它可能很容易瘫痪。通过实验,我们发现,我们的基线网络不断误识别人行道和汽车行驶街道。因此,对于像素的预测标签是极度不匹配的。
为修正之,我们使用全局图像上的标签分布pt作为首要属性。在不访问目标标签的情况下,我们必须从标记的源图像训练机器学习模型以估计目标图像的标签分布p t。我们认为尽管两个任务都受到域不匹配的影响,但这并不比生成每像素预测更具挑战性。
在实验中,我们考察了这一任务上的若干不同方法。从Inception-Resnet-v2中的平均池化层的输出中提取1536D图像特征作为以下模型的输入。
Logistic regression.尽管多项逻辑回归(LR)主要用于分类,但其输出实际上是类别上的有效分布。我们通过用交叉熵损失中的one-hot矢量替换groundtruth标签分布p s来训练它,其通过公式(1)计算来自源域的人供标注。给定目标图像,我们直接将LR的输出作为估计的标签分布p t。
Mean of nearest neighbors.我们还通过简单地为每个目标图像检索多个最近邻(NN)源图像然后将其标签分布的均值传送到目标图像来测试非参数方法。我们在Inception-Resnet-v2特征空间中使用L2距离进行NN检索。
最后,我们将两个模糊的预测作为对照实验。 一个是,对于任何目标图像,输出源域中所有标签分布的均值(源均值),另一个是输出均匀分布。
3.3.2 界标超像素( landmark superpixels)的局部标签分布
在全局域中,图像级标签分布全局惩罚潜在的不成比例的分割输出。在向网络提供空间正规化方面尚不充分。在本节中,我们考虑在某些超像素上使用标签分布作为驱动网络朝向空间所需目标属性的锚点。
请注意,使用目标图像中的所有超像素来规范分割网络是不必要的,甚至是有害的,因为它太强大并且可能会否决像素方面的判别性(从完全标记的源获得域名),特别是当标签分布没有足够准确推断时。
为了具有估计某些超像素的标签分布并从所有候选超像素中选择它们的双重效果,我们使用线性SVM。首先使用线性光谱聚类将每个图像分割成100个超像素。对于源域的超像素,能够为它们中的每一个分配单个主导标签,然后使用源域的“标记”超像素训练多类SVM。给定目标图像的测试超像素,多类SVM返回类标签以及决策值,其被解释为关于对该超像素进行分类的置信度得分。在目标域中保留前30%最有信心的超像素。 然后将类标签编码成one-hot矢量,其用作关于所选地标超像素区域上的类别标签的有效分布。虽然简单,但我们发现这种方法非常有效。
为了训练上述超像素SVM,我们需要找到一种在特征空间中表示超像素的方法。我们对视觉和上下文信息进行编码以表示超像素。首先,我们使用在PASCAL CONTEXT数据集上预训练的FCN-8,该数据集具有59个不同的类别,以获得每个像素的59个检测分数。然后我们在每个超像素内平均这些分数。超像素的最终特征表示是其自身的59D向量,是其左右超像素的295D级联,以及分别在其上方和下方的两个向量表示。由于此功能表示依赖于额外的数据源,我们还在实验中检查人工实现的功能和VGG功能。
3.4 课程域适应:概述(recapitulation)
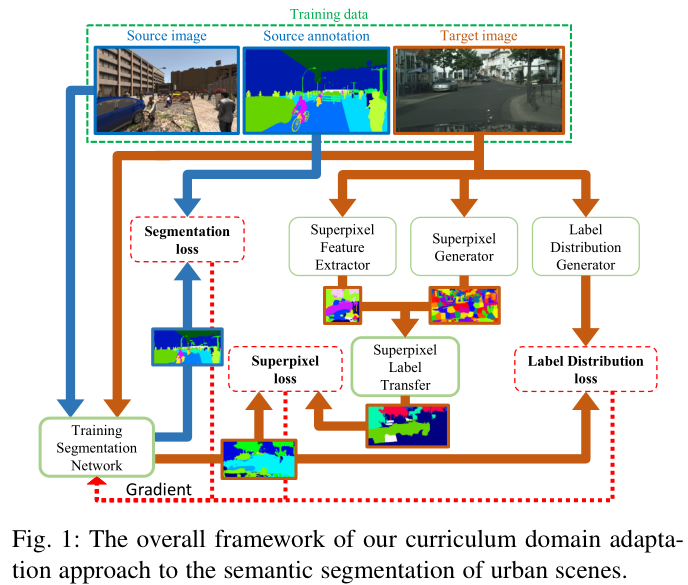
在下一节介绍实验之前,我们使用图1概述了拟议的课程领域适应性。 我们的主要想法是逐步执行域自适应,从简单的任务开始,与语义分段相比,对域差异不太敏感。 我们在这项工作中选择了全局图像和局部地标超像素的标签分布; 未来将探索更多任务。 它们的解决方案提供了源自目标域的有用渐变(参见图1中的棕色箭头),而源域为网络提供了带有良好标记的图像和分割掩模(参见图1中的深蓝色箭头)。
3.5 颜色一致性
在本小节中,我们提出了一个颜色校准预处理步骤,我们发现这一步骤非常有效地使语义分割方法从源合成域适应目标实际图像域。假设两个域的颜色是从不同的分布中提取的。将目标域图像的颜色校准为源域的颜色,从而减少它们在颜色方面的差异。在这里将其描述为一个独立的子部分,因为它可以独立存在,并且可以添加到任何现有的语义分割域适应方法中。
人类有能力感知物体的相同颜色,即使它在不同的照明下曝光,但图像捕捉传感器却没有。所以,不同的照明条件会导致由相机捕获不同的RGB图像。因此,感知不连贯性阻碍了计算机视觉算法的性能,因为照明通常是导致域不匹配的关键因素之一。为此,我们建议使用计算颜色连续性来消除照明的影响。
颜色连续的目标是将在非常规或偏置光源下获得的图像的颜色校正为在参考光照条件下应该呈现的颜色。在域自适应场景中,我们假设源域类似于参考光照条件。通过学习参数模型来描述目标和源光源,然后尝试根据源域的光恢复目标图像。然而,并非所有颜色连续性方法都适用。例如,一些方法依赖于物理先验或自然图像的统计,此二种方法在合成图像中都不可用。
综上所述,我们改为使用基于色域的颜色连续性方法来根据颜色对齐目标和源图像。该方法假设在某个光源下仅能观察到有限范围的颜色的,继而推断出光源的特性。这符合我们的假设,即目标图像的颜色和源图像的颜色属于不同的分布/范围。除了像素值之外,图像边缘和导数还用于查找映射。图2显示了分割模型对照明的敏感程度。可以看到,在应用颜色连续性之前,CityScapes图像的很大一部分被错误地归类为“地形”,因为图像有点偏绿。

6、Conclusion
在本文中,我们提出了一种课程领域适应方法,用于城市场景的语义分割。学习估计目标图像上的全局标签分布和目标图像的超像素上的局部标签分布。这些任务比逐像素标签分配更容易解决。然后,使用他们的结果有效地规范语义分割网络的训练,使得它们的像素预测与全局和局部标签分布一致。通过从合成图像的源域调整到真实图像的目标域来验证所提方法的有效性。算法性能优于几个此外,我们报告了几项关键的消融研究,这些研究使我们能够获得有关所提方法的更多认识。我们还检查了分类混淆矩阵,发现当前数据集中的某些类(例如,火车和公共汽车)几乎无法区分,这表明需要更好的模拟或更多标记的实例以获得更好的分割结果。在未来的工作中,我们将探索具有与全局和局部标签分布相同形式的更多目标属性 - 它们比像素标签预测更容易解决,同时可以作为像素标签的函数编写。我们还计划研究将域适配框架直接应用于DeepGTAV和AirSim等虚拟自动驾驶环境的可能性。
[11] Y. Zhang, P. David, and B. Gong, “Curriculum domain adaptation for semantic segmentation of urban scenes,” in IEEE International Conference on Computer Vision (ICCV), vol. 2, no. 5, Oct 2017, p. 6.
论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes的更多相关文章
- [论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation 论文原文 摘要 创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法 ...
- 论文笔记:Unsupervised Domain Adaptation by Backpropagation
14年9月份挂出来的文章,基本思想就是用对抗训练的方法来学习domain invariant的特征表示.方法也很只管,在网络的某一层特征之后接一个判别网络,负责预测特征所属的domain,而后特征提取 ...
- [论文阅读] A Discriminative Feature Learning Approach for Deep Face Recognition (Center Loss)
原文: A Discriminative Feature Learning Approach for Deep Face Recognition 用于人脸识别的center loss. 1)同时学习每 ...
- DWA局部路径规划算法论文阅读:The Dynamic Window Approach to Collision Avoidance。
DWA(动态窗口)算法是用于局部路径规划的算法,已经在ROS中实现,在move_base堆栈中:http://wiki.ros.org/dwa_local_planner DWA算法第一次提出应该是1 ...
- 论文阅读 | DeepDrawing: A Deep Learning Approach to Graph Drawing
作者:Yong Wang, Zhihua Jin, Qianwen Wang, Weiwei Cui, Tengfei Ma and Huamin Qu 本文发表于VIS2019, 来自于香港科技大学 ...
- 论文阅读笔记十一:Rethinking Atrous Convolution for Semantic Image Segmentation(DeepLabv3)(CVPR2017)
论文链接:https://blog.csdn.net/qq_34889607/article/details/8053642 摘要 该文重新窥探空洞卷积的神秘,在语义分割领域,空洞卷积是调整卷积核感受 ...
- 【论文阅读】DCAN: Deep Contour-Aware Networks for Accurate Gland Segmentation
DCAN: Deep Contour-Aware Networks for Accurate Gland Segmentation 作者:Hao Chen Xiaojuan Qi Lequan Yu ...
- 论文阅读及复现 | Effective Neural Solution for Multi-Criteria Word Segmentation
主要思想 这篇文章主要是利用多个标准进行中文分词,和之前复旦的那篇文章比,它的方法更简洁,不需要复杂的结构,但比之前的方法更有效. 方法 堆叠的LSTM,最上层是CRF. 最底层是字符集的Bi-LST ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
随机推荐
- SpringBoot与Mybatis整合的设置
Mybatis和Spring Boot的整合有两种方式: 第一种:使用mybatis官方提供的Spring Boot整合包实现,地址:https://github.com/mybatis/spring ...
- 如何查看kernel社区的变更历史
kernel社区稳定版本的地址为: https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/ 如果我们想查找某一个文件,比如 ...
- mysql-笔记 json
1 JSON 列不能有non-NULL 默认值 2 JSON值:数组:["abc",10,null,true,false] 可嵌套 对象:{"k1":" ...
- EventBus 线程切换原理
主要问题其实只有两个,其一:如何判断当前发送事件的线程是否是主线程:其二:如何在接收事件时指定线程并执行: 一个一个来看. 1.如何判断是否在主线程发送 EventBus在初始化的时候会初始化一个Ma ...
- CSS之样式属性(背景固定、圆形头像、模态框)
CSS属性 一.宽和高 width属性可以为元素设置宽度. height属性可以为元素设置高度. 块级标签才能设置宽度,内联标签的宽度由内容来决定. div {width: 1000px;backgr ...
- 面向对象__call__
__call__在Python中,函数其实是一个对象: >>> f = abs>>> f.__name__'abs'>>> f(-123)123由 ...
- Java基础 -- 访问控制权限
一 包:库单元 假设我们存在两个类名相同的类,如果没有一定的措施对其进行区分,就会无法区别到底使用的是哪一个类.因此java引入了包来进行名字空间管理. 包(类库)包含有一组类,这些类在单一的名字空 ...
- GCC __builtin_expect的作用
https://blog.csdn.net/shuimuniao/article/details/8017971 #define LIKELY(x) __builtin_expect(!!(x), 1 ...
- SpringCloud笔记一:扫盲
目录 前言 什么是微服务? 微服务的优缺点是什么? 微服务之间是如何通讯的? SpringCloud和Dubbo有哪些区别? SpringCloud和SpringBoot的关系? 什么是服务熔断?什么 ...
- oldboy s21day06
#!/usr/bin/env python# -*- coding:utf-8 -*- # 1.列举你了解的字典中的功能(字典独有).'''dic.keys() 获取所有keydic.values() ...