流式大数据计算实践(4)----HBase安装
一、前言
1、前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase
2、HBase简介
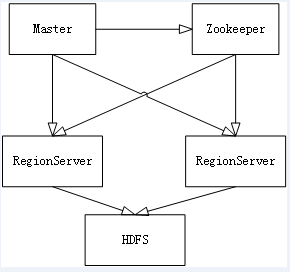
(1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表等操作,如果挂掉了也不会影响使用
(2)RegionServer节点负责存储数据,类似Hadoop里面的datanode,通过Zookeeper进行通信
(3)可以看出HBase实际上是基于HDFS的分布式数据库,但是单机模式下也可以直接用普通文件系统存储数据
二、HBase环境搭建
1、下载tar.gz包,并解压
tar zxvf /work/soft/installer/hbase-1.2.-bin.tar.gz
2、由于HBase是依赖Zookeeper的,所以HBase自带Zookeeper,我们先从单机模式搭建开始学习,先把之前搭建的集群停掉
3、进入到HBase目录的conf/hbase-site.xml文件,配置HBase的目录,以下目录HBase会自动创建
vim /work/soft/hbase-1.2./conf/hbase-site.xml <property>
<name>hbase.rootdir</name>
<value>file:///work/hbase/root</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/work/hbase/zookeeper/data</value>
</property>
4、启动HBase单机模式
/work/soft/hbase-1.2./bin/start-hbase.sh
5、通过jps查看进程是否存在

6、进入HBase的命令行
/work/soft/hbase-1.2./bin/hbase shell

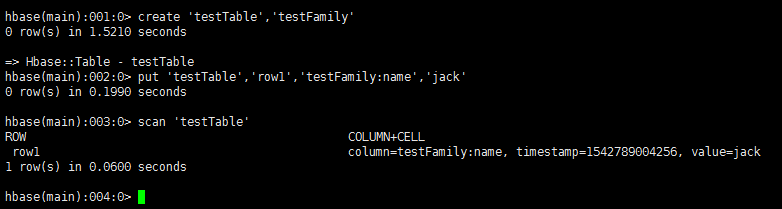
7、我们尝试一下建表、插入数据、查询的操作,看到结果就说明单机模式成功搭建!
create 'testTable','testFamily' put 'testTable','row1','testFamily:name','jack' scan 'testTable'
8、接下来搭建分布式模式,先停掉单机模式
/work/soft/hbase-1.2./bin/stop-hbase.sh
9、然后删除刚刚自动创建的目录
rm -rf /work/hbase/root
rm -rf /work/hbase/zookeeper/data
10、由于HBase默认自动开启自带的Zookeeper,所以我们设置为不开启,用自己的Zookeeper
vim /work/soft/hbase-1.2./conf/hbase-env.sh export HBASE_MANAGES_ZK=false
11、手动创建日志文件夹
mkdir /work/hbase/logs
12、配置hbase-env.sh
(1)配置Hadoop的配置文件目录
(2)配置日志文件夹的目录(也就是刚刚手动创建的那个目录)
vim /work/soft/hbase-1.2./conf/hbase-env.sh export HBASE_CLASSPATH=/work/soft/hadoop-2.6./etc/hadoop
export HBASE_LOG_DIR=/work/hbase/logs
13、配置hbase-site.xml
(1)配置我们的Hadoop集群id
(2)开启分布式开关
(3)配置Zookeeper集群
vim /work/soft/hbase-1.2./conf/hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://stormcluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>storm1,storm2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/work/hbase/zookeeper/data</value>
</property>
14、启动HBase集群
(1)首先启动我们的Hadoop集群
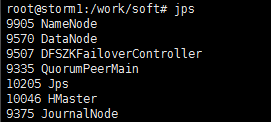
(2)启动Master
/work/soft/hbase-1.2./bin/hbase-daemon.sh start master
(3)用jps命令查看进程是否存在
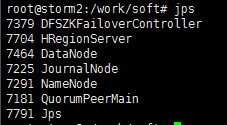
(4)启动RegionServer
/work/soft/hbase-1.2./bin/hbase-daemon.sh start regionserver
(5)用jps命令查看进程是否存在
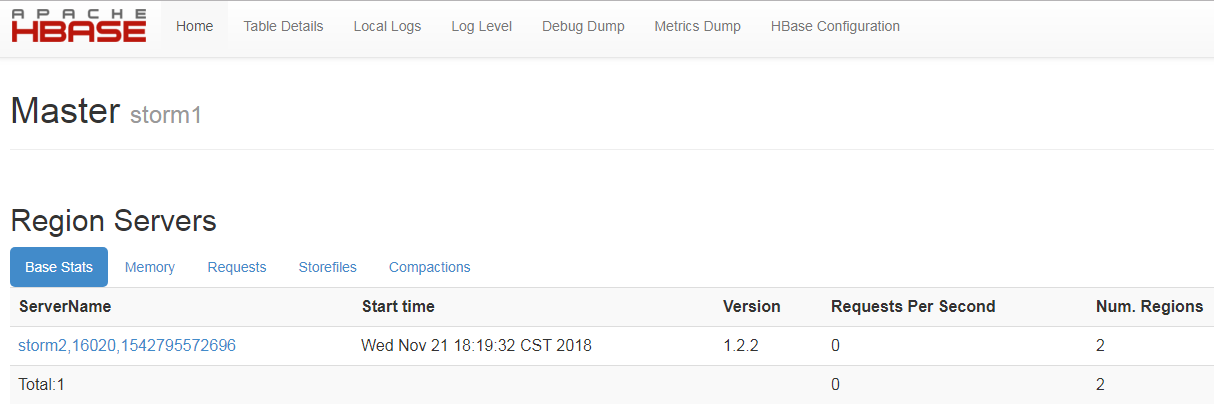
(6)通过16010端口访问HBase的控制台,可以看到刚刚开启的regionserver,到此HBase搭建成功!
流式大数据计算实践(4)----HBase安装的更多相关文章
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- 流式大数据计算实践(5)----HBase使用&SpringBoot集成
一.前言 1.上文中我们搭建好了一套HBase集群环境,这一文我们学习一下HBase的基本操作和客户端API的使用 二.shell操作 先通过命令进入HBase的命令行操作 /work/soft/hb ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- 流式大数据计算实践(3)----高可用的Hadoop集群
一.前言 1.上文中我们已经搭建好了Hadoop和Zookeeper的集群,这一文来将Hadoop集群变得高可用 2.由于Hadoop集群是主从节点的模式,如果集群中的namenode主节点挂掉,那么 ...
- 流式大数据计算实践(2)----Hadoop集群和Zookeeper
一.前言 1.上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群 二.搭建Hadoop集群 1.根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 低调、奢华、有内涵的敏捷式大数据方案:Flume+Cassandra+Presto+SpagoBI
基于FacebookPresto+Cassandra的敏捷式大数据 文件夹 1 1.1 1.1.1 1.1.2 1.2 1.2.1 1.2.2 2 2.1 2.2 2.3 2.4 2.5 2.6 3 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
随机推荐
- MongoDB 用Robomong可视化工具操作的 一些简单语句
一.数据更新 db.getCollection('表名').update({ "字段":{$in:["值"]} }, //更新条件 {$set:{ " ...
- worknote
一.变更注意事项 1.部署平台: a.重启服务时,通过部署平台跳到各服务器操作时,注意修改字符编码为en_US.utf-8 b.服务器之间通过部署平台的dscp命令传输文件到目标服务器:如果连接目标服 ...
- Mac自动化环境
1. JDK安装 下载JDK for Mac 我这里使用的是 jdk-7u79-macosx-x64.dmg 验证安装open Terminal java -version java versio ...
- BUAA_OO Summary——多项式求导问题
从C.DS.计组一路折磨过来, 几乎都在采用过程化.函数式的编程思想.初接触面向对象的项目开发,经过了三周的对多项式求导问题的迭代开发,经历了设计.coding.测评环节,算是对面向对象有了一定的认识 ...
- javaweb聊天室源码免费
效果:可擴展源碼,免費技術指導,電話13956301647 链接:https://pan.baidu.com/s/1FWV8DNWacGaEpAQEsWsNaw 提取码:b6gf
- hadoop基础操作
通过hadoop上的hive完成WordCount 启动hadoop Hdfs上创建文件夹 上传文件至hdfs 启动Hive 创建原始文档表 导入文件内容到表docs并查看 用HQL进行词频统计,结果 ...
- Hadoop 操作常见问题解决
1. 安全模式下不可操作 提示信息: Hadoop "Cannot create directory .Name node is in safe mode." 解决方法: $ ha ...
- 1.4 The usage of plug-in
Once upon a time, we once thought naively that Android plug-in was intended to add new features or a ...
- Dubbo 分布式事务一致性实现
我觉得事务的管理不应该属于Dubbo框架, Dubbo只需实现可被事务管理即可, 像JDBC和JMS都是可被事务管理的分布式资源, Dubbo只要实现相同的可被事务管理的行为,比如可以回滚, 其它事务 ...
- 如何理解Python装饰器
如何理解Python装饰器?很多学员对此都有疑问,那么上海尚学堂python培训这篇文章就给予答复. 一.预备知识 首先要理解装饰器,首先要先理解在 Python 中很重要的一个概念就是:“函数是 F ...