scrapy_redis 相关: 多线程更新 score/request.priority
0.背景
使用 scrapy_redis 爬虫, 忘记或错误设置 request.priority(Rule 也可以通过参数 process_request 设置 request.priority),导致提取 item 的 request 排在有序集 xxx:requests 的队尾,持续占用内存。
1.代码实现
遍历 SortedSet 的所有 item 并根据预定义字典对 data 中的 url 进行正则匹配,更新 score 并复制到临时 newkey,最后执行 rename
# -*- coding: UTF-8 -*
import sys
import re
from multiprocessing.dummy import Pool as ThreadPool
from functools import partial try:
input = raw_input #For py2
except NameError:
pass import redis def print_line(string):
print('\n{symbol}{space}{string}'.format(symbol='#'*10, space=' '*5, string=string)) def check_key_scores(key):
try:
total = redis_server.zcard(key)
except redis.exceptions.ResponseError:
print("The value of '{key}' is not a SortedSet".format(key=key))
sys.exit()
except Exception as err:
print(err)
sys.exit() if total == 0:
print("key '{key}' does not exist or has no items".format(key=key))
sys.exit() __, min_score = redis_server.zrange(key, 0, 0, withscores=True)[0]
__, max_score = redis_server.zrange(key, -1, -1, withscores=True)[0] print('score amount')
total_ = 0
# Asuming that score/request.priority is an integer, rather than float number like 1.1
for score in range(int(min_score), int(max_score)+1):
count = redis_server.zcount(key, score, score)
print(score, count)
total_ += count
print("{total_}/{total} items of key '{key}' have an integer priority".format(
total_=total_, total=total_, key=key)) def zadd_with_new_score(startstop, total_items):
data, ori_score = redis_server.zrange(key, startstop, startstop, withscores=True)[0]
for pattern, score in pattern_score:
# data eg: b'\\x80\\x02}q\\x00(X\\x03\\x00\\x00\\x00urlq\\x01X\\x13\\x00\\x00\\x00http://httpbin.org/q\\x02X\\x08\\x00\\x00\\x00callbackq\\x03X\\x
# See /site-packages/scrapy_redis/queue.py
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
m = pattern.search(data.decode('utf-8', 'replace'))
if m:
redis_server.execute_command('ZADD', newkey, score, data)
break
else:
redis_server.execute_command('ZADD', newkey, ori_score, data)
print('{startstop} / {total_items}'.format(
startstop=startstop+1, total_items=total_items)) if __name__ == '__main__': password = 'password'
host = '127.0.0.1'
port = ''
database_num = 0 key = 'test:requests'
newkey = 'temp'
# Request whose url matching any key of keyword_score would be updated with the corresponding value as its score
# Smaller value/score means higher request.priority
keyword_score = {'httpbin': -12, 'apps/details': 1}
pattern_score = [(re.compile(r'url.*?%s.*?callback'%k), v)for (k, v) in keyword_score.items()] threads_amount = 10 redis_server = redis.StrictRedis.from_url('redis://:{password}@{host}:{port}/{database_num}'.format(
password=password, host=host,
port=port, database_num=database_num)) print_line('Step 0: pre check')
check_key_scores(key) print_line('Step 1: copy items and update score')
# total_items = redis_server.zlexcount(key, '-', '+')
total_items = redis_server.zcard(key)
input("Press Enter to copy {total_items} items of '{key}' into '{newkey}' with new score".format(
total_items=total_items, key=key, newkey=newkey))
p = ThreadPool(threads_amount)
p.map(partial(zadd_with_new_score, total_items=total_items), range(total_items))
p.close() #Prevents any more tasks from being submitted to the pool. Once all the tasks have been completed the worker processes will exit.
p.join() #Wait for the worker processes to exit. One must call close() or terminate() before using join(). # For py3
# https://stackoverflow.com/questions/5442910/python-multiprocessing-pool-map-for-multiple-arguments
# with ThreadPool(threads_amount) as pool:
# pool.map(partial(zadd_with_new_score, total_items=total_items), range(total_items))
# print('zadd_with_new_score done') print_line('Step 2: check copy result')
check_key_scores(key)
check_key_scores(newkey) print_line('Step 3: delete, rename and check key')
input("Press Enter to DELETE '{key}' and RENAME '{newkey}' to '{key}'".format(
key=key, newkey=newkey))
print(redis_server.delete(key))
print(redis_server.rename(newkey, key))
check_key_scores(key)
check_key_scores(newkey)
2.运行结果
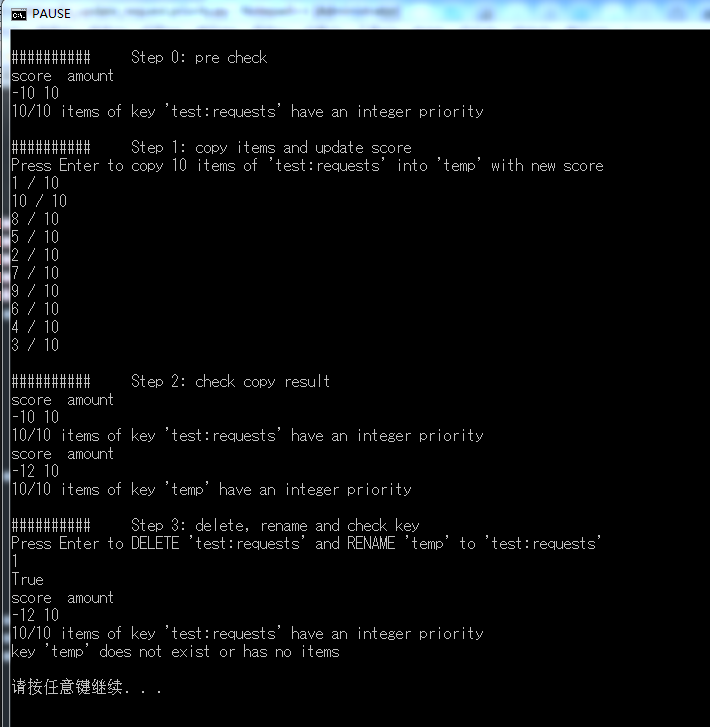
scrapy_redis 相关: 多线程更新 score/request.priority的更多相关文章
- 拒绝卡顿——在WPF中使用多线程更新UI
原文:拒绝卡顿--在WPF中使用多线程更新UI 有经验的程序员们都知道:不能在UI线程上进行耗时操作,那样会造成界面卡顿,如下就是一个简单的示例: public partial class MainW ...
- Oracle E-Business Suite并发请求的优先级(Concurrent Request Priority)
不少用户抱怨自己的Oracle E-Business Suite并发请求(Concurrent Request)提交了好久,但还是一直在排队,等了好久还没有执行.用户希望对于一些重要性程度高.响应要求 ...
- WPF多线程更新UI的一个解决途径
那么该如何解决这一问题呢?通常的做法是把耗时的函数放在线程池执行,然后切回主线程更新UI显示.前面的updateTime函数改写如下: private async void updateTime() ...
- DataGridView 多线程更新 数据 解决卡顿问题
使用多线程更新DataGridView,防止页面卡顿和卡死的问题 private delegate void UpdateDataGridView(DataTable dt); private voi ...
- 多线程更新已排序的Datagridview数据,造成数据错位
多线程更新已排序的Datagridview数据,触发Datagridview的auto-sort时间,数据重新排序,造成后面更新数据的更新错误. 解决方法: 方法一.设置Datagridview的表头 ...
- Android多线程更新UI的方式
Android下,对于耗时的操作要放到子线程中,要不然会残生ANR,本次我们就来学习一下Android多线程更新UI的方式. 首先我们来认识一下anr: anr:application not rep ...
- C# 通过委托控制进度条以及多线程更新控件
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- scrapy_redis 相关: 将 jobdir 保存的爬虫进度转移到 Redis
0.参考 Scrapy 隐含 bug: 强制关闭爬虫后从 requests.queue 读取的已保存 request 数量可能有误 1.说明 Scrapy 设置 jobdir,停止爬虫后,保存文件目录 ...
- 富客户端 wpf, Winform 多线程更新UI控件
前言 在富客户端的app中,如果在主线程中运行一些长时间的任务,那么应用程序的UI就不能正常相应.因为主线程要负责消息循环,相应鼠标等事件还有展现UI. 因此我们可以开启一个线程来格外处理需要长时间的 ...
随机推荐
- mybatis 插入 含有美元符号($) 字符串 报 java.lang.IndexOutOfBoundsException: No group 2 的问题
一:问题描述: 在springboot-security框架生成BCryptPasswordEncoder()方法生成加密后的密码后,带有$符号,导致新增用户的时候插入不了,报(IndexOutOfB ...
- python第七天
复习: 1.深浅拷贝 值拷贝:直接赋值 = 号, 列表中的任何值发生改变,第二个中的值都会随之改变浅拷贝:通过copy()方法 ls2 = ls.copy(),第一个中存放的值的地址没有改变, 但内部 ...
- 解决php -v查看到版本与phpinfo()版本不一致问题
安装p7后发现phpinfo的版本是7.2.12,而php -v查看的却是5.4.16 应该是php.ini的配置文件有问题. 查看文件,有两个 查看cli执行的文件是哪一个? 再查看phpinfo用 ...
- python类方法以及类调用实例方法的理解
classmethod类方法 1) 在python中.类方法 @classmethod 是一个函数修饰符,它表示接下来的是一个类方法,而对于平常我们见到的则叫做实例方法. 类方法的第一个参数cls,而 ...
- localStorage sessionStorage cookie indexedDB
目录: localStorage sessionStorage cookie indexedDB localStorage localStorage存储的数据能在跨浏览器会话保留 数据可以长期保留,关 ...
- 使用Docker安装Nginx
启动命令 docker run -d -p : --name nginx -v $PWD/nginx.conf:/etc/nginx/nginx.conf -v $PWD/conf.d/:/etc/n ...
- numpy&pandas补充常用示例
Numpy [数组切片] In [115]: a = np.arange(12).reshape((3,4)) In [116]: a Out[116]: array([[ 0, 1, 2, 3], ...
- [转载]如何在ubuntu上使用github
来源:https://blog.csdn.net/tina_ttl/article/details/51326684 https://blog.csdn.net/u013551462/article/ ...
- Java方法参数的传递方式
程序设计语言中,将参数传递给方法(或函数)有两种方法.按值传递(call by value)表示方法接受的是调用者提供的值:按引用调用(call by reference)表示方法接受的是调用者提供的 ...
- pycharm+selenium搭建环境
1.在你的python安装目录D:\Python36\Scripts下执行pip install selenium 2.安装完成后最好直接打开python,在下面输入from selenium imp ...