『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析
在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等)才能展现自己的实力。此时,模型和计算平台的"默契程度"会决定模型的实际表现。Roofline Model 提出了使用 Operational Intensity(计算强度)进行定量分析的方法,并给出了模型在计算平台上所能达到理论计算性能上限公式。
一、指标介绍
1、计算平台的两个指标:算力π,带宽ß
算力π:也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是FLOP/s。
带宽ß:也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。
计算强度上限 I max:两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是FLOP/Byte。
I max = π / ß
注:这里所说的“内存”是广义上的内存。对于CPU计算平台而言指的就是真正的内存;而对于GPU计算平台指的则是显存。
2、 模型的两个指标:计算量,访存量
计算量:指的是输入单个样本(对于CNN而言就是一张图像),模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度,单位是FLOPS。
访存量:指的是输入单个样本,模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度。在理想情况下(即不考虑片上缓存),模型的访存量就是模型各层权重参数的内存占用(Kernel Mem)与每层所输出的特征图的内存占用(Output Mem)之和。单位是Byte。由于数据类型通常为float32 ,因此需要乘以四。
模型的计算强度 I:由计算量除以访存量就可以得到模型的计算强度,它表示此模型在计算过程中,每Byte内存交换到底用于进行多少次浮点运算。单位是FLOP/Byte。可以看到,模计算强度越大,其内存使用效率越高。
二、Roof-line Model 形态
其实 Roof-line Model 说的是很简单的一件事:模型在一个计算平台的限制下,到底能达到多快的浮点计算速度。
更具体的来说,Roof-line Model 解决的,是“计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少”这个问题。
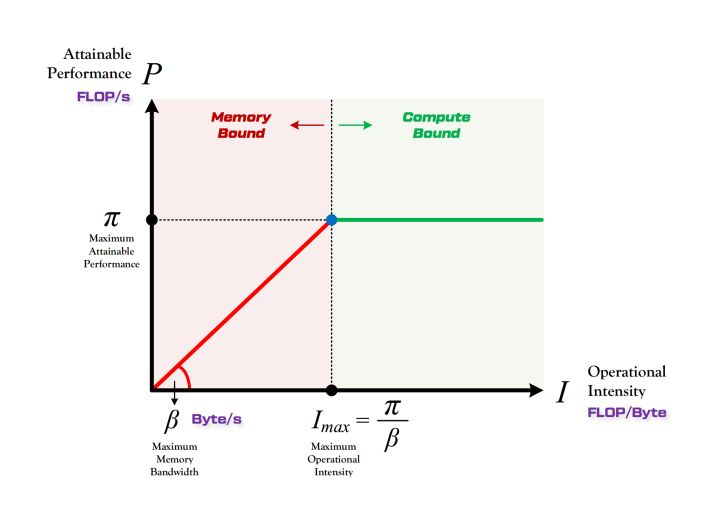
所谓“Roof-line”,指的就是由计算平台的算力和带宽上限这两个参数所决定的“屋顶”形态,如上图图所示。
- 算力决定“屋顶”的高度(绿色线段)
- 带宽决定“房檐”的斜率(红色线段)
a、带宽瓶颈区域 Memory-Bound
当模型的计算强度 I 小于计算平台的计算强度上限 I max 时,由于此时模型位于“房檐”区间,因此模型理论性能 P 的大小完全由计算平台的带宽上限 ß (房檐的斜率)以及模型自身的计算强度 I 所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽 ß 越大(房檐越陡),或者模型的计算强度 I 越大,模型的理论性能 P 可呈线性增长。
一方面,我们可以认为计算平台的带宽限制导致计算平台的算力不能完全发挥;另一方面我们也可以认为,模型的计算强度太低,导致对单位内存访问时的计算量太小。
b、计算瓶颈区域 Compute-Bound
不管模型的计算强度 I 有多大,它的理论性能 P 最大只能等于计算平台的算力 π 。当模型的计算强度 I 大于计算平台的计算强度上限 I max 时,模型在当前计算平台处于 Compute-Bound 状态,即模型的理论性能 P 受到计算平台算力 π 的限制,无法与计算强度 I 成正比。
但这其实并不是一件坏事,因为从充分利用计算平台算力的角度上看,此时模型已经 100% 的利用了计算平台的全部算力。可见,计算平台的算力 π 越高,模型进入计算瓶颈区域后的理论性能 P 也就越大。
三、使用 Roof-line 分析模型
1、理论分析
a、VGG16
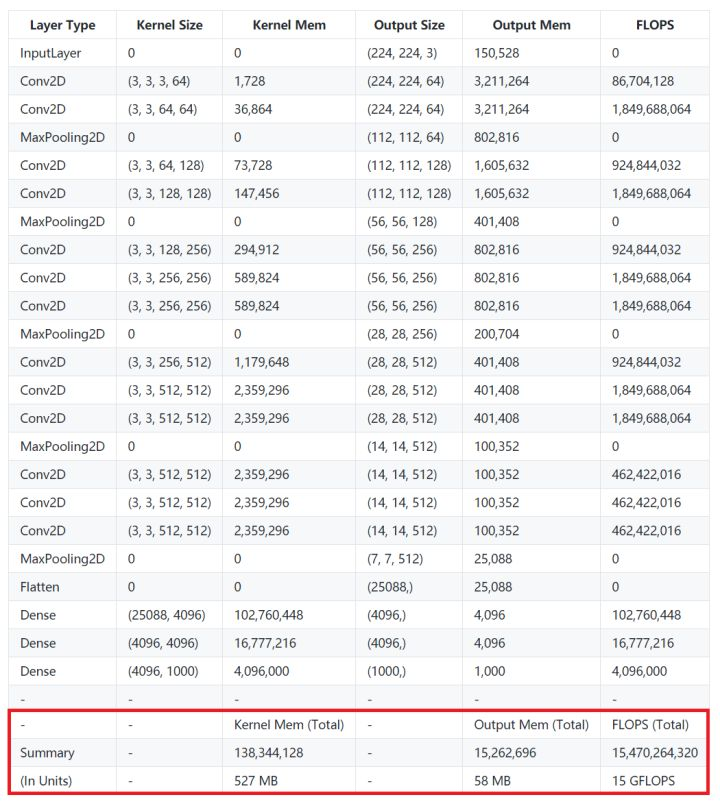
VGG 可以说是在计算强度上登峰造极的一个模型系列,简约不简单。以 VGG16 为例,从上表可以看到,仅包含一次前向传播的计算量就达到了 15GFLOPs,如果包含反向传播,则需要再乘二。访存量则是 Kernel Mem 和 Output Mem 之和再乘以四,大约是 600MB。因此 VGG16 的计算强度就是 25 FLOP/Byte。
另外如果把模型顶端那两个硕大无比的全链接层(其参数量占整个模型的80%以上)替换为GAP以降低访存量(事实证明这样修改并不会影响准确率),那么它的实际计算强度可以再提升四倍以上,简直突破天际。
注:以上分析仅限于前向传播计算过程(即模型预测)。如果涵盖反向传播(即模型训练),则计算量和访存量都要考虑梯度更新的具体方式,例如计算 Momentum 几个变量时引入的时间和空间复杂度。
b、MobileNet
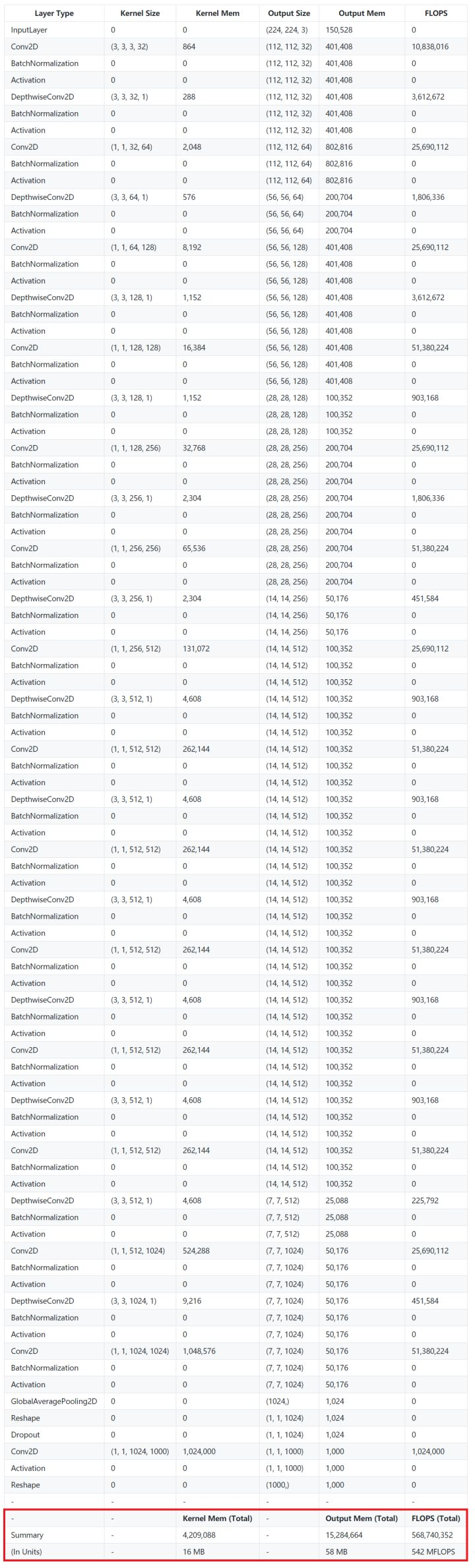
MobileNet 是以轻量著称的小网络代表。相比简单而庞大的 VGG16 结构,MobileNet 的网络更为细长,加入了大量的BN,每一层都通过 DW + PW 的方式降低了计算量,同时也付出了计算效率低的代价。从上面超级长的表格就能有一个感性的的认识。
MobileNet 的计算量只有大约 0.5 GFLOPS(VGG16 则是 15 GFLOPS),其访存量也只有 74 MB(VGG16 则是约 600 MB)。这样看上去确实轻量了很多,但是由于计算量和访存量都下降了,而且相比之下计算量下降的更厉害,因此 MobileNet 的计算强度只有 7 FLOP/Byte。
2、两个模型在 1080Ti 上的对比
1080Ti 的算力 π = 11.3 TFLOPS/s
1080Ti 的带宽 ß = 484 GB/s
因此 1080Ti 计算平台的最大计算强度 I max ≈ 24
VGG16 的计算强度 I v≈ 25
MobileNet 的计算强度 I M≈ 7
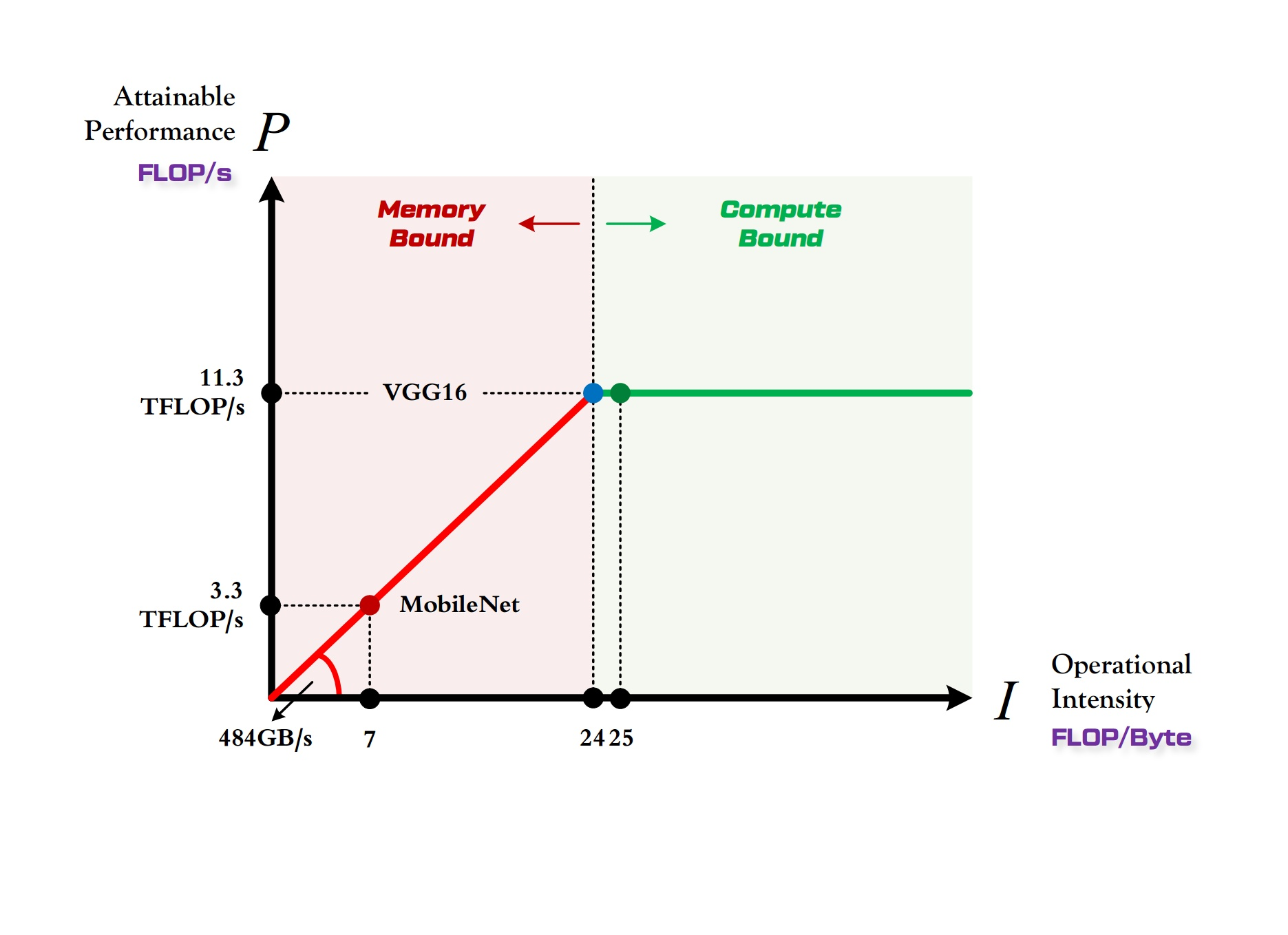
由上图可以非常清晰的看到,
- MobileNet 处于 Memory-Bound 区域。在 1080Ti 上的理论性能只有 3.3 TFLOP/s。
- VGG16 刚好迈入 Compute-Bound 区域。完全利用 1080Ti 的全部算力。
虽然 MobileNet 进行前向传播的计算量只有 VGG 的三十分之一,但是由于计算平台的带宽限制,它不能像 VGG 那样完全利用 1080Ti 这个计算平台的全部算力,因此它在 1080Ti 上每秒钟可以进行的浮点运算数只能达到 VGG 的 30%,因此理论上的运行速度大约是 VGG 的十倍(实际上会因为各方面其他因素的限制而使得差别更小)。
MobileNet 这类小型网络更适合运行在嵌入式平台之上。首先这类轻量级的计算平台根本就放不下也运行不起来 VGG 这种大模型。更重要的是,由于这类计算平台本身的计算强度上限就很低,可能比 MobileNet 的计算强度还要小,因此 MobileNet 运行在这类计算平台上的时候,它就不再位于 Memory-Bound 区域,而是农奴翻身把歌唱的进入了 Compute-Bound 区域,此时 MobileNet 和 VGG16 一样可以充分利用计算平台的算力,而且内存消耗和计算量都小了一两个数量级,同时分类准确率只下降了1%,所以大家才愿意用它。
Roofline 模型讲的是程序在计算平台的算力和带宽这两个指标限制下,所能达到的理论性能上界,而不是实际达到的性能,因为实际计算过程中还有除算力和带宽之外的其他重要因素,它们也会影响模型的实际性能,这是 Roofline Model 未考虑到的。例如矩阵乘法,会因为 cache 大小的限制、GEMM 实现的优劣等其他限制,导致你几乎无法达到 Roofline 模型所定义的边界(屋顶)。
『高性能模型』Roofline Model与深度学习模型的性能分析的更多相关文章
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- CUDA上的量化深度学习模型的自动化优化
CUDA上的量化深度学习模型的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参 ...
- 深度学习模型融合stacking
当你的深度学习模型变得很多时,选一个确定的模型也是一个头痛的问题.或者你可以把他们都用起来,就进行模型融合.我主要使用stacking和blend方法.先把代码贴出来,大家可以看一下. import ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- Opencv调用深度学习模型
https://blog.csdn.net/lovelyaiq/article/details/79929393 https://blog.csdn.net/qq_29462849/article/d ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
随机推荐
- [macOS] Mojave10.14 夜神安卓模拟器启动问题
废话不多说,其它的都有在这里讨论: https://bbs.yeshen.com/forum.php?mod=viewthread&tid=8566 我的最终解决办法是,virtualbox安 ...
- 【论文速读】Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes
Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes 作 ...
- Hadoop 故障整理
1.关于DataNode 错误信息解析 错误内容 java.io.IOException: Incompatible clusterIDs -b89c-43f90751214b; datanode c ...
- 信步漫谈之Jenkins—集成环境搭建
一.环境准备 1)Jenkins 部署 WAR 包:jenkins.war(2.164.2 版本,WAR 包官方下载路径:https://jenkins.io/download/)2)Tomcat 服 ...
- python学习之爬虫初体验
作业来源: "https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851" ** 1.简述爬虫原理 通用爬虫 即(搜索 ...
- Java EE开发技术课程第七周(json)
JSON: https://baike.baidu.com/item/JSON/2462549?fr=aladdin JSON指JavaScript对象表示法(JavaScript Object No ...
- 用JDBC连接 数据库 进行简单的增删改查
JDBC为java的基础.用jdbc实现对数据库的增删改查的功能是程序员的基本要求.本例以mysql为例,首先要使用本例需要添加mysql-connector-java-5.1.7-bin.jar包. ...
- js encode方法
js对文字进行编码涉及3个函数:escape,encodeURI,encodeURIComponent,相应3个解码函数:unescape,decodeURI,decodeURIComponent 1 ...
- 在linux和windows用c++编写c接口的动态库
linux 动态的头文件api.h #ifndef _API_H #define _API_H #ifdef DLL_IMPLEMENT #define DLL_EXPORT extern " ...
- JS版剑指offer
介绍 用JavaScript刷完了剑指offer,故总结下每道题的难度.解决关键点,详细题解代码可以点链接进去细看. 关于JS刷题的技巧可以看我之前的这篇:JS刷题总结. 剑指offer的题目在牛客网 ...