基于N-Gram判断句子是否通顺
完整代码实现及训练与测试数据:click me
一、任务描述
自然语言通顺与否的判定,即给定一个句子,要求判定所给的句子是否通顺。
二、问题探索与分析
拿到这个问题便开始思索用什么方法来解决比较合适。在看了一些错误的句子之后,给我的第一直觉就是某些类型的词不应该拼接在一起,比如动词接动词(e.g.我打开听见)这种情况基本不会出现在我们的用语中。于是就有了第一个idea基于规则来解决这个问题。但是发现很难建立完善的语言规则也缺乏相关的语言学知识,实现这么完整的一套规则也不简单,因此就放弃了基于规则来实现,但还是想抓住某些类型的词互斥的特性,就想到了N-Gram,但是这里的N-Gram不是基于词来做,而是基于词的词性来做。基于词来做参数量巨大,需要非常完善且高质量的语料库,而词的词性种类数目很小,基于词性来做就不会有基于词的困扰,而且基于词性来做直觉上更能贴合想到的这个idea。除了这个naive的idea之外,后面还有尝试用深度学习来学习句子通顺与否的特征,但是难点在于特征工程怎么做才能学习到句子不通顺的特征。下面我会详细说明我的具体实现。
三、代码设计与实现
3.1 基于词性的N-Gram
环境:
python 3.6.7
pyltp 0.2.1(匹配的ltp mode 3.4.0)
numpy 1.15.4
pyltp用于分词和词性标注,首先加载分词和词性标注模型
from pyltp import Segmentor
from pyltp import Postagger seg = Segmentor()
seg.load(os.path.join('../input/ltp_data_v3.4.0', 'cws.model'))
pos = Postagger()
pos.load(os.path.join('../input/ltp_data_v3.4.0', 'pos.model'))
加载训练数据,并对数据进行分词和词性标注,在句首句尾分别加上<s>和</s>作为句子开始和结束的标记
train_sent = []
trainid = []
train_sent_map = {} #[id:[ngram value, label]]
with open('../input/train.txt', 'r') as trainf:
for line in trainf:
if len(line.strip()) != 0:
items = line.strip().split('\t')
tags = ['<s>']
for tag in pos.postag(seg.segment(items[1])):
tags.append(tag)
tags.append('</s>')
train_sent.append(tags)
trainid.append(int(items[0]))
train_sent_map[trainid[-1]] = [0.0, int(items[2])]
测试数据的加载方式与训练数据一致不再赘述,接下来就是对训练数据中标签为0的数据进行1gram和2grams的词性频率计数
train_1gram_freq = {}
train_2grams_freq = {}
for sent in test_sent:
train_1gram_freq[sent[0]] = 1
for j in range(1, len(sent)):
train_1gram_freq[sent[j]] = 1
train_2grams_freq[' '.join(sent[j-1:j+1])] = 1e-100 for i in range(len(trainid)):
if train_sent_map[trainid[i]][1] == 0:
sent = train_sent[i]
train_1gram_freq[sent[0]] = 0
for j in range(1, len(sent)):
train_1gram_freq[sent[j]] = 0
train_2grams_freq[' '.join(sent[j-1:j+1])] = 0 # 预处理训练集0标记的正确句子
for i in range(len(trainid)):
if train_sent_map[trainid[i]][1] == 0:
sent = train_sent[i]
train_1gram_freq[sent[0]] += 1
for j in range(1, len(sent)):
train_1gram_freq[sent[j]] += 1
train_2grams_freq[' '.join(sent[j-1:j+1])] += 1
由于测试数据中可能包含训练数据中未包含的词性组合,用python的dict存储词性到频度的映射,在对测试集中句子的N-Gram概率进行计算时会报KeyError的错误。为了解决这个问题,就有了上面看起来似乎有点冗余的代码。先将测试集中1gram和2grams的词性写到dict中,这样就至少保证了不会出现KeyError的错误。然后将训练集中1gram和2grams的词性写到dict中,覆盖了测试集写入的相同的key,再进行频度计数。对于只在测试集中出现的key还保留着原来的值,这里对测试集中的2grams组合赋值为1e-100是为了在计算2-Grams模型概率值时突显出未在训练集中出现的特征,从而能够从测试集中辨识出这些异常的句子。
由于句子长短不一,计算出来的句子的概率差距甚远,所以需要对相同长度的句子进行一个聚类,然后用计算出来的概率值除以句子字长,这样才能保证句子的概率基本保持在一个较小的范围内,设置的阈值才能较好地将不同类型句子区分开来。
# 计算句子基于2-grams的概率值
def compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq):
p = 0.0
for j in range(1, len(sent)):
p += math.log(train_2grams_freq[' '.join(sent[j-1:j+1])] * 1.0 \
/ train_1gram_freq[sent[j-1]])
return p / len(sent) # 计算训练集中句子的概率值
for i, sent in enumerate(train_sent):
if train_sent_map[trainid[i]][1] == 0:
train_sent_map[trainid[i]][0] = compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq) # 对不同长度的句子进行聚类,然后计算等长句子类的平均概率值
train_samesize_avgprob = {}
for i, sent in enumerate(train_sent):
train_samesize_avgprob[len(sent)] = [0.0, 0]
for i, sent in enumerate(train_sent):
train_samesize_avgprob[len(sent)][0] += train_sent_map[trainid[i]][0]
train_samesize_avgprob[len(sent)][1] += 1
for key in train_samesize_avgprob.keys():
train_samesize_avgprob[key][0] = train_samesize_avgprob[key][0] / train_samesize_avgprob[key][1]
统计训练集中2-Grams概率的最小值,最大值,以及平均值,其中平均值将被用作判断句子好坏的阈值
thresh = {'min0':0.0, 'max0':-np.inf, 'avg0':0.0}
c0 = 0
for id in trainid:
if train_sent_map[id][1] == 0:
if train_sent_map[id][0] < thresh['min0']:
thresh['min0'] = train_sent_map[id][0]
if train_sent_map[id][0] > thresh['max0']:
thresh['max0'] = train_sent_map[id][0]
thresh['avg0'] += train_sent_map[id][0]
c0 += 1
thresh['avg0'] /= c0
接着计算测试集中每个句子基于2-Grams的除以字长的概率值,然后与由训练集计算得到的与其等字长类的平均概率值进行对比。如果训练集中没有找到与测试集中某个句子的等长的句子,则测试集中该句子概率值直接去总体训练样本计算得到的概率值进行对比。
thresh_tx = {'min':0.0, 'max':-np.inf, 'avg':0.0}
TX = []
with open('../output/ngramfluent_postag_pyltp.txt', 'w') as resf:
for sent in test_sent:
TX.append([compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq)])
for i in range(len(TX)):
if thresh_tx['min'] > TX[i][0]:
thresh_tx['min'] = TX[i][0]
if thresh_tx['max'] < TX[i][0]:
thresh_tx['max'] = TX[i][0]
thresh_tx['avg'] += TX[i][0]
thresh_tx['avg'] /= len(TX)
print('测试集:', thresh_tx)
for i in range(len(testid)):
if len(test_sent[i]) in train_samesize_avgprob.keys():
if TX[i][0] >= train_samesize_avgprob[len(test_sent[i])][0]:
resf.write(testid[i] + '\t0\n')
else:
resf.write(testid[i] + '\t1\n')
else:
if TX[i][0] >= thresh['avg'] - 0.1:
resf.write(testid[i] + '\t0\n')
else:
resf.write(testid[i] + '\t1\n')
thresh['avg']-0.1之后再比较是因为训练集基于2-Grams计算的概率平均值与测试集基于2-Grams计算的概率平均值相比有一点小小上下波动,减0.1相当于一个微调的优化操作。
以上便是基于词性的2-Grams方法的具体实现,最后提交的结果65%的样子,同时我也使用了直接基于词的2-Grams方法,但是提交的结果没有基于词性的方法好,应该是语料库内容不足以支撑,然后我又尝试将wiki中文数据集内容提取出来并划分成句子作为正类输入,但是结果还是没有基于词性的好,可能是wiki数据集太大,而我处理得很粗糙,数据清洗工作不到位导致的。
3.2 深度学习学习句法特征
环境:
python 3.6.7
bert-serving-server
bert-serving-client
sklearn
numpy
深度学习我没有系统地学过,Google最近提出的bert很火,于是就想尝试使用bert来基于句子做特征工程,学习病句特征,然后再用SVM做一个分类。都是调用的接口,代码很少,但是最后效果却很差。可能是bert参数没调好,但是目前对bert了解甚少不知该怎么调,而时间有限所以也就没进一步深入了。后续有时间学习一下bert再回过头来优化模型。
四、性能分析
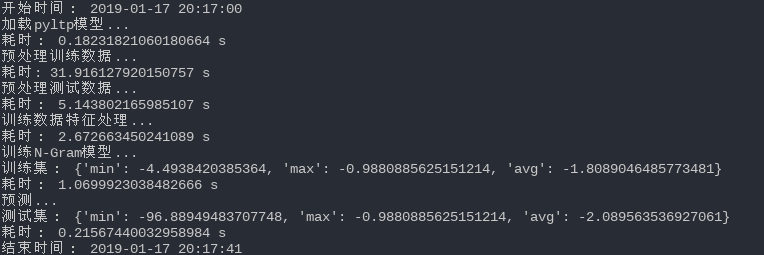
使用基于统计的方法做计算复杂度很低,除去分词模块,2-Grams模型的计算复杂度为O(样本数*句子平均字长),所以代码运行起来很快,下面是代码运行截图:
五、遇到的问题及解决方案
对于未包含在训练集中的测试集2-Grams,在计算概率值时怎么做平滑处理?
具体解决方案在第三节中有详细描述。
不同句长的句子基于2-Grams计算出来的log概率值相差甚远,这给设置分类阈值带来了麻烦,该如何解决?
计算得到的概率值除以句子字长,具体实现时还加入了等句长的聚类,详细解决方案在第三节中有描述。
概率比对阈值设置多大才能最准确地进行分类?
这个问题我目前也没有很好的解决方法,只能多试几个看看实际的结果。
六、未来改进
估计使用2-Grams方法的瓶颈不到70%,当下深度学习在NLP中应用很火热,未来可以深入学习以下深度学习在NLP中的应用然后再回过头来用深度学习的视角来重新看待这个问题。
基于N-Gram判断句子是否通顺的更多相关文章
- .NET C#生成随机颜色,可以控制亮度,生成暗色或者亮色 基于YUV模式判断颜色明亮度
.NET C#生成随机颜色,可以控制亮度,生成暗色或者亮色 基于YUV模式判断颜色明亮度 随机颜色在日常开发中很常用到,有时候要控制颜色明亮度,比如在白色背景网页上的随机颜色,一般要求颜色稍微暗一 ...
- 基于jQuery的判断iPad、iPhone、Android是横屏还是竖屏的代码
在ipad.iphone网页开发中,我们很可能需要判断是横屏或者竖屏.下面就来介绍如何用 jQuery 判断iPad.iPhone.Android是横屏还是竖屏的方法 其实主要是通过window.or ...
- 基于jQuery的判断iPad、iPhone、Android是横屏还是竖屏
function orient() {if (window.orientation == 90 || window.orientation == -90) {//ipad.iphone竖屏:Andri ...
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- C#实现判断字符是否为中文
C#实现判断字符是否为中文 (2012-08-14 14:25:28) 标签: gb2312 big5编码 gbk编码 判断 汉字 杂谈 分类: 技术 protected bool IsChinese ...
- iOS中利用CoreTelephony获取用户当前网络状态(判断2G,3G,4G)
前言: 在项目开发当中,往往需要利用网络.而用户的网络环境也需要我们开发者去注意,根据不同的网络状态作相应的优化,以提升用户体验. 但通常我们只会判断用户是在WIFI还是移动数据,而实际上,移动数据也 ...
- C# 判断中文字符(字符串)
在unicode 字符串中,中文的范围是在4E00..9FFF:CJK Unified Ideographs.通过对字符的unicode编码进行判断来确定字符是否为中文.protected bool ...
- C# 判断字符编码的六种方法
方法一http://blog.csdn.net/qiujiahao/archive/2007/08/09/1733169.aspx在unicode 字符串中,中文的范围是在4E00..9FFF:CJK ...
- Linux中的判断式
格式一:test [参数] 判断内容格式二:[ [参数] 判断内容 ] 说明: a.格式二可以认为是格式一的缩写 b.格式二里中括号和内容之间要有空格 基于文件的判断-d 判断文件是否存在,并且是目录 ...
随机推荐
- Golang实现requests库
Golang实现requests库 简单的封装下,方便使用,像python的requests库一样. Github地址 Github 支持 GET.POST.PUT.DELETE applicatio ...
- libevent入门介绍
libevent是之前看到的一个别人推荐的清凉级网络库,我就想了解一下它.今天下载到了一个人写的剖析系列,从结构和源码方面进行了简要分析.只是这个分析文章是2010年的,有点过时了(跟现在的libev ...
- linux学习:用户管理
一.管理用户(user) 主要工具命令 useradd 注:添加用户 adduser 注:添加用户 passwd 注:为用户设置密码 usermod 注:修改用户命令,可以通 ...
- C# 使用WinApi操作剪切板Clipboard
前言: 最近正好写一个程序,需要操作剪切板 功能很简单,只需要从剪切板内读取字符串,然后清空剪切板,然后再把字符串导入剪切板 我想当然的使用我最拿手的C#来完成这项工作,原因无他,因为.Net框架封装 ...
- 错误:Java HotSpot(TM) 64-Bit Server VM warning: Insufficient space for shared memory file
Java HotSpot(TM) 64-Bit Server VM warning: Insufficient space for shared memory file: /tmp/hsperfdat ...
- win 10 亮度调节不能使用了
我的解决办法的前提:装过teamviewer ,然后每次系统推送大升级似乎都会无法调节亮度,如果不是这个前提自己找别的办法吧 teamviewer 就是一个流氓软件. 每次更新之后都末名奇妙的不能调节 ...
- 长沙学院APP之校园模块设计
一.简单回顾 在上次的scrum冲刺中,我将整个长沙学院的APP做了一个基本的架构设计以及框架设计,确定好了APP的功能结构以及实现时所要达到的效果,并且做了一个简单的用户登录界面,由于所学知识有限, ...
- [Swift]LeetCode375. 猜数字大小 II | Guess Number Higher or Lower II
We are playing the Guess Game. The game is as follows: I pick a number from 1 to n. You have to gues ...
- javascript 使用小技巧总结
按位取反 ~a 即:返回 -(a+1),会去掉小数点. let a = 3.14; let b = ~a; //b = -(3.14+1) 取整 为-4: let c = ~b; //c = -(-4 ...
- python安装whl文件
在命令指示符下(cmd)的Python3安装命令为: pip3 install 文件名.whl 安装出错: matplotlib-2.0.0-cp34-cp34m-win_amd64.whl is n ...