【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一、前述
Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼。由于源码部分太多本节只抽取关键部分和结论阐述,更多的偏于应用。
二、具体细节
1、Spark-Submit提交参数
Options:
- --master
MASTER_URL, 可以是spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
- --deploy-mode
DEPLOY_MODE, Driver程序运行的地方,client或者cluster,默认是client。
- --class
CLASS_NAME, 主类名称,含包名
- --jars
逗号分隔的本地JARS, Driver和executor依赖的第三方jar包(Driver是把算子中的逻辑发送到executor中去执行,所以如果逻辑需要依赖第三方jar包 比如oreacl的包时 这里用--jars添加)
- --files
用逗号隔开的文件列表,会放置在每个executor工作目录中
- --conf
spark的配置属性
- --driver-memory
Driver程序使用内存大小(例如:1000M,5G),默认1024M
- --executor-memory
每个executor内存大小(如:1000M,2G),默认1G
Spark standalone with cluster deploy mode only:
- --driver-cores
),仅限于Spark standalone模式
Spark standalone or Mesos with cluster deploy mode only:
- --supervise
失败后是否重启Driver,仅限于Spark alone或者Mesos模式
Spark standalone and Mesos only:
- --total-executor-cores
executor使用的总核数,仅限于SparkStandalone、Spark on Mesos模式
Spark standalone and YARN only:
- --executor-cores
每个executor使用的core数,,standalone默认为worker上所有可用的core。
YARN-only:
- --driver-cores
driver使用的core,仅在cluster模式下,默认为1。
- --queue
QUEUE_NAME 指定资源队列的名称,默认:default
- --num-executors
一共启动的executor数量,默认是2个。
2、资源调度源码分析
- 资源请求简单图
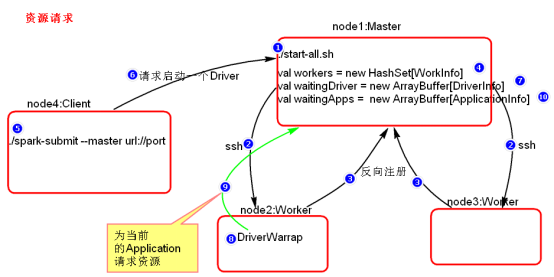
- 资源调度Master路径:

路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/Master/Master.scala
- 提交应用程序,submit的路径:

路径:spark-1.6.0/core/src/main/scala/org.apache.spark/ deploy/SparkSubmit.scala
- 总结:
- Executor在集群中分散启动,有利于task计算的数据本地化。
- 默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
- 如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
- 默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。设置多少个用多少。
- 结论演示
集群中总资源如下:
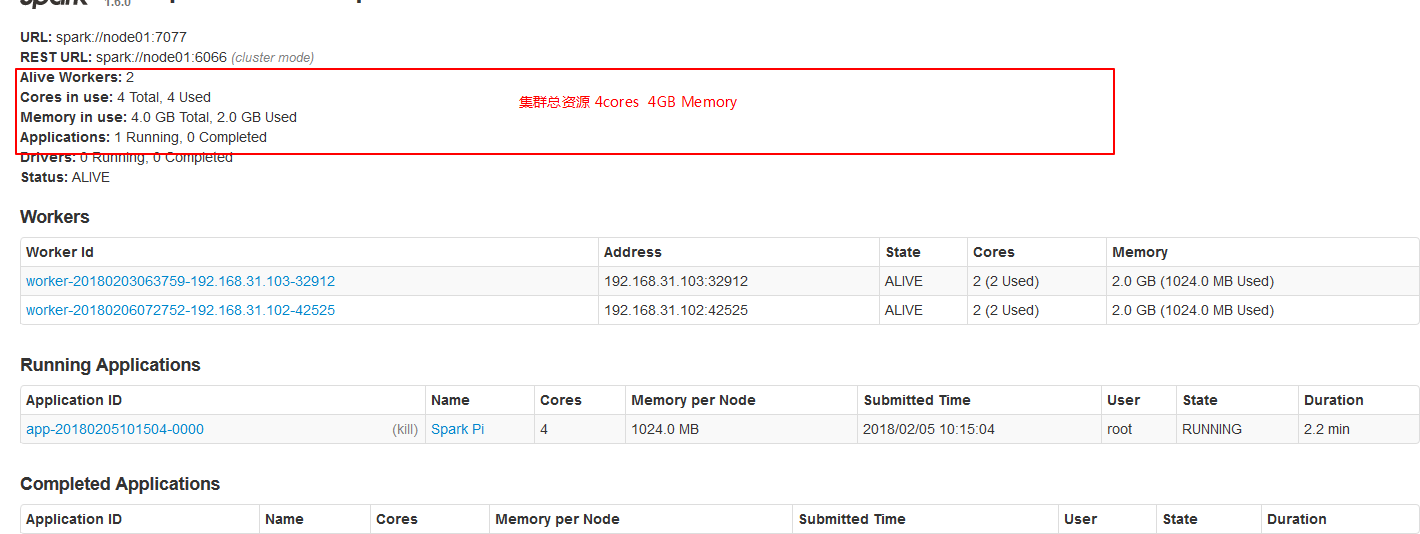
使用Spark-submit提交任务演示。也可以使用spark-shell
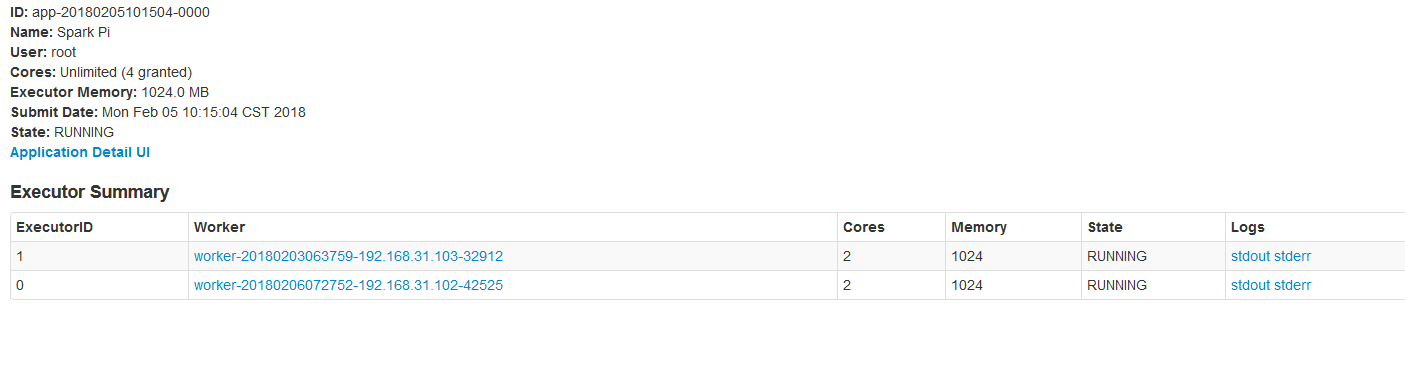
2.1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000

2.2、在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit --master spark://node01:7077 --executor-cores 1 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10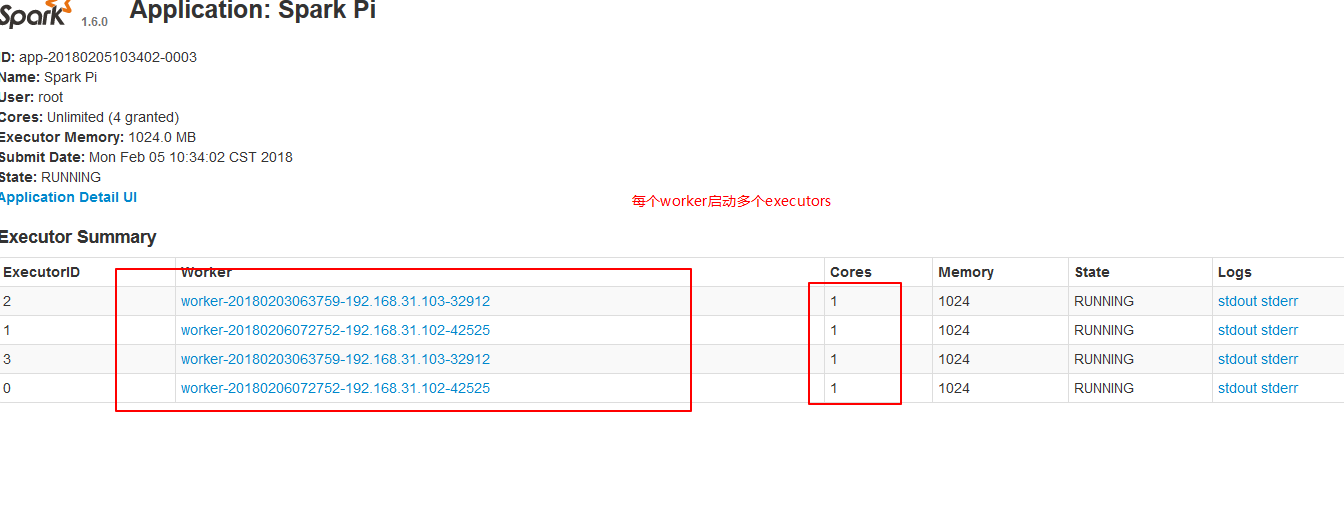
2.3、内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 3g --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
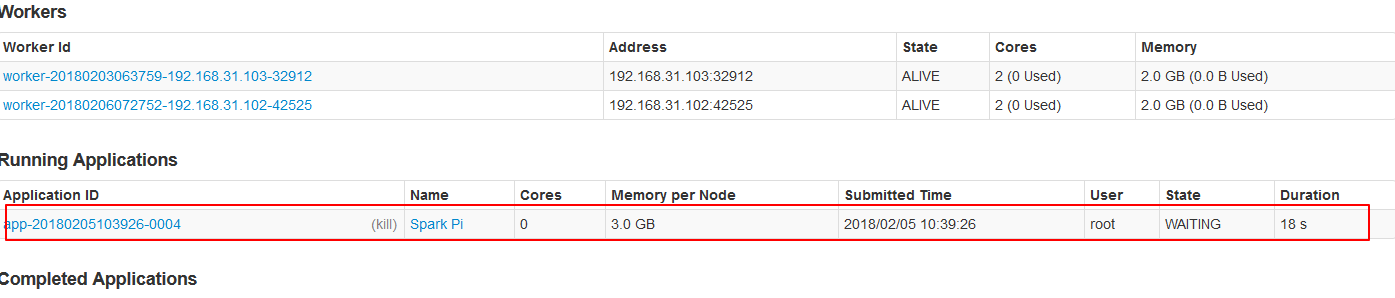

可见并没有启动起来,因为内存不够。。。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
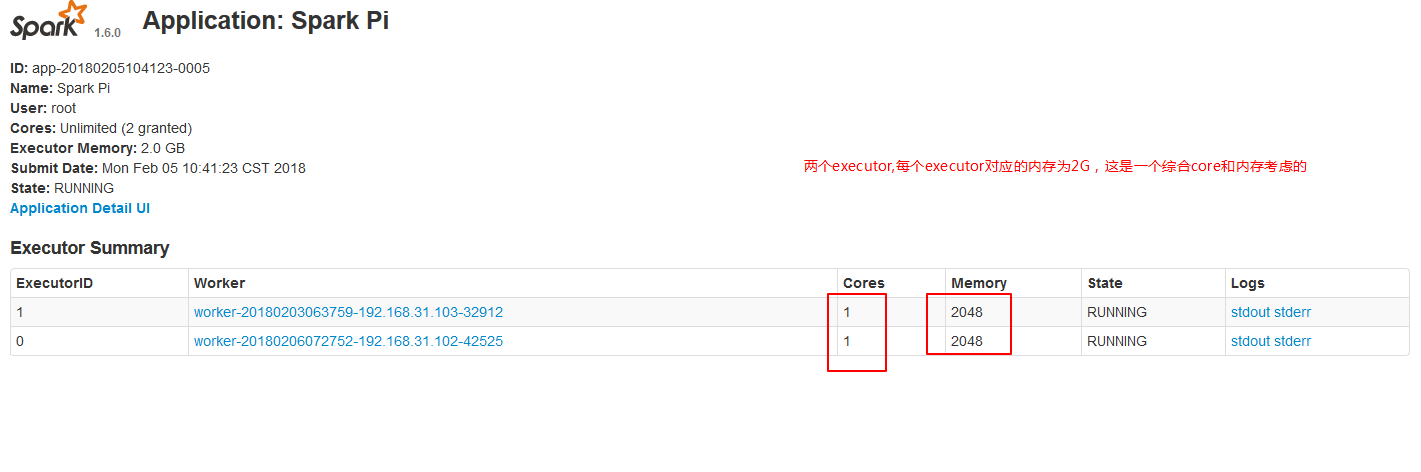
2.4、--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
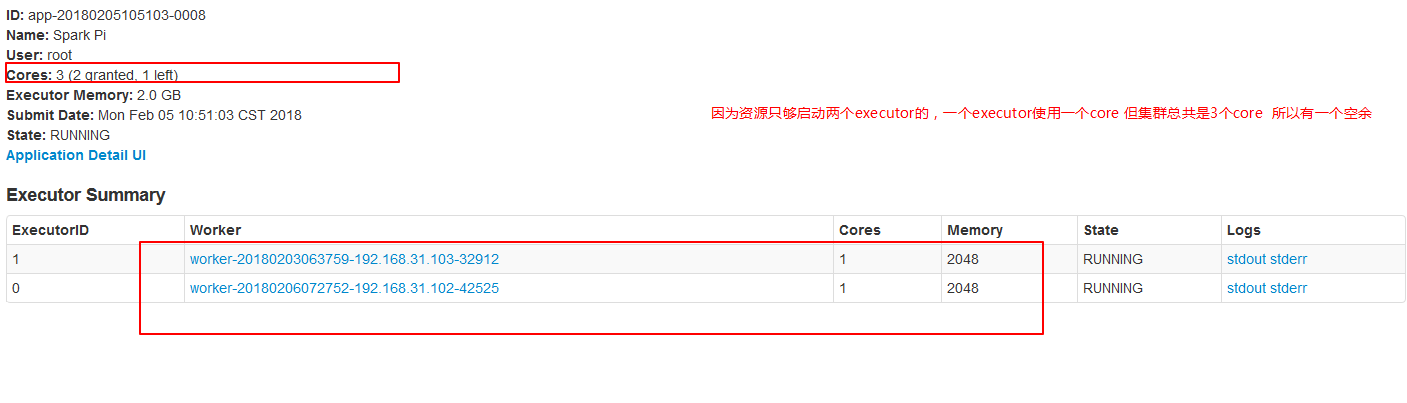
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 1g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 200
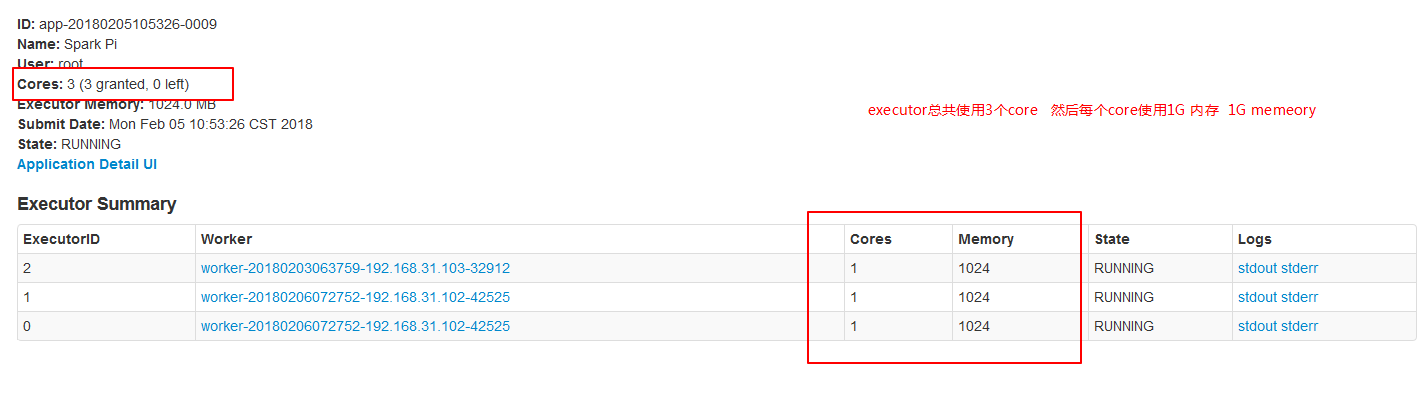
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 200
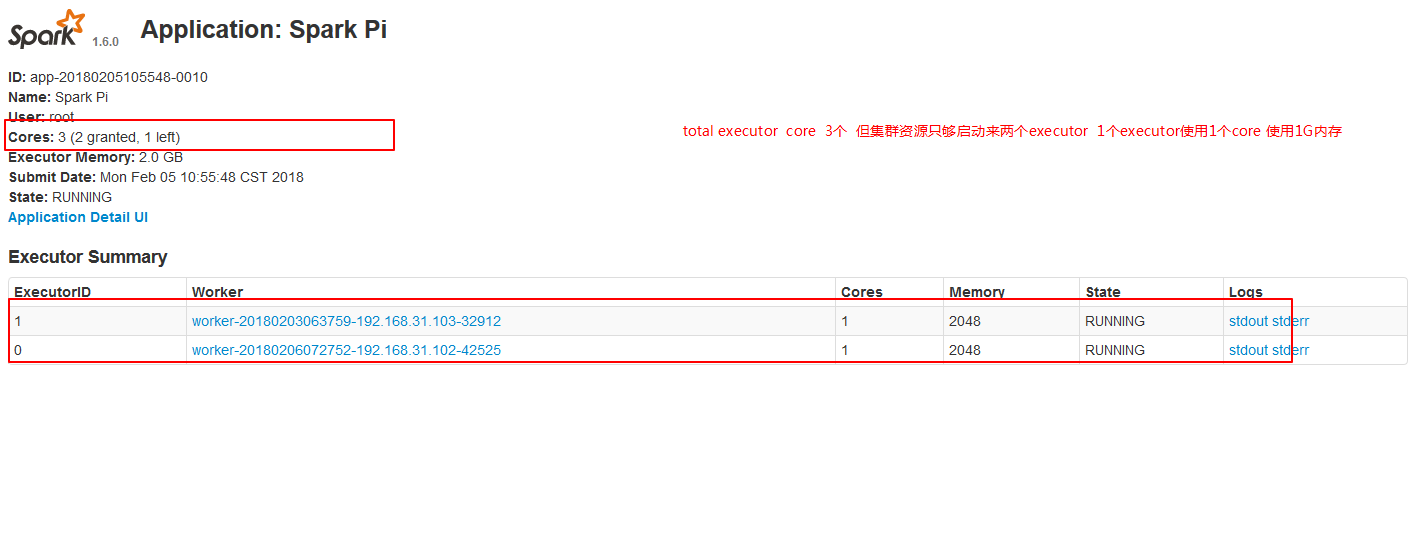
注意:生产环境中一定要加上资源的配置 因为Spark是粗粒度调度资源框架,不指定的话,默认会消耗所有的cores!!!!
3 、任务调度源码分析
- Action算子开始分析
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。
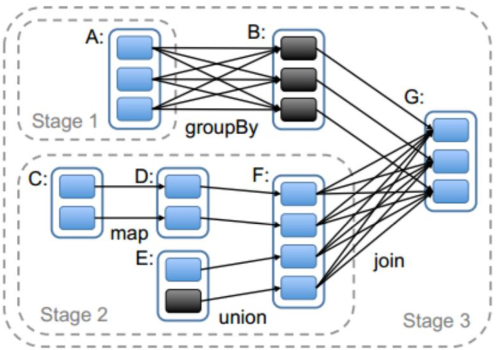
- 划分stage,以taskSet形式提交任务
DAGScheduler 类中getMessingParentStages()方法是切割job划分stage。可以结合以下这张图来分析:
【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用的更多相关文章
- 性能测试分享: Jmeter的源码分析main函数参数
性能测试分享: Jmeter的源码分析main函数参数 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大 ...
- Android查缺补漏(View篇)--事件分发机制源码分析
在上一篇博文中分析了事件分发的流程及规则,本篇会从源码的角度更进一步理解事件分发机制的原理,如果对事件分发规则还不太清楚的童鞋,建议先看一下上一篇博文 <Android查缺补漏(View篇)-- ...
- [Abp vNext 源码分析] - 9. 接口参数的验证
一.简要说明 ABP vNext 当中的审计模块早在 依赖注入与拦截器一文中有所提及,但没有详细的对其进行分析. 审计模块是 ABP vNext 框架的一个基本组件,它能够提供一些实用日志记录.不过这 ...
- spark[源码]-任务调度源码分析[三]
前言 在上一篇文章中,我主要是讲解了DAG阶段的处理,spark是如何将一个job根据宽窄依赖划分出多个stage的,在最后一步中是将生成的TaskSet提交给了TaskSchedulerInmpl的 ...
- jQuery源码分析--为什么在参数列表中传入undefined
(function(window, undefined){ //jQuery code; })(window); 为什么要传入undefined? 1.没有传入undefined: <!DOCT ...
- 小记--------spark的worker原理分析及源码分析
- ReactNative 4Android源码分析二: 《JNI智能指针之实现篇》
文/Tamic http://blog.csdn.net/sk719887916/article/details/53462268 回顾 上一篇介绍了<ReactNative4Android源码 ...
- 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视GCC编译全过程 | 百篇博客分析OpenHarmony源码| v57.01
百篇博客系列篇.本篇为: v57.xx 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视编译全过程 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙 ...
- folly::AtomicHashmap源码分析(二)
本文为原创,转载请注明:http://www.cnblogs.com/gistao/ 背景 上一篇只是细致的把源码分析了一遍,而源码背后的设计思想并没有写,设计思想往往是最重要的,没有它,基本无法做整 ...
随机推荐
- urllib-Proxy
代理的使用: 首先,当我们正确爬取一个网页时,发现代码没有错误,可就是不能爬取网站.原因是有些网站设置了反爬取手段,就是知道你就是用python代码爬取该网站,设置了屏蔽.如果我们又想爬取该网站,便要 ...
- Future模式衍生出来的更高级的应用
再上一个场景:我们自己写一个简单的数据库连接池,能够复用数据库连接,并且能在高并发情况下正常工作. 实现代码1: package test; import java.util.concurrent.C ...
- ubuntu频繁出现 安装包依赖关系
折腾了一下午,还差点重装一次,最后记下解决办法,引以为戒! 第一步,备份官方的默认源 避免自己手贱操作失误,重装系统太费时间 cp /etc/apt/sources.list /etc/apt/sou ...
- 主流图库对比以及JanusGraph入门
1.Overall Comparison Name Neo4j JanusGraph Giraph Jena 1.Compute Framework Yes Yes Yes 2.External Co ...
- 我的 FPGA 学习历程(08)—— 实验:点亮单个数码管
数码管是一种常见的用于显示的电子器件,根据数码管大致可以分为共阴极和共阳极两种,下图所示的是一个共阳极的数码管的电路图(摘自金沙滩工作室的 51 开发板电路图),我的 AX301 开发板与这张图的情况 ...
- [POJ1193][NOI1999]内存分配(链表+模拟)
题意 时 刻 T 内存占用情况 进程事件 0 1 2 3 4 5 6 7 8 9 进程A申请空间(M=3, P=10)<成功> 1 A 2 A B 进程B申请空间(M=4, P=3)< ...
- 20181115 python-第一章学习小结part4
python第一章 流程控制 单分枝任务 If 条件: 满足条件执行动作 注意if下面的缩进,建议直接使用tab键,4个空格太难输入. 双分枝任务 If 条件: 满足条件执行动作 else: 条件 ...
- SpringMVC之拦截器的的配置和使用
拦截器与过滤器的区别:拦截器只能拦截controller的请求,过滤器可以过滤所有请求 (1)实现HandlerInterceptor接口 在执行控制器中的方法之前执行preHandle()中的方法 ...
- lodash 实现一些常见的功能
排序 const sorted = _.orderBy(filtered, [sortColumn.path], [sortColumn.order]); 数组切片 普通的 slice 可传递两个参数 ...
- mysql的必知技巧
1.使用联合索引可以大大减少查询数据,联合索引的顺序尽量为查询的顺序