AIO系列文档(1)----图解ByteBuffer
因何而写
网上关于bytebuffer的文章真的很多,为何在此还要写一篇呢?主要是基于以下几点考虑
用极易的方式认识一下bytebuffer
bytebuffer之第一眼印象
我们可以把bytebuffer理解成如下几个成员组成的一个新对象,对,就是一个普通的java对象,像string一样的java对象。(强调一下,这里只是说这样理解,实际上有些bytebuffer的实现类并非这样实现,并且这里只列出掌握bytebuffer所需要的最小知识集合,其它诸如mark等字段本文并不介绍,以免增加初学者的惑度)
- byte[] bytes: 用来存储数据
- int capacity: 用来表示bytes的容量,那么可以想像capacity就等于bytes.size(),此值在初始化bytes后,是不可变的。
- int limit: 用来表示bytes实际装了多少数据,可以容易想像得到limit <= capacity,此值是可灵活变动的
- int position: 用来表示在哪个位置开始往bytes写数据或是读数据,此值是可灵活变动的
通过下图,对bytebuffer形成一个感观认识吧
bytebuffer之常用操作及各操作对内部变量带来的变化
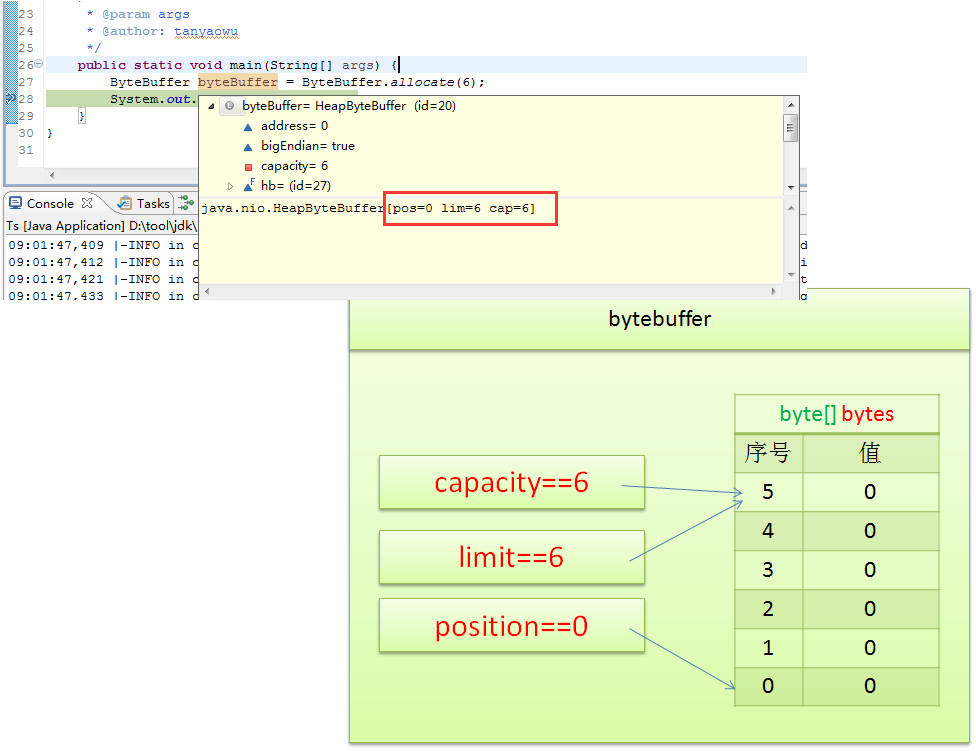
创建bytebuffer: ByteBuffer.allocate(6)
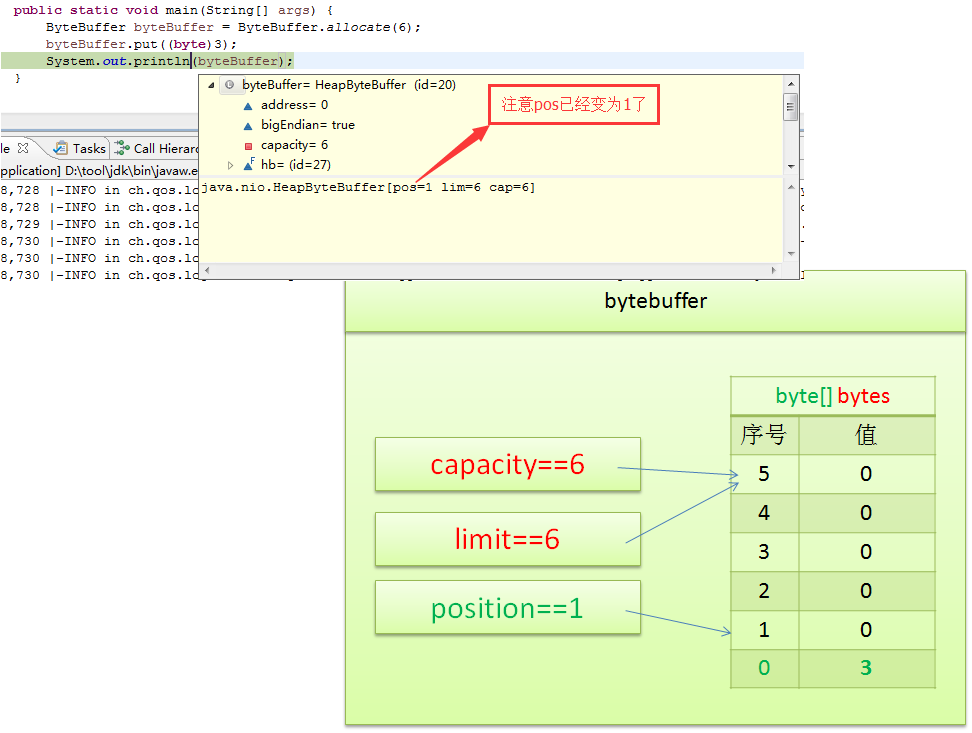
写入一个字节: byteBuffer.put((byte)3)
读取一个字节: byte bs = byteBuffer.get()
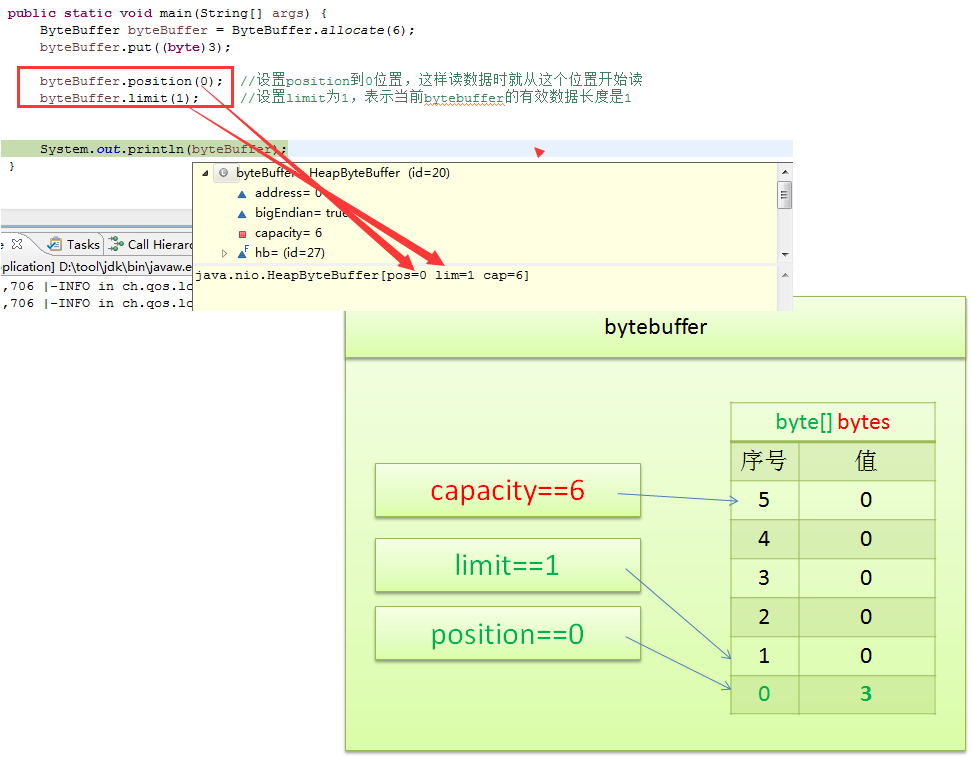
对于刚刚写好的bytebuffer,我们要读取它的内容,需要先设置一下position和limit,否则读的位置就不对
byteBuffer.position(0); //设置position到0位置,这样读数据时就从这个位置开始读
byteBuffer.limit(1); //设置limit为1,表示当前bytebuffer的有效数据长度是1
我们看一下,设置position和limit后,bytebuffer的内部变化
接下来,我们就可以读取刚才写入的数据了
byte bs = byteBuffer.get();
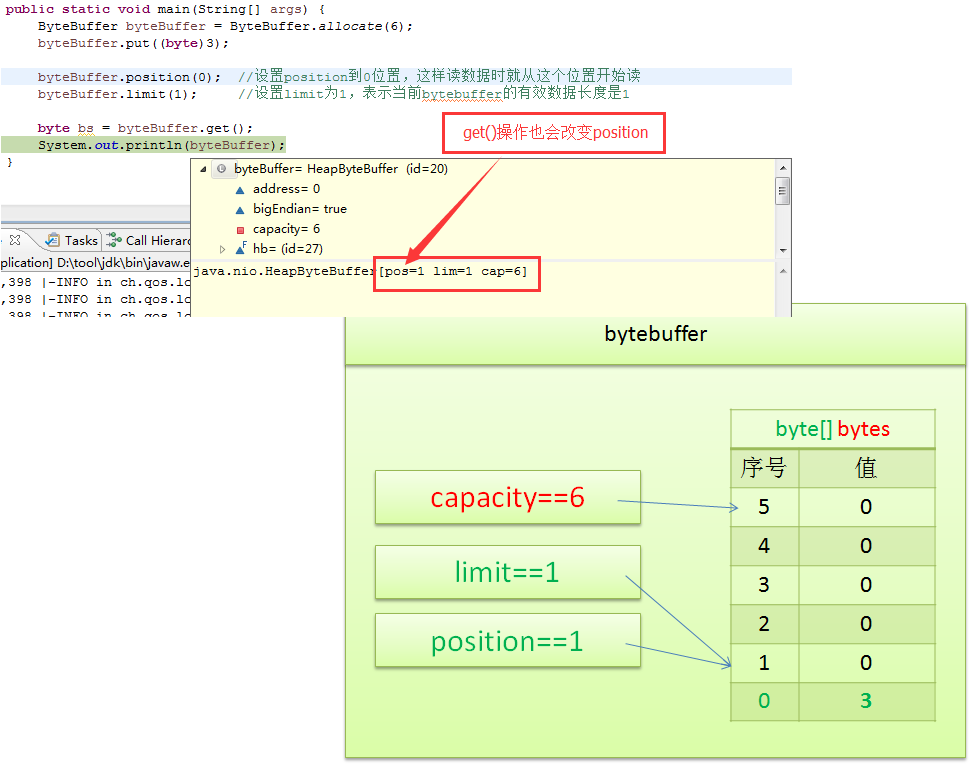
bytebuffer之使用心得
这里说的是作者本人使用bytebuffer的一些心得,这些与其说是心得,不如说是实践+测试得来的一些经验,所以并不保证就是权威的,欢迎有更深研究的朋友来合理讨论,如果有不同意见,可以以更好的论据来说服对方。
合理灵活运用HeapByteBuffer.array()
HeapByteBuffer.array()返回的是其内部byte[],我们拿到这个后,就可以随意对这个byte[]随便操作了,可以参考t-io的SendRunnable.java的下面这段代码
ByteBuffer allByteBuffer = ByteBuffer.allocate(allBytebufferCapacity);
byte[] dest = allByteBuffer.array();
for (ByteBuffer byteBuffer : byteBuffers) {
if (byteBuffer != null) {
int length = byteBuffer.limit();
int position = allByteBuffer.position();
System.arraycopy(byteBuffer.array(), 0, dest, position, length);
allByteBuffer.position(position + length);
}
}
注意:DirectBuffer内部是没有byte[]的,也就没有所谓的byte[]操作了。
jdk自带的bytebuffer已经足够好用
有一些nio/aio框架喜欢自己弄一套bytebuffer来,既增加了作者自己的工作量,又增加了用户的学习成本,但我们要知道一点,nio/aio在发送数据时,最终的参数是jdk的bytebuffer,我们真的有必要再作一次转换和计算吗?尽管某些中间过程是“零拷贝”(这个“零拷贝”也是有额外的计算成本的)的,但是jdk版bytebuffer的诞生到发送完毕,这整个过程经历了哪些操作呢?真的是如某书某博客上所说的“零拷贝”吗?更不应该把某些对象池的做法也牵强附会到“零拷贝”的概念中来----对象池属对象重复利用范畴,既然是重复利用自然便已经默认有零拷贝的属性了,但是对象池本身的维护也是需要消耗资源的,所以并不是所有场景说用了对象池,性能就提升了,有时候用不好反而增加负担,所以万事要以测试数据为准,不应盲目人云亦云!
最后附上bytebuffer的示例程序
这里附上bytebuffer的示例程序,用户可以自己debug观察观察,增加bytebuffer的相关概念,以便更灵活的运用bytebuffer
import java.nio.ByteBuffer; /**
* @author tanyaowu
* 2017年5月1日 上午9:00:50
*/
public class Ts { /**
*
* @author: tanyaowu
*/
public Ts() {
} /**
* @param args
* @author: tanyaowu
*/
public static void main(String[] args) {
ByteBuffer byteBuffer = ByteBuffer.allocate(6);
byteBuffer.put((byte)3); byteBuffer.position(0); //设置position到0位置,这样读数据时就从这个位置开始读
byteBuffer.limit(1); //设置limit为1,表示当前bytebuffer的有效数据长度是1 byte bs = byteBuffer.get();
System.out.println(byteBuffer);
}
}
AIO系列文档(1)----图解ByteBuffer的更多相关文章
- AIO系列文档(2)----TIO使用
AIO系列文档(1)----图解ByteBuffer中介绍了ByteBuffer用法,下面通过介绍t-io介绍如何使用: hello world例子简介 本例子演示的是一个典型的TCP长连接应用,代码 ...
- 老猿学5G扫盲贴:3GPP规范文档命名规则及同系列文档阅读指南
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在学习5G规范过程中,有些内容把握不定的时候,有时 ...
- Sharepoint学习笔记—ECM系列—文档列表的Metedata Navigation与Key Filter功能的实现
如果一个文档列表中存放了成百上千的文档,想要快速的找到你想要的还真不是件容易的事,Sharepoint提供了Metedata Navigation与Key Filter功能可以帮助我们快速的过滤和定位 ...
- Sharepoint学习笔记—ECM系列--文档集(Document Set)的实现
文档集是 SharePoint Server 2010 中的一项新功能,它使组织能够管理单个可交付文档或工作产品(可包含多个文档或文件).文档集是特殊类型的文件夹,它合并了唯一的文档集属性以及文件夹和 ...
- Thinking in Java系列 文档+代码+简评
声明:本人无意侵犯原作者的版权,这里可下载的文档都属于作者自行开放下载的,统一放置在这里是因为不可预测的原因使得原文档和代码不方便下载,故将我所收集的内容统一在这里,如果这里的内容侵犯了别人,请告知我 ...
- 微软官方的.net系列文档
闲下来的时候给自己补充补充基础,微软官方的相关技术文档地址,最新最全最官方:https://docs.microsoft.com/zh-cn/ 其中.NET专区:https://docs.micros ...
- 一起买Beta版本系列文档
一起买beta版本文档报告汇总 031402401鲍亮 031402402曹鑫杰 031402403常松 031402412林淋 031402418汪培侨 031402426许秋鑫 一.Beta版本冲 ...
- JEECMS8——系列文档
jeecms8 系列文章地址 https://blog.csdn.net/weixin_37490221/article/details/78652035
- 框架优化系列文档:SVN中非版本控制文件忽略上传的设置
对于SVN代码库,只应该上传源代码.资源文件等内容进行版本管理,通常编译后的二进制文件.程序包等生成产物是不应该放到SVN上做版本管理的.因此在svn的客户端工具中设置svn的属性:svn:ignor ...
随机推荐
- 2、阿里云ECS发送邮件到腾讯企业邮箱(ECS默认不开启25端口)
阿里云ECS默认禁用25端口导致发邮件失败. 方法一: 使用shell脚本发送邮件,需要配置mailx 1.安装软件 yum install mailx 2.配置 vim /etc/mail.rc在文 ...
- 想明白为什么C->D
C公司为什么不行? 钱不够 第一个原因是在新世界,C能够给我的钱是远远低于市场价的.如果按照现公司的行情,也就一个社招人员的白菜价. 领导不行 C公司的领导,从面相上看就无法让我信服.领导力中下,忽悠 ...
- Cross-Origin Resource Sharing(CORS)详解,CORS详解,CORS原理分析
Keywords CORS, 跨域,JS跨域调用,Ajax CORS 跨域,跨域详解,CORS跨域原理 Cross-Origin Resource Sharing详解 Cross-Origin Res ...
- C# 防止程序多开的两种方法
互斥对象防止程序多开 private void Form1_Load(object sender, EventArgs e) { bool Exist;//定义一个bool变量,用来表示是否已经运行 ...
- Trie for string LeetCode
Trie build and search class TrieNode { public: TrieNode * next[]; bool is_word; TrieNode(bool b = fa ...
- 设计完美的策略模式,消除If-else
策略模式是oop中最著名的设计模式之一,是对方法行为的抽象,可以归类为行为设计模式,也是oop中interface经典的应用.其特点简单又实用,是我最喜欢的模式之一.策略模式定义了一个拥有共同行为的算 ...
- java时间处理,获取当前时间的小时,天,本周周几,本周周一的日期,本月一号的日期
1.时间转时间戳 public static long strToTimestamp(String dateTimeStr) throws Exception { Timestamp time = T ...
- Hadoop HDFS安装、环境配置
hadoop安装 进入Xftp将hadoop-2.7.3.tar.gz 复制到自己的虚拟机系统下的放软件的地方,我的是/soft/software 在虚拟机系统装软件文件里,进行解压缩并重命名 进入p ...
- Spark实战
实战 数据导入Hive中全量: 拉链增量:用户.商品表数据量大时用 拉链表动作表 增量城市信息 全量 需求一: 获取点击.下单和支付数量排名前 的品类 ①使用累加器: click_category_i ...
- Android中Adapter类的使用 “Adapter”
Adapter用来把数据绑定到扩展了AdapterView类的视图组(例如:ListView或Gallery).Adapter负责创建代表所绑定父视图中的底层数据的子视图. 可以创建自己的Adapte ...