flink Standalone Cluster
Requirements
Software Requirements
Flink runs on all UNIX-like environments, e.g. Linux, Mac OS X, and Cygwin (for Windows) and expects the cluster to consist of one master node and one or more worker nodes. Before you start to setup the system, make sure you have the following software installed on each node:
- Java 1.8.x or higher,
- ssh (sshd must be running to use the Flink scripts that manage remote components)
If your cluster does not fulfill these software requirements you will need to install/upgrade it.
Having passwordless SSH and the same directory structure on all your cluster nodes will allow you to use our scripts to control everything.
ssh免密登录:
在源机器执行
ssh-keygen //一路回车,生成公钥,位置~/.ssh/id_rsa.pub
ssh-copy-id -i ~/.ssh/id_rsa.pub root@目的机器 //将源机器生成的公钥拷贝到目的机器的~/.ssh/authorized_keys
或者 手动将源机器生成的公钥拷贝到目的机器的~/.ssh/authorized_keys。注意:不要有换行
完成!
JAVA_HOME Configuration
系统环境配置了JAVA_HOME即可,无需如下操作
Flink requires the JAVA_HOME environment variable to be set on the master and all worker nodes and point to the directory of your Java installation.
You can set this variable in conf/flink-conf.yaml via the env.java.home key.
Flink Setup
Go to the downloads page and get the ready-to-run package. Make sure to pick the Flink package matching your Hadoop version. If you don’t plan to use Hadoop, pick any version.
After downloading the latest release, copy the archive to your master node and extract it:
tar xzf flink-*.tgz
cd flink-*Configuring Flink (不做任何设置,在单节点上直接运行bin/start-cluster.sh,可在单机启动单个jobmanager和单个taskmanager,方便debug代码)
After having extracted the system files, you need to configure Flink for the cluster by editing conf/flink-conf.yaml.
Set the jobmanager.rpc.address key to point to your master node. You should also define the maximum amount of main memory the JVM is allowed to allocate on each node by setting the jobmanager.heap.mb and taskmanager.heap.mb keys.
These values are given in MB. If some worker nodes have more main memory which you want to allocate to the Flink system you can overwrite the default value by setting the environment variable FLINK_TM_HEAP on those specific nodes.
Finally, you must provide a list of all nodes in your cluster which shall be used as worker nodes. Therefore, similar to the HDFS configuration, edit the file conf/slaves and enter the IP/host name of each worker node. Each worker node will later run a TaskManager.
The following example illustrates the setup with three nodes (with IP addresses from 10.0.0.1 to 10.0.0.3 and hostnames master, worker1, worker2) and shows the contents of the configuration files (which need to be accessible at the same path on all machines):
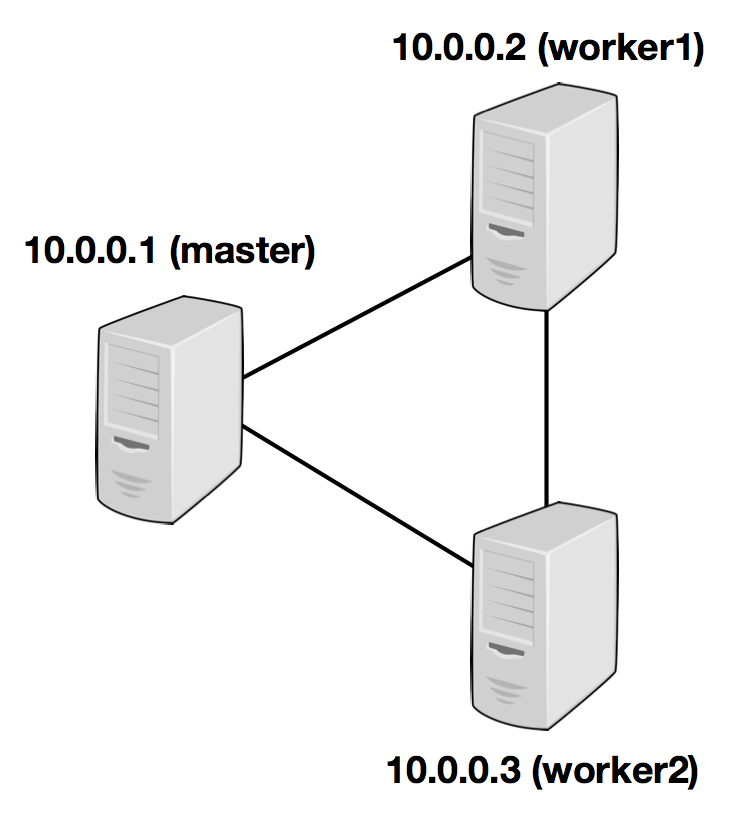
jobmanager.rpc.address: 10.0.0.1
注意:需要在所有需要启动taskmanager的机器进行如上配置
/path/to/flink/conf/slaves
10.0.0.2
10.0.0.3
The Flink directory must be available on every worker under the same path. You can use a shared NFS directory, or copy the entire Flink directory to every worker node.
Please see the configuration page for details and additional configuration options.
In particular,
- the amount of available memory per JobManager (
jobmanager.heap.mb), - the amount of available memory per TaskManager (
taskmanager.heap.mb), - the number of available CPUs per machine (
taskmanager.numberOfTaskSlots), - the total number of CPUs in the cluster (
parallelism.default) and - the temporary directories (
taskmanager.tmp.dirs)
are very important configuration values.
Starting Flink
The following script starts a JobManager on the local node and connects via SSH to all worker nodes listed in the slaves file to start the TaskManager on each node. Now your Flink system is up and running. The JobManager running on the local node will now accept jobs at the configured RPC port.
Assuming that you are on the master node and inside the Flink directory:
bin/start-cluster.shTo stop Flink, there is also a stop-cluster.sh script.
Adding JobManager/TaskManager Instances to a Cluster
You can add both JobManager and TaskManager instances to your running cluster with the bin/jobmanager.sh and bin/taskmanager.shscripts.
Adding a JobManager
bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-allAdding a TaskManager
bin/taskmanager.sh start|start-foreground|stop|stop-allMake sure to call these scripts on the hosts on which you want to start/stop the respective instance.
flink Standalone Cluster的更多相关文章
- flink初识及安装flink standalone集群
flink architecture 1.可以看出,flink可以运行在本地,也可以类似spark一样on yarn或者standalone模式(与spark standalone也很相似),此外fl ...
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文主要讲述在standalone cluster部署模式下,Spark Application在整个运行期间,资源(主要是cpu core和内存)的申请与 ...
- Spark Standalone cluster try
Spark Standalone cluster node*-- stop firewalldsystemctl stop firewalldsystemctl disable firewalld-- ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Spark运行模式_spark自带cluster manager的standalone cluster模式(集群)
这种运行模式和"Spark自带Cluster Manager的Standalone Client模式(集群)"还是有很大的区别的.使用如下命令执行应用程序(前提是已经启动了spar ...
- Flink standalone模式作业执行流程
宏观流程如下图: client端 生成StreamGraph env.addSource(new SocketTextStreamFunction(...)) .flatMap(new FlatMap ...
- 【转帖】两年Flink迁移之路:从standalone到on yarn,处理能力提升五倍
两年Flink迁移之路:从standalone到on yarn,处理能力提升五倍 https://segmentfault.com/a/1190000020209179 flink 1.7k 次阅读 ...
- Apache Flink 的迁移之路,2 年处理效果提升 5 倍
一.背景与痛点 在 2017 年上半年以前,TalkingData 的 App Analytics 和 Game Analytics 两个产品,流式框架使用的是自研的 td-etl-framework ...
- 重磅!解锁Apache Flink读写Apache Hudi新姿势
感谢阿里云 Blink 团队Danny Chan的投稿及完善Flink与Hudi集成工作. 1. 背景 Apache Hudi 是目前最流行的数据湖解决方案之一,Data Lake Analytics ...
随机推荐
- redis 系列8 数据结构之整数集合
一.概述 整数集合(intset)是集合键的底层实现之一, 当一个集合只包含整数值元素,并且这个集合元素数量不多时, Redis就会使用整数集合作为集合键的底层实现.下面创建一个只包含5个元素的集合键 ...
- SpringBoot入门教程(十)应用监控Actuator
Actuator可能大家非常熟悉,它是springboot提供对应用自身监控,以及对应用系统配置查看等功能.spring-boot-starter-actuator模块的实现对于实施微服务的中小团队来 ...
- Asp.Net SignalR - 持久连接类
持久连接类 通过SignalR持久连接类可以快速的构建一个即时通讯的应用,上篇博文已经我们创建一个owin Startup类和一个持久连接类来完成我们的工作,然后在Startup类的Configura ...
- .NET快速信息化系统开发框架 V3.2->Web版本新增“文件管理中心”集上传、下载、文件共享等一身,非常实用的功能
文件中心是3.2版本开始新增的一个非常实用功能,可以归档自己平时所需要的文件,也可以把文件分享给别人,更像一个知识中心.文件中心主界面如下图所示,左侧“我的网盘”展示了用户对文件的分类,只能自己看到, ...
- 浅析MySQL 8忘记密码处理方式
对MySQL有研究的读者,可能会发现MySQL更新很快,在安装方式上,MySQL提供了两种经典安装方式:解压式和一键式,虽然是两种安装方式,但我更提倡选择解压式安装,不仅快,还干净.在操作系统上,My ...
- tuxedo开发
近来一直在和某电信的系统做对接开发,需要从对方系统(tuxedo)中查询数据后进行显示,本来是个挺简单的事情,无奈tuxedo这个东西以前真是没听说过,网上能用的资料也不多,真是苦了我这段时间,还好已 ...
- 逐步搭建vs2015的API自带认证调用+跨域调用
demo百度网盘链接:https://pan.baidu.com/s/1HJ19RJwS6qCixui8KF8QBg 提取码:yt1c 首先我们建立一个webapi项目,这个就不需要小编解释了.如下图 ...
- 冒泡排序/选择排序/插入排序(c#)
---恢复内容开始--- 每次看这些排序都像没见过一样,完全理解不了,可是不久前明明了解的十分透彻.记下来记下来记下来! 1>>>冒泡排序:相邻的两两相比 把大的(或者小的)放后边, ...
- python学习笔记(五)、抽象
不知不觉已经快毕业一年了,想想2018年过的可真舒适!!!社会就像一锅水,不同地方温度不同,2018年的我就身处温水中,没有一丝想要进取之心. 1 抽象 抽象在程序中可谓是神来之笔,辣么什么是抽象呢? ...
- LeetCode 176. 第二高的薪水(MySQL版)
0.前言 最近刷LeetCode 刷数据库题目 由于数据库课上的是SQL,而MySQL有许多自己的函数的,怕把刚学会的函数忘记 特在此记录! 1.题目 编写一个 SQL 查询,获取 Employee ...