day22-多并发编程基础(三)
今天学习了并发编程中的最后一部分,协程,也是python中区别于java,c等语言中很大不同的一部分
1.协程产生的背景
2.协程的概念
3.yield模拟协程
4.协程中主要的俩个模块
5.协程的应用
开始今日份总结
1.协程产生的背景
之前我们学习了线程、进程的概念,了解了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位。按道理来说我们已经算是把cpu的利用率提高很多了。但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程、创建线程、以及管理他们之间的切换。
随着我们对于效率的追求不断提高,基于单线程来实现并发又成为一个新的课题,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发。这样就可以节省创建线进程所消耗的时间。
为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长

ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
- #1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
- #2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
2.协程的概念
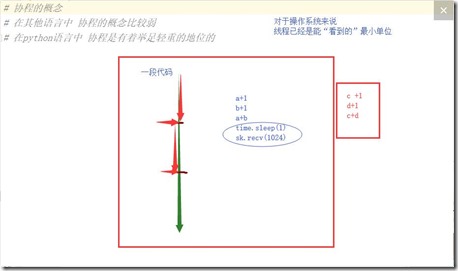
协程:在其他语言中很少去用,在python中非常重要的点,对于操作系统来说,线程已经是操作系统能够看到的最小单位,操作系统无法感知协程
- 协程的本质是,就是一条线程分成多份,每一份执行一段代码,多段代码可以在一个线程上来回切换
- 如果能在一段代码执行,在遇到I/O操作的时候,记录此时的状态,去执行另外一段代码,相当于完成利用协程完成了更加充分利用线程的目的
协程利用切换来规避I/O操作带来的好处
- 一条线程可以执行多个任务
- 减少了一个线程的阻塞,帮助线程最大程度的抢占CPU资源
- 协程由于操作系统不可见,不由操作系统控制吗,协程是用户级,减少I/O操作,提高CPU的计算能力
- 协程之间永远数据安全,----因为很多协程本质上就是一条线程
在pthon中,协程是非常重要的。
3.yield模拟协程
那么现在就用yield来模拟协程,毕竟yield也是可以在代码级别记录状态
- #代码如下,yield本质是保存现在的状态,send是调用其他函数
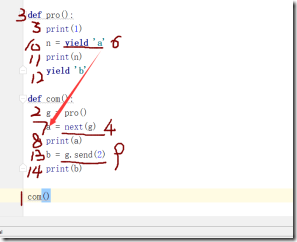
- def pro():
- print(1)
- n = yield 'a'
- print(n)
- yield 'b'
- def com():
- g = pro()
- a = next(g)
- print(a)
- b = g.send(2)
- print(b)
- com()
代码执行顺序如下
相比于串行的去执行,单纯的用yield只会让时间更长
下面用yield测试一下之前用到的生产者消费者模型
- #单纯的生产者,消费者模型
- import time
- def consumer(res):
- '''单纯的处理数据'''
- pass
- def producer():
- res =[]
- for i in range(10000000):
- pass
- return res
- start = time.time()
- res = producer()
- consumer(res)
- end = time.time()
- print(end-start)
- #结果
- 0.347031831741333
- #用yield模式尝试
- import time
- def consumer():
- while True:
- x = yield
- def producer():
- g = consumer()
- next(g)
- for i in range(10000000):
- g.send(i)
- start = time.time()
- #并发的执行任务
- producer()
- end = time.time()
- print(end-start)
- #结果
- 1.8232519626617432
可以看出来,单纯线程之间俩个任务的切换时很可浪费时间的,如果数据量大存储数据也是很需要时间的,每一次切换都需要记住当前的状态,切换回去需要读取之前的状态。
如果我们遇到I/0操作的时候可以自动切换,并且I/O阻塞时间可以和执行代码共享这段时间,才是真正的提高了程序的执行率,yield只是保存了状态。
可以用yield实现一个协程的操作。
4.协程中主要的俩个模块
协程中的主要有俩个模块,俩个模块都是第三方模块,既然是第三方模块那就先说明一下,第三方模块的导入方法
- 方法一:在pycharm中,file—settings—project’xxx’—Project Interpreter—‘+’—搜索要安装的包—InstallPackage
- 方法二:在cmd中 pip install ‘gevent’ 。pip list 查看已经安装的包目录。pip unistalled ‘’ 卸载已经安装的包
这个时候需要俩个第三方模块,一个是gevent,一个是greenlet,不过gevent是greenlet的上层模块,,gevent规避I/O操作,判断程序中的I/O操作,遇到I/O就切换到另一个任务去执行。greenlet主要是俩个任务之间的切换,状态的保存以及读取
4.1 greenlet模块
安装 :pip3 install greenlet
查看代码
- import greenlet
- def eat():
- print('eat1')
- g2.switch()
- print('eat2')
- g2.switch()
- def sleep():
- print('sleep1')
- g1.switch()
- print('sleep2')
- g1 = greenlet.greenlet(eat)
- g2 = greenlet.greenlet(sleep)
- g1.switch()
- #结果
- eat1
- sleep1
- eat2
- sleep2
greenlet 模块只是记录了状态并且在切换回去的是读取了状态,并没有真正意思的自动规避I/O操作
4.2 gevent模块
这个时候就需要了gevent模块了
安装:pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
- #gevent模块的使用方法
- g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
- g2=gevent.spawn(func2)
- g1.join() #等待g1结束
- g2.join() #等待g2结束
- #或者上述两步合作一步:gevent.joinall([g1,g2])
- g1.value#拿到func1的返回值
先运用最基本的协程函数
- import gevent
- def eat():
- print('eat1')
- gevent.sleep(1)
- print('eat2')
- def sleep():
- print('sleep1')
- gevent.sleep(1)
- print('sleep2')
- g1 = gevent.spawn(eat)#实例化一个gevent对象
- g2 = gevent.spawn(sleep)#实例化一个gevent对象
- gevent.joinall([g1,g2])#监测到有I/O就切换
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前,或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头。
查看更改后的代码
- from gevent import monkey
- monkey.patch_all()#用来匹配所有的I/O操作
- import gevent
- import time
- def eat():
- print('eat1')
- time.sleep(1)
- print('eat2')
- def sleep():
- print('sleep1')
- time.sleep(1)
- print('sleep2')
- g1 = gevent.spawn(eat)#实例化一个gevent对象
- g2 = gevent.spawn(sleep)#实例化一个gevent对象
- gevent.joinall([g1,g2])#监测到有I/O就切换
最后我们来看一下协程的id号,代码如下
- from gevent import monkey
- monkey.patch_all()
- import gevent
- import time
- from threading import currentThread
- def eat():
- print('eat:',currentThread())
- print('eat1')
- time.sleep(1)
- print('eat2')
- def sleep():
- print('sleep:',currentThread())
- print('sleep1')
- time.sleep(1)
- print('sleep2')
- g1 = gevent.spawn(eat)
- g2 = gevent.spawn(sleep)
- gevent.joinall([g1,g2])
- #结果如下
- eat: <_DummyThread(DummyThread-1, started daemon 53379528)>
- eat1
- sleep: <_DummyThread(DummyThread-2, started daemon 53380480)>
- sleep1
- eat2
- sleep2
我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程

5.协程的应用
对于协程一般使用比较多的地方为网络I/O以及sleep操作,不过一般我们程序代码基本是不会去使用sleep操作,所以日常用的比较多的就是网络爬虫以及socket.server
5.1 网络爬虫简易
看代码
- #普通打开方式
- import time
- from urllib import request
- def func(name,url):
- ret = request.urlopen(url)#获取网页
- with open(name+'.html','wb') as f:
- f.write(ret.read())
- url_lst = [
- ('python','https://www.python.org/'),
- ('blog','http://www.cnblogs.com/Eva-J/articles/8324673.html'),
- ('pypi','https://pypi.org/project/pip/'),
- ('blog2','https://www.cnblogs.com/z-x-y/p/9237706.html'),
- ('douban','https://www.douban.com/')
- ]
- start = time.time()
- for url_item in url_lst:
- func(*url_item)
- end = time.time()
- print('普通打开方式',end-start)
- #协程打开方式
- from gevent import monkey
- monkey.patch_all()
- import gevent
- from urllib import request
- import time
- def func(name,url):
- ret = request.urlopen(url)
- with open(name+'2.html','wb')as f:
- f.write(ret.read())
- url_lst = [
- ('python','https://www.python.org/'),
- ('blog','http://www.cnblogs.com/Eva-J/articles/8324673.html'),
- ('pypi','https://pypi.org/project/pip/'),
- ('blog2','https://www.cnblogs.com/z-x-y/p/9237706.html'),
- ('douban','https://www.douban.com/')
- ]
- start = time.time()
- g_list =[]
- for url_item in url_lst:
- g = gevent.spawn(func,*url_item)
- g_list.append(g)
- gevent.joinall(g_list)
- end = time.time()
- print('协程打开方式',end-start)
看结果
普通打开方式 6.35495924949646
协程打开方式 1.931349754333496
我们会发现现在在少量的url状况下是这样,如果在大量的代码下,这个时间就会缩减的更多。
补充:这个是我在测试的时候发现的状况,在已有文件,打开文件并重新写入文件内容,耗费的时间会高很多!
在爬虫的时候还是用协程,这样会更快的拿到我们需要的数据并对其作出分析!
5.2 用协程实现socket.server
看代码
#服务端
- #服务端
- import socket
- from gevent import monkey
- monkey.patch_all()
- import gevent
- def talk(conn):
- while True:
- msg = conn.recv(1024).decode()
- conn.send(msg.upper().encode('utf-8'))
- sk =socket.socket()
- sk.bind(('127.0.0.1',8500))
- sk.listen()
- while True:
- conn,addr = sk.accept()
- gevent.spawn(talk,conn)
#客户端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',8500))
- while True:
- msg = input('--->').encode('utf-8')
- sk.send(msg)
- recv_msg = sk.recv(1024).decode('utf-8')
- print(recv_msg)
- sk.close()
任何基础知识都是看着简单,运用难,多练习就好啦!
day22-多并发编程基础(三)的更多相关文章
- 并发编程(三)Promise, Future 和 Callback
并发编程(三)Promise, Future 和 Callback 异步操作的有两个经典接口:Future 和 Promise,其中的 Future 表示一个可能还没有实际完成的异步任务的结果,针对这 ...
- TCP与UDP比较 以及并发编程基础知识
一.tcp比udp真正可靠地原因 1.为什么tcp比udp传输可靠地原因: 我们知道在传输数据的时候,数据是先存在操作系统的缓存中,然后发送给客户端,在客户端也是要经过客户端的操作系统的,因为这个过程 ...
- Java并发编程系列-(1) 并发编程基础
1.并发编程基础 1.1 基本概念 CPU核心与线程数关系 Java中通过多线程的手段来实现并发,对于单处理器机器上来讲,宏观上的多线程并行执行是通过CPU的调度来实现的,微观上CPU在某个时刻只会运 ...
- Java并发编程基础三板斧之Semaphore
引言 最近可以进行个税申报了,还没有申报的同学可以赶紧去试试哦.不过我反正是从上午到下午一直都没有成功的进行申报,一进行申报 就返回"当前访问人数过多,请稍后再试".为什么有些人就 ...
- [Java并发编程(三)] Java volatile 关键字介绍
[Java并发编程(三)] Java volatile 关键字介绍 摘要 Java volatile 关键字是用来标记 Java 变量,并表示变量 "存储于主内存中" .更准确的说 ...
- python中并发编程基础1
并发编程基础概念 1.进程. 什么是进程? 正在运行的程序就是进程.程序只是代码. 什么是多道? 多道技术: 1.空间上的复用(内存).将内存分为几个部分,每个部分放入一个程序,这样同一时间在内存中就 ...
- Java并发编程基础
Java并发编程基础 1. 并发 1.1. 什么是并发? 并发是一种能并行运行多个程序或并行运行一个程序中多个部分的能力.如果程序中一个耗时的任务能以异步或并行的方式运行,那么整个程序的吞吐量和可交互 ...
- 并发-Java并发编程基础
Java并发编程基础 并发 在计算机科学中,并发是指将一个程序,算法划分为若干个逻辑组成部分,这些部分可以以任何顺序进行执行,但与最终顺序执行的结果一致.并发可以在多核操作系统上显著的提高程序运行速度 ...
- Java高并发编程基础三大利器之CountDownLatch
引言 上一篇文章我们介绍了AQS的信号量Semaphore<Java高并发编程基础三大利器之Semaphore>,接下来应该轮到CountDownLatch了. 什么是CountDownL ...
- Java并发编程--基础进阶高级(完结)
Java并发编程--基础进阶高级完整笔记. 这都不知道是第几次刷狂神的JUC并发编程了,从第一次的迷茫到现在比较清晰,算是个大进步了,之前JUC笔记不见了,重新做一套笔记. 参考链接:https:// ...
随机推荐
- Kali 无法正常上网问题
有时候我们会突然发现我们的kali不能够正常上网,在终端使用ping 命令对其进行检查,显示网络不可达, 然后使用ifconfig,可以看到没有正在工作的网卡,只有localhost 接着使用ifco ...
- [二]Java虚拟机 jvm内存结构 运行时数据内存 class文件与jvm内存结构的映射 jvm数据类型 虚拟机栈 方法区 堆 含义
前言简介 class文件是源代码经过编译后的一种平台中立的格式 里面包含了虚拟机运行所需要的所有信息,相当于 JVM的机器语言 JVM全称是Java Virtual Machine ,既然是虚拟机, ...
- 痞子衡嵌入式:飞思卡尔Kinetis系列MCU启动那些事(3)- KBOOT配置(FOPT/BOOT Pin/BCA)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是飞思卡尔Kinetis系列MCU的KBOOT配置. KBOOT是支持配置功能的,配置功能可分为两方面:一.芯片系统的启动配置:二.KBO ...
- 痞子衡嵌入式:ARM Cortex-M文件那些事(4)- 可重定向文件(.o/.a)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是嵌入式开发里的relocatable文件(object, library). 前三节课里,痞子衡都是在给大家介绍嵌入式开发中的input文 ...
- MariaDB官方手册翻译
MariaDB官方手册 翻译:create database语句(已提交到MariaDB官方手册) 翻译:rename table语句(已提交到MariaDB官方手册) 翻译:alter table语 ...
- Captcha服务(后续2)— 改造Captcha服务之Asp.Net Core项目中如何集成TypeScript
环境准备 .Net Core 版本:下载安装.Net Core SDK,安装完成之后查看sdk版本 ,查看命令dotnet --version,我的版本是2.2.101 IDE: Visual Stu ...
- winform中获取指定文件夹下的所有图片
方法一: C#的IO自带了一个方法DirectoryInfo dir = new DirectoryInfo("文件夹名称");dir.getFiles();//这个方法返回值就是 ...
- 前端面试:谈谈 JS 垃圾回收机制
摘要: 不是每个人都回答的出来... 最近看到一些面试的回顾,不少有被面试官问到谈谈JS 垃圾回收机制,说实话,面试官会问这个问题,说明他最近看到一些关于 JS 垃圾回收机制的相关的文章,为了 B 格 ...
- 如何保证MongoDB的安全性?
上周写了个简短的新闻<MongoDB裸奔,2亿国人求职简历泄漏!>: 根据安全站点HackenProof的报告,由于MongoDB数据库没有采取任何安全保护措施,导致共计202,730,4 ...
- Sublime 无法安装插件的解决办法
1,打开命令面板 Ctrl + Shift + P 输入:pi 回车 按回车后,出现异常如下图: 解决办法: 1,点击Preferences----Brows Packages ---会到安装目录 ...