VGG
2019-04-08 13:30:58
模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。
目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层)。大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等,这里重点介绍VGG。
二、VGG网络的特点
- 将网络的深度加深到了19层,可以说证明了Depth在深度学习领域的核心作用,为之后的ResNet打下了伏笔;
- 使用了更小的3 * 3卷积核,和更深的网络。两个3 * 3卷积核的堆叠相对于5 * 5卷积核的视野,三个3 * 3卷积核的堆叠相当于7 * 7卷积核的视野。这样一方面可以有更少的参数,另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力;
对于输入通道为cin,输出通道为cout的卷积层来说,7 * 7的卷积核参数量是:7 * 7 * cin * cout = 49 * cin * cout;
对于输入通道为cin,输出通道为cout的卷积层来说,3 * 3的卷积核达到相同的接受域参数量是:3 * 3 * 3 * cin * cout = 27 * cin * cout;
显然小卷积核的参数量要大大少于大卷积核的参数量,同时由于卷积层的最后会引入Relu进行激活,这样也增加了更多的非线性变换。
- 使用了1 * 1卷积,作者首先认为1x1卷积可以增加决策函数(decision function,这里的决策函数就是softmax)的非线性能力,非线性是由激活函数ReLU决定的,本身1x1卷积则是线性映射,即将输入的feature map映射到同样维度 的feature map;
- 层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
- VGG网络模型泛化能力强,在做年龄估计时候,采用VGG误差比GoogLeNet还要好;
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
三、VGG网络复杂度分析


在内存使用方面最初的卷积层使用的内存最多;
在参数使用方面最后的卷积层参数数量最大;
四、模型评估方法
- 预初始化权重
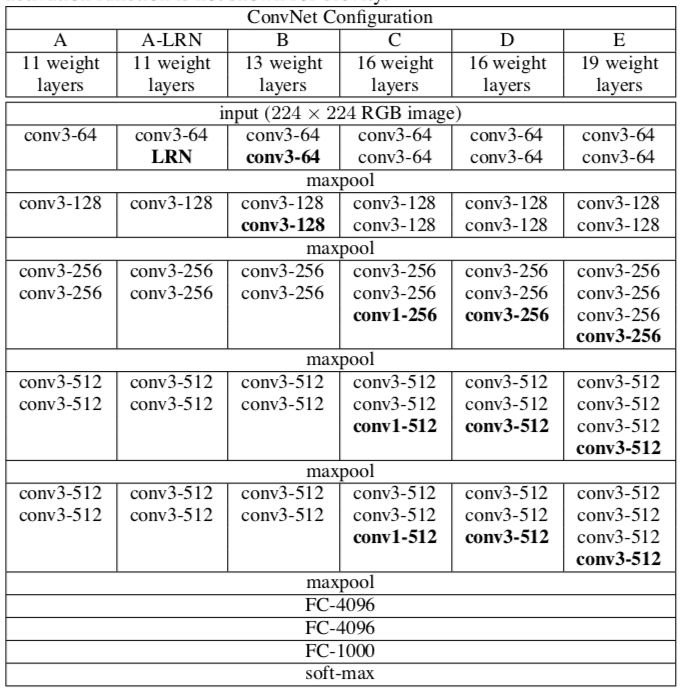
对于深度网络来说,网络权值的初始化十分重要。为此,论文中首先训练一个浅层的网络结构A(网络结构见上图),训练这个浅层的网络时,随机初始化它的权重就足够得到比较好的结果。然后,当训练深层的网络时,前四层卷积层和最后的三个全连接层使用的是学习好的A网络的权重来进行初始化,而其余层则随机初始化。这也就是上一点提到的某些层的预初始化。(随机初始化权重时,使用的是0均值,方差0.01的正态分布;偏置则都初始化为0)。
- 训练图像尺寸选择
S是训练图像的最小边,训练尺度。
Q是测试图像的最小边,测试尺度。
对原始图片进行等比例缩放,使得S大于224,然后在图片上随机提取224x224窗口,进行训练。
单一尺度训练:固定 S 的大小,对应了单一尺度的训练,训练多个分类器。训练S=256和S=384两个分类器,其中S=384的分类器用S=256的权重进行初始化;
多尺度(Multi-scale)训练(尺度抖动):直接训练一个分类器,每次数据输入的时候,每张图片被重新缩放,缩放的短边S随机从[256,512]中选择一个,也可以认为通过尺度抖动(scale jittering)进行训练集增强。图像中的目标可能具有不同的大小,所以训练时认为这是有用的。
- 模型评估
1. 单一尺度评估(single scale)
即测试图像大小Q固定,若S固定,则Q=S;若S抖动,则Q=0.5(Smin+Smax)
作者将深层次网络B与与具有5×5卷积层的浅层网络进行了比较,浅层网络可以通过用单个5×5卷积层替换B中每对3×3卷积层得到。测量的浅层网络性能比网络B差,这证实了具有小滤波器的深层网络优于具有较大滤波器的浅层网络。
训练时的尺度抖动(S∈[256;512])得到了与固定最小边(S=256或S=384)的图像训练相比更好的结果,即使在测试时使用单尺度。这证实了通过尺度抖动进行的训练集增强确实有助于捕获多尺度图像统计。
2. 多尺度评估(multi-scale)
即评估图像大小Q不固定,Q = {S_{min}, 0.5(S_{min} + S_{max}), S_{max}
作者通过试验发现当使用固定值S训练时,Q的范围在[S−32,S,S+32]之间时,测试的结果与训练结果最接近,否则可能由于训练和测试尺度之间的巨大差异导致性能下降。
实验结果表明测试时的尺度抖动与在单一尺度上相同模型的评估相比性能更优,并且尺度抖动优于使用固定最小边S的训练。
3. 多裁剪评估(multi-crop)
Dense(密集评估),即指全连接层替换为卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层),最后得出一个预测的score map,再对结果求平均。
multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均。
多剪裁表现要略好于密集评估,并且这两种方法确实是互补的,因为它们的结合优于它们中的每一种。
多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。
由于全卷积网络被应用在整个图像上,所以不需要在测试时对采样多个裁剪图像,因为它需要网络重新计算每个裁剪图像,这样效率较低。使用大量的裁剪图像可以提高准确度,因为与全卷积网络相比,它使输入图像的采样更精细。
VGG的更多相关文章
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- 第五弹:VGG
接下来讲一个目前经常被用到的模型,来自牛津大学的VGG,该网络目前还有很多改进版本,这里只讲一下最初的模型,分别从论文解析和模型理解两部分组成. 一.论文解析 一:摘要 -- 从Alex-net发展而 ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络Vgg
上周我们讲了经典CNN网络AlexNet对图像分类的效果,2014年,在AlexNet出来的两年后,牛津大学提出了Vgg网络,并在ILSVRC 2014中的classification项目的比赛中取得 ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- VGG网路结构
VGG网络的基本结构 如图所示,从A到E网络的深度是逐渐增加的,在A中有11个权重层(8个卷积层,3个全连接层),在E中有19个权重层(16个卷积层,3个全连接层),卷积层的宽度是十分小的,开始时在第 ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 卷积神经网络之VGG
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比 ...
- VGG网络结构
这个结构其实不难,但是它里面训练的一些东西我还没有搞清楚,打算把昨天写的代码传上来,方便日后来看,发现了一个很有意思的库叫TF-slim打算哪天看看有没有好用的东西 from datetime imp ...
随机推荐
- jsp四大作用域
- java中的类型转换
java中的类型转换分为两种 自动类型转换 要实现数据的自动类型转换必须同时满足下面两个条件 两种数据类型彼此兼容 目标类型的取值范围大于原类型范围 强制类型转换 当两种数据类型彼此不兼容,或者说目标 ...
- 在Ubuntu中,vi命令编辑异常
在Ubuntu中,进入vi命令的编辑模式,发现按方向键不能移动光标,而是会输出ABCD,以及退格键也不能正常删除字符.这是由于Ubuntu预装的是vim-tiny,而我们需要使用的是vim-full, ...
- 如何在Jenkins上配置一个可以从其它Job取回Artifact的Job
今天因为工作上的需求,需要在Jenskin上配置一个job, 它应该可以从其它所选择的Job中取回Artifact. 首先,在"构建"步骤中添加 "Copy Artifa ...
- spring boot常见问题
1.什么是springboot 用来简化spring应用的初始搭建以及开发过程 使用特定的方式来进行配置(properties或yml文件) 创建独立的spring引用程序 main方法运行 嵌入的T ...
- 2018-2019-2 20165316 『网络对抗技术』Exp3:免杀原理与实践
2018-2019-2 20165316 『网络对抗技术』Exp3:免杀原理与实践 一 免杀原理与实践说明 (一).实验说明 任务一:正确使用msf编码器,msfvenom生成如jar之类的其他文件, ...
- U盘启动安装Centos 7
,1.先下载CentOS iso文件,http://centos.ustc.edu.cn/centos/7.6.1810/isos/x86_64/,注意大小是4G左右,之前不知道从哪里下载的iso文件 ...
- flutter 读取sdcard权限问题相关
https://stackoverflow.com/questions/46698751/permission-denied-at-externalstoragedirectory-access-vi ...
- 【题解】Luogu P4436 [HNOI/AHOI2018]游戏
原题传送门 \(n^2\)过百万在HNOI/AHOI2018中真的成功了qwqwq 先将没门分格的地方连起来,枚举每一个块,看向左向右最多能走多远,最坏复杂度\(O(n^2)\),但出题人竟然没卡(建 ...
- 最长(大)回文串的查找(字符串中找出最长的回文串)PHP实现
首先还是先解释一下什么是回文串:就是从左到右或者从右到左读,都是同样的字符串.比如:上海自来水来自海上,bob等等. 那么什么又是找出最长回文串呢? 例如:字符串abcdefedcfggggggfc, ...