PPIO 是为开发者打造的去中心化存储与分发平台,让数据存储更便宜、更高速、更隐私。官方网站是
pp.io。PPIO 不仅仅是个存储平台,也是一个分发平台。之前我们写了许多文章介绍 PPIO 的存储技术,这篇文章将重点介绍 PPIO 的分发技术。
什么是数据分发
分发指的是在保证传递体验的同时将同一份数据快速传递给很多人。这些人分布在一定区域很多地方 (可能是一个国家),而且要保证数据传输的体验。常用的分发场景有:静态网页、大文件下载、大图片查看、流媒体点播、流媒体直播等。还有一些商业场景,如多路视频通话、视频会议等,其本质也是一种双向的分发。
数据分发的关键技术和场景应用
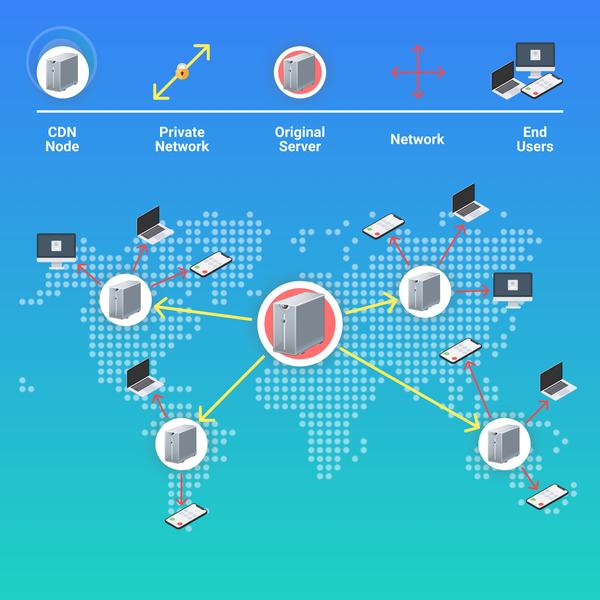
传统意义上的分发叫做 CDN,Content Delivery Network (内容分发网络),是一种构建在网络之上的内容分发网络,他的技术基本原理是把数据从源站推送到离用户最近的服务器上,然后用户直接从离自己最近的服务器获取数据,从而获得最好的用户体验。依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN 的关键技术主要有内容存储和分发技术。
分发是 P2P 技术的最古老的应用。P2P 网络从最早的的Napster 到后来的 Edonkey,BitTorrent 等,其应用场景本身都是把同一个内容,传递给更多的人,因为越多的人使用同一个内容,就意味着上传的节点越多,速度也就能越快,这本身就是分发的场景。
虽然同样是分发技术,P2P 和 CDN 的实现方式却不同。CDN 中每个分发的节点都是服务器,CDN 网络最终形成的是树状结构,一级一级的分发数据。而 P2P 网络则不同,P2P 中的每个客户端都具有上传能力,当客户端在下载数据的同时其实也上传数据给别的客户端。如果每个客户端都按照这个逻辑来,就形成了一个人人为我,我为人人的生态系统。
P2P 是多点下载,能更充分的使用自身网络,下载速度更快。特别是对于服务器(也包括 CDN 节点)距离客户端比较远的时候,这里说的是网络距离。
P2P 的多点下载模式下,单节点的下载读取抖动不会引起整体下载速度的波动
节约资源发布者带宽
P2P 实现比较复杂,CDN 简单。P2P 的服务在面对业务变化的时候,没有 CDN 快。
P2P 在启动的时候,有冷启动问题需要解决,要找到优质的其他节点需要些时间;所有在要求快速启动的业务上,P2P 不如 CDN 便利。
对运营商来说,P2P 的可控性不如 CDN,运营商会研究如何限制 P2P,降低了 P2P 的用户体验。
P2P 和 CDN 并不矛盾,P2SP 技术就是 P2P 和 CDN 技术的结合,也就是对客户端来说,既可以从 CDN 节点上下载,也可以从 P2P 网络中下载数据。使用 P2SP 构建的服务,也被称为 PCDN 服务。
分发应用是个重流媒体应用,视频点播,如 YouTube, Netflix,还有视频直播,如 Hulu 等,以及短视频,如Tiktok 等,都是分发类的应用场景。据2018年10月的报告,视频应用占互联网流量下载量的58%左右。所以,PPIO 在做分发技术时候,会花大量的精力把视频类的服务质量 QoS 做好。
存储和分发的实质都是数据的读取和使用,两者是不可能分割的。当一个数据存储在 PPIO 网络中,如果只有一个人会读取并使用,就是存储;如何有很多人读取或者使用,就是分发。只是存储场景和分发场景,设计有些不同,服务质量的要求也不一样。
PPIO 为分发场景进行的技术设计
PPIO 的核心团队做过 PPTV,这是曾经最大的 P2SP 华语视频平台,用户数做到了4.5亿的规模。近十年的 P2P 视频产品经验让我们团队积累了丰富的 P2P 和分发类项目的技术、产品和运营实践。我们非常了解分发场景对技术的多样化甚至刁钻的需求。这些经验让我们可以为分发类产品做出符合实际需要的技术架构。以下是 PPIO 为分发场景所做的技术设计。
PPIO 支持重叠网络 (Overlay 网络),每个存储节点 (Storage Node/Miner) 都会将与自己物理连接较快的存储节点作为自己的邻居,在数据传递和信息交互过程,充分发挥临近节点的优势,使得网络效率大大提高。
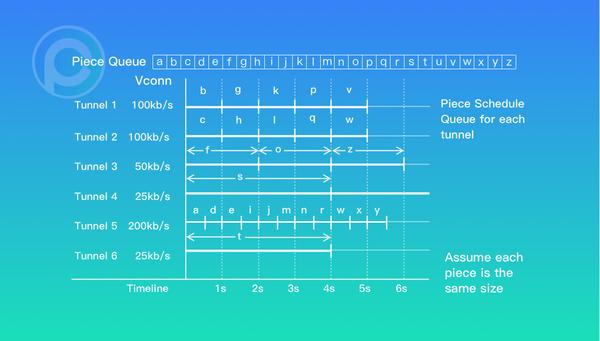
前面提到,流媒体是分发场景的最主要应用,对流媒体的支持以及做到足够好的服务质量 (QoS) 非常重要。PPIO 实现了针对流媒体的由数据来驱动的特别下载算法,从而保证实时流媒体的流畅播放。
P2P 会产生大量的网络间的跨 ISP 流量。一般来说,网络运营商 ISP 的网络内的流量是没有额外费用的,但是,运营商之间传输所产生的通讯会按照流量来计费。有没有什么办法能够做到既保留 P2P 技术的优势,又能做到降低跨 ISP 流量呢?这就是 P4P 技术。
P4P 全称 Proactive Network Provider Participation for P2P,在加强相同服务供应商 (ISP) 内网络流量的同时,降低了骨干网络传输压力和运营成本,从而也提高了 P2P 文件的传输性能。与 P2P 随机挑选节点的方式不同,P4P 模式可以协调网络拓扑数据,有效选择节点,从而提高网络路由效率。
PPIO 团队之前在做 PPTV 的时候有丰富地和运营商打交道的经历,在降低运营商的跨 ISP 流量有独特的方法。而在 P4P 技术出现之前,运营商都在想办法限制使用 P2P 的技术。
PPIO 支持 P2P-CDN。在 P2P-CDN 里面,热门内容的自适应调度是非常重要的,也是提高服务质量 (QoS) 的重要手段。热门内容的自适应调度就是当一个文件在网络中变得受欢迎之后,系统会自动触发调度机制,让更多的存储节点存储这个文件。这样的设计既能提高用户体验,也能提高更多存储节点的收益。反之,当很受欢迎的文件失去热度之后,系统则会自适应地减少存储此文件的存储节点的数量。这样就形成一种动态的平衡。PPIO 在热门内容调度算法上下了很大的功夫。
除了热门内容的自适应调度之外,PPIO 还提供了一套人为预热的机制,那么人为预热机制适用于什么场景呢?
比如说大家在看一部电视剧,前面一集看的人已经很多了,那么大概率地预测,下一集看的人也会很多。所以发布方在更新新的一集的时候,就可以提前推送新的一集的资源到更多矿工那里。这样当大家观看下一级电视剧的时候,已经有足够多的存储节点在做种了。这样在内容发布前就能充分利用 P2P 网络的优势,大大提升观看体验。类似的场景还有很多,只要人为可预知的热门内容都可以预热来提升冷启动过程中的体验。
内容发布者可以支付费用来指定需要预热的内容,并且可以指定执行预热的区域、ISP、时间段。根据区域、ISP 和时段的不同,存储的价格也会有不同。PPIO 中预热的实现是和去中心化存储的原理基本一致的,因为矿工不知道这个内容是不是真的很热,所以需要收取费用来对冲风险。但是预热和存储不同的是,预热采用的是全副本,而存储主要采用的纠删码,后面我会解释为什么会有所不同。
PPIO 不仅仅考虑了流媒体点播的下载,而且还考虑实时流媒体直播。直播在本质上就是一堆连续的小文件的分发,只是这些小文件他们的生命周期比较短,一段时间过后就没有用了,但同时也要求这些小文件的分发效率要非常高,要非常快速地分发到尽可能多的节点上。直播的整体架构和 PPIO 的流媒体体系是一致的,只是切分文件的方式,下载算法有所不同。
直播分为两类,一类是高延时直播,主要用于赛事,新闻等,这类直播的特点是一个直播频道,可能观看的用户数很多很多,但是大家对节目的时延不是那么敏感。还有一类是低延时直播,主要用于主播,秀场等模式,这种直播的特点是,由于涉及到和主播之间的互动,这类对延时的要求非常低,一般在 5s 之内,也就是当动作发生到看到画面最多只有 5s 的时间,但是用户规模一般不大。
PPIO 面对这两种直播场景,使用一推二拉三补偿的方案,做了一致性兼容,只是参数的不同,就能很好地支持两种模式。PPIO 的创始团队之前是做 P2P 直播起家的,做过全世界最大的 P2P 直播平台,PPTV,在直播领域的积累也是非常丰富的。
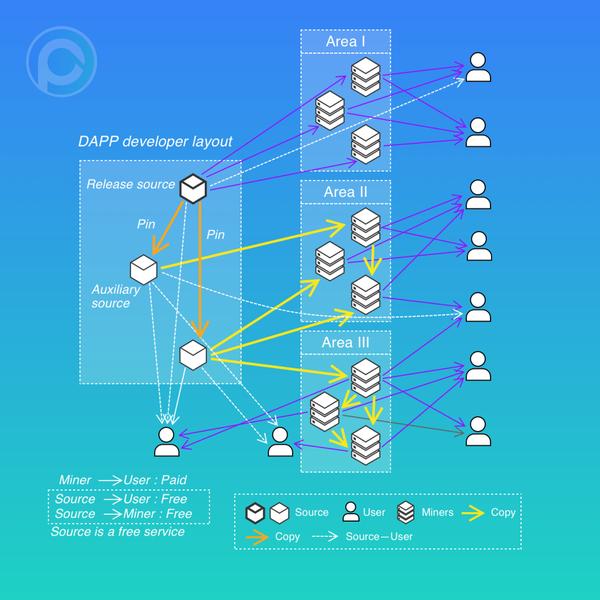
PCDN 即 CDN acceleration with P2P,是利用 P2P 技术和大量租户节点的带宽和磁盘资源来做 CDN 分发加速。PPIO 的设计是支持 PCDN 的,并且提供了 DApp 开发接口,开发者将很容易使用 PCDN 接口为自己的内容服务提供加速。
应用中的存储内容会首先在发布源节点进行发布,在源节点不下线的前提下,能够持续提供下载服务。然而当从同一个源节点下载的用户数增加后,该节点的带宽将被消耗殆尽,而每个用户的下载速度也会降低。通过 PCDN,网络中的大量租户节点开始保存和提供同样内容的下载。用户因此可以从多个节点下载内容,用户体验大幅提高。
充分利用3.2.4中热门内容按照预测调度的机制。PPIO 本身有根据热度来预测调度的功能。当发现一个热度比较好的内容时候,有其他租户也主动拉过来提供服务,从而增加了网络的副本数,而副本数越多,最终用户 P2P 下载的效果也就越好。
源节点发布内容的时候,可以指定 PCDN 定向缓存副本数。DApp 开发者可以根据自身需求,通过 PCDN API 接口,强制对一个内容设置缓存,可以在设定哪个网络区域,及地理区域(国家,ISP,州,市 四元组)的缓存数量。PPIO 会在这些定向区域的范围内寻找租户节点,以存储数据并提供下载服务。因为这是通过 API 指定的租户,所以源节点在这种情况下要支付给这部分租户相应的存储时空费用,调度费和时空证明费。上图中展示了这种情况下网络中 PCDN 驱动的数据流动。
PPIO 针对分发和存储的设计有哪些不同
PPIO 的定位是做存储与分发,那么存储和做分发在技术上还有什么不同呢?主要有以下几点。
分发和存储的最终目的是不同的。分发讲究的是如何快地获取内容。一般的分发场景中,源节点是在的,在所以不用担心数据会丢失,即使不小心被存储节点搞丢了,也能从源节点找到。所以在分发场景中我们选择采用全副本的算法。
而存储则不同,存储首先要保证不能丢数据, 提高内容不丢失率。如果采用全副本算法的方式,不知道要存多少副本才能做到11个9的不丢失率。而在适用纠删码技术候,做到11个9的不丢失率,需要的冗余空间将会少很多,这是提高内容不丢失率的最有用方案。
简单地来说,分发追求高速,所以用全副本方案为主;而存储追求极高的内容不丢失率,所以适用纠删码技术为主导。
分发和存储还有一个很大的区别。分发往往有很强的头部效应而存储没有。
分发的头部效应,也叫二八原则,就是20%的内容拥有80%的流量。而深入研究可能会发现,头部的20%的内容里面,也适用二八原则。所以在分发中,我们通常把内容分为头部内容,中部内容和尾部内容:头部的流量很集中,中部的流量较少,尾部的流量非常零散。在分发的场景中,从成本的角度考虑。头部和中头部内容适合使用内存的缓存,中尾部内容适合使用 SSD 等高速存储介质,而尾部内容处于成本角度考虑,则更适合机械硬盘。
存储没有头部效应,都是尾部内容,因为很少有人拥有相同的内容。存储也分为热存储、温存储和冷存储,热存储指的是数据在写入之后,经常会被读取;温存储指得是数据在写入之后,很少被读取,也可能永远不被去读,如私人网盘的老数据;冷存储指的是写入后,大概率是不会使用,即使使用也不会要求那么及时,如监控数据。
在 PPIO 的网络中,热存储主要使用全副本和纠删码并存方案,全副本保证适当地高速传输,纠删码能将数据的丢失率降到很低,同时推荐承载热存储的存储节点使用 SSD 等高速硬盘。而温存储和冷存储使用纯纠删码方案,因为读取的次数不多,推荐使用机械硬盘,这样能将成本降到最低。
所以对于存储节点来说,如果要获得最大的收益,其机器配置的参数也要与其提供的服务相搭配。
PPIO 更重视分发场景
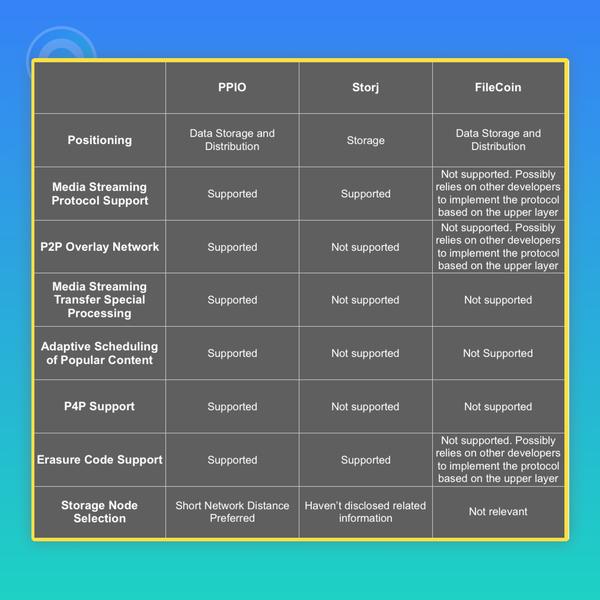
PPIO 项目相当于其他去中心化存储区块链项目,如Filecoin 和 Storj,是更重视分发场景的,其他项目都把重心放在了存储场景上。这里有个简易地对比表格分析三个存储链,并给出对比信息。
综上所诉,这些就是 PPIO 在数据分发领域的优势。如果你想了解更多,欢迎加入我们的开发者社区共同讨论!
- [更新]跨平台物联网通讯框架 ServerSuperIO v1.2(SSIO),增加数据分发控制模式
1.[开源]C#跨平台物联网通讯框架ServerSuperIO(SSIO) 2.应用SuperIO(SIO)和开源跨平台物联网框架ServerSuperIO(SSIO)构建系统的整体方案 3.C#工业 ...
- MongoDB 数据分发
在MongoDB(版本 3.2.9)中,数据的分发是指将collection的数据拆分成块(chunk),分布到不同的分片(shard)上,数据分发主要有2种方式:基于数据块(chunk)数量的均衡分 ...
- streamdataio 实时数据分发平台
streamdataio 是一个实时的数据分发平台(当然是收费的,但是设计部分可以借鉴),我们可以通过这个平台 方便的拉取rest api 数据,或者发布数据到后端,streamdataio 可以帮助 ...
- MongoDB 分片键分类与数据分发
In sharded clusters, if you do not use the _id field as the shard key, then your application must en ...
- 深度探索区块链/基于Gossip的P2P数据分发(4)
一.概述 背书节点模拟执行签名的结果会经过排序服务(Ording service)广播给所有的节点. 它提供的是一种原子广播服务(Atomic Broadcast),即在逻辑上所有节点接收到的消息顺序 ...
- 构建数据湖上低延迟数据 Pipeline 的实践
T 摘要 · 云原生与数据湖是当今大数据领域最热的 2 个话题,本文着重从为什么传统数仓 无法满足业务需求? 为何需要建设数据湖?数据湖整体技术架构.Apache Hudi 存储模式与视图.如何解决冷 ...
- Android开发:向下一个activity传递数据,返回数据给上一个activity
1.向下一个activity传递数据 activity1 Button button=(Button) findViewById(R.id.button1); button.setOnClickLis ...
- EasyUI Form提交后json数据IE上需要下载(转)
EasyUI Form提交后json数据IE上需要下载(转) 在使用EasyUI的form中的submit方法时,返回json在IE中变成提示下载的问题,代码如下: $('#fileForm'). ...
- hive(在大数据集合上的类SQL查询和表)学习
1.jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&use ...
随机推荐
- Django项目的创建的基本流程---基本配置
一.项目分析: 二.需求分析 三.Git管理代码: 1.创建仓库 2.克隆仓库 3.设置虚拟环境 4.复制前端font代码 在font中打开终端,运行live-server 5.测试前端代码是否可以运 ...
- qt 利用 HTML 生成PDF文档,不能显示jpg图片
利用 QPrinter 和html 生成 pdf文档 其中用html语句有显示图片的语句 但只能显示png格式的图片,不能显示jpg格式图片. 经过排查:语法,文件路径等都正确,最终在stack ov ...
- wxPython制作跑monkey工具(python3)
一. wxPython制作跑monkey工具python文件源代码内容Run Monkey.py如下: #!/usr/bin/env python import wx import os import ...
- nginx配置https转发http
生成ssl证书: 1.首先要生成服务器端的私钥,运行时会提示输入密码,此密码用于加密key文件: openssl genrsa -des3 -out server.key 1024 2.去除key文件 ...
- MVCC(Multi-version Cocurrent Control)多版本并发控制协议
MVCC相比2PC是一种更简单有效的分布式事务解决方案. 假设一种场景,一个分布式事务在A,B两个节点更新数据,要么同时成功,要么同时失败. MVCC 中,为每个事务分配一个递增的事务编号,有一个中心 ...
- 微信小程序测试策略
一.测试前准备(环境搭建) 1.前端页面 微信Web开发者工具安装.授权测试用的微信号可预览和调试小程序... 可参考此文: 微信Web开发者工具-下载.安装和使用图解 2.管理后台 配置内网测试服务 ...
- SQL的修炼
查询所有区有多少人,从而得知一个区有多少设备. ###############################################select o2.ORG_ENDDATE as name ...
- Jquery图集
- ms16-032漏洞复现过程
这章节写的是ms16-032漏洞,这个漏洞是16年发布的,版本对象是03.08和12.文章即自己的笔记嘛,既然学了就写下来.在写完这个漏洞后明天就该认真刷题针对16号的比赛了.Over,让我们开始吧! ...
- Java中如何拆分字符串为字符数组
题目:输入一串字符,由(){}[]组成,判断是否所有的括号都是闭括号,是的返回TRUE,不是返回FALSE. /*输入字符串,拆解为字符数组 * 用函数s.charAt(i)来完成 * * */imp ...