Zookeeper + Hadoop2.6 集群HA + spark1.6完整搭建与所有参数解析
废话就不多说了,直接开始啦~
安装环境变量:
使用linx下的解压软件,解压找到里面的install 或者 ls 运行这个进行安装
yum install gcc
yum install gcc-c++
安装make,这个是自动编译源码的工具
yum install make
yum install autoconfautomake libtool cmake
封装了底层的终端功能
yum install ncurses-devel
OpenSSL是一个软件包,用于支持SSL传输协议的软件包
yum install openssl-devel
git就不用多说了
yum install git git-svn git-email git-gui gitk
安装protoc(需用root用户), 作用是把某种数据结构的信息,以某种格式保存起来。主要用于数据存储、传输协议格式等
1 tar -xvf protobuf-2.5.0.tar.bz2
2 cd protobuf-2.5.0
3 ./configure --prefix=/opt/protoc/
4 make && make install
安装wget (以后备用~)
sudo yum -y install wget
二、增加用户组
groupadd hadoop 添加一个组
useradd hadoop -g hadoop 添加用户
三、编译hadoop
mvn clean package -Pdist,native -DskipTests -Dtar
编译完的hadoop在 /home/hadoop/ocdc/hadoop-2.6.0-src/hadoop-dist/target 路径下
四、各节点配置hosts文件 vi/etc/hosts
10.1.245.244 master
10.1.245.243 slave1
10.1.245.242 slave2
命令行输入 hostname master
ssh到其他主机 相应输入 hostName xxxx
五、各节点免密码登录:
各节点 免密码登录
ssh-keygen -t rsa
cd /root/.ssh/
ssh-copy-id master
将生成的公钥id_rsa.pub 内容追加到authorized_keys(执行命令:cat id_rsa.pub >> authorized_keys)
时间等效性同步
ssh master date; ssh slave1 date;ssh slave2 date;
六、hadoop路径下创建相应目录(namenode,datenode 等信息存放处)
Mkdir data
(在data路径下创建目录)
mkdir yarn
mkdir jn
mkdir current
(hadoop路径下)
mkdir name
(jn目录下)
mkdir streamcluster
七、Zookeeper集群配置:
解压zookeeper
Tar zxvf zookeeper-3.4.6.tar.gz
修改temp文件为可用
Cp zoo_sample.cfg zoo.cfg
修改zoo.cfg文件:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/ocdc/zookeeper-3.4.6/data
dataLogDir=/home/hadoop/ocdc/zookeeper-3.4.6/logs
# the port at which the clients will connect
clientPort=2183
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#写入节点ip与端口
server.1=master:2898:3898
server.2=slave1:2898:3898
server.3=slave2:2898:3898
在zookeeper目录下:
mkdir data
vi myid (写入id为1,)
拷贝zookeeper到各个目录下(将slave1中的myid改为2,slave2中的myid改为3....)
随后在 bin目录下 逐个启动zookeeper
./zkServer.sh start
./zkServer.sh status (查看状态)
八、hadoop相关配置文件及参数说明
core-site.xml
默认文件系统的名称,如果是HA模式,不加端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs:// streamcluster </value>
</property>
io.file.buffer.size都被用来设置缓存的大小,较大的缓存可以提供高效的数据传输,但太大也会造成更大的内存消耗和延迟
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置在/tmp/{$user}下面
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
集群的逻辑名,要注意的是,如果为HA模式,需要与core-site.xml中的fs.defaultFS名一致
<property>
<name>dfs.nameservices</name>
<value>streamcluster</value>
</property>
datanode的端口,运行tcp/ip服务器以支持块传输,默认为0.0.0.0:50010
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50012</value>
</property>
datanode的http服务器地址和端口
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50077</value>
</property>
datanode的rpc服务器的地址和端口, 提供进程间交互通信
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50022</value>
</property>
dfs.ha.namenodes.[nameservice ID]在名称服务中每一个nameNode的唯一标识符,streamcluster为之前配置的nameservice的名称,这里配置高可用,所以配置两个NN
<property>
<name>dfs.ha.namenodes.streamcluster</name>
<value>nn1,nn2</value>
</property>
由namenode存储元数据的目录地址
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/name</value>
<final>true</final>
</property>
由datanode存放数据块的目录列表
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data</value>
<final>true</final>
</property>
由写操作所需要创建的最小副本数目
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
如果是 true,则打开权限系统
<property>
<name>dfs.permission</name>
<value>true</value>
</property>
设置成true, 通过知道每个block所在磁盘,可以在调度cpu资源时让不同的cpu读不同的磁盘,避免查询内和查询间的IO竞争
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
是否在HDFS中开启权限检查。
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
HA模式下该参数为streamcluster中namenode1节点对外服务的RPC地址
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn1</name>
<value>master:8033</value>
</property>
HA模式下该参数为streamcluster中namenode1节点对外服务的RPC地址
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn2</name>
<value>slave1:8033</value>
</property>
HA模式下该参数为streamcluster中namenode1节点对外服务的HTTP地址
<property>
<name>dfs.namenode.http-address.streamcluster.nn1</name>
<value>master:50083</value>
</property>
HA模式下该参数为streamcluster中namenode1节点对外服务的HTTP地址
<property>
<name>dfs.namenode.http-address.streamcluster.nn2</name>
<value>slave1:50083</value>
</property>
设置的为journalNode的地址,Activity状态中的Namenode会将edits的Log写入JournalNode,而standby状态中的Namenode会读取这些edits log.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8489;slave1:8489;slave2:8489/streamcluster</value>
</property>
JournalNode 所在节点上的一个目录,用于存放 editlog 和其他状态信息。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data/jn</value>
</property>
journalNode RPC服务地址和端口
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8489</value>
</property>
journalNode HTTP服务地址和端口
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8484</value>
</property>
此参数为客户端与activity状态下的Namenode进行交互的java实现类,DFS客户端通过该类寻找当前activity的Namenode
<property>
<name>dfs.client.failover.proxy.provider.streamcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
使HA模式下不会同时出现两个master,不允许出现两个activity状态下的Namenode
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
SSH的超时时间设置,倘若超过此时间,则认为执行失败.
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
指定streamcluster的两个NameNode共享edits文件目录时,使用的JournalNode集群信息
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
每个datanode任一时刻可以打开的文件数量上限。
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
DataNode传送数据出入的最大线程数,等同于dfs.datanode.max.xcievers。
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
块的字节大小
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
一般原则是将其设置为集群大小的自然对数乘以20,即20logN, NameNode有一个工作线程池用来处理客户端的远程过程调用及集群守护进程的调用。处理程序数量越多意味着要更大的池来处理来自不同DataNode的并发心跳以及客户端并发的元数据操作。
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Resource Manager Configs -->
NodeManager的心跳间隔
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
是否启用RM HA,默认为false(不启用)。这里设置为启用。
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
是否启用自动故障转移。默认情况下,在启用HA时,启用自动故障转移。
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
启用内置的自动故障转移。默认情况下,在启用HA时,启用内置的自动故障转移。
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
集群的ID,确保ResourceManager不会为成为其他集群的Activity活跃状态。
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
HA下两个ResourceManager的逻辑名称
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
用于标识ResourceManager,这里要注意一点,HA备用的RM的服务器需要修改为rm2
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
启用重启ResourceManager的功能,默认为false
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
用于状态存储的类,可以设置为
org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore,基于Hadoop文件系统的实现,这里的设置是基于ZooKeeper的实现
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
存储RM状态的ZooKeeper Znode全路径。
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
被RM用于状态存储的ZooKeeper服务器的主机:端口号
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
Scheduler失联等待的时间
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
ResourceManager1的地址和端口
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master:23140</value>
</property>
ResourceManager1调度器地址:端口
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:23130</value>
</property>
ResourceManager 1对外web ui地址。可通过该地址在浏览器中查看集群各类信息。
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:23188</value>
</property>
NodeManager通过该地址向ResourceManager1汇报心跳,领取任务等的地址。
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:23125</value>
</property>
ResourceManager 1对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master:23142</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slave1:23140</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value> slave1:23130</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value> slave1:23188</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value> slave1:23125</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value> slave1:23141</value>
</property>
HA ResourceManager2相关参数同上 rm1
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value> slave1:23142</value>
</property>
<!-- Node Manager Configs -->
localizer IPC
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
http服务端口
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
通过该配置,用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的,可运行mapReduce程序
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
之前定义了为mapreduce_shuffle,那么相对应属性的类就定义为org.apache.hadoop.mapred.ShuffleHandle
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
NodeManager会通过参数yarn.nodemanager.local-dirs配置一系列目录(磁盘),用于存储Application中间结果(比如MapReduce中Map Task的中间输出结果)
<property>
<name>yarn.nodemanager.local-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/local</value>
</property>
同上NodeManager配置的日志文件
<property>
<name>yarn.nodemanager.log-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/log</value>
</property>
MapReduce JobHistory Server Web UI地址。
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:12345</value>
</property>
每个节点可用的最大内存,RM中的两个值不应该超过此值。此数值可以用于计算container最大数目,即:用此值除以RM中的最小容器内存。虚拟内存率,是占task所用内存的百分比,默认值为2.1倍;注意:第一个参数是不可修改的,一旦设置,整个运行过程中不可动态修改,且该值的默认大小是8G,即使计算机内存不足8G也会按着8G内存来使用。
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.4</value>
</property>
每个节点可用的内存,单位为MB
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
单个任务可申请的最大内存,默认为8192MB
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
启用的资源调度器主类。目前可用的有FIFO、Capacity Scheduler和Fair Scheduler。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
为applications配置相应的ClassPath
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
mapred-site.xml
<configuration>
配置引擎为yarn,如果要配置Tez则改为yarn-tez. 其中的奥妙在于使用了JDK6+的一个特性ServiceLoader类。其为JDK实现了一个依赖注入的机制。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
mapreduce.jobhistory.webapp.address和mapreduce.jobhistory.address参数配置的主机上对Hadoop历史作业情况经行查看。
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
mapreduce.jobhistory.webapp.address和mapreduce.jobhistory.address参数配置的主机上对Hadoop历史作业情况经行查看。
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
指定压缩类型,默认是RECORD类型,它会按单个的record压缩,如果指定为BLOCK类型,它将一组record压缩,压缩效果自然是BLOCK好。
<property>
<name>mapred.output.compression.type</name>
<value>BLOCK</value>
</property>
</configuration>
slaves
vi slaves
master1
slave1
slave2
随后将拷贝配置好的hadoop到各个服务器中
九、启动Hadoop各组件
在各节点启动jounalnode
./hadoop-daemon.sh start journalnode
首先在namenode1服务器上进行namenode格式化
./hadoop namenode -format
格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,之后通过下面命令,启动namenode进程在namenode2上执行
sbin/hadoop-daemon.sh start namenode
在namenode2上执行,完成主备节点同步信息
./hdfs namenode –bootstrapStandby
格式化ZK(在namenode1上执行即可, 这句命令必须手工打上,否则会报错)
./hdfs zkfc –formatZK
启动HDFS(在namenode1上执行)
./start-dfs.sh
启动YARN(在namenode1和namenode2上执行)
./start-yarn.sh
在namenode1上执行${HADOOP_HOME}/bin/yarn rmadmin -getServiceState rm1查看rm1和rm2分别为active和standby状态
我们在启动hadoop各个节点时,启动namenode和datanode,这个时候如果datanode的storageID不一样,那么会导致如下datanode注册不成功的信息:
这个时候,我们需要修改指定的datanode的current文件中的相应storageID的值,直接把它删除,这个时候,系统会动态新生成一个storageID,这样再次启动时就不会发生错误了。
查看端口是否占用
Netstat-tunlp |grep 22
查看所有端口
Netstat -anplut
十、spark搭建与参数解析
修改spark-env..sh 增加如下参数(路径根据服务器上的路径修改)
HADOOP_CONF_DIR=/home/hadoop/ocdc/hadoop-2.6.0/etc/hadoop/
HADOOP_HOME=/home/hadoop/ocdc/hadoop-2.6.0/
SPARK_HOME=/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/
该参数决定了yarn集群中,最多能够同时启动的EXECUTOR的实例个数。
SPARK_EXECUTOR_INSTANCES=3
设置每个EXECUTOR能够使用的CPU core的数量。
SPARK_EXECUTOR_CORES=7
该参数设置的是每个EXECUTOR分配的内存的数量
SPARK_EXECUTOR_MEMORY=11G
该参数设置的是DRIVER分配的内存的大小
SPARK_DRIVER_MEMORY=11G
Spark Application在Yarn中的名字
SPARK_YARN_APP_NAME="asiainfo.Spark-1.6.0"
指定在yarn中执行,提交方式为client
MASTER=yarn-cluster
修改spark-default.conf文件 (路径根据服务器上的路径修改)
如果没有适合当前本地性要求的任务可供运行,将跑得慢的任务在空闲计算资源上再度调度的行为,这个参数会引发一些tmp文件被删除的问题,一般设置为false
spark.speculation false
如果设置为true,前台用jdbc方式连接,显示的会是乱码
spark.sql.hive.convertMetastoreParquet false
应用程序上载到HDFS的复制份数
spark.yarn.submit.file.replication 3
Spark application master给YARN ResourceManager 发送心跳的时间间隔(ms)
spark.yarn.scheduler.heartbeat.interal-ms 5000
仅适用于HashShuffleMananger的实现,同样是为了解决生成过多文件的问题,采用的方式是在不同批次运行的Map任务之间重用Shuffle输出文件,也就是说合并的是不同批次的Map任务的输出数据,但是每个Map任务所需要的文件还是取决于Reduce分区的数量,因此,它并不减少同时打开的输出文件的数量,因此对内存使用量的减少并没有帮助。只是HashShuffleManager里的一个折中的解决方案。
spark.shuffle.consolidateFiles true
用来调整cache所占用的内存大小。默认为0.6。如果频繁发生Full GC,可以考虑降低这个比值,这样RDD Cache可用的内存空间减少(剩下的部分Cache数据就需要通过Disk Store写到磁盘上了),会带来一定的性能损失,但是腾出更多的内存空间用于执行任务,减少Full GC发生的次数,反而可能改善程序运行的整体性能。这要看你的具体业务逻辑,是cache的多还是计算的多。
spark.storage.memoryFraction 0.3
一个partition对应着一个task,如果数据量过大,可以调整次参数来减少每个task所需消耗的内存.
spark.sql.shuffle.partitions 800
Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短的查询,可能会增加开销,因为它必须先编译每一个查询
spark.sql.codegen true
我们都知道shuffle默认情况下的文件数据为map tasks * reduce tasks,通过设置其为true,可以使spark合并shuffle的中间文件为reduce的tasks数目。
spark.shuffle.consolidateFiles true
相关jar包的加载地址
spark.driver.extraClassPath /home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.1.30-bin.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib
/datanucleus-core-3.2.10.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/ojdbc14-10.2.0.3.jar
最终:
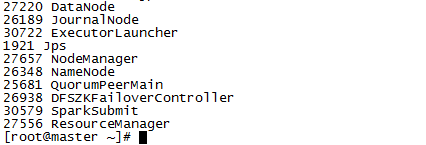
Hadoop监控页面(根据yarn-site.xml的参数yarn.resourcemanager.webapp.address.rm1中配置的端口决定的):
http://10.1.245.244: 23188
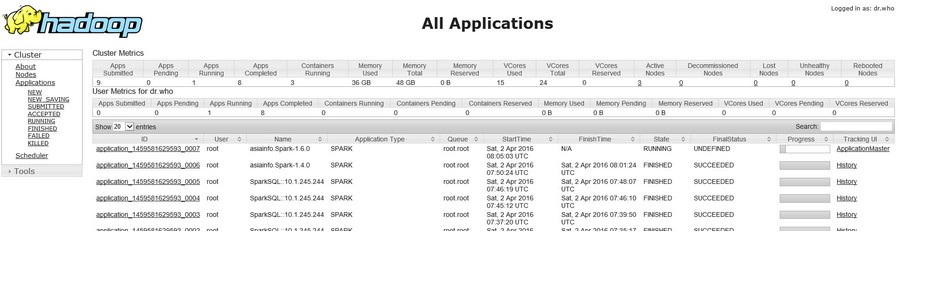
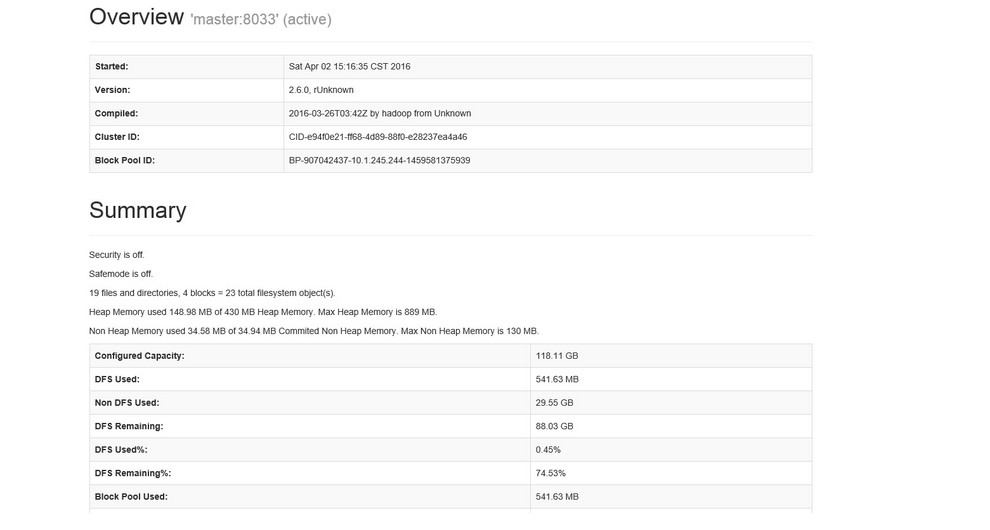
Hadoop namenode监控页面( 根据hdfs-site.xml中配置的参数 dfs.namenode.http-address.streamcluster.nn1中的端口决定):
http://10.1.245.244: 50083
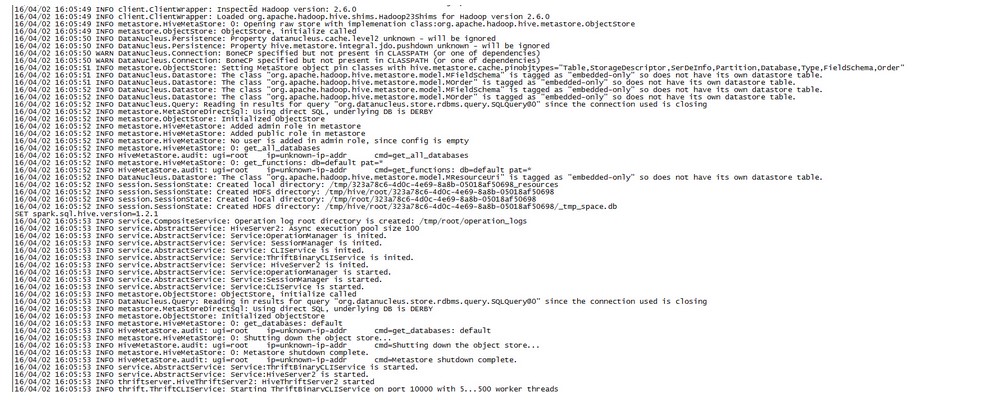
spark thriftserver注册启动:
Zookeeper + Hadoop2.6 集群HA + spark1.6完整搭建与所有参数解析的更多相关文章
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
- zookeeper高可用集群搭建
前提:已经在master01配置好hadoop:在各个slave节点配置好hadoop和zookeeper: (该文是将zookeeper配置在各slave节点上的,其实也可以配置在各master上, ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 分布式集群HA模式部署
一:HDFS系统架构 (一)利用secondary node备份实现数据可靠性 (二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止 二:HA架构---提高NameNode ...
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
- zookeeper部署及集群测试
zookeeper部署及集群测试 环境 三台测试机 操作系统: centos7 ; hostname: c1 ; ip: 192.168.1.80 操作系统: centos7 ; hostname: ...
- 备忘zookeeper(单机+伪集群+集群)
#下载: #单机模式 解压到合适目录. 进入zookeeper目录下的conf子目录, 复制zoo_sample.cfg-->zoo.cfg(如果没有data和logs就新建):tickTime ...
随机推荐
- leetcode 139. Word Break ----- java
Given a string s and a dictionary of words dict, determine if s can be segmented into a space-separa ...
- Ansible安装配置Nginx
一.思路 现在一台机器上编译安装好nginx.打包,然后在用ansible去下发 cd /etc/ansible 进入ansible配置文件目录 mkdir roles/{common,install ...
- 新浪代码部署手册 git管理工具
目前新浪云上的应用支持通过Git和SVN来部署代码. Git仓库地址 https://git.sinacloud.com/YOUR_APP_NAME SVN仓库地址 https://svn.sinac ...
- SQL书写规范及常用SQL语句
常用的查询语句 SELECT * FROM 表名 [WHERE 条件 或 GROUP BY 字段名 HAVING] ORDER BY 字段名 排序方式 LIMIT 初始值,数量; SELECT fna ...
- poj1417 带权并查集+0/1背包
题意:有一个岛上住着一些神和魔,并且已知神和魔的数量,现在已知神总是说真话,魔总是说假话,有 n 个询问,问某个神或魔(身份未知),问题是问某个是神还是魔,根据他们的回答,问是否能够确定哪些是神哪些是 ...
- springMvc源码学习之:利用springMVC随时随地获取HttpServletRequest等对象
一.准备工作: 在web.xml中添加 <listener> <listener-class> org.springframework.web.context.request. ...
- java.lang.OutOfMemoryError: unable to create new native thread如何解决
工作中碰到过这个问题好几次了,觉得有必要总结一下,所以有了这篇文章,这篇文章分为三个部分:认识问题.分析问题.解决问题. 一.认识问题: 首先我们通过下面这个 测试程序 来认识这个问题:运行的环境 ( ...
- liunx之:wps for liunx的安装经验
首先是下载正确的安装包 WPS For Linux : 社区下载:http://community.wps.cn/download/ 社区最新包下载:http://wps-community.org/ ...
- OSPF
Ospf OSPF(开放最短路径优先协议)是一种无类内部网关协议(IGP):是一种链路状态路由选择协议: 入门: 可以把整个网络(一个自治系统AS)看成一个王国,这个王国可以分成几个 区(area), ...
- Tutorial: Triplet Loss Layer Design for CNN
Tutorial: Triplet Loss Layer Design for CNN Xiao Wang 2016.05.02 Triplet Loss Layer could be a tri ...