Edit Distance编辑距离(NM tag)- sam/bam格式解读进阶
sam格式很精炼,几乎包含了比对的所有信息,我们平常用到的信息很少,但特殊情况下,我们会用到一些较为生僻的信息,关于这些信息sam官方文档的介绍比较精简,直接看估计很难看懂。
今天要介绍的是如何通过bam文件统计比对的indel和mismatch信息
首先要介绍一个非常重要的概念--编辑距离
定义:从字符串a变到字符串b,所需要的最少的操作步骤(插入,删除,更改)为两个字符串之间的编辑距离。
(2016年11月17日:增加,有点误导,如果一个插入有两个字符,那编辑距离变了几呢?1还是2?我又验证了一遍:确实是2)
这也是sam文档中对NM这个tag的定义。
编辑距离是对两个字符串相似度的度量(参见文章:Edit Distance)
举个栗子:两个字符串“eeba”和“abca”的编辑距离是多少?
根据定义,通过三个步骤:1.将e变为a 2.删除e 3.添加c,我们可以将“eeba”变为“abca”

所以,“eeba”和“abca”之间的编辑距离为3
回到序列比对的问题上
下面是常见的二代比对到ref的结果(bwa):
D00360:96:H2YLYBCXX:1:2110:18364:84053 353 seq1_len154_cov5 1 1 92S59M8I17M1D6M1D67M seq30532_len2134_cov76 1 0 AAAAAAAAAAAAAAAAAAAAAAAACCCTGTCTCTAATAAAATACAAACAATTAGCCGGGCATGGTGGCACGCGCCTTTAGTCCCAGCTACTAGGGAGGCTGAGGCAGGGGAATTGTTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCGGAGTTTTTTTCACTGCACTCCAGCCTGGTGACAAATCAAAAATCCATTTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAAAACAACAAA
DDDDDHIIIIIIII<EHHII?EHH0001111111<11<DEH1D1<FH1D<<<C<@GEHD</<11<101<1D<<C<E0D11<<1<D?1F1CC1DE110C0D1011100////0DD<1=@1=FGHCDHH<FG<D0<<<EF?CE<00<<0<D//0;<:D/////;///////;8F.;/.8.8......88.9........-8BBGADHIIHD?>D?HH<,>=HHDD,5CHDCDHD><,,,--8----8-8-- NM:i:25 MD:Z:16A21C16C0A3T15^A6^G1G0T0G3C2T0G1C41A4A2A3 AS:i:49 XS:i:42 SA:Z:seq13646_len513_cov63,125,-,103S125M21S,1,11; RG:Z:chr22
这是ref序列
>seq1_len154_cov5
GGGAGGCTGAGGCAGGAGAATTGTTTGAACCCGGGAGGCGGAGGTTGCAGTGAGCCAAGATTGCACTCCAGCCTGGATGACAAGAGTGAAACTCTGTCTCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
cigar字段包含了序列比对的简化信息,M(匹配比对,包含match和mismatch),=(纯match),X(纯mismatch),I(插入),D(删除),还有N、P和S、H。(注:目前只在blasr比对结果中见过=和X)
根据cigar字段可以统计indel信息,但是无法统计mismatch。
这个时候就可以用到NM tag了,mismatch = NM – I - D = 25 – 8 – 1 – 1 = 15
有兴趣的可以对着cigar数一遍,下面是我无聊数着的结果,也是15个
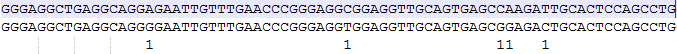

使用python的pysam模块可以很容易的提取出每个比对结果的NM信息
参见之前的帖子:pysam - 多种数据格式读写与处理模块(python)
再次验证一遍:证明NM=len(mismatch) + len(insertion) + len(deletion), 而不是 count(mismatch) + count(insertion) + count(deletion) (count的意思是三个碱基的insertion算一个)
>>> bam_file = pysam.AlignmentFile(infile, "rb")
>>> for line in bam_file:
... if 300 < line.query_alignment_length < 500:
... break
...
>>> line.query_alignment_length
321
>>> line.seq
'CTCTTCATCACGTCACTTGTCCATGTCAATGGCTACAGGTTGGAAGTTTGGCCGCGGAGGGTGGGCAGGCAAGAGAAAGAAATCAGATAGGGCAGATGGTAGGGTAAAAGGAGGGGGTTAAGTGCAAATTGTCTACTGTTTGCAAATGGGAAGCATGTGATTGTTAAAATTTATACGATAAACCTTCTCATCATGTTGAGTCTCATGCTTGCGCCAAGAAGATCGGGTTCGGCGGGTCAAGCTGATAAGCAACTTGGGCAGCAAAGTCGTTCAGTGATACAAAATCATGTGCAAAAATCACAAGCATTCTTATAAACACCA'
>>> line.cigarstring
'5148H3M1I2M1I4M2I3M3I3M1D2M1I4M3I1M1I4M1D10M1D5M4I4M3D1M3I18M1I1M1I1M1I4M4D2M1I2M2I4M2I4M1I4M5I4M1I9M1I14M3I1M1I2M2I7M2I7M3I2M1I5M2I1M1I2M1I1M1I4M5I3M1I2M3I1M1I4M4I3M4I2M2I1M3I19M3I10M2I4M1I11M1D27M2I6M25212H'
>>> line.reference_name
'Backbone_1'
>>> line.reference_start
7164
>>> line.reference_end
7413
>>> line.get_tag('NM')
100
取出了一条长度适中的比对结果,cigar字段比较全面。
取出了比对上的ref:
>>> ref = 'CTCTCTCACCACTCCTATTCAACACAGTGTTGGAAGTTCTGGACAGGGCAATCAGGCAAGAGAAAGAAATAAAGGGTATTCAATTAGGAAAAGAGGAAGTCAAATTGTCCCCGTTTGCAGATGACATGATTGTATATTTAGAAAACCCCACTGTTTCAGCCCCAAATCTCCTTAAGCTGATAAGCAACTTCAGCAAAGTCTCAGGATACAAAATCAATGTGCAAAAATCACAAGCATTCTTATACACCA'
先通过我自己写的cigar校正函数校正:
def formatSeqByCigar(seq, cigar):
'''
Input: query_alignment_sequence and cigar from sam file
Output: formatSeq
Purpose: make sure the pos is one to one correspondence(seq to ref)
'''
formatSeq = ''
pointer = 0; qstart = 0; qend = -1; origin_seq_len = 0
if cigar[0][0] == 4 or cigar[0][0] == 5:
qstart = cigar[0][1]
if cigar[-1][0] == 4 or cigar[-1][0] == 5:
qend = - cigar[-1][1] - 1 # fushu count
for pair in cigar:
operation = pair[0]
cigar_len = pair[1]
if operation == 0: # 0==M
formatSeq += seq[pointer:(pointer+cigar_len)]
pointer += cigar_len
origin_seq_len += cigar_len
elif operation == 1: # 1==I
pointer += cigar_len
origin_seq_len += cigar_len
elif operation == 2: # 2==D
formatSeq += 'D'*cigar_len
elif operation == 4 or operation == 5: # 5==H
origin_seq_len += cigar_len
continue
else:
print (cigar)
raise TypeError("There are cigar besides S/M/D/I/H\n")
return formatSeq, qstart, qend, origin_seq_len
然后分别计算deletion和mismatch:
>>> i = 0
>>> count = 0
>>> while i < len(ref):
if formatSeq[i] != ref[i]:
count += 1
i += 1 >>> count
17
>>> formatSeq.count('D')
11
可以看出deletion有11个,退出mismatch有6个。
随手一推insertion有83个。
而
>>> cigarstring = '5148H3M1I2M1I4M2I3M3I3M1D2M1I4M3I1M1I4M1D10M1D5M4I4M3D1M3I18M1I1M1I1M1I4M4D2M1I2M2I4M2I4M1I4M5I4M1I9M1I14M3I1M1I2M2I7M2I7M3I2M1I5M2I1M1I2M1I1M1I4M5I3M1I2M3I1M1I4M4I3M4I2M2I1M3I19M3I10M2I4M1I11M1D27M2I6M25212H'
>>> cigarstring.count('I')
41
>>> cigarstring.count('D')
6
用count计算显然不对。
验证成功
真切的明白了计算机有多么伟大,如果要是你肉眼去比对去数的话,我估计你会立马崩溃。
Edit Distance编辑距离(NM tag)- sam/bam格式解读进阶的更多相关文章
- mismatch位置(MD tag)- sam/bam格式解读进阶
这算是第二讲了,前面一讲是:Edit Distance编辑距离(NM tag)- sam/bam格式解读进阶 MD是mismatch位置的字符串的表示形式,貌似在call SNP和indel的时候会用 ...
- sam/bam格式
1)Sam (Sequence Alignment/Map) ------------------------------------------------- 1) SAM 文件产生背景 随着Ill ...
- [LeetCode] Edit Distance 编辑距离
Given two words word1 and word2, find the minimum number of steps required to convert word1 to word2 ...
- leetCode 72.Edit Distance (编辑距离) 解题思路和方法
Edit Distance Given two words word1 and word2, find the minimum number of steps required to convert ...
- [LeetCode] 72. Edit Distance 编辑距离
Given two words word1 and word2, find the minimum number of operations required to convert word1 to ...
- leetcode72. Edit Distance(编辑距离)
以下为个人翻译方便理解 编辑距离问题是一个经典的动态规划问题.首先定义dp[i][j表示word1[0..i-1]到word2[0..j-1]的最小操作数(即编辑距离). 状态转换方程有两种情况:边界 ...
- 【LeetCode每天一题】Edit Distance(编辑距离)
Given two words word1 and word2, find the minimum number of operations required to convert word1 to ...
- 【LeetCode】72. Edit Distance 编辑距离(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 递归 记忆化搜索 动态规划 日期 题目地址:http ...
- edit distance(编辑距离,两个字符串之间相似性的问题)
Given two words word1 and word2, find the minimum number of steps required to convert word1 to word2 ...
随机推荐
- JS实现base64编码与解码
var base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" ...
- 蚂蚁运输(ant)
蚂蚁运输(ant)Time Limit:5000ms Memory Limit:64MB[题目描述] LYK 在观察一些蚂蚁.蚂蚁想要积攒一些货物来过冬.积攒货物的方法是这样的.对于第i只蚂蚁, 它要 ...
- Struts2的处理结果(一)——处理结果的配置
Struts2的处理结果(一) --处理结果的配置 1.处理结果 在Action处理完用户请求之后,并不会直接生成响应,而是把一个字符串返回给Struts2框架,再由框架选择此字符串结果对应的物理视图 ...
- BZOJ 1050 旅行comf(枚举最小边-并查集)
题目链接:http://61.187.179.132/JudgeOnline/problem.php?id=1050 题意:给出一个带权图.求一条s到t的路径使得这条路径上最大最小边的比值最小? 思路 ...
- __declspec(dllexport) & __declspec(dllimport)
__declspec(dllexport) 声明一个导出函数,是说这个函数要从本DLL导出.我要给别人用.一般用于dll中 省掉在DEF文件中手工定义导出哪些函数的一个方法.当然,如果你的DLL里全是 ...
- 正则表达式(/[^0-9]/g,'')中的"/g"是什么意思 ?
正则表达式(/[^0-9]/g,'')中的"/g"是什么意思 ? 表达式加上参数g之后,表明可以进行全局匹配,注意这里“可以”的含义.我们详细叙述: 1)对于表达式对象的e ...
- eclipse启动报错eclipse failed to create the java virutal machine
早上一来,我的eclipse就无法启动了,错误就是这句话: eclipse failed to create the java virutal machine 直译就是eclipse无法创建JAVA虚 ...
- Hearthstone-Deck-Tracker项目的编译
https://github.com/HearthSim/Hearthstone-Deck-Tracker https://github.com/HearthSim/HearthDb https:// ...
- [51NOD1405] 树的距离之和(树DP)
题目链接:http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1405 (1)我们给树规定一个根.假设所有节点编号是0-(n-1 ...
- [Java解惑]数值表达式
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...