【原创】MapReduce编程系列之二元排序
- 普通排序实现
普通排序的实现利用了按姓名的排序,调用了默认的对key的HashPartition函数来实现数据的分组。partition操作之后写入磁盘时会对数据进行排序操作(对一个分区内的数据作排序),但这里的排序仅仅是对key的排序,而不是对value。可以进行以下测试:
待排序文件:sourceFile
Denlin Gao
Dengli Gao
Linjin Gao
Mingzhi Gao
Zhiming Gao
Lin Gao
Meili Gao
Meiling Gao
Hong Li
Ming Zhang
Ying Zhang
Bai Li
Song Zhang
Bai Gan
Yang Li
Yuan Zhang
Xuan Zhang
Yuan Gao
Xing Gao
排序MR程序:
public class PersonSort {
public static class MyMap extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String nameString = value.toString();
String[] nameSplit = nameString.split(" ");
String firstName = nameSplit[0];
String lastName = nameSplit[1];
context.write(new Text(lastName), new Text(firstName));
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text firstName : values) {
context.write(new Text(key), firstName);
}
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(PersonSort.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setJobName("Person Sort!");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/sourceFile"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/SortResult"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果:
Gan Bai
Gao Xing
Gao Dengli
Gao Linjin
Gao Mingzhi
Gao Zhiming
Gao Lin
Gao Meili
Gao Meiling
Gao Denlin
Gao Yuan
Li Bai
Li Hong
Li Yang
Zhang Song
Zhang Yuan
Zhang Xuan
Zhang Ming
Zhang Ying
从输出结果来看,排序只是只对key,如Gao Xing 和Gao Dengli就可以看出。以上输出将姓名安装中文的排列来输出。
- 二元排序
这里所说的二元排序指的是同时安装姓和名来排序,且以姓为主排序,名为从排序。
思考1:定义一个类,重写其hashcode方法,按照hashcode的值来实现分区,这样是否就能实现二元排序?
- 定义一个Person类,重写hashcode方法
class Person implements WritableComparable<Person> {
private String firstName;
private String lastName;
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.firstName = in.readUTF();
this.lastName = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(this.firstName);
out.writeUTF(this.lastName);
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
final int tmp = 17;
int result = 0;
result = result + tmp * this.getFirstName().hashCode();
result = result + tmp * this.getLastName().hashCode();
return result;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
}
2. 实现Person的partition:
class PersonNamePartitioner extends Partitioner<Person, Text> {
@Override
public int getPartition(Person key, Text value, int numPartitions) {
// TODO Auto-generated method stub
return Math.abs(key.hashCode()) % numPartitions;
}
}
3. 修改MR代码:
public class PersonSort {
public static class MyMap extends Mapper<Object, Text, Person, Text> {
private Person outputKey = new Person();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String nameString = value.toString();
String[] nameSplit = nameString.split(" ");
String firstName = nameSplit[0];
String lastName = nameSplit[1];
outputKey.setFirstName(firstName.toString());
outputKey.setLastName(lastName.toString());
context.write(outputKey, new Text(""));
}
}
public static class MyReduce extends Reducer<Person, Text, Text, Text> {
@Override
public void reduce(Person key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
context.write(new Text(key.getLastName()), new Text(key.getFirstName()));
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(PersonSort.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setJobName("Person Sort!");
job.setPartitionerClass(PersonNamePartitioner.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/sourceFile"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/SortResult"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4. 结果输出:
Gan Bai
Li Bai
Gao Dengli
Gao Denlin
Li Hong
Gao Lin
Gao Linjin
Gao Meili
Gao Meiling
Zhang Ming
Gao Mingzhi
Zhang Song
Gao Xing
Zhang Xuan
Li Yang
Zhang Ying
Gao Yuan
Zhang Yuan
Gao Zhiming
5. 总结:没有达到我们想要的效果!!原因在哪里呢?我们把firstName和LastName反过来输出下看看是什么样子:
Bai Gan
Bai Li
Dengli Gao
Denlin Gao
Hong Li
Lin Gao
Linjin Gao
Meili Gao
Meiling Gao
Ming Zhang
Mingzhi Gao
Song Zhang
Xing Gao
Xuan Zhang
Yang Li
Ying Zhang
Yuan Gao
Yuan Zhang
Zhiming Gao
从上面的结果可以看到,这下是正确的,不过不太符合我们的习惯,是按照名为主排序,姓为次排序的。那能否修改过来呢?
思考下我们整个数据的处理过程就不难发现,只要我们在map阶段传入数据的时候把姓和名互换下,就可以了。
mapreduce程序作下修改:
public class PersonSort {
public static class MyMap extends Mapper<Object, Text, Person, Text> {
private Person outputKey = new Person();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String nameString = value.toString();
String[] nameSplit = nameString.split(" ");
String firstName = nameSplit[0];
String lastName = nameSplit[1];
outputKey.setFirstName(lastName.toString());
outputKey.setLastName(firstName.toString());
context.write(outputKey, new Text(""));
}
}
public static class MyReduce extends Reducer<Person, Text, Text, Text> {
@Override
public void reduce(Person key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
context.write(new Text(key.getFirstName()), new Text(key.getLastName()));
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(PersonSort.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setJobName("Person Sort!");
job.setPartitionerClass(PersonNamePartitioner.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/sourceFile"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://localhost:9000/user/hadoop/PersonNameSort/SortResult"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果如下:
Gan Bai
Gao Dengli
Gao Denlin
Gao Lin
Gao Linjin
Gao Meili
Gao Meiling
Gao Mingzhi
Gao Xing
Gao Yuan
Gao Zhiming
Li Bai
Li Hong
Li Yang
Zhang Ming
Zhang Song
Zhang Xuan
Zhang Ying
Zhang Yuan
正确了,达到了我们想要的目的!
思考2:以上实现有没有什么问题呢?
mapreduce的默认实现是设置一个reducer,所以我们上面的分区函数最后都是往一个reducer上跑,但是如果有多个reducer,相同姓的人可能被分到不同的reducer,因为我们不是按照姓来分区,而是按照整个名字来分区的。可以测试一下,把reducer设置为2个以上,会发现有错误。这样说来,我们在map阶段必须安装lastname来分区,然后在排序算法那里调用我们的key来排序。
OK,这样一来,设置多个reducer就没有问题了。
思考3:其他实现方式:http://www.cnblogs.com/datacloud/p/3584640.html提供了一种实现了方法,直接copy过来了,感谢分享!
在MapReduce中,排序的目的有两个:
- MapReduce可以通过排序将Map输出的键分组。然后每组键调用一次reduce。
- 在某些需要排序的特定场景中,用户可以将作业(job)的全部输出进行总体排序。
例如:需要了解前N个最受欢迎的用户或网页的数据分析工作。
在这一节中,有两个场景需要对MapReduce的排序行为进行优化。
- 次排序(Secondary sort)
- 总排序(Total order sorting)
次排序可以根据reduce的键对它的值进行排序。如果要求一些数据先于另外一些数据到达reduce,次排序就很有用。(这一章在讲解优化过的重分区连接中也提到了这样的场景。)另一个场景中,需要将作业的输出根据两个键进行排序,一个键的优先级高于另外一个键(secondary key)。这个场景也可以用到次排序。例如:将股票数据先根据股票标志进行主排序(primary sort),然后根据股票配额进行次排序。本书很多技术中将会运用次排序,如重分区连接的优化,朋友图算法等。
这一节第二部分中,将探讨对reduce的输出的全部数据进行总体排序。这在分析数据集中的前N个元素或后N个元素时会比较有用。
4.2.1 次排序(Secondary sort)
在前一节(MapReduce连接)中,次排序用于使一部分数据先于另外一部分到达reduce。作为基础知识,学习次排序前需要了解MapReduce中的数据整理和数据流。图4.12说明了三个影响数据整理和数据流(分区,排序,分组)的元素,并且说明了这些元素如何整合到MapReduce中。
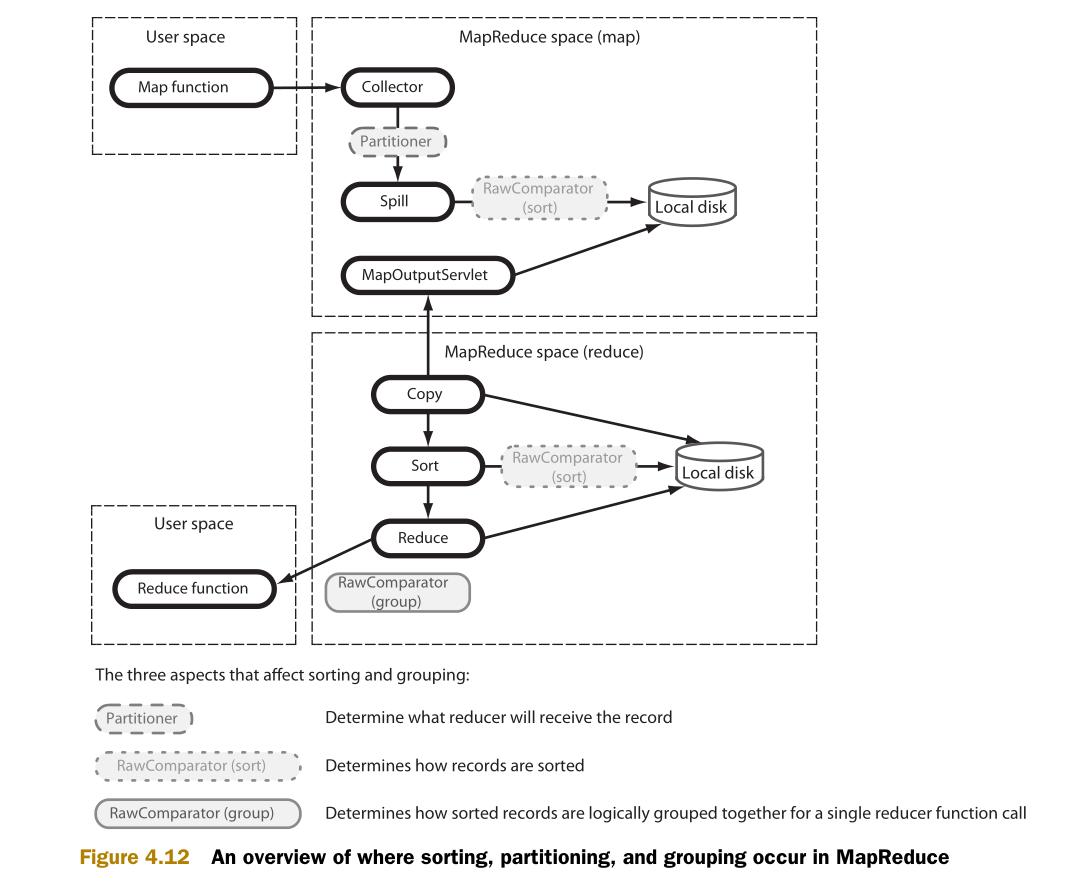
在map输出收集(output collection)阶段,由分区器(Partitioner)选择哪个reduce应该接收map的输出。map输出的各个分区的数据,由RawComparator进行排序。Reduce端也用RawComparator进行排序。然后,由RawComparator对排序好的数据进行分组。
技术21 实现次排序
对于某个map的键的所有值,如果需要其中一部分值先于另外一部分值到达reduce,就可以用到次排序。次排序还用在了本书的第7章中的朋友图算法,和经过优化的重分区排序中。
问题
在发送给某个reduce的数据中,需要对某个自然键(natural key)的值进行排序。
方案
这个技术中将应用到自定义分区类,排序比较类(sort comparator),分组比较类(grouping comparator)。这些是实现次排序的基础。
讨论
在这个技术中,使用次排序来对人的名字进行排序。具体步骤是:先用主排序对人的姓排序,再用次排序对人的名字排序。
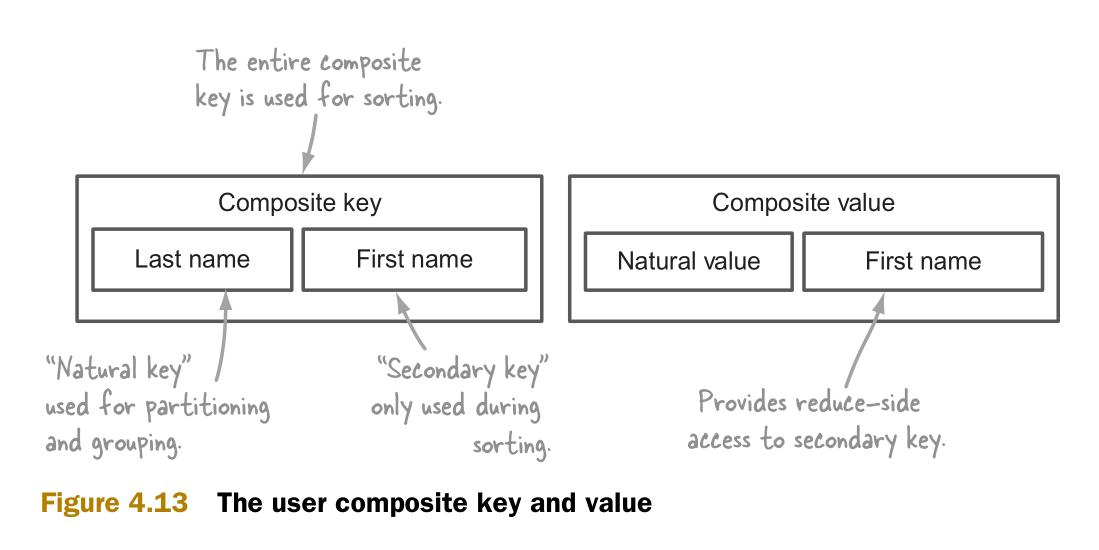
次排序需要在map函数中生成组合键(composite key)作为输出键。
组合输出键包括两个部分:
- 自然键,用于连接。
- 次键(secondary key),用于对隶属于自然键的值进行排序。排序后的结果将被发送给reduce。
图4.13说明了组合键的构成。它还包括了一个用于reduce端的组合值(composite value)。组合值让reduce可以访问次键。
在介绍了组合键类之后,接下来具体说明分区,排序和分组阶段以及他们的实现。
组合键(COMPOSITE KEY)
组合键包括姓氏和名字。它扩展了WritableComparable。WritableComparable被推荐用于map函数输出键的Writable类。

1 public class Person implements WritableComparable<Person> {
2
3 private String firstName;
4 private String lastName;
5
6 @Override
7 public void readFields(DataInput in) throws IOException {
8 this.firstName = in.readUTF();
9 this.lastName = in.readUTF();
10 }
11
12 @Override
13 public void write(DataOutput out) throws IOException {
14 out.writeUTF(firstName);
15 out.writeUTF(lastName);
16 }
17 ...
图4.14说明了分区,排序和分组的类的名字和方法的设置。同时还有各个类如何使用组合键。

接下来是对其它类的实现代码的介绍。
分区器(PARTITIONER)
分区器用来决定map的输出值应该分配到哪个reduce。MapReduce的默认分区器(HashPartitioner)调用输出键的hashCode方法,然后用hashCode方法的结果对reduce的数量进行一个模数(modulo)运算,最后得到那个目标reduce。默认的分区器使用整个键。这就不适于组合键了。因为它可能把有同样自然键的组合键发送给不同的reduce。因此,就需要自定义分区器,基于自然键进行分区。
以下代码实现了分区器的接口。getPartition方法的输入参数有key,value和分区的数量:
1 public interface Partitioner<K2, V2> extends JobConfigurable {
2 int getPartition(K2 key, V2 value, int numPartitions);
3 }
自定义的分区器将基于Person类中的姓计算哈希值,然后将这个哈希值对分区的数量进行模运算。在这里,分区的数量就是reduce的数量:
1 public class PersonNamePartitioner extends Partitioner<Person, Text> {
2
3 @Override
4 public int getPartition(Person key, Text value, int numPartitions) {
5 return Math.abs(key.getLastName().hashCode() * 127) % numPartitions;
6 }
7
8 }
排序(SORTING)
Map端和reduce端都要进行排序。Map端排序的目的是让reduce端的排序更加高效。这里将让MapReduce使用组合键的所有值进行排序,也就是基于姓氏和名字。
在下列例子中实现了WritableComparator。WritableComparator比较用户的姓氏和名字。
1 public class PersonComparator extends WritableComparator {
2
3 protected PersonComparator() {
4 super(Person.class, true);
5 }
6
7 @Override
8 public int compare(WritableComparable w1, WritableComparable w2) {
9
10 Person p1 = (Person) w1;
11 Person p2 = (Person) w2;
12
13 int cmp = p1.getLastName().compareTo(p2.getLastName());
14
15 if (cmp != 0) {
16 return cmp;
17 }
18
19 return p1.getFirstName().compareTo(p2.getFirstName());
20 }
21 }
分组(GROUPING)
当reduce阶段将在本地磁盘上的map输出的记录进行流化处理(streaming)的时候,需要要进行分组。在分组中,记录将被按一定方式排成一个有逻辑顺序的流,并被传输给reduce。
在分组阶段,所有的记录已经经过了次排序。分组比较器需要将有相同姓氏的记录分在同一个组。下面是分组比较器的实现:
1 public class PersonNameComparator extends WritableComparator {
2
3 protected PersonNameComparator() {
4 super(Person.class, true);
5 }
6
7 @Override
8 public int compare(WritableComparable o1, WritableComparable o2) {
9 Person p1 = (Person) o1;
10 Person p2 = (Person) o2;
11 return p1.getLastName().compareTo(p2.getLastName());
12 }
13 }
MAPREDUCE
最后一步是告诉MapReduce使用自定义的分区器类,排序比较器类和分组比较器类:
1 job.setPartitionerClass(PersonNamePartitioner.class);
2 job.setSortComparatorClass(PersonComparator.class);
3 job.setGroupingComparatorClass(PersonNameComparator.class);
然后需要实现map和reduce代码。Map类创建具有姓和名的组合键,然后将它作为输出键。将名字作为输出值。
Reduce类的输出和输入一样:
1 public static class Map extends Mapper<Text, Text, Person, Text> {
2
3 private Person outputKey = new Person();
4
5 @Override
6 protected void map(Text lastName, Text firstName, Context context)
7 throws IOException, InterruptedException {
8
9 outputKey.set(lastName.toString(), firstName.toString());
10 context.write(outputKey, firstName);
11
12 }
13 }
14
15 public static class Reduce extends Reducer<Person, Text, Text, Text> {
16
17 Text lastName = new Text();
18
19 @Override
20 public void reduce(Person key, Iterable<Text> values, Context context)
21 throws IOException, InterruptedException {
22
23 lastName.set(key.getLastName());
24
25 for (Text firstName : values) {
26 context.write(lastName, firstName);
27 }
28 }
29 }
【原创】MapReduce编程系列之二元排序的更多相关文章
- MapReduce编程系列 — 4:排序
1.项目名称: 2.程序代码: package com.sort; import java.io.IOException; import org.apache.hadoop.conf.Configur ...
- 学习ASP.NET Core Razor 编程系列十六——排序
学习ASP.NET Core Razor 编程系列目录 学习ASP.NET Core Razor 编程系列一 学习ASP.NET Core Razor 编程系列二——添加一个实体 学习ASP.NET ...
- 【原创】MapReduce编程系列之表连接
问题描述 需要连接的表如下:其中左边是child,右边是parent,我们要做的是找出grandchild和grandparent的对应关系,为此需要进行表的连接. Tom Lucy Tom Jim ...
- hadoop2.2编程:mapreduce编程之二次排序
mr自带的例子中的源码SecondarySort,我重新写了一下,基本没变. 这个例子中定义的map和reduce如下,关键是它对输入输出类型的定义:(java泛型编程) public static ...
- MapReduce编程系列 — 6:多表关联
1.项目名称: 2.程序代码: 版本一(详细版): package com.mtjoin; import java.io.IOException; import java.util.Iterator; ...
- MapReduce编程系列 — 5:单表关联
1.项目名称: 2.项目数据: chile parentTom LucyTom JackJone LucyJone JackLucy MaryLucy Ben ...
- MapReduce编程系列 — 3:数据去重
1.项目名称: 2.程序代码: package com.dedup; import java.io.IOException; import org.apache.hadoop.conf.Configu ...
- MapReduce编程系列 — 2:计算平均分
1.项目名称: 2.程序代码: package com.averagescorecount; import java.io.IOException; import java.util.Iterator ...
- MapReduce编程系列 — 1:计算单词
1.代码: package com.mrdemo; import java.io.IOException; import java.util.StringTokenizer; import org.a ...
随机推荐
- [CF660C]Hard Process(尺取法)
题目链接:http://codeforces.com/problemset/problem/660/C 尺取法,每次遇到0的时候补一个1,直到补完或者越界为止.之后每次从左向右回收一个0点.记录路径用 ...
- 投影纹理映射(Projective Texture Mapping)
摘抄“GPU Programming And Cg Language Primer 1rd Edition” 中文名“GPU编程与CG语言之阳春白雪下里巴人” 投影纹理映射( Projective ...
- hdu 4810 Wall Painting (组合数学+二进制)
题目链接 下午比赛的时候没有想出来,其实就是int型的数分为30个位,然后按照位来排列枚举. 题意:求n个数里面,取i个数异或的所有组合的和,i取1~n 分析: 将n个数拆成30位2进制,由于每个二进 ...
- bower常用命令
bower install loadash --save bower uninstall loadash --save bower init bower install loadash#2.2.1 b ...
- UVa 10048 Audiophobia【Floyd】
题意:给出一个c个点,s条边组成的无向图,求一点到另一点的路径上最大权值最小的路径,输出这个值 可以将这个 d[i][j]=min(d[i][j],d[i][k]+d[k][j]) 改成 d[i][j ...
- jquery总结(1)
jquery是一种js对象.里面封装了一些方法,但是jquery对象不能直接使用js方法,js对象不能直接使用jquery方法. jquery对象类似于js对象的集合,就是存在形式是以特殊数组的形式: ...
- hihoCoder #1181: 欧拉路·二 (输出路径)
题意: 给定一个图,要求打印出任一条欧拉路径(保证图肯定有欧拉路). 思路: 深搜的过程中删除遍历过的边,并在回溯时打印出来.在深搜时会形成多个环路,每个环都有一个或多个结点与其他环相扣,这样就可以产 ...
- python练习程序(批量重命名)
# -*- coding: cp936 -*- import sys,os,string d=0; path="F://test" srcfile=os.listdir(path) ...
- 机器学习(二)——K-均值聚类(K-means)算法
最近在看<机器学习实战>这本书,因为自己本身很想深入的了解机器学习算法,加之想学python,就在朋友的推荐之下选择了这本书进行学习,在写这篇文章之前对FCM有过一定的了解,所以对K均值算 ...
- MornUI 源码阅读笔记
1. label的mouseChildren属性为true,但label本身是不需要监听textfield的任何事件的, 个人猜测是为了给TextInput, TextArea用的,因为后两者需要监听 ...