C#识别验证码技术-Tesseract
相信大家在开发一些程序会有识别图片上文字(即所谓的OCR)的需求,比如识别车牌、识别图片格式的商品价格、识别图片格式的邮箱地址等等,当然需求最多的还是识别验证码。如果要完成这些OCR的工作,需要你掌握图像处理、图像识别的知识,需要用到图形形态学、傅里叶变换、矩阵变换、贝叶斯决策等很多复杂的理论,这让绝大部分人都会望而却步。
Tesseract这个开源项目的出现让我们普通人也可以涉足OCR的开发。Tesseract可以从图片中识别出文字内容,但不要以为Tesseract可以智能的识别出各种奇形怪状、复杂的图片文字,Tesseract默认只能识别非常标准字体、清晰无干扰的图片文字,刚接触Tesseract的人很多都会发出这样的评价“Tesseract吹的挺厉害,但是识别率很低呀,不好用”。其实我们要识别的内容千奇百怪,Tesseract是需要去训练才能比较高准确率的识别的,我们需要把一批样本图片让Tesseract去尝试识别,然后对他识别出的错误结果进行校正,告诉他“这个图片你识别错了,应该识别为某某某”,这样Tesseract慢慢的就“学会了”怎么样进行识别。也就是如下一个训练过程:
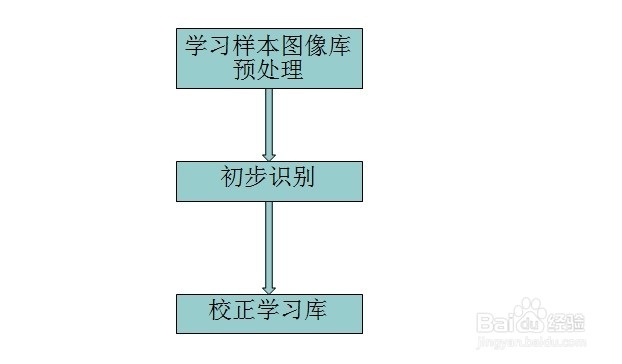
看到上图有一个“预处理”,这是什么意思呢?我们知道,很多验证码都是加了一些干扰处理的,比如说有的验证码加了噪音点、有的验证码加了干扰线、有的验证码加了干扰背景、有的验证码做了文字扭曲。如下图:

这些图片如果直接交给Tesseract去处理,识别的难度会非常大。开发人员应该在把图片交给Tesseract之前对图片进行比较的预处理操作,比如去掉干扰线、去掉背景噪点、字符矫正等等,有些复杂的预处理操作可能会涉及到图形形态学中比较深入的理论,这不是一篇文章能够介绍的,下面只列出比较简单的图片预处理的基本知识,深入学习请参考图形学相关资料。
基础讲解:
1、.Net中图片对象类是Image类,使用Image.FromFile(file)来加载一张图片,一般的图片都是位图,Bitmap类是Image类的子类,所以我们一般把Image. FromFile()返回值转换为Bitmap类型使用Bitmap bitmap = (Bitmap)Image.FromFile(file)
2、Bitmap. Save()用来把内存中的图片对象保存到输出中去。第二个参数为图片格式。
3、由于Bitmap关联到GDI的非托管资源,实现了IDisposable接口,所以需要使用using进行对象的资源管理,以避免程序内存泄露的问题。
4、如果要进行高效的图片操作,需要配合指针对Bitmap进行操作,当然为了避免对C#指针操作不熟悉的读者,这篇文章中我将会使用效率略低但是比较易懂的GetPixel、 SetPixel方法来进行图片操作。GetPixel、 SetPixel是Bitmap提供的两个方法,分别可以用来对图片进行指定坐标像素点颜色的读取和设置指定坐标像素点的颜色。
接下来开始讲解Tesseract的使用:
首先我们要采集多张有代表性的验证码样本图片,因为比较复杂的验证码的训练过程会比较长,而这次传智播客.Net学院举办的验证码识别免费公开课时间有限,因此我挑选了相对比较简单的验证码进行识别。复杂验证码的识别过程也是大同小异的。我测试用的100张验证码图片在文章最后的“公开课软件、图片库和代码.zip”压缩包中。

这些图片有一些明显的噪音背景和干扰线,但是噪音背景和干扰线的颜色就是那几个,因此我使用拾色器拾取了这些点的颜色,使用如下的代码把那些颜色替换为白色,并且保存为tif格式的图片:
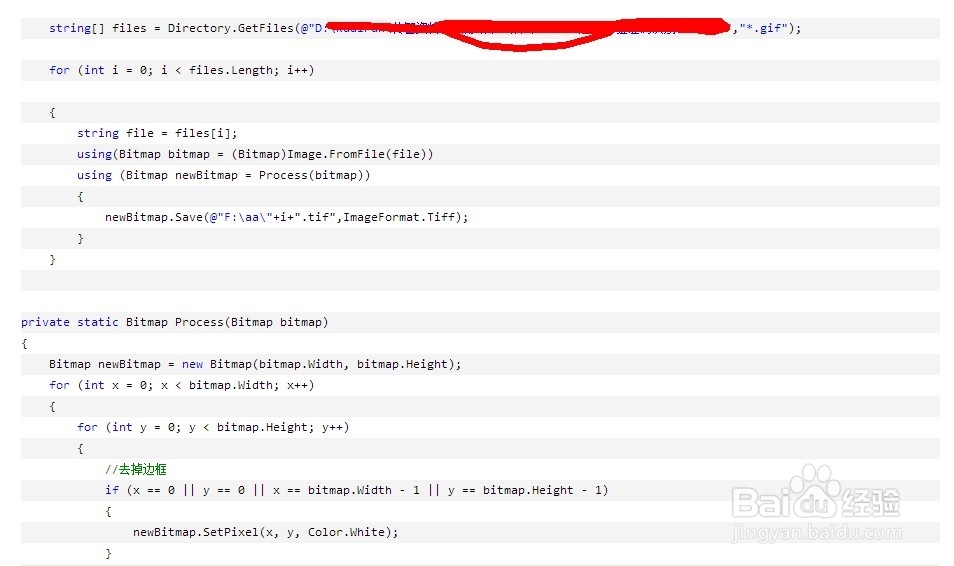
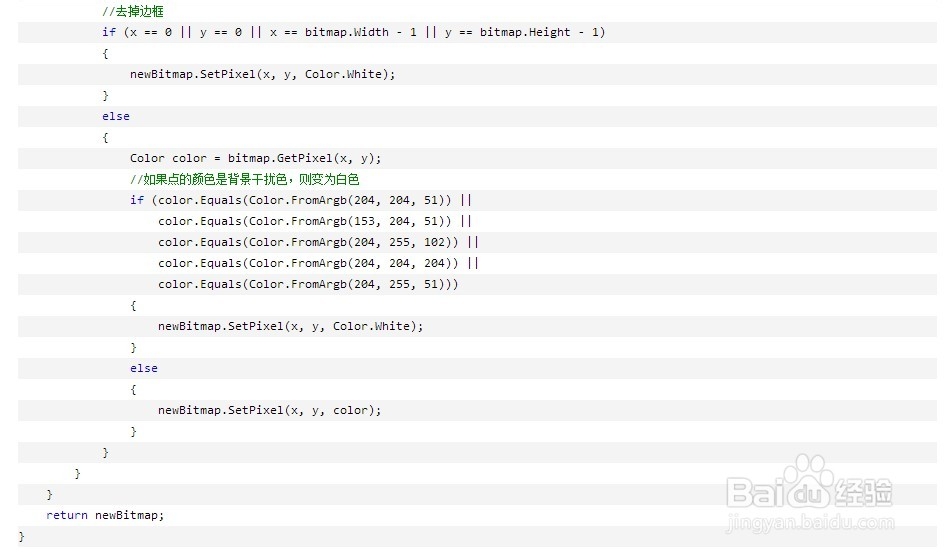
转换后效果如下:

可以看到背景颜色和干扰线全部被去掉了。
接下来运行jTessBoxEditor(jTessBoxEditor是使用java编写的,因此先需要安装配置java运行环境,对java运行环境安装配置不熟悉的朋友请自行寻找资料),双击jTessBoxEditor.jar即可启动运行。将第二步处理后的tiff使用主菜单 “Tool→Merge Tiff”图片合并为一张图片,比如保存到F:\aa\下haijia.tif文件中。
下载安装tesseract-ocr-setup-3.01-1.exe(我使用3.02有问题,不知道是我的问题还是我不会用,总之还是推荐大家这里先使用3.01版本),这个setup版本会自动把安装目录添加到Path环境变量中,推荐使用。如果下载portable版本则需要自己编辑环境把tesseract解压路径添加到Path环境变量中。
在下一步操作之前需要先给训练结果取一个名字,比如我这里就取haijia这个名字。如果你取了别的名字,只要把后面所有操作中的“haijia”改成你取的名字即可。
启动windows命令行窗口,并且进入haijia.tif文件所在的目录,然后执行tesseract.exe haijia.tif haijia batch.nochop makebox。其中haijia.tif就是第三步生成的合并tiff文件的文件名,haijia则是咱们取的训练名。这样就会生成初始识别结果的haijia.box文件
保证haijia.box文件和haijia.tif文件文件名完全一样并且放在同一个文件夹下。使用jTessBoxEditor打开haijia.tif文件,逐个校正文字,后保存。注意在jTessBoxEditor中每次修改完了字符都要回车,注意及时保存。如果发现多识别了、两个字母被识别为一个字母、一个字母被识别为两个字母等错误,需要使用Merge、split、delete之类的功能进行微调,还要通过修改X、Y、W、H修改自动识别的区域 。
所有的自动识别结果矫正完毕后命令行执行tesseract.exe haijia.tif haijia nobatch box.train
命令行执行unicharset_extractor.exe haijia.box
在目录下新建一个名字为“font_properties”的文件,并且输入文本(其中haijia就是训练的名字,保存的时候使用EditPlus等高级文本编辑器去掉BOM头或者保存为ANSI格式): haijia 1 0 0 1 0
命令行执行cntraining.exe haijia.tr
命令行执行 mftraining.exe -F font_properties -U unicharset haijia.tr
第12步完成后,目录下应该生成若干个文件了,把unicharset, inttemp, normproto, pfftable这四个文件加上训练名字前缀“haijia.”。
命令行执行“combine_tessdata haijia.” 来合并生成的haijia.traineddata训练文件。执行完这步后,文件夹下就应该生成一个haijia.traineddata文件了,这个文件就是识别用的训练数据文件,只需要这一个haijia.traineddata文件即可,之前用的tif图片文件以及其他的中间文件都不需要了。
接下来调用Tesseract的API就可以在程序中进行验证码识别了。Tesseract支持很多语言,C/C++、Java、.Net、PHP、Python都有相应的API封装,只要寻找你使用语言的API库即可。下面还是以.Net为例。
使用tesseractdotnet_v301_r590.zip中的tesseract.dll添加到相应的引用。注意tesseractdotnet默认只支持.Net 2.0,所以需要把项目的Target修改为.Net 2.0,如果你需要在2.0以上的版本中使用,则需要自己下载tesseractdotnet的源代码进行编译。
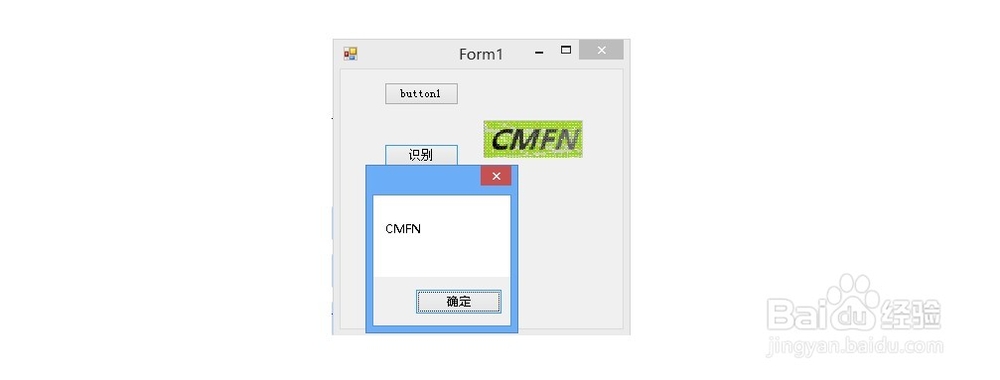
采用第二步同样的方法对待识别的图片进行预处理,然后执行下面的代码对预处理过后的图片对象进行识别:

C#识别验证码技术-Tesseract的更多相关文章
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 【转载】loadrunner使用system()函数调用Tesseract-OCR识别验证码遇到的问题
俗话说前人栽树,后人乘凉,此话一点不假,结合云层的一遍文章:http://bbs.51testing.com/thread-533920-1-1.html,知道还有一个Tesseract-OCR可以用 ...
- java识别验证码
所需资源下载链接(资源免费,重在分享) Tesseract:http://download.csdn.net/detail/chenyangqi/9190667 jai_imageio-1.1-alp ...
- loadrunner使用system()函数调用Tesseract-OCR识别验证码遇到的问题
俗话说前人栽树,后人乘凉,此话一点不假,结合云层的一遍文章:http://bbs.51testing.com/thread-533920-1-1.html,知道还有一个Tesseract-OCR可以用 ...
- Python爬虫入门教程 60-100 python识别验证码,阿里、腾讯、百度、聚合数据等大公司都这么干
常见验证码 之前的博客中已经解决了一些常见验证码的问题,但是验证码是层出不穷的,目前解决验证码除了通过常规手段解决以外,还可以通过人工智能领域的深度学习去解决 深度学习?! 无疑对爬虫coder提高了 ...
- Python Tensorflow CNN 识别验证码
Python+Tensorflow的CNN技术快速识别验证码 文章来源于: https://www.jianshu.com/p/26ff7b9075a1 验证码处理的流程是:验证码分析和处理—— te ...
- python网络爬虫之如何识别验证码
有些网站的登录方式是验证码登录的方式,比如今天我们要测试的网站专利检索及分析. http://www.pss-system.gov.cn/sipopublicsearch/portal/uilogin ...
- Python之selenium+pytesseract 实现识别验证码自动化登录脚本
今天写自己的爆破靶场WP时候,遇到有验证码的网站除了使用pkav的工具我们同样可以通过py强大的第三方库来实现识别验证码+后台登录爆破,这里做个笔记~~~ 0x01关于selenium seleniu ...
- python 识别验证码自动登陆
# python 3.5.0 # 通过Chrom浏览器访问发起请求 # 需要对应版本的Chrom和chromdriver # 作者:linyouyi from selenium import webd ...
随机推荐
- css 背景色渐变---和背景色透明
1 背景色渐变 background:#fb0000; background: -webkit-gradient(linear, left top, left bottom, color-stop(0 ...
- CDN学习笔记一(CDN是什么?)
CDN是什么? 谈到CDN的作用,可以用8年买火车票的经历来形象比喻: 8年前,还没有火车票代售点一说,12306.cn更是无从说起.那时候火车票还只能在火车站的售票大厅购买,而我所住的小县城并不通火 ...
- OpenERP QWeb模板标签笔记
在OpenERP中,通过QWeb来对模板进行渲染后加载到浏览器中,而模板中有许多的标签来定制各种需求变化,在这里记录学习过程中碰到的标签定义,以方便查询. 模板中的标签统一都是以"t-&qu ...
- Android开源库--Gson谷歌官方json解析库
官方文档地址:http://google-gson.googlecode.com/svn/trunk/gson/docs/javadocs/index.html 官方网站:http://code.go ...
- 简析 addToBackStack使用和Fragment执行流程
在使用Fragment的时候我们一般会这样写: FragmentTransaction transaction = getSupportFragmentManager().beginTransacti ...
- 转:C++中Static作用和使用方法
转自:http://blog.csdn.net/artechtor/article/details/2312766 1.什么是static? static 是C++中很常用的修饰符,它被用 ...
- D3.js 交互式操作
与图表的交互,指在图形元素上设置一个或多个监听器,当事件发生时,做出相应的反应. 一.什么是交互 交互,指的是用户输入了某种指令,程序接受到指令之后必须做出某种响应.对可视化图表来说,交互能使图表更加 ...
- QT对话框模式与非模式
QT模态对话框及非模态对话框 非模态对话框(Modeless Dialog)的概念不是模态对话框就是在其没有被关闭之前,用户不能与同一个应用程序的其他窗口进行交互,直到该对话框关闭.对于在模态来显示对 ...
- 能在CAD2004以下版本里面打开2007以上版本文件的外挂
下载地址:http://yunpan.cn/cjrxMKNubXQ5E 访问密码 1974 老何CAD工具安装办法:[推荐]先安装老何工具箱,然后用[扩展添加老何cad下拉菜单.bat]就完成老何下 ...
- AOP 之 6.1 AOP基础(拾陆)
6.1.1 AOP是什么 考虑这样一个问题:需要对系统中的某些业务做日志记录,比如支付系统中的支付业务需要记录支付相关日志,对于支付系统可能相当复杂,比如可能有自己的支付系统,也可能引入第三方支付平 ...