机器学习之K-means算法
前言
以下内容是个人学习之后的感悟,转载请注明出处~
简介
在之前发表的线性回归、逻辑回归、神经网络、SVM支持向量机等算法都是监督学习算法,需要样本进行训练,且
样本的类别是知道的。接下来要介绍的是非监督学习算法,其样本的类别是未知的。非监督学习算法中,比较有代表性
的就是聚类算法。而聚类算法中,又有
- 分割方法:K-means
- 分层次方法:ROCK 、 Chemeleon
- 基于密度的方法:DBSCAN
- 基于网格的方法:STING 、 WaveCluster
以上只是部分算法,在这里就不一一列举了,本文讲解的是K-means算法。
K-means原理
K-means算法原理十分简单,实行起来总共分为以下几个步骤:
- 1、根据要分K类来确定K个初始聚类中心
- 2、将每个样本数据分配给距离最近的聚类中心,形成K个簇
- 3、算出每个簇的均值点作为新的聚类中心
- 4、重复2、3两个步骤,直到聚类中心不再改变
文字往往没有这么直观,接下来看下面的图片,我们可以清晰地看到聚类中心的变化,簇的变化。随着上面步骤的结束,
K-means算法到达了我们想要的效果。
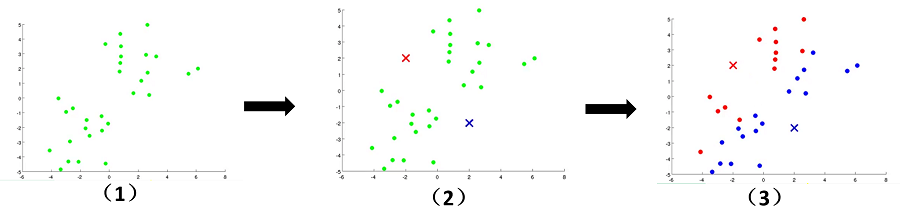
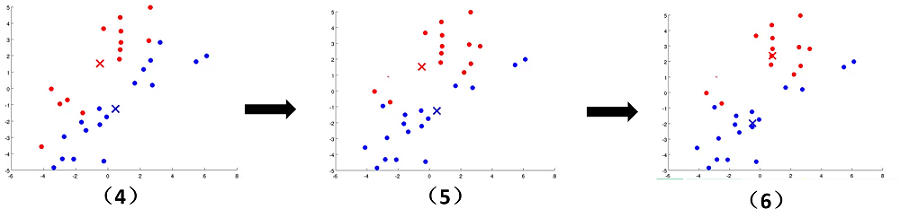
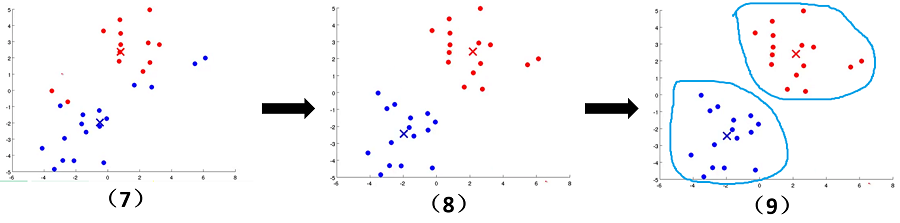
K-means参数优化
1、代价函数
这代价函数很好理解,最小化此代价函数,无非是最小化每个样本到所属类簇中心的距离,此时的分类效果很好。
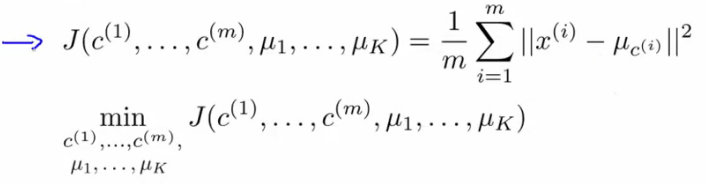
2、选择初始化聚类中心
如果采用随机初始化,很可能导致结果的不理想,下图是两个不同初始化聚类中心的分类效果,明显下面这个分类效果好
多了,所以一次随机初始化,并不能给我们带来理想的效果。
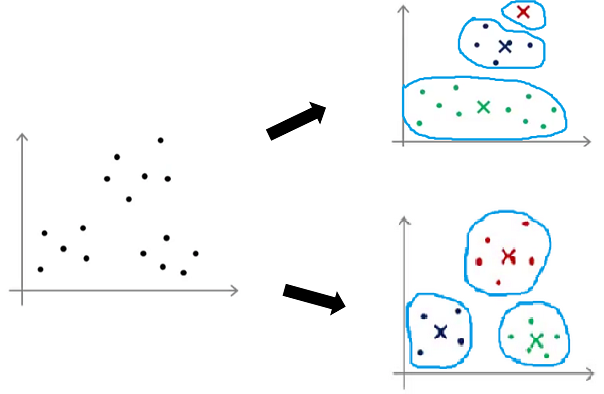
那我们该怎么选择初始聚类中心呢?其实只需多次随机初始化,并运行算法,计算其代价函数,选择代价函数值小的初
始化聚类中心。

3、选择聚类的数目
如何选择聚类的数目?说实话,没有特别标准的答案。一般来说,手动选取比较多,或者采用“肘部法则”(Elbow method),
此法则是计算不同聚类数目下的代价函数,画出曲线,选择这个转折点(像肘部)的K值作为聚类数目,如下面左图所示。但是,现实
中的情况往往是下面右图所示,很难找到“肘部”。
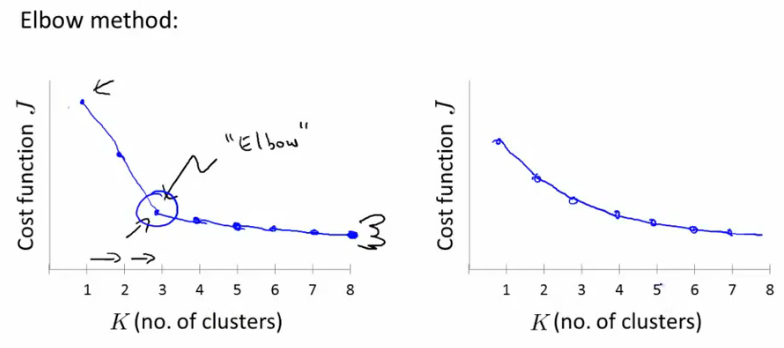
注意:其实很多时候,你要分类的目标会给你相应的信息,需要分几类,此时你完全可以按照目标的要求来。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~
机器学习之K-means算法的更多相关文章
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置. 在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解. 而是会出现一下情况: 为了解决这个问题,我们通常的做法是: 我们选取K ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 机器学习实战-k近邻算法
写在开头,打算耐心啃完机器学习实战这本书,所用版本为2013年6月第1版 在P19页的实施kNN算法时,有很多地方不懂,遂仔细研究,记录如下: 字典按值进行排序 首先仔细读完kNN算法之后,了解其是用 ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
随机推荐
- Swift----编程语言语法
1 简单介绍 今天凌晨Apple刚刚公布了Swift编程语言,本文从其公布的书籍<The Swift Programming Language>中摘录和提取而成.希望对各位的iOS&a ...
- 华为P7电信4G版刷机包 EMUI2.3 官方B125 第3版 精简 ROOT
ROM介绍 基于底包至 B125 SP03解包制作 增加自己订制的超美丽EMUI 2.3专用的全局主题 自调刷机脚本,全部权限完美百分百与官方原版相贴合. 加入Root权限并使用SuperSU 2.0 ...
- UVA 1541 - To Bet or Not To Bet(概率递推)
UVA 1541 - To Bet or Not To Bet 题目链接 题意:这题题意真是神了- -.看半天,大概是玩一个游戏,開始在位置0.终点在位置m + 1,每次扔一个硬币,正面走一步,反面走 ...
- hadoop集群ambari搭建(2)之制作hadoop本地源
准备好源资源server,我使用之前的一台node4,配置都是1GB内存20GB存储 集群最好的安装方式一定是通过本地源的,假设是公共源,那么网络将会严重影响我们的安装进度.所以制作本地源是每个大数据 ...
- how to run a continuous background task on OpenShift
https://stackoverflow.com/questions/27152438/best-way-to-run-rails-background-jobs-with-openshift ht ...
- Web性能测试工具:Siege安装&使用简介
在Web性能测试工具中,siege是比较热门和常见的,它有安装简单,使用简单,测试报告详细的特点. 并且可以在文本中预定义一系列待测试url模拟,并可设定一定并发量下持续指定时间or测试进行测试. 比 ...
- 使用 fcntl 函数 获取,设置文件的状态标志
前言 当打开一个文件的时候,我们需要指定打开文件的模式( 只读,只写等 ).那么在程序中如何获取,修改这个文件的状态标志呢?本文将告诉你如何用 fcntl函数 获取指定文件的状态标志. 解决思路 1. ...
- git 安装及命令
一.window下的git安装 1.安装教程 网上教程一堆.我參考的是这个:Git_Windows 系统下Git安装图解 还有这个也不错 2.环境搭建: 在配置完毕后,自己主动载入到系统环境变量中.如 ...
- Java类加载器(死磕5)
Java类加载器( CLassLoader ) 死磕5: 自定义一个文件系统classLoader 本小节目录 5.1. 自定义类加载器的基本流程 5.2. 入门案例:自定义文件系统类加载器 5 ...
- aop学习总结二------使用cglib动态代理简单实现aop功能
aop学习总结二------使用cglib动态代理简单实现aop功能 模拟业务需求: 1.拦截所有业务方法 2.判断用户是否有权限,有权限就允许用户执行业务方法,无权限不允许用户执行业务方法 (判断是 ...