PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集
目标站点分析
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,
先来看一下今日头条的源码结构:我们抓取文章的标题,详情页的图片链接试一下:

看到上面的源码了吧,抓取下来没有用,那么我看下它的后台数据:‘
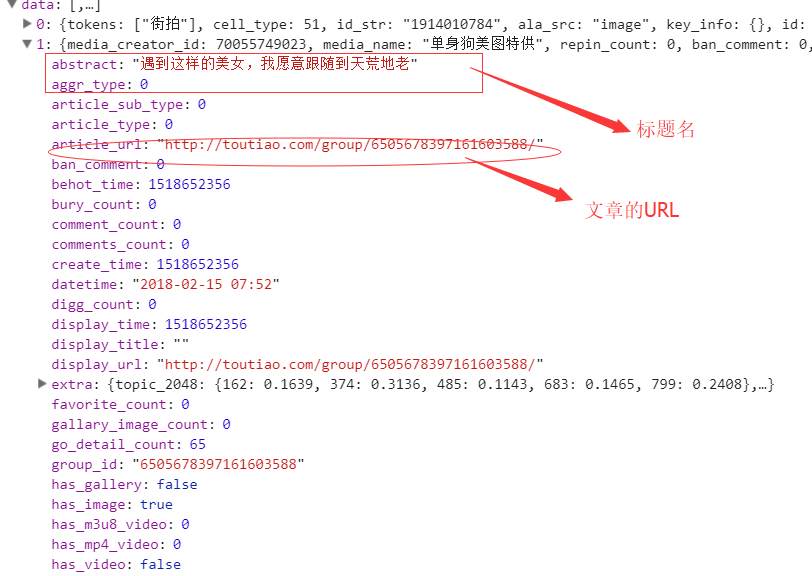
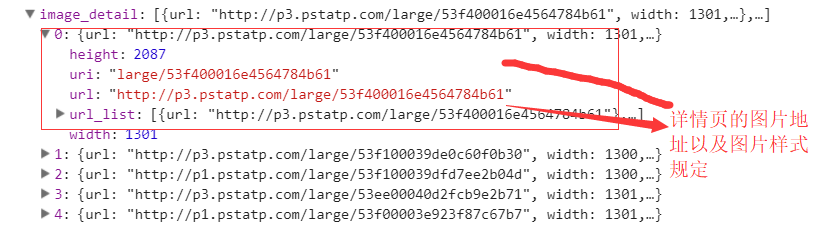
所有的数据都在后台的JSON展示中,所以我们需要通过接口对数据进行抓取


提取网页JSON数据
执行函数结果,如果你想大量抓取记得开启多进程并且存入数据库:

看下结果:

总结一下:网上好多抓取今日头条的案例都是先抓去指定主页,获取文章的URL再通过详情页,接着在详情页上抓取,但是现在的今日头条的网站是这样的,在主页的接口数据中就带有详情页的数据,通过点击跳转携带数据的方式将数据传给详情页的页面模板,这样开发起来方便节省了不少时间并且减少代码量
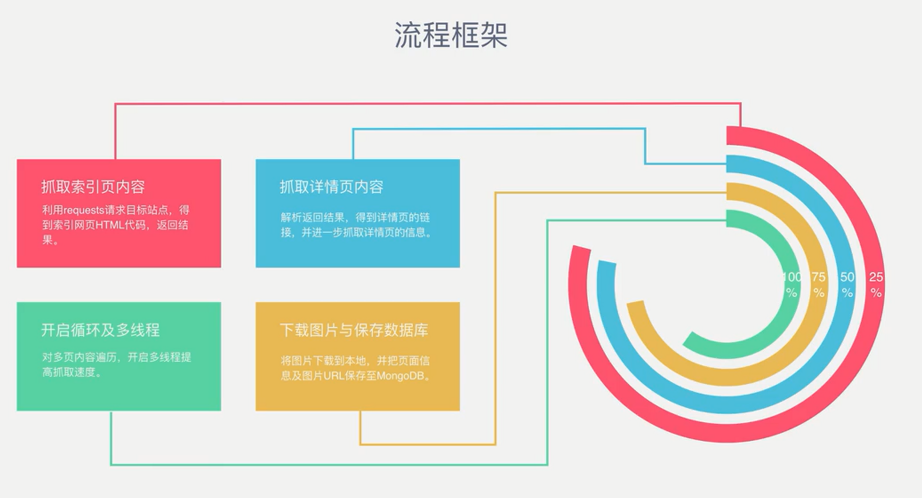
流程框架
爬虫实战
spider详情页
import json
import os
from hashlib import md5
from json import JSONDecodeError import pymongo
import re
from urllib.parse import urlencode
from multiprocessing import Pool import requests
from bs4 import BeautifulSoup
from config import * client = pymongo.MongoClient(MONOGO_URL, connect=False)
db = client[MONOGO_DB] def get_page_index(offset,keyword): #请求首页页面html
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3,
'from': 'search_tab'
}
url ='https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except Exception:
print('请求首页出错')
return None def parse_page_index(html): #解析首页获得的html
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') def get_page_detalil(url): #请求详情页面html
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except Exception:
print('请求详情页出错',url)
return None def parse_page_detail(html,url): #解析每个详情页内容
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
image_pattern = re.compile('gallery: JSON.parse\("(.*)"\)',re.S)
result = re.search(image_pattern,html)
if result:
try:
data = json.loads(result.group(1).replace('\\',''))
if data and 'sub_images' in data.keys():
sub_images = data.get("sub_images")
images = [item.get('url') for item in sub_images]
for image in images:download_image(image)
return {
'title':title,
'url':url,
'images':images
}
except JSONDecodeError:
pass def save_to_mongo(result): #把信息存储导Mongodb
try:
if db[MONOGO_TABLE].insert(result):
print('存储成功',result)
return False
return True
except TypeError:
pass def download_image(url): #查看图片链接是否正常获取
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
print('正在下载:',url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
save_image(response.content)
return None
except ConnectionError:
print('请求图片出错', url)
return None def save_image(content): #下载图片到指定位置 #file_path = '{}/{}.{}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
file_path = '{}/{}.{}'.format('/Users/darwin/Desktop/aaa',md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close() def main(offset):
html = get_page_index(offset,KEYWORD)
for url in parse_page_index(html):
html = get_page_detalil(url)
if html:
result = parse_page_detail(html,url)
save_to_mongo(result) if __name__ == '__main__':
groups = [x*20 for x in range(GROUP_START,GROUP_END+1)]
pool = Pool() pool.map(main,groups)config配置页
MONOGO_URL='localhost'
MONOGO_DB = 'toutiao'
MONOGO_TABLE = 'toutiao' GROUP_START=1
GROUP_END=2 KEYWORD='街拍'
PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)的更多相关文章
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- Python爬虫系列-分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. 2.抓取详情页内容 解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 3.下载图片与保存数据库 将 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
随机推荐
- bbed初体验
bbed能够直接查看或改动数据文件.听起来非常强大,以下体验一下,安装方法网上一搜一大把,我的环境是centos+10G的 bbed參考文档:http://pan.baidu.com/s/1hqCC6 ...
- 非常酷的word技巧---删除行前的空格
今天整理一篇文章的时间遇见一个问题,非常多行前的空格严重影响美观.搞计算机的就是爱折腾.于是做了各种尝试完美解决,以下把方法发布例如以下,事实上非常easy哦! 问题例如以下情况所看到的: 解决的方法 ...
- Java 使用StringBuffer注意
Stringbuffer使用注意 问题背景: 模拟客户端使用Socket请求服务器核心系统,核心系统正常响应,内容较大,近2715KB,大于2.6M多. 使用指定编码GBK来接收响应内容到过程中没 ...
- [读书笔记] learn python the hard way书中 有关powershell 的一些小问题
ex46中,创建自己的python, 当你激活环境时 .\.venvs\lpthw\ Scripts\activate 会报一个错误 此时需要以管理员身份运行PowerShell,(当前的PS不用关 ...
- 高性能HTTP加速器Varnish安装与配置(包含常见错误)
Varnish是一款高性能的开源HTTP加速器.挪威最大的在线报纸Verdens Gang使用3台Varnish取代了原来的12台Squid,性能竟然比曾经更好.Varnish 的作者Poul-Hen ...
- Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可以完 ...
- Chrome自带恐龙小游戏的源码研究(三)
在上一篇<Chrome自带恐龙小游戏的源码研究(二)>中实现了云朵的绘制和移动,这一篇主要研究如何让游戏实现昼夜交替. 昼夜交替的效果主要是通过样式来完成,但改变样式的时机则由脚本控制. ...
- xml 操作
/////////////////////////////////jaxp对xml文档进行解析/////////////////////////////////////////// 要操作的xml文件 ...
- Dubbo--简单介绍
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,能够和Spring框架无缝集成.Dubbo致力于提供高性能和透明化的RPC远程服务调用 ...
- linux下的显示有中国农历的日历ccal
1.linux下的显示有中国农历的日历ccal