文件解析库doctotext源码分析
DOC, XLS, XLSB, PPT, RTF, ODF (ODT, ODS, ODP),
OOXML (DOCX, XLSX, PPTX), iWork (PAGES, NUMBERS, KEYNOTE),
ODFXML (FODP, FODS, FODT), PDF, EML and HTML documents to plain text.
Extracts metadata and annotations.
对于解析像office2007这类的文件,doctotext只是识别出来格式是OOXML类型,并没有细分是word还是execl。
namespace doctotext
{
enum TableStyle { TABLE_STYLE_TABLE_LOOK, TABLE_STYLE_ONE_ROW, TABLE_STYLE_ONE_COL, };
enum UrlStyle { URL_STYLE_TEXT_ONLY, URL_STYLE_EXTENDED, URL_STYLE_UNDERSCORED, };
class ListStyle {}; struct FormattingStyle
{
TableStyle table_style;
UrlStyle url_style;
ListStyle list_style;
}; enum XmlParseMode {PARSE_XML, FIX_XML, STRIP_XML};
}
class PlainTextExtractor
{
//文件类型的枚举
enum ParserType{......}
//实现结构体
struct Implementation;
//实现结构体私有变量
Implementation *impl;
}
implementation中实现的函数列表
isRTF [PlainTextExtractor::Implementation]
isODFOOXML [PlainTextExtractor::Implementation]
isXLS [PlainTextExtractor::Implementation]
isDOC [PlainTextExtractor::Implementation]
isPPT [PlainTextExtractor::Implementation]
isHTML [PlainTextExtractor::Implementation]
isIWork [PlainTextExtractor::Implementation]
isXLSB [PlainTextExtractor::Implementation]
isPDF [PlainTextExtractor::Implementation]
isEML [PlainTextExtractor::Implementation]
isODFXML [PlainTextExtractor::Implementation]
parseRTF [PlainTextExtractor::Implementation]
parseODFOOXML [PlainTextExtractor::Implementation]
parseXLS [PlainTextExtractor::Implementation]
parseDOC [PlainTextExtractor::Implementation]
parsePPT [PlainTextExtractor::Implementation]
parseHTML [PlainTextExtractor::Implementation]
parseIWork [PlainTextExtractor::Implementation]
parseXLSB [PlainTextExtractor::Implementation]
parsePDF [PlainTextExtractor::Implementation]
parseTXT [PlainTextExtractor::Implementation]
parseEML [PlainTextExtractor::Implementation]
parseODFXML [PlainTextExtractor::Implementation]
parseRTFMetadata [PlainTextExtractor::Implementation]
parseODFOOXMLMetadata [PlainTextExtractor::Implementation]
parseXLSMetadata [PlainTextExtractor::Implementation]
parseDOCMetadata [PlainTextExtractor::Implementation]
parsePPTMetadata [PlainTextExtractor::Implementation]
parseHTMLMetadata [PlainTextExtractor::Implementation]
parseIWorkMetadata [PlainTextExtractor::Implementation]
parseXLSBMetadata [PlainTextExtractor::Implementation]
parsePDFMetadata [PlainTextExtractor::Implementation]
parseEMLMetadata [PlainTextExtractor::Implementation]
parseODFXMLMetadata [PlainTextExtractor::Implementation]
PlainTextExtractor [PlainTextExtractor]
~PlainTextExtractor [PlainTextExtractor]
setVerboseLogging [PlainTextExtractor]
setLogStream [PlainTextExtractor]
setFormattingStyle [PlainTextExtractor]
setXmlParseMode [PlainTextExtractor]
setManageXmlParser [PlainTextExtractor]
parserTypeByFileExtension [PlainTextExtractor]
parserTypeByFileExtension [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
根据输入参数选项指定文件类型
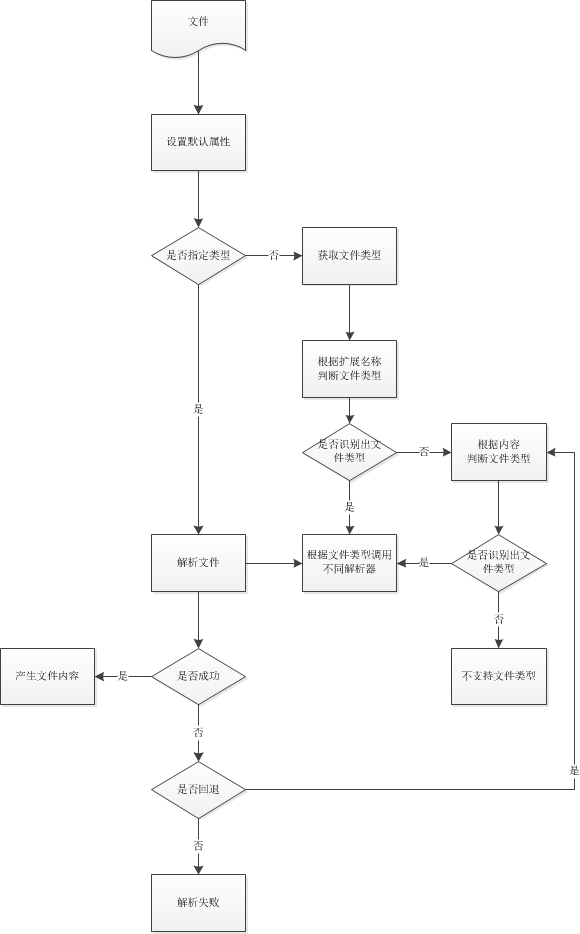
文件解析库doctotext源码分析的更多相关文章
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- 文件解析库doctotext安装和使用
安装doctotext 1 安装GCC到4.6以上 tar jxf gcc-4.7.0.tar.bz2 cd gcc-4.7.0 编译 ./contrib/download_prerequisites ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Android ViewManger解析 从ViewRoot 源码分析invalidate
转载请标明出处:http://blog.csdn.net/sk719887916/article/details/48443429,作者:skay 通过学习了AndroidUI之绘图机基础知道 ...
- 云风协程库coroutine源码分析
前言 前段时间研读云风的coroutine库,为了加深印象,做个简单的笔记.不愧是大神,云风只用200行的C代码就实现了一个最简单的协程,代码风格精简,非常适合用来理解协程和用来提升编码能力. 协程简 ...
- spring data jpa 全面解析(实践 + 源码分析)
前言 本文将从示例.原理.应用3个方面介绍spring data jpa. 以下分析基于spring boot 2.0 + spring 5.0.4版本源码 概述 JPA是什么? JPA (Java ...
- 【spring boot 系列】spring data jpa 全面解析(实践 + 源码分析)
前言 本文将从示例.原理.应用3个方面介绍spring data jpa. 以下分析基于spring boot 2.0 + spring 5.0.4版本源码 概述 JPA是什么? JPA (Java ...
- Python之contextlib库及源码分析
Utilities for with-statement contexts __all__ = ["contextmanager", "closing", &q ...
- Spring源码分析之AOP从解析到调用
正文: 在上一篇,我们对IOC核心部分流程已经分析完毕,相信小伙伴们有所收获,从这一篇开始,我们将会踏上新的旅程,即Spring的另一核心:AOP! 首先,为了让大家能更有效的理解AOP,先带大家过一 ...
随机推荐
- EasyNVR如何实现跨域鉴权
EasyNVR提供简单的登录鉴权,客户端通过用户名密码登录成功后,服务端返回认证token的cookie, 后续的接口访问, 服务端从cookie读取token进行校验. 但是, 在与客户系统集成时, ...
- ZOJ 3502 Contest <状态压缩 概率 DP>
链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3502 #include <iostream> #incl ...
- 九度OJ 1014:排名 (排序)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:8267 解决:2469 题目描述: 今天的上机考试虽然有实时的Ranklist,但上面的排名只是根据完成的题数排序,没有考虑每题的分 ...
- Linux就该这么学--Shell脚本条件语句(一)
1.条件测试语句能够让Shell脚本根据实际工作灵活调整工作内容,例如判断系统的状态后执行指定的工作,或创建指定数量的用户,批量修改用户密码,这些都可以让Shell脚本通过条件测试语句完成. if条件 ...
- MySql索引建立规则
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引.本小节将向读者介绍一些索引的设计原则. 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确 ...
- Machine Learning No.9: Dimensionality reduction
1. Principal component analysis algorithm data preprocessing 2. choosing the number of principal com ...
- HTML5/CSS3超酷环形动画菜单
在线演示 本地下载
- 关于NIO编程
NIO概述 什么是NIO? Java NIO(New IO)是一个可以替代标准Java IO API的IO API(从Java 1.4开始),Java NIO提供了与标准IO不同的IO工作方式. Ja ...
- matlab之结构体数组struct
以下内容来自于:https://blog.csdn.net/u010999396/article/details/54413615/ 要在MALTAB中实现比较复杂的编程,就不能不用struct类型. ...
- 阿里大于短信服务_异常_01_InvalidTimeStamp.Expired
一.异常信息 dm.aliyuncs.com InvalidTimeStamp.Expired Specified time stamp or date value is expired. 二.异常原 ...