ORM取数据很简单!是吗?

简介
几乎任何系统都以某种方式与外部数据存储一起运行。大多数情况下,外部数据存储是一个关系数据库,并且在实现时通常将数据提取任务委托给某些 ORM。 尽管 ORM 包含很多 routine 代码,但是另一方面也提供了一些新的抽象。
Martin Fowler 写过一篇关于 ORM 的有趣文章,其中一个主要思想是 “ ORM 帮助我们处理大多数企业应用程序中的一个非常现实的问题... ORM 不是漂亮的工具,但它解决的问题也不是可爱的。我认为他们应该得到更多的尊重和更多的理解”。
在 CUBA 框架中,我们大量地使用了 ORM,因为我们在世界各地都有各种各样的项目,所以我们非常了解它的局限性。关于 ORM 有很多方面可以讨论,但这里我们只关注其中一个:Lazy 和 Eager 方式加载数据。我们将会讨论数据获取的不同方法(主要在 JPA API 和 Spring 中),以及我们如何在 CUBA 中获取数据,还有我们在 CUBA 中改进 ORM 层所做的研发工作。我们还会了解哪些基本要素需要在使用ORM时考虑,以避免可怕的性能问题。
获取数据:Lazy 方式还是 Eager 方式?
如果数据模型只包含一个实体,那使用 ORM 不会有问题。我们来看看这个例子。有一个User实体,包含 ID 和 Name 属性:
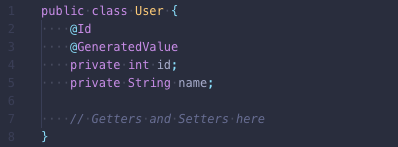
要获取这个实体,我们只需要简单的使用 EntityManager:

但是如果有实体之间的一对多关系的话,事情就变得有点意思了:
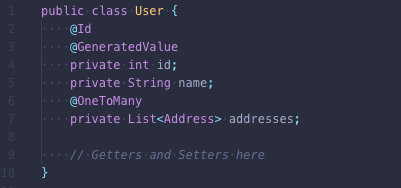
如果我们想从数据库中获取用户记录,就会出现一个问题:“我们也应该同时获取一个 address 吗?”。而“正确”的答案将是:“看情况”。在某些情况下,我们可能需要获取地址信息。通常,ORM提供两种获取数据的选项:Lazy 和 Eager。大多数ORM默认设置使用Lazy模式。因此,当我们编写以下代码时:

我们会遇到所谓的 “LazyInitException”,这会让ORM新手非常困惑。所以这里我们需要解释“Attach”和“Detach”对象的概念,以及数据库会话和事务。
那么,一个实体实例应该关联到一个数据库会话,这样我们才能够获取详细信息属性(比如 User.addresses)。但是在这种情况下,我们遇到了另一个问题,事务会变得越来越长,因此,会增加了数据库死锁的风险。可是,如果将我们的代码拆分为一系列短事务的话,又会由于非常短的单独查询语句数量的急剧增加,导致数据库“数百万只蚊子死亡” - 太多小事务。
如上所述,我们可能需要获取地址属性或者不需要,因此只是在某些情况下或者更多的条件判断之后使用 Address 集合。 嗯....看起来变得越来越复杂了。
好的,另一种获取类型会有帮助吗?
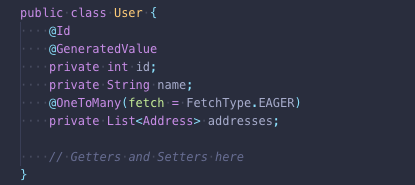
并没有想象的那么好。虽然使用 Eager 方式能避免烦人的懒加载初始化异常,也不需要检查实例是 Attach 还是 Detach。但是这里我们会遇到性能问题,因为我们并不是针对所有情况都需要用户的地址信息,可是用 Eager 方式会始终获取地址信息。那还有其他办法吗?
Spring JDBC
一些开发人员对ORM非常恼火,因此使用Spring JDBC并切换到“半自动”映射。在这种情况下,我们会为唯一用例创建唯一查询语句,并返回包含仅对特定用例有效的属性的对象。
这种方式给了我们很大的灵活性。比如,我们可以只获取一个属性:

或者整个对象:

您也可以使用 ResultSetExtractor 获取 addresses,但需要涉及编写一些额外的代码,还需要知道如何编写 SQL join 语句以避免 n+1 select 问题。
好吧,又变得复杂了。使用 Spring JDBC 您可以控制所有查询并控制结果映射,但是您必须编写更多代码,学习 SQL 并了解数据库查询语句的执行方式。虽然我认为了解 SQL 基础知识对于几乎每个开发人员来说都是一项必要的技能,但有些人并不这么认为,而我也不打算与他们争论。因为现在我们知道 x86 汇编程序对每个人来说都不是一项至关重要的技能。我们只是考虑如何能简化开发。
JPA EntityGraph
我们回过头想想,我们到底要实现什么样的目标?好像就是确切地说明在不同的用例中我们需要获取哪些实体属性。JPA 2.1 引入了一个新的 API - Entity Graph。这个API背后的想法很简单 - 您只需编写几个注解来描述应该获取的内容。我们来看看这个例子:
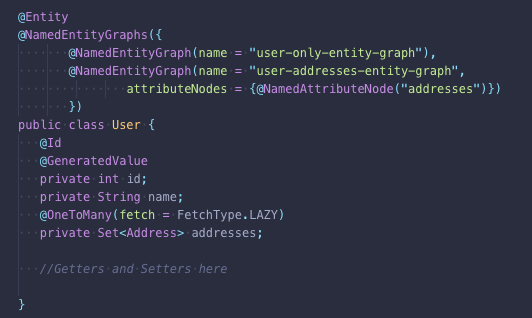
对于这个实体,我们描述了两个实体图(entity graphs) - user-only-entity-graph 不加载addresses属性(标记为lazy),而第二个实体图需要 ORM 获取 addresses。但是如果我们将属性标记为 Eager,则将忽略实体图设置并获取属性。
因此,从JPA 2.1开始,您可以通过以下方式选择实体:

这种方法极大地简化了开发人员的工作,无需“触摸” Lazy 属性并创建长事务。最棒的是,实体图可以在生成SQL的级别使用,因此不会从数据库中将额外数据提取到Java应用程序。但是这里仍然存在问题:在外部调用时不方便知道提取了哪些属性。有一个API可以检查: 使用 PersistenceUnit 类检查属性是否加载:

但是这样做很无聊。我们有办法简化并且不显示无法获取的属性吗?
Spring Projections
Spring Framework 提供了一个名为 Projections 的出色工具(它与Hibernate的 Projections 不同)。如果我们只想获取实体的某些属性,我们可以指定一个接口,Spring 将从数据库中选择接口“实例”。我们来看看这个例子。如果我们定义以下接口:
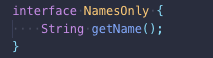
然后定义 Spring JPA repository 以获取我们的用户实体:

在这种情况下,在调用 findByName 方法之后,我们将无法访问未获取的属性!同样的原则也适用于 detail entity 类。因此,您可以通过这种方式获取 master 记录和 detail 记录。此外,在大多数情况下,Spring 能生成 “合适的” SQL 并仅提取 projection 中指定的属性,也就是说 projections 能像实体图一样工作。
这是一个非常强大的概念,您可以使用 SpEL 表达式,使用类而不是接口,等等。如果您感兴趣,可以在文档中了解更多信息。
Projections 的唯一问题是它们在底层使用 map 实现,所以是只读的。因此,您可以为 projection 定义 setter 方法,但无法使用 CRUD repositories 和 EntityManager 来保存更改。您可以将 projection 视为DTO,但是您必须编写自己的 DTO-to-entity 转换代码。
CUBA 的实现
从CUBA框架开发开始,我们尝试优化与处理数据库的代码。在框架中,我们使用 EclipseLink 来实现数据访问层API。关于 EclipseLink 的好处 - 它从一开始就支持部分实体加载,这就是我们首先选择它而不选 Hibernate 的原因。在 JPA 2.1 成为标准之前,使用这个 ORM 就能准确指定加载哪些属性。因此,我们在 CUBA 框架中加入了内部的 “Entity Graph” 概念 - CUBA 视图。视图非常强大 - 您可以对视图进行扩展、组合等等。创建 CUBA 视图背后的第二个原因 - 我们希望使用短事务,并主要使用 detach 对象,否则,我们没办法让丰富的web UI 以响应式并且快速的方式运行。
在CUBA中,视图描述存储在 XML 文件中,如下所示:
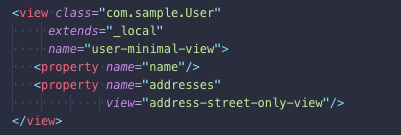
此视图会告诉 CUBA DataManager 使用其 name 属性获取User实体,并在查询级别获取地址时使用 address-street-only-view 视图。视图定义之后,您可以在使用 DataManager 类获取实体时使用视图:

这就像魔法一样。由于不加载未使用的属性,能节省大量的网络流量,但是跟 JPA Entity Graph 类似,有一个小问题:我们不知道加载了用户实体的哪些属性。在 CUBA 中,我们非常讨厌 “IllegalStateException: Cannot get unfetched attribute [...] from detached object”。与 JPA 一样,您可以检查属性是否已获取,但是为每个正在加载的实体编写这些检查是一项无聊的工作,开发人员对此有些不满。
CUBA 视图接口初探
如果我们能够充分利用两种方式呢?我们决定实现使用 Spring 方法的所谓实体接口,不同的是,这些接口在应用程序启动期间转换为 CUBA 视图,然后可以在 DataManager 中使用。这个想法非常简单:您定义了一个指定实体图的接口(或一组接口)。它看起来像 Spring Projections 并且像 Entity Graph 一样工作:
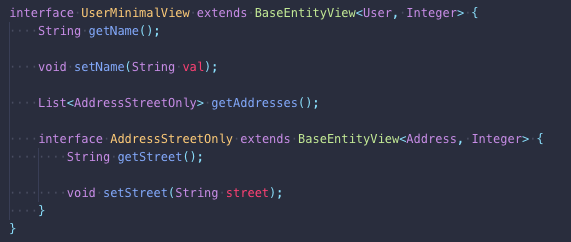
请注意,如果 AddressStreetOnly 接口只在一种情况下使用,则可以声明其为内部接口。
然后在 CUBA 应用程序启动期间(事实上,主要是Spring Context 初始化的过程中),我们为 CUBA 视图创建一个程序化表示,并将它们存储在 Spring Context 的内部 repository bean中。
之后我们需要调整 DataManager,然后,除了CUBA 视图的字符串名称之外它还可以接受类名,加载时,我们只需传递上面定义的接口类:

跟 Hibernate 一样,我们生成代理,为从数据库中提取的每个实例实现实体视图。当您尝试获取属性的值时,代理会将调用转发给具体的实体执行。
通过这个实现,我们试着能一石二鸟:
l 未在接口中声明的数据不会加载到Java应用程序代码,从而节省了服务器资源
l 开发人员只使用被提取的属性,因此不再出现 “UnfetchedAttribute” 错误(在 Hibernate中也称为 LazyInitException)。
与 Spring Projections 相比,实体视图能包装实体并实现了 CUBA 的 Entity 接口,因此可以将它们视为实体:您可以更新属性并将更改保存到数据库。
这里还有 “ 第三只鸟” - 你可以定义一个只包含 getter 的 “只读”接口,能完全阻止实体在API级别进行修改。
此外,我们可以在 detach 的实体上实现一些操作,例如将此用户的名称转换为小写:

在这种情况下,可以从实体模型移除所有需要计算的属性,因此不会在实体内部将数据获取逻辑与特定于用例的业务逻辑混合使用。
另一个有趣的机会 - 您可以继承接口。这使您可以使用不同的属性集准备多个视图,然后根据需要混合它们。例如,您可以拥有一个包含用户名和电子邮件的界面,另一个界面包含用户名和地址。如果你需要一个应该包含用户名,电子邮件和地址的第三个视图界面,你可以通过组合两者来实现 - 这要归功于Java中的多接口继承。请注意,您可以将此第三个接口传递给使用第一个或第二个接口的方法,这里也能使用OOP原则。
我们还在视图之间实现了实体转换 - 每个实体视图都有reload()方法,它接受另一个视图类作为参数:

UserFullView 可能包含其他属性,因此使用时,会从数据库重新加载实体。实体重新加载是一个 Lazy 的过程,只有在尝试获取实体属性值时才会执行。我们故意这样做是因为在 CUBA 中我们有一个 web 模块,可以呈现丰富的 UI,并且可能包含自定义的 REST 控制器。在此模块中,跟 core 模块(也叫中间件)使用相同的实体,但是 web 模块可以部署在单独的服务器上。因此,每个实体重新加载都会通过 core 模块向数据库发出附加请求。所以,通过引入实体重新懒加载,我们节省了一些网络流量和数据库查询。
PoC 代码可以从GitHub下载 - 随意试试看。
结论
ORM 将在不久的将来在企业应用程序中大量使用。我们只需要提供一些将数据库行转换为 Java 对象的东西。当然,在复杂,高负载的应用程序中,我们也能继续看到独特的解决方案,但只要 RDBMS 存在,ORM 也会继续存在。
在 CUBA 框架中,我们试图简化 ORM 的使用,使开发人员尽可能轻松。在接下来的版本中,我们将引入更多更改。我不确定这些是视图接口还是其他东西,但我很确定一件事 - 在下一版本中我们将简化 CUBA 中 ORM 的使用方法。
ORM取数据很简单!是吗?的更多相关文章
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- nodejs利用superagent爬取数据的简单例子
爬取世界银行统计数据 安装:npm install superagent /** * Created by zh on 16-9-7. */ var request = require('supera ...
- mysql实现高效率随机取数据
从数据库中(mysql)随机获取几条数据很简单,但是如果一个表的数据基数很大,比如一千万,从一千万中随机产生10条数据,那就相当慢了,如果同时一百个人访问网站,处理这些个进程,对于一般的服务器来说,肯 ...
- 轻松搞定Ajax(分享下自己封装ajax函数,其实Ajax使用很简单,难是难在你得到数据后来怎样去使用这些数据)
hey,guys!今天我们一起讨论下ajax吧!此文只适合有一定ajax基础,但还是模糊状态的同志,当然高手也可以略过~~~ 一.概念 Ajax(Asynchronous Javascript + X ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- C#简单爬取数据(.NET使用HTML解析器ESoup和正则两种方式匹配数据)
一.获取数据 想弄一个数据库,由于需要一些人名,所以就去百度一下,然后发现了360图书馆中有很多人名 然后就像去复制一下,发现复制不了,需要登陆 此时f12查看源码是可以复制的,不过就算可以复制想要插 ...
- django orm 分页(paginator)取数据出现警告manage.py:1: UnorderedObjectListWarning: Pagination may yield inconsistent results with an unordered object_list: <class 'sign.models.Guest'> QuerySet.
使用django的orm做分页(Paginator)时出现了下面的警告 In [19]: p=Paginator(guest_list,2) manage.py:1: UnorderedObjectL ...
- python爬取旅游数据+matplotlib简单可视化
题目如下: 共由6个函数组成: 第一个函数爬取数据并转为DataFrame: 第二个函数爬取数据后存入Excel中,对于解题来说是多余的,仅当练手以及方便核对数据: 后面四个函数分别对应题目中的四个m ...
随机推荐
- 安装openSUSE网卡驱动
网卡:英特尔 82579LM Gigabit Network Connection 先去英特尔的网站下载驱动 http://downloadcenter.intel.com/SearchResult. ...
- bzoj-2251 外星联络
题意: 给出一个字符串,求出现次数超过1的子串的出现个数. 字符串长度<=3000: 题解: 题目问的是子串的个数.那么首先我们要找到全部的子串. 而字符串的全部后缀的前缀能够不重不漏的表示全部 ...
- 【BZOJ1085】[SCOI2005]骑士精神 双向BFS
[BZOJ1085][SCOI2005]骑士精神 Description 在一个5×5的棋盘上有12个白色的骑士和12个黑色的骑士, 且有一个空位.在任何时候一个骑士都能按照骑士的走法(它可以走到和它 ...
- 九度OJ 1122:吃糖果 (递归)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:1522 解决:1200 题目描述: 名名的妈妈从外地出差回来,带了一盒好吃又精美的巧克力给名名(盒内共有 N 块巧克力,20 > N ...
- a REST API
https://spring.io/guides/tutorials/bookmarks/ http://roy.gbiv.com/untangled/2008/rest-apis-must-be-h ...
- ubuntu搭建nginx
1.下载nginx压缩包 2.上传.解压 tar -zxvf nginx-1.8.0.tar.gz cd nginx-1.8.0 3.安装 make install 4.启动,停止 ,重启 服务 可 ...
- P1604&P1601
[usaco2010]冲浪_slide 受到秘鲁的马丘比丘的新式水上乐园的启发,Farmer John决定也为奶牛们建一个水上乐园.当然,它最大的亮点就是新奇巨大的水上冲浪. 超级轨道包含 E (1 ...
- atol的实现【转】
本文转载自:http://blog.csdn.net/cwqbuptcwqbupt/article/details/7518582 看了atol的实现,发现char到int的转换比较奇怪:c = (i ...
- HDU5950 Recursive sequence —— 矩阵快速幂
题目链接:https://vjudge.net/problem/HDU-5950 Recursive sequence Time Limit: 2000/1000 MS (Java/Others) ...
- html5--5-16 综合实例绘制饼图
html5--5-16 综合实例绘制饼图 实例 <!doctype html> <html> <head> <meta charset="utf-8 ...