storm中的topology-worker-executor-task
- 调度角色
- 调度方法
- 自定义调度
1 调度角色

上图是JStorm中一个topology对应的任务执行结构,其中worker是进程,executor对应于线程,task对应着spout或者bolt组件。
1.1 Worker
Worker是task的容器, 同一个worker只会执行同一个topology相关的task。 一个topology可能会在一个或者多个worker(工作进程)里面执行,每个worker执行整个topology的一部分。比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks。Storm会尽量均匀的工作分配给所有的worker。
1.2 Executor
Executor是在worker中的执行线程,在同一类executor中,要么全部是同一个bolt类的task,要么全部是同一个spout类的task,需要注意的是, 一个executor只能同时运行一个task,创建时将多个task设置在一个executor中,在前期Storm中主要考虑的是后期线程扩展(待验证),但是在JStorm中可以在rebalance时改变Task的数量,所以不需要将task数量大于executor。
1.3 Task
Task是真正任务的执行者,对应创建topology时建立的一个bolt或者spout组件。每一个spout和bolt会被当作很多task在整个集群里执行。可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)。
2 调度方法
2.1 默认调度算法
默认调度算法遵循以下的原则:
- 任务调度算法以worker为维度,尽量将平均分配到各个supervisor上;
- 以worker为单位,确认worker与task数目大致的对应关系(注意在这之前已经其他拓扑占用利用的worker不再参与本次动作);
- 建立task-worker关系的优先级依次为:尽量避免同类task在同一work和supervisor下的情况,尽量保证task在worker和supervisor基准上平均分配,尽量保证有直接信息流传输的task在同一worker下。
- 调度过程中正在进行的调度动作不会对已发生的调度动作产生影响
2.2 调度示例
如下是一个topology创建时配置代码,以及运行时的示意图。
//创建topology配置代码
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf,
topologyBuilder.createTopology());

参考以上代码,以及任务调度算法,该拓扑中,设为worker为2,蓝色Spout并发设置为2,task默认与并发相同为2;绿色Bolt执行并发为2,但设置其task为4,所以每个executor中有两个Task,黄色Bolt并发为6,task默认与并发相同为6。
图中两个worker是一致的,可以认为是JStorm分配任务时做的权衡,尽量分配的均匀,不代表所有情况都是如此。
2.3 分发过程

上图是storm的示例,JStorm雷同。
JStorm任务分发过程:
- 客户端提交拓扑到nimbus,并开始执行;
- Nimbus针对该拓扑建立本地的目录,根据topology的配置计算task,分配task,在zookeeper上建立assignments节点存储task和supervisor机器节点中woker的对应关系;
- 在zookeeper上创建taskbeats节点来监控task的心跳;启动topology。
- 各Supervisor去zookeeper上获取分配的tasks,启动多个woker进行,每个woker生成task;根据topology信息初始化建立task之间的连接。
使用ack机制需要注意是的:
spout发送数据时需要指定msgID,中间的bolt在emit数据的时候需要传递tuple,否则当下游的bolt失败后,不会触发spout的fail

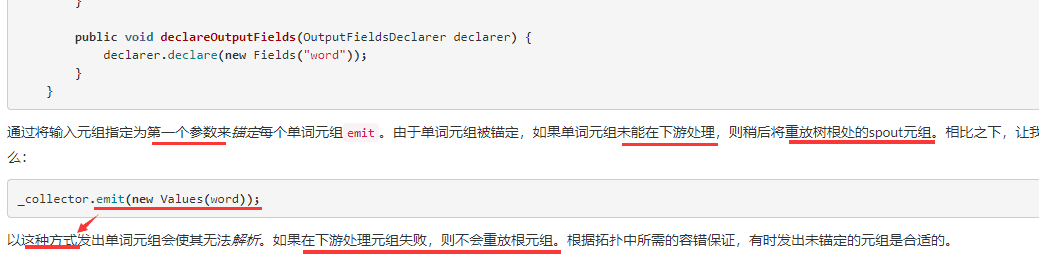
collector.ack与collector.fail的位置一定不要乱放,否则很可能不执行spout的fail方法
如果ack放在emit之前,或者在调用fail之后,程序还有机会调用到ack,那么就会结束jstorm的ack线程,告诉整个topology,此任务已结束,并处理成功。
https://blog.csdn.net/wwwxxdddx/article/details/49977697
storm中的topology-worker-executor-task的更多相关文章
- Storm中-Worker Executor Task的关系
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:1. Worker(进程)2. Executor(线程)3. Task 下图简要描述了这3者之间的关 ...
- Storm概念学习系列之Worker、Task、Executor三者之间的关系
不多说,直接上干货! Worker.Task.Executor三者之间的关系 Storm集群中的一个物理节点启动一个或者多个Worker进程,集群的Topology都是通过这些Worker进程运行的. ...
- Storm中关于Topology的设计
一:介绍Storm设计模型 1.Topology Storm对任务的抽象,其实 就是将实时数据分析任务 分解为 不同的阶段 点: 计算组件 Spout Bolt 边: 数据流向 数据从上 ...
- Storm概念学习系列之核心概念(Tuple、Spout、Blot、Stream、Stream Grouping、Worker、Task、Executor、Topology)(博主推荐)
不多说,直接上干货! 以下都是非常重要的storm概念知识. (Tuple元组数据载体 .Spout数据源.Blot消息处理者.Stream消息流 和 Stream Grouping 消息流组.Wor ...
- storm源码之理解Storm中Worker、Executor、Task关系 + 并发度详解
本文导读: 1 Worker.Executor.task详解 2 配置拓扑的并发度 3 拓扑示例 4 动态配置拓扑并发度 Worker.Executor.Task详解: Storm在集群上运行一个To ...
- 【原】storm源码之理解Storm中Worker、Executor、Task关系
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:1. Worker(进程)2. Executor(线程)3. Task 下图简要描述了这3者之间的关 ...
- storm中worker、executor、task之间的关系
这里做一些补充: worker是一个进程,由supervisor启动,并只负责处理一个topology,所以不会同时处理多个topology. executor是一个线程,由worker启动,是运行t ...
- 关于Storm 中Topology的并发度的理解
来自:https://storm.apache.org/documentation/Understanding-the-parallelism-of-a-Storm-topology.html htt ...
- Storm官方文档翻译之在生产环境集群中运行Topology
在进群生产环境下运行Topology和在本地模式下运行非常相似.下面是步骤: 1.定义Topology(如果使用Java开发语言,则使用TopologyBuilder来创建) 2.使用StormSub ...
- Twitter Storm中Topology的状态
Twitter Storm中Topology的状态 状态转换如下,Topology 的持久化状态包括: active, inactive, killed, rebalancing 四个状态. 代码上看 ...
随机推荐
- windwos 10 谷歌浏览器出现彩色闪条
应该是上个星期五开始,发现电脑从别的地方切换到谷歌浏览器就会出现闪条,开始也没太注意,但是到周一还是这样,所以再网上查了下, 说什么的都有,什么你按脑屏幕坏了,内存条不行什么是的.后来才发现原来是谷歌 ...
- SQL SERVER 判断是否存在数据库、表、列、视图
SQL SERVER 判断是否存在数据库.表.列.视图 --1. 判断数据库是否存在 IF EXISTS (SELECT * FROM SYS.DATABASES WHERE NAME = '数据库名 ...
- 《TCP/IP详解卷一:协议》 概述
分层 TCP/IP协议族是一组不同层次上的多个协议的组合.TCP/IP通常被认为是一个四层次协议系统. 链路层(数据链路层或网络接口层):通常包括操作系统中的设备驱动程序和计算 ...
- JAVA基础知识 String s = new String("ABC") VS String s = "abc"
一: String s = new String("ABC") VS String s = "abc" String s = "abc&q ...
- ng2中router-outlet用法
说明:router-outlet 是应用中的路由插座,一个页面中可以使用一个或多个router-outlet 1.只使用一个router-outlet 父组件: <router-outlet&g ...
- HDU - 5878 2016青岛网络赛 I Count Two Three(打表+二分)
I Count Two Three 31.1% 1000ms 32768K I will show you the most popular board game in the Shanghai ...
- Working Experience - WPF XAML 报错 - 命名空间中不存在该名称
问题 编辑 xaml 时,VS 提示一个存在的类不存在(如:命名空间"xxx"中不存在"xxx"名称). 运行环境 Windows 版本:Window 10 V ...
- Shader 模板缓冲和模板测试
http://blog.sina.com.cn/s/blog_6e159df70102xa67.html 模板缓冲的概念 Unity官方的Shader文档根本没有提到这个玩意,这个概念也是看到了UGU ...
- Solr 6.7学习笔记(03)-- 样例配置文件 solrconfig.xml
位于:${solr.home}\example\techproducts\solr\techproducts\conf\solrconfig.xml <?xml version="1. ...
- AcDbHelix Demo
AcDbObjectPointer<AcDbHelix> aHelix; aHelix.create(); aHelix->setAxisPoint(AcGePoint3d(, , ...