javaweb入门20160305---xml的解析入门

package com.itheima.sax; import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler; public class SaxDemo1 {
public static void main(String[] args) throws Exception {
//1.获取解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.通过工厂获取sax解析器
SAXParser parser = factory.newSAXParser();
//3.获取读取器
XMLReader reader = parser.getXMLReader();
//4.注册事件处理器
reader.setContentHandler(new MyContentHandler2() );
//5.解析xml
reader.parse("book.xml"); }
} //适配器设计模式
class MyContentHandler2 extends DefaultHandler{
private String eleName = null;
private int count = 0;
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
this.eleName = name;
} @Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if("书名".equals(eleName) && ++count==2){
System.out.println(new String(ch,start,length));
}
} @Override
public void endElement(String uri, String localName, String name)
throws SAXException {
eleName = null;
} } class MyContentHandler implements ContentHandler{ public void startDocument() throws SAXException {
System.out.println("文档解析开始了.......");
} public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException {
System.out.println("发现了开始标签,"+name);
} public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
} public void endElement(String uri, String localName, String name)
throws SAXException {
System.out.println("发现结束标签,"+name);
} public void endDocument() throws SAXException {
System.out.println("文档解析结束了.......");
} public void endPrefixMapping(String prefix) throws SAXException {
// TODO Auto-generated method stub } public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub } public void processingInstruction(String target, String data)
throws SAXException {
// TODO Auto-generated method stub } public void setDocumentLocator(Locator locator) {
// TODO Auto-generated method stub } public void skippedEntity(String name) throws SAXException {
// TODO Auto-generated method stub } public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// TODO Auto-generated method stub } }
Document document = reader.read(new File("input.xml"));
ele.addElement("age");
Attribute attr= ele.attribute("aaa");
ele.remove(attribute);
Document document = DocumentHelper.parseText(text);
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(node);
writer.close();
XMLWriter writer =
你所应该知道的Dom4J
创建解析器:
SAXReader reader = new SAXReader();
利用解析器读入xml文档:
Document document = reader.read(new File("input.xml"));
获取文档的根节点:
Element root = document.getRootElement();
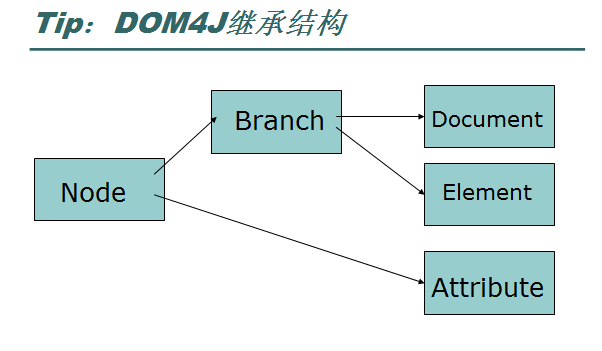
接口继承结构:
Node ---
Branch
--Document
--Element
----
Attribute
Node接口
|
asXML() 将一个节点转换为字符串 |
|
|
getName() 获取节点的名称,如果是元素则获取到元素名,如果是属性获取到属性名 |
|
|
short |
getNodeType() 获取节点类型,在Node接口上定义了一些静态short类型的常量用来表示各种类型 |
|
getParent() 获取父节点,如果是根元素调用则返回null,如果是其他元素调用则返回父元素,如果是属性调用则返回属性所依附的元素。 |
|
|
getText() 返回节点文本,如果是元素则返回标签体,如果是属性则返回属性值 |
|
|
selectNodes(String xpathExpression) 利用xpath表达式,选择节点 |
|
|
void |
setName(String name) 设置节点的名称,元素可以更改名称,属性则不可以,会抛出UnsupportedOperationException 异常 |
|
void |
setText(String text) 设置节点内容,如果是元素则设置标签体,如果是属性则设置属性的值 |
|
void |
write(Writer writer) 将节点写出到一个输出流中,元素、属性均支持 |
Branch接口(实现了Node接口)
|
void |
add(Element element) 增加一个子节点 |
|
addElement(QName qname) 增加一个给定名字的子节点,并且返回这个新创建的节点的引用 |
|
|
int |
indexOf(Node node) 获取给定节点在所有直接点中的位置号,如果该节点不是此分支的子节点,则返回-1 |
|
boolean |
remove(Element element) 删除给定子元素,返回布尔值表明是否删除成功。 |
|
void |
add(Attribute attribute) 增加一个属性 |
|
addAttribute(QName qName, String value) 为元素增加属性,用给定的属性名和属性值,并返回该元素 |
|
|
addAttribute(String name, String value) 为元素增加属性 |
|
|
attribute(int index) 获取指定位置的属性 |
|
|
attribute(QName qName) 获取指定名称的属性 |
|
|
attributeIterator() 获取属性迭代器 |
|
|
attributes() 获取该元素的所有属性,以一个list返回 |
|
|
attributeValue(QName qName) 获取指定名称属性的值,如果不存在该属性返回null,如果存在该属性但是属性值为空,则返回空字符串 |
|
|
element(QName qName) 获取指定名称的子元素,如果有多个该名称的子元素,则返回第一个 |
|
|
element(String name) 获取指定名称的子元素,如果有多个该名称的子元素,则返回第一个 |
|
|
elementIterator() 获取子元素迭代器 |
|
|
elementIterator(QName qName) 获取指定名称的子元素的迭代器 |
|
|
elements() 获取所有子元素,并用一个list返回 |
|
|
elements(QName qName) 获取所有指定名称的子元素,并用一个list返回 |
|
|
getText() 获取元素标签体 |
|
|
boolean |
remove(Attribute attribute) 移除元素上的属性 |
|
void |
setAttributes(List attributes) 将list中的所有属性设置到该元素上 |
Attribute接口(实现了Node接口)
|
getQName() 获取属性名称 |
|
|
getValue() 获取属性的值 |
|
|
void |
setValue(String value) 设置属性的值 |
DocumentHelper 类
|
static Attribute |
createAttribute(Element owner, QName qname, String value) 创建一个Attribute |
|
|
static Document |
创建一个Document |
|
|
static Document |
createDocument(Element rootElement) 以给定元素作为根元素创建Document |
|
|
static Element |
createElement(QName qname) 以给定名称创建一个Element |
|
|
static Document |
parseText(String text) 将一段字符串转化为Document |
将节点写出到XML文件中去
方法1:
调用Node提供的write(Writer writer) 方法,使用默认方式将节点输出到流中:
node.write(new FileWriter("book.xml"));
乱码问题:
Dom4j在将文档载入内存时使用的是文档声明中encoding属性声明的编码集进行编码, 如果在此时使用writer输出时writer使用的内部编码集与encoding不同则会有乱码问题。
FileWriter默认使用操作系统本地码表即gb2312编码,并且无法更改。
此时可以使用OutputStreamWriter(FileOutputStream("filePath"),"utf-8");的方式自己封装 一个指定码表的Writer使用,从而解决乱码问题。
方式2:
利用XMLWriter写出Node:
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(node);
writer.close();
乱码问题:
(1)使用这种方式输出时,XMLWriter首先会将内存中的docuemnt翻译成UTF-8 格式的document,在进行输出,这时有可能出现乱码问题。
可以使用OutputFormat 指定XMLWriter转换的编码为其他编码。
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
(2)Writer使用的编码集与文档载入内存时使用的编码集不同导致乱码,使用字节流 或自己封装指定编码的字符流即可(参照方法1)。
package com.itheima.dom4j; import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; public class Dom4jDemo1 {
public static void main(String[] args) throws Exception {
//1.获取解析器
SAXReader reader = new SAXReader();
//2.解析xml获取代表整个文档的dom对象
Document dom = reader.read("book.xml");
//3.获取根节点
Element root = dom.getRootElement();
//4.获取书名进行打印
String bookName = root.element("书").element("书名").getText();
System.out.println(bookName);
}
}
package com.itheima.dom4j; import java.io.FileOutputStream;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test; public class Demo4jDemo2 {
@Test
public void attr() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement(); Element bookEle = root.element("书");
//bookEle.addAttribute("出版社", "传智出版社");
// String str = bookEle.attributeValue("出版社");
// System.out.println(str);
Attribute attr = bookEle.attribute("出版社");
attr.getParent().remove(attr); XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
} @Test
public void del() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement(); Element price2Ele = root.element("书").element("特价");
price2Ele.getParent().remove(price2Ele); XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
} @Test
public void update()throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement(); root.element("书").element("特价").setText("4.0元"); XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
} @Test
public void add()throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
//凭空创建<特价>节点,设置标签体
Element price2Ele = DocumentHelper.createElement("特价");
price2Ele.setText("40.0元");
//获取父标签<书>将特价节点挂载上去
Element bookEle = root.element("书");
bookEle.add(price2Ele); //将内存中的dom树会写到xml文件中,从而使xml中的数据进行更新
// FileWriter writer = new FileWriter("book.xml");
// dom.write(writer);
// writer.flush();
// writer.close();
XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
} @Test
public void find() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement(); List<Element> list = root.elements();
Element book2Ele = list.get(1);
System.out.println(book2Ele.element("书名").getText()); }
}
javaweb入门20160305---xml的解析入门的更多相关文章
- JavaWeb学习日记----XML的解析
XML的解析简介: 在学习JavaScript时,我们用的DOM来解析HEML文档,根据HTML的层级结构在内存中分配一个树形结构,把HTML的标签啊,属性啊和文本之类的都封装成对象. 比如:docu ...
- Javaweb入门20160301 ---xml入门
一.xml语法 1.文档声明 用来声明xml的基本属性,用来指挥解析引擎如何去解析当前xml 通常一个xml都要包含并且只能包含一个文档声明 xml的文档必须在整个xml的最前面,在文档声明之前不能有 ...
- OkHttp框架从入门到放弃,解析图片使用Picasso裁剪,二次封装OkHttpUtils,Post提交表单数据
OkHttp框架从入门到放弃,解析图片使用Picasso裁剪,二次封装OkHttpUtils,Post提交表单数据 我们这片博文就来聊聊这个反响很不错的OkHttp了,标题是我恶搞的,本篇将着重详细的 ...
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
- SpringBoot快速入门(解析+入门案例源码实现)
这里写目录标题 SpringBoot入门 一.SpringBoot 概念 二.JavaConfig 入门 1. JavaConfig 概念 2. 项目准备 三.常用注解 四.SpringBoot 入门 ...
- JavaWeb学习笔记——XML解析
DOM解析操作 只在跟节点<addresslist>下面建立一个子节点<name> <?xml version="1.0" encoding=&quo ...
- Linux入门:运行级别解析
Linux入门:运行级别解析 一.查看当前运行级别 Ubuntu中,runlevel命令 可以查看当前运行级别: CentOS中,who -r 命令查看当前运行级别: www.2cto.com ...
- Maven入门2-pom.xml文件与settings.xml文件
Maven入门2-pom.xml文件与settings.xml文件 本文内容来源于官网文档部分章节,settings.xml文件:参考http://maven.apache.org/settings. ...
- Spring 入门 web.xml配置详解
Spring 入门 web.xml配置详解 https://www.cnblogs.com/cczz_11/p/4363314.html https://blog.csdn.net/hellolove ...
- 用java实现一个简易编译器1-词法解析入门
本文对应代码下载地址为: http://download.csdn.net/detail/tyler_download/9435103 视频地址: http://v.youku.com/v_show/ ...
随机推荐
- Tdxtreelist 行变色
ACanvas.Font.Color := clRed; //如果有加印的 变颜色
- FZU 2233 ~APTX4869 贪心+并查集
分析:http://blog.csdn.net/chenzhenyu123456/article/details/51308460 #include <cstdio> #include & ...
- UVA 1351 - String Compression
题意: 对于一个字符串中的重复部分可以进行缩写,例如"gogogo"可以写成"3(go)",从6个字符变成5个字符.."nowletsgogogole ...
- [摘]selenium-ide命令
关于,selenium 命令这一部分,为了便于像我一样的菜鸟理解,我采用通过例子讲命令的方式. 菜鸟Selenium 命令通常被称为selenese,有一系列运行测试案例所需的命令构成. ----// ...
- [NOIP2011]瑞士轮
noip2011普及组第3题. 题目背景 在双人对决的竞技性比赛,如乒乓球.羽毛球.国际象棋中,最常见的赛制是淘汰赛和循环赛.前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高.后者的特点是较为公平 ...
- 代码-Weka的LinearRegression类
package kit.weka; import weka.classifiers.Evaluation; import weka.classifiers.functions.LinearRegres ...
- git日常操作
0.准备工作 0.1 git安装 http://git-scm.com/download/ 图形客户端建议使用source tree,中文界面 http://www.sourcetreeapp.c ...
- C++ 类T T t;构造时分配的内存在静态数据区 T t=new T()分配的内存在堆 这样说对吗
C++ 类T T t;构造时分配的内存在静态数据区 T t=new T()分配的内存在堆
- 10个强大的Apache开源模块
1.单点登录模块 LemonLDAP LemonLdap可以很棒地实现Apache的SSO功能,并且可以处理超过 20 万的用户请求.LemonLdap支持Java, PHP, .Net, Perl, ...
- 《Effect Java》学习笔记1———创建和销毁对象
第二章 创建和销毁对象 1.考虑用静态工厂方法代替构造器 四大优势: i. 有名称 ii. 不必在每次调用它们的时候都创建一个新的对象: iii. 可以返回原返回类型的任何子类型的对象: JDBC ...