[Android] 混音器AudioMixer
AudioMixer是Android的混音器,通过混音器可以把各个音轨的音频数据混合在一起,然后输出到音频设备。
创建AudioMixer
AudioMixer在MixerThread的构造函数内创建:
AudioFlinger::MixerThread::MixerThread(...)
{
...
mAudioMixer = new AudioMixer(mNormalFrameCount, mSampleRate);
...
}
这说明了一个MixerThread对应一个AudioMixer。
而且MixerThread传了两个参数给AudioMixer:
- mNormalFrameCount,AudioMixer会根据传进来的mNormalFrameCount作为一次输送数据的长度,把源buffer的音频数据写入目的buffer
- mSampleRate,AudioMixer会把传进来的mSampleRate作为音频数据输出的采样率
配置AudioMixer参数
在上一篇描述MixerThread的时候说过,prepareTrack_l内会配置AudioMixer的参数,现在来详细分析一下各个参数的作用。
mAudioMixer->setBufferProvider(name, track);
设置混音的源buffer,name为传入的索引,track即从mActiveTracks取出来的Track
关于索引name,在这里深入分析,name的获取过程如下:
int name = track->name();
+
+--> int name() const { return mName; }
+
+--> mName = thread->getTrackName_l(channelMask, sessionId);
+
+--> return mAudioMixer->getTrackName(channelMask, sessionId);
+
+--> uint32_t names = (~mTrackNames) & mConfiguredNames;
|
+--> int n = __builtin_ctz(names);
names为索引的集合,names的每一个bit代表不同的索引,names上的某个bit为1,就代表该bit可以取出来作为索引,__builtin_ctz的作用是计算names的低位0的个数,即可以取出最低位为1的bit作为索引。如下:
11111111111111111111000000000000
^
低位有12个0,则取bit12作为索引,那么返回的索引值为1<<12
决定names的参数有两个:
- mTrackNames:用于记录当前的Track,初始值为0。当加入某个Track时,该Track对应的bit会被置为1.
- mConfiguredNames:用于表明该AudioMixer所支持最多的Track数目,如支持最多N个Track,那么mConfiguredNames = 1<<N – 1,此时mConfiguredNames低位的N个bit为1,高位的32-N个bit为0。mConfiguredNames的默认值为-1,即N = 32
mAudioMixer->enable(name);
enable方法只是把track的enabled置为true,然后调用invalidateState(1 << name);表明需要调用刷新函数。
void AudioMixer::enable(int name)
{
name -= TRACK0;
track_t& track = mState.tracks[name]; if (!track.enabled) {
track.enabled = true;
invalidateState(1 << name);
}
}
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, (void *)vl);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, (void *)vr);
分别设置左右声道音量,然后调用invalidateState(1 << name);表明需要调用刷新函数。
case VOLUME0:
case VOLUME1:
if (track.volume[param-VOLUME0] != valueInt) {
ALOGV("setParameter(VOLUME, VOLUME0/1: %04x)", valueInt);
track.prevVolume[param-VOLUME0] = track.volume[param-VOLUME0] << 16;
track.volume[param-VOLUME0] = valueInt;
if (target == VOLUME) {
track.prevVolume[param-VOLUME0] = valueInt << 16;
track.volumeInc[param-VOLUME0] = 0;
}
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::FORMAT, (void *)track->format());
保证传进来的PCM数据为16bit
case FORMAT:
ALOG_ASSERT(valueInt == AUDIO_FORMAT_PCM_16_BIT);
break;
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::CHANNEL_MASK, (void *)track->channelMask());
设置通道数,mask:单音轨(mono),双音轨(stereo)…
case CHANNEL_MASK: {
audio_channel_mask_t mask = (audio_channel_mask_t) value;
if (track.channelMask != mask) {
uint32_t channelCount = popcount(mask);
ALOG_ASSERT((channelCount <= MAX_NUM_CHANNELS_TO_DOWNMIX) && channelCount);
track.channelMask = mask; //设置mask
track.channelCount = channelCount; //更新音轨数目
// the mask has changed, does this track need a downmixer?
initTrackDownmix(&mState.tracks[name], name, mask);
ALOGV("setParameter(TRACK, CHANNEL_MASK, %x)", mask);
invalidateState(1 << name);
}
mAudioMixer->setParameter(
name,
AudioMixer::RESAMPLE,
AudioMixer::SAMPLE_RATE,
(void *)reqSampleRate);
设置当前track的采样频率为reqSampleRate,并要求AudioMixer对当前track进行重采样,输出频率为当前AudioMixer的输出频率mSampleRate。然后调用invalidateState(1 << name);表明需要调用刷新函数。调用过程如下:
mAudioMixer->setParameter(
+ name,
| AudioMixer::RESAMPLE,
| AudioMixer::SAMPLE_RATE,
| (void *)reqSampleRate);
|
+--> track.setResampler(uint32_t(valueInt), mSampleRate)
+
+--> if (sampleRate != value) { //只有输入采样率跟输出采样率不同的时候才会进行重采样
+ if (resampler == NULL) {
| quality = AudioResampler::VERY_HIGH_QUALITY; //高级重采样
| resampler = AudioResampler::create(...); //创建resampler
| }
|}
+--> switch (quality) {
| default:
| case DEFAULT_QUALITY:
| case LOW_QUALITY:
| ALOGV("Create linear Resampler");
| resampler = new AudioResamplerOrder1(bitDepth, inChannelCount, sampleRate);
| break;
| case MED_QUALITY:
| ALOGV("Create cubic Resampler");
| resampler = new AudioResamplerCubic(bitDepth, inChannelCount, sampleRate);
| break;
| case HIGH_QUALITY:
| ALOGV("Create HIGH_QUALITY sinc Resampler");
| resampler = new AudioResamplerSinc(bitDepth, inChannelCount, sampleRate);
| break;
| case VERY_HIGH_QUALITY: //由于我们选择的是VERY_HIGH_QUALITY,所以resampler创建的是AudioResamplerSinc
| ALOGV("Create VERY_HIGH_QUALITY sinc Resampler = %d", quality);
| resampler = new AudioResamplerSinc(bitDepth, inChannelCount, sampleRate, quality);
| break;
| }
|
+--> // initialize resampler
resampler->init();
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MAIN_BUFFER, (void *)track->mainBuffer());
设置目的buffer。然后调用invalidateState(1 << name);表明需要调用刷新函数。
我们追踪一下目的buffer是在哪里创建的:
track->mainBuffer()
+
+--> int16_t *mainBuffer() const { return mMainBuffer; }
mMainBuffer是在track创建的时候就被赋值了
sp<AudioFlinger::PlaybackThread::Track> AudioFlinger::PlaybackThread::createTrack_l(...)
+
+--> track = new Track(...)
+
+--> AudioFlinger::PlaybackThread::Track::Track(...)
+:mMainBuffer(thread->mixBuffer())
|
+--> int16_t *mixBuffer() const { return mMixBuffer; };
thread就是MixerThread,在MixerThread创建的同时,PlaybackThread也一同被创建。在PlaybackThread的构造函数内,申请了一块buffer,并赋值给mMixerBuffer
AudioFlinger::MixerThread::MixerThread
+
+--> AudioFlinger::PlaybackThread::PlaybackThread
+
+--> void AudioFlinger::PlaybackThread::readOutputParameters()
+
+--> mAllocMixBuffer = new int8_t[mNormalFrameCount * mFrameSize + align - 1];
|
+--> mMixBuffer = (int16_t *) ((((size_t)mAllocMixBuffer + align - 1) / align) * align);
这表明了一个AudioMixer对应一个mMixBuffer,经过某个AudioMixer的音频数据最后会汇聚到一个buffer内进行输出
invalidateState
我们上面大量提到了invalidateState可以用来表明需要调用刷新函数,现在来分析一下。
void AudioMixer::invalidateState(uint32_t mask)
{
if (mask) {
mState.needsChanged |= mask; //mask即track->name,表明该track需要被刷新
mState.hook = process__validate;
}
}
由于AudioMixer进行混音处理的时候会调用process方法,而process调用的是mState.hook,所以调用invalidateState,会使得下一次的process函数会调用process__validate进行参数的刷新。process__validate分析如下:
void AudioMixer::process__validate(state_t* state, int64_t pts)
{
ALOGW_IF(!state->needsChanged,
"in process__validate() but nothing's invalid"); uint32_t changed = state->needsChanged; //所有需要invalidate的track都在这里面
state->needsChanged = 0; // clear the validation flag // recompute which tracks are enabled / disabled
uint32_t enabled = 0;
uint32_t disabled = 0;
while (changed) { //对于所有需要invalidate的track,取出来
const int i = 31 - __builtin_clz(changed);
const uint32_t mask = 1<<i;
changed &= ~mask;
track_t& t = state->tracks[i];
(t.enabled ? enabled : disabled) |= mask; //通过track.enabled或者track.disabled来判断该track是否需要混音
}
state->enabledTracks &= ~disabled; //disabled mask
state->enabledTracks |= enabled; //enabled mask // compute everything we need...
int countActiveTracks = 0;
bool all16BitsStereoNoResample = true;
bool resampling = false;
bool volumeRamp = false;
uint32_t en = state->enabledTracks;
while (en) { //对所有需要进行混音的track
const int i = 31 - __builtin_clz(en); //取出最高位为1的bit
en &= ~(1<<i); //把这一位置为0 countActiveTracks++;
track_t& t = state->tracks[i]; //取出来track
uint32_t n = 0;
n |= NEEDS_CHANNEL_1 + t.channelCount - 1; //至少有一个channel需要混音
n |= NEEDS_FORMAT_16; //必须为16bit PCM
n |= t.doesResample() ? NEEDS_RESAMPLE_ENABLED : NEEDS_RESAMPLE_DISABLED; //是否需要重采样
if (t.auxLevel != 0 && t.auxBuffer != NULL) {
n |= NEEDS_AUX_ENABLED;
} if (t.volumeInc[0]|t.volumeInc[1]) {
volumeRamp = true;
} else if (!t.doesResample() && t.volumeRL == 0) {
n |= NEEDS_MUTE_ENABLED;
}
t.needs = n; //更新track flag
//下面为设置track的混音方法
if ((n & NEEDS_MUTE__MASK) == NEEDS_MUTE_ENABLED) { //mute
t.hook = track__nop;
} else {
if ((n & NEEDS_AUX__MASK) == NEEDS_AUX_ENABLED) {
all16BitsStereoNoResample = false;
}
if ((n & NEEDS_RESAMPLE__MASK) == NEEDS_RESAMPLE_ENABLED) { //重采样
all16BitsStereoNoResample = false;
resampling = true;
t.hook = track__genericResample;
ALOGV_IF((n & NEEDS_CHANNEL_COUNT__MASK) > NEEDS_CHANNEL_2,
"Track %d needs downmix + resample", i);
} else {
if ((n & NEEDS_CHANNEL_COUNT__MASK) == NEEDS_CHANNEL_1){ //单声道
t.hook = track__16BitsMono;
all16BitsStereoNoResample = false;
}
if ((n & NEEDS_CHANNEL_COUNT__MASK) >= NEEDS_CHANNEL_2){ //双声道
t.hook = track__16BitsStereo;
ALOGV_IF((n & NEEDS_CHANNEL_COUNT__MASK) > NEEDS_CHANNEL_2,
"Track %d needs downmix", i);
}
}
}
} // select the processing hooks //下面为设置整体的混音方法,一个process__xxx内会循环调用track_xxx
state->hook = process__nop;
if (countActiveTracks) {
if (resampling) { //重采样,需要多一块重采样buffer
if (!state->outputTemp) {
state->outputTemp = new int32_t[MAX_NUM_CHANNELS * state->frameCount];
}
if (!state->resampleTemp) {
state->resampleTemp = new int32_t[MAX_NUM_CHANNELS * state->frameCount];
}
state->hook = process__genericResampling;
} else {
if (state->outputTemp) {
delete [] state->outputTemp;
state->outputTemp = NULL;
}
if (state->resampleTemp) {
delete [] state->resampleTemp;
state->resampleTemp = NULL;
}
state->hook = process__genericNoResampling; //双声道process
if (all16BitsStereoNoResample && !volumeRamp) {
if (countActiveTracks == 1) {
state->hook = process__OneTrack16BitsStereoNoResampling; //单声道process
}
}
}
} ALOGV("mixer configuration change: %d activeTracks (%08x) "
"all16BitsStereoNoResample=%d, resampling=%d, volumeRamp=%d",
countActiveTracks, state->enabledTracks,
all16BitsStereoNoResample, resampling, volumeRamp); state->hook(state, pts); //这里调用一次进行混音,后续会在MixerThread的threadLoop_mix内调用 // Now that the volume ramp has been done, set optimal state and
// track hooks for subsequent mixer process
if (countActiveTracks) {
bool allMuted = true;
uint32_t en = state->enabledTracks;
while (en) {
const int i = 31 - __builtin_clz(en);
en &= ~(1<<i);
track_t& t = state->tracks[i];
if (!t.doesResample() && t.volumeRL == 0)
{
t.needs |= NEEDS_MUTE_ENABLED;
t.hook = track__nop;
} else {
allMuted = false;
}
}
if (allMuted) {
state->hook = process__nop;
} else if (all16BitsStereoNoResample) {
if (countActiveTracks == 1) {
state->hook = process__OneTrack16BitsStereoNoResampling;
}
}
}
}
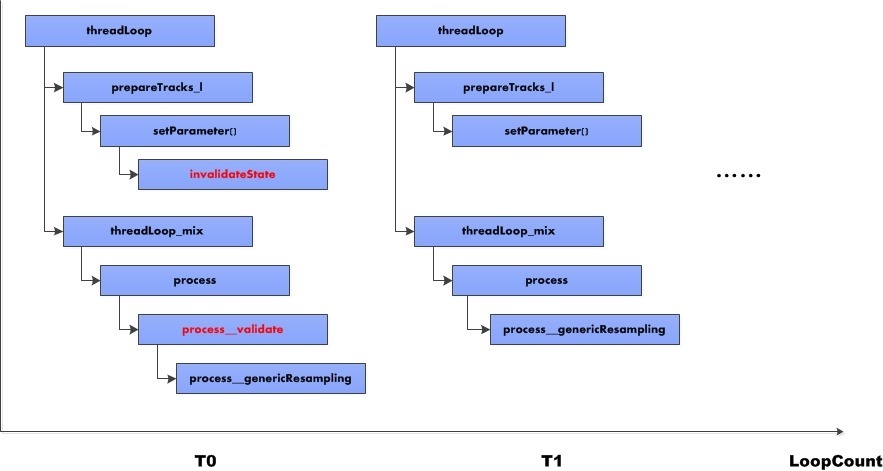
AudioMixer混音
关于混音,我们已经知道:混音以track为源,mainBuffer为目标,frameCount为一次混音长度。AudioMixer最多能维护32个track。track可以对应不同mainBuffer,尽管一般情况下他们的mainBuffer都是同一个。

在分析MixerThread时说过,我们调用AudioMixer的process方法进行混音的,实际上混音的方法是调用AudioMixer内的process_xxx方法,各个process方法大同小异。下面来分析process__genericResampling这个方法。
// generic code with resampling
void AudioMixer::process__genericResampling(state_t* state, int64_t pts)
{
// this const just means that local variable outTemp doesn't change
int32_t* const outTemp = state->outputTemp; //重采样缓存
const size_t size = sizeof(int32_t) * MAX_NUM_CHANNELS * state->frameCount; size_t numFrames = state->frameCount; uint32_t e0 = state->enabledTracks;
while (e0) {
// process by group of tracks with same output buffer
// to optimize cache use
uint32_t e1 = e0, e2 = e0;
int j = 31 - __builtin_clz(e1);
track_t& t1 = state->tracks[j]; //取出第一个track t1
e2 &= ~(1<<j); //除了t1之外,其余的track的索引都在e2内 //对于其他的track,通过循环取出来,赋值为t2,如果t2的目标buffer与t1的不同,则把t2从e1的集合中去掉
//这么做就是为了把相同目标buffer的track取出来,一起进行混音,因为不同目标buffer的track是要混音输出到不同buffer的
//不过实际上一般都会有相同的目标buffer,如MixerThread设定了mMixBuffer作为track的目标buffer
//如果设定了eq(AudioEffect)那就有可能会出现不同目标buffer的情况?
while (e2) {
j = 31 - __builtin_clz(e2);
e2 &= ~(1<<j);
track_t& t2 = state->tracks[j];
if (CC_UNLIKELY(t2.mainBuffer != t1.mainBuffer)) {
e1 &= ~(1<<j);
}
}
e0 &= ~(e1);
int32_t *out = t1.mainBuffer;
memset(outTemp, 0, size);
while (e1) { //对于e1内的所有track,调用t.hook进行混音
const int i = 31 - __builtin_clz(e1);
e1 &= ~(1<<i);
track_t& t = state->tracks[i];
int32_t *aux = NULL;
if (CC_UNLIKELY((t.needs & NEEDS_AUX__MASK) == NEEDS_AUX_ENABLED)) {
aux = t.auxBuffer;
} // this is a little goofy, on the resampling case we don't
// acquire/release the buffers because it's done by
// the resampler.
if ((t.needs & NEEDS_RESAMPLE__MASK) == NEEDS_RESAMPLE_ENABLED) {
ALOGE("[%s:%d]", __FUNCTION__, __LINE__);
t.resampler->setPTS(pts);
t.hook(&t, outTemp, numFrames, state->resampleTemp, aux); //实际上重采样会走这里,然后输出到重采样buffer,outTemp
} else { size_t outFrames = 0; ALOGE("[%s:%d]", __FUNCTION__, __LINE__);
while (outFrames < numFrames) {
t.buffer.frameCount = numFrames - outFrames;
int64_t outputPTS = calculateOutputPTS(t, pts, outFrames);
t.bufferProvider->getNextBuffer(&t.buffer, outputPTS);
t.in = t.buffer.raw;
// t.in == NULL can happen if the track was flushed just after having
// been enabled for mixing.
if (t.in == NULL) break; if (CC_UNLIKELY(aux != NULL)) {
aux += outFrames;
}
t.hook(&t, outTemp + outFrames*MAX_NUM_CHANNELS, t.buffer.frameCount,
state->resampleTemp, aux);
outFrames += t.buffer.frameCount;
t.bufferProvider->releaseBuffer(&t.buffer);
}
}
}
ditherAndClamp(out, outTemp, numFrames); //把重采样buffer内的数据输出到out,即目标buffer
}
}
在process__invalidate时,设置了重采样时track.hook函数为track__genericResample,下面看一下这个函数做了什么
void AudioMixer::track__genericResample(track_t* t, int32_t* out, size_t outFrameCount,
int32_t* temp, int32_t* aux)
{
//设置输入采样率
t->resampler->setSampleRate(t->sampleRate); // ramp gain - resample to temp buffer and scale/mix in 2nd step
if (aux != NULL) {
// always resample with unity gain when sending to auxiliary buffer to be able
// to apply send level after resampling
// TODO: modify each resampler to support aux channel?
t->resampler->setVolume(UNITY_GAIN, UNITY_GAIN);
memset(temp, 0, outFrameCount * MAX_NUM_CHANNELS * sizeof(int32_t));
t->resampler->resample(temp, outFrameCount, t->bufferProvider);
if (CC_UNLIKELY(t->volumeInc[0]|t->volumeInc[1]|t->auxInc)) {
volumeRampStereo(t, out, outFrameCount, temp, aux);
} else {
volumeStereo(t, out, outFrameCount, temp, aux);
}
} else {
if (CC_UNLIKELY(t->volumeInc[0]|t->volumeInc[1])) {
t->resampler->setVolume(UNITY_GAIN, UNITY_GAIN);
memset(temp, 0, outFrameCount * MAX_NUM_CHANNELS * sizeof(int32_t));
t->resampler->resample(temp, outFrameCount, t->bufferProvider);
volumeRampStereo(t, out, outFrameCount, temp, aux);
} // constant gain
else {
//设置音量
t->resampler->setVolume(t->volume[0], t->volume[1]);
//进行重采样
t->resampler->resample(out, outFrameCount, t->bufferProvider);
}
}
}
最终调用了resampler的resample方法进行重采样
[Android] 混音器AudioMixer的更多相关文章
- [Android] 获取音频输出getOutput
每创建一个AudioTrack,代表需要新增一个输出实例,即需要根据音频流的的stream type,音频流的音轨数量,采样率,位宽等数据来重新构建buffer,而且输出的设备也可能会有变化,由于An ...
- unity5x --------Music Mixer参数详解
我们一直在致力开发出业界最顶尖水准音频处理功能,而经过很长一段时间的努力,在Unity5.0中,音频处理功能将成为非常重点的一个功能. 要达成这个目标,我们首先重写了很多Unity中音频相关得处理 ...
- Android 音频播放分析笔记
AudioTrack是Android中比较偏底层的用来播放音频的接口,它主要被用来播放PCM音频数据,和MediaPlayer不同,它不涉及到文件解析和解码等复杂的流程,比较适合通过它来分析Andro ...
- [深入理解Android卷一全文-第七章]深入理解Audio系统
由于<深入理解Android 卷一>和<深入理解Android卷二>不再出版,而知识的传播不应该由于纸质媒介的问题而中断,所以我将在CSDN博客中全文转发这两本书的全部内容. ...
- Android 开发之 ---- 底层驱动开发(一) 【转】
转自:http://blog.csdn.net/jmq_0000/article/details/7372783 版权声明:本文为博主原创文章,未经博主允许不得转载. 驱动概述 说到 Android ...
- [转]Android音频底层调试-基于tinyalsa
http://blog.csdn.net/kangear/article/details/38139669 [-] 编译tinyalsa配套工具 查看当前系统的声卡 tinymix查看混响器 使用ti ...
- Android 开发之 ---- 底层驱动开发(一)
驱动概述 说到 android 驱动是离不开 Linux 驱动的.Android 内核采用的是 Linux2.6 内核 (最近Linux 3.3 已经包含了一些 Android 代码).但 Andro ...
- Android音频底层调试-基于tinyalsa
因为Android中默认并没有使用标准alsa,而是使用的是tinyalsa.所以就算基于命令行的測试也要使用libtinyalsa.Android系统在上层Audio千变万化的时候,能够能这些个工具 ...
- 3.android下Makefile编写规范
随着移动互联网的发展,移动开发也越来越吃香了,目前最火的莫过于android,android是什么就不用说了,android自从开源以来,就受到很多人的追捧.当然,一部人追捧它是因为它是Google开 ...
随机推荐
- 火球-UML大战需求分析(体验版3.0.2).pdf
火球-UML大战需求分析(体验版3.0.2).pdf http://files.cnblogs.com/files/happlyonline/%E7%81%AB%E7%90%83-UML%E5%A4% ...
- rsyslogd配置文件详解
非常详细的rsyslogd配置文件解析 rsyslog服务和logrotate服务=========================================================== ...
- 第十四章 红黑树——C++代码实现
红黑树的介绍 红黑树(Red-Black Tree,简称R-B Tree),它一种特殊的二叉查找树.红黑树是特殊的二叉查找树,意味着它满足二叉查找树的特征:任意一个节点所包含的键值,大于等于左孩子的键 ...
- 深入探索C++对象模型-5
虚拟继承下的对象构造: 由于虚拟基类对象在子类中只能保持一个实例,那么,子类构造的时候调用父类的构造函数的时候必须保证虚拟基类对象不能够重复构造. 那么如何保证基类对象的唯一性? C++规定虚拟基类对 ...
- python-Pickle序列化
[Python之旅]第三篇(二):Pickle序列化 python 序列化 pickle 摘要: 说明:关于Pickle的说明 作如下说明: 1 2 3 4 5 6 7 序列化的概念很简单 ...
- 2015-09-22CSS:border、background、表格、超链接、overflow、firebug
1.CSS的border属性 ⑴定义和用法 border 简写属性在一个声明设置所有的边框属性. 可以按顺序设置如下属性: border-width border-style border-color ...
- OpenXmlSdk导出Excel
感觉OpenXmlSdk的语法真的不是很友好.研究了半天,只实现了简单的导出功能.对于单元格样式的设置暂时还是搞明白,网上的资料真的很少,官方文档是英文的.中文的文章大都是用工具(Open XML S ...
- Struts2 删除后直接直接到List显示页面
package com.sun; import java.util.List; import java.util.Map; import org.hibernate.Session; import o ...
- 用js给html设置style
[html] view plaincopyprint? 原贴地址:<a href="http://heichong.iteye.com/blog/860698">htt ...
- web.xml配置详解 (及<context-param>配置作用 )
http://blog.csdn.net/guihaijinfen/article/details/8363839 <context-param>配置作用 http://blog.csdn ...