java_log_01
logback&slf4j(本文中的版本为logback1.1.7.slf4j1.7.21),参照
原作者:Ceki Gülcü、Sébastien Pennec
中文版译者:陈华
联系方式:clinker@163.com
一,入门
1.什么是日志,它能干什么?
对于日志:如果是小程序就不是必须的了如果是大点的程序,日志就非常有用了
日志的作用:主要在维护的时候非常有用,系统可能会出一些其名其秒的错误,这个时候如果日志做的比较详细就能很清楚的查找到错误了
举个简单的例子:
志主要是用户操作的记录
也可以作为日后处理问题的一个追溯
可以根据日志来进行统计和查询问题等等、
比如说你提供一个绑定邮箱的功能
日志可能就需要记录一下信息:
谁 何时 做了什么 成功或失败
张三 2011-12-26 11:07 绑定邮箱 成功
张二 2011-11-26 11:07 绑定邮箱 失败
以后你就可以通过各个字段的信息来进行统计成功或者失败的用户 或者某个时间段做了什么操作的用户
2.按照常规,首先来看一下我们的hello world
一,环境搭建:个人是用的Maven项目
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.wy</groupId>
<artifactId>testLog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>testLog</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<!-- https://mvnrepository.com/artifact/ch.qos.logback/logback-classic -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/ch.qos.logback/logback-core -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.1.7</version>
</dependency>
</dependencies>
</project>
二,HelloWorld
package test03; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class HelloWorld {
static Logger logger = LoggerFactory.getLogger("this is my Hello world");
public static void main(String[] args) {
logger.debug("Hello world.");
}
}
三,运行结果:

HelloWorld 类导入了 SLF4J API 定义的 Logger 类和 LoggerFactory 类,更明确地说是
定义在 org.slf4j 包里的两个类。
main()方法的第一行里,调用 LoggerFactory 类的静态方法 getLogger 取得一个 Logger
实例, 将该实例赋值给变量logger。 这个 logger被命名为 “this is my Hello world” 。main 方法继续调用这个 logger 的 debug 方法并传递参数“Hello world” 。我们称之为 main方法包含了一条消息是“Hello world” 、级别是 DEBUG 的记录语句。注意上面的例子并没有引用任何 logback 的类。多数情况下,只要涉及到记录,你只需要引用 SLF4J 的类。因此在绝大多数情况下,你的类只导入 SLF4J 的 API,基本可以忽略logback 的存在。
StatusManager
Logback 可以通过内置的状态系统来报告其内部状态。通过 StatusManager 组件可以访
问 logback 生命期内发生的重要事件。目前,我们调用 StatusPrinter 类的 print()方法来打印
logback 的内部状态。
package test01; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import ch.qos.logback.classic.LoggerContext;
import ch.qos.logback.core.util.StatusPrinter; public class HelloWorld1 {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(HelloWorld1.class); logger.debug("Hello world.");
LoggerContext context=(LoggerContext) LoggerFactory.getILoggerFactory();
StatusPrinter.print(context);
}
}
运行结果:

Logback 说它没有找到配置文件 logback-test.xml 和 logback.xml(稍后解释) ,于是用默
认策略进行配置,即用一个基本的 ConsoleAppender。Appender 类可被视为输出目的地的。
Appender 包含许多不同类型的目的地,包括控制台、文件、Syslog、TCP 套接字、JMS 和
其他。用户可以很容易地自定义 Appender。
当发生错误时,logback 将自动在控制台上打印其内部状态。
之前的两个示例相当简单, 大型程序里真实记录志情况也不会有太大区别。 记录系统的
基本模式不会改变, 可能改变的是配置过程。 也许你想按照自己的需要来定制或配置 logback,
之后的章节会讨论配置 logback。
在上面的例子里,我们调用 StatusPrinter.pring()方法来打印 logback 的内部状态。在诊
断与 logback 相关的问题时,logback 的内部状态信息会非常有用。
在应程序里启用记录的三个必需步骤如下:
1. 配置 logback 环境。方法有繁有简,稍后讨论。
2. 在每个需要执行记录的类里,调用 org.slf4j.LoggerFactory 类的 getLogger()方法获
取一个 Logger 实例,以当前类名或类本身作为参数。
3. 调用取得的 logger 实例的打印方法,即 debug()、info()、warn()和 error(),把记录
输出到配置里的各 appender。
二,体系:
1.logback 的体系结构
Logback 的基本结构充分通用, 可应用于各种不同环境。 目前, logback 分为三个模块:
Core、Classic 和 Access。
Core模块是其他两个模块的基础。 Classic 模块扩展了core模块。 Classic 模块相当于 log4j
的显著改进版。Logback-classic 直接实现了 SLF4J API,因此你可以在 logback 与其他记录
系统如 log4j 和 java.util.logging (JUL)之间轻松互相切换。Access 模块与 Servlet 容器集成,
提供 HTTP 访问记录功能。本文不讲述 access 模块。
本文中, “logback”代表 logback-classic 模块
2. Logger 、Appender 和 和 Layout
Logback 建立于三个主要类之上:Logger、Appender 和 Layout。这三种组件协同工作,
使开发者可以按照消息类型和级别来记录消息, 还可以在程序运行期内控制消息的输出格式
和输出目的地。
Logger类是logback-classic 模块的一部分, 而Appender和Layout接口来自logback-core。
作为一个多用途模块,logback-core 不包含任何 logger。
Logger 上下文
任何比System.out.println高级的记录API的第一个也是最重要的优点便是能够在禁用特
定记录语句的同时却不妨碍输出其他语句。这种能力源自记录隔离(space)——即所有各
种记录语句的隔离——是根据开发者选择的条件而进行分类的。在 logback-classic 里,这种
分类是 logger 固有的。各个 logger 都被关联到一个 LoggerContext,LoggerContext 负责制造
logger,也负责以树结构排列各 logger。
Logger 是命名了的实体。它们的名字大小写敏感且遵从下面的层次化的命名规则:
命名层次:
如果 logger 的名称带上一个点号后是另外一个 logger 的名称的前缀,那么, 前者 就被
称为 后者的祖先。 如果 logger 与代 其后代 logger 之间没有其他祖先, 那么,前者就被称为子
logger 之 父。比如:
名为 “com.foo"” 的 logger 是名为 “com.foo.Bar” 之父。 同理, “java” 是 “java.util"”
之父,也是“java.util.V ector”的祖先。
根 logger 位于 logger 等级的最顶端,它的特别之处是它是每个层次等级的共同始祖。
如同其他各 logger,根 logger 可以通过其名称取得,如下所示:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);
其他所有 logger 也通过 org.slf4j.LoggerFactory 类的静态方法 getLogger 取得。 getLogger
方法以 logger 名称为参数。Logger 接口的部分基本方法列举如下:
public interface Logger {
// Printing methods:
public void trace(String message);
public void debug(String message);
public void info(String message);
public void warn(String message);
public void error(String message);
}
有效 级别(Level ) 即 级别 继承
Logger 可以被分配级别。级别包括:TRACE、DEBUG、INFO、WARN 和 ERROR,定
义于 ch.qos.logback.classic.Level 类。注意在 logback 里,Level 类是 final 的,不能被继承,
Marker 对象提供了更灵活的方法。
如果 logger 没有被分配级别,那么它将从有被分配级别的最近的祖先那里继承级别。
更正式地说:
logger L 的有效级别 等于其层次等级里的第一个非 null 级别, 顺序是从 从 L 开始, 向上
直至根 根 logger 。
为确保所有 logger 都能够最终继承一个级别,根 logger 总是有级别,默认情况下,这
个级别是 DEBUG。
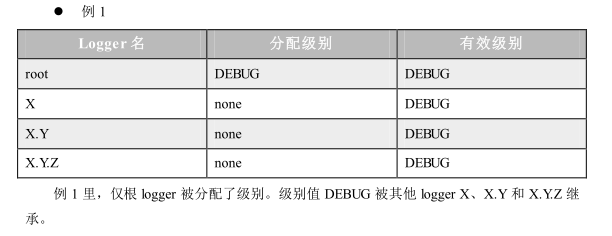
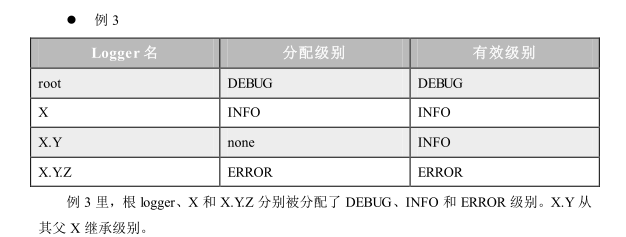
下面的四个例子包含各种分配级别值和根据级别继承规则得出的最终有效 (继承) 级别。


打印方法和基本选择规则
根据定义,打印方法决定记录请求的级别。例如,如果 L 是一个 logger 实例,那么,
语句 L.info("..")是一条级别为 INFO 的记录语句
记录请求的级别在高于或等于其 logger 的有效级别时被称为被启用,否则,称为被禁
用。如前所述,没有被分配级别的 logger 将从其最近的祖先继承级别。该规则总结如下:
基本 选择规则
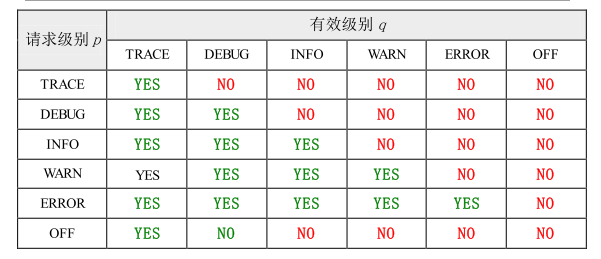
记录为 请求级别为 p , 其 logger 的有效级别为 为 q, 只有则当 p>=q, 时, 该请求才会被执行。
该规则是 logback 的核心。 级别排序为: TRACE < DEBUG < INFO < WARN < ERROR。
下表显示了选择规则是如何工作的。行头是记录请求的级别 p。列头是 logger 的有效级
别 q。行(请求级别)与列(有效级别)的交叉部分是按照基本选择规则得出的布尔值。
下面举个关于上述级别的例子:
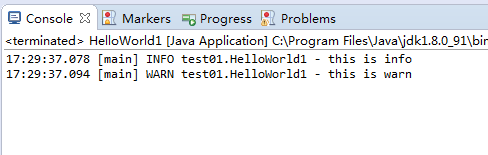
package test01; import org.slf4j.LoggerFactory; import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger; public class HelloWorld1 {
public static void main(String[] args) {
//注意这里的Logger不是slf4j中的Logger---ch.qos.logback.classic.Logger;
Logger logger = (Logger) LoggerFactory.getLogger(HelloWorld1.class);
//设置logger的日志级别为INFO
logger.setLevel(Level.INFO);
//这条请求为info满足,将会打印
logger.info("this is info");
//这条请求为warn>info满足,将会打印
logger.warn("this is warn");
//这条请求为debug<info不满足,不会打印
logger.debug("this is debug"); }
}
运行结果:
获取 Logger
用同一名字调用 LoggerFactory.getLogger 方法所得到的永远都是同一个 logger 对象的引
用。
package test01; import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class Test01 { @Test
public void test() {
Logger x = LoggerFactory.getLogger("wombat");
Logger y = LoggerFactory.getLogger("wombat");
System.out.println(x==y);//true
} }
因此,可以配置一个 logger,然后从其他地方取得同一个实例,不需要到处传递引用。
生物学里的父母总是先于其孩子,而 logback 不同,它可以以任何顺序创建和配置 logger。
特别的是,即使“父”logger 是在其后代初始化之后才初始化的,它仍将查找并链接到其后代们.
通常是在程序初始化时对 logback 环境进行配置。推荐用读配置文件类进行配置。稍后
会讲这种方法。
Logback 简化了 logger 命名,方法是在每个类里初始化 logger,以类的全限定名作为
logger 名。这种定义 logger 的方法即有用又直观。由于记录输出里包含 logger 名,这种命名
方法很容易确定记录消息来源。Logback 不限制 logger 名,你可以随意命名 logger。
然而,目前已知最好的策略是以 logger 所在类的名字作为 logger 名称。
Appender 和 Layout
有选择性地启用或禁用记录请求仅仅是 logback 功能的冰山一角。Logback 允许打印记
录请求到多个目的地。在 logback 里,一个输出目的地称为一个 appender。目前有控制台、
文件、 远程套接字服务器、 MySQL、 PostreSQL、 Oracle和其他数据库、 JMS和远程UNIX Syslog
守护进程等多种 appender。
一个 logger 可以被关联多个 appender。
方法 addAppender 为指定的 logger 添加一个 appender。 对于 logger 的每个启用了的记录
请求,都将被发送到 logger 里的全部 appender 及更高等级的 appender。换句话说,appender
叠加性地继承了 logger 的层次等级。例如,如果根 logger 有一个控制台 appender,那么所有
启用了的请求都至少会被打印到控制台。如果 logger L 有额外的文件 appender,那么,L 和
L后代的所有启用了的请求都将同时打印到控制台和文件。 设置 logger 的 additivity 为 false,
则可以取消这种默认的 appender 累积行为。
控制 appender 叠加性的规则总结如下:
Appender的添加性:
Logger L 的记录 语句的输出会发送给 L 及其祖先的全部 appender。 。 这就是“appender
叠加性”的含义。
然而,果 如果 logger L 的某个祖先 P 设置叠加性标识为 false ,那么,L 的输出会发送给L 与 与 P 之间(含 P )的所有 appender ,但不会发送给 P 的任何祖先的 appender
Logger 的叠加性默认为 true。

有些用户希望不仅可以定制输出目的地,还可以定制输出格式。这时为 appender 关联
一个 layout 即可。 Layout 负责根据用户意愿对记录请求进行格式化, appender 负责将格式化
化后的输出发送到目的地。PatternLayout 是标准 logback 发行包的一部分,允许用户按照类
似于 C 语言的 printf 函数的转换模式设置输出格式。
例如, 转换模式"%-4relative [%thread] %-5level %logger{32} - %msg%n"在 PatternLayout
里会输出形如:
[main] DEBUG manual.architecture.HelloWorld2 - Hello world
第一个字段是自程序启动以来的逝去时间,单位是毫秒。
第二个地段发出记录请求的线程。
第三个字段是记录请求的级别。
第四个字段是与记录请求关联的 logger 的名称。
“-”之后是请求的消息文字。
这种后面会在配置文件中体现
参数化记录:
因为 logback-classic 里的 logger 实现了 SLF4J 的 Logger 接口,某些打印方法可接受多
个参数。这些不同的打印方法主要是为了在提高性能的同时尽量不影响代码可读性。
对于某个 Logger,下面的代码
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
在构造消息参数时有性能消耗, 即把整数 i 和 entry[i]都转换为字符串时, 还有连接多个
字符串时。不管消息会不会被记录,都会造成上述消耗。
一个可行的办法是用测试语句包围记录语句以避免上述消耗,比如,
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
当 logger 的 debug 级别被禁用时, 这个方法可以避免参数构造带来的性能消耗。 另一方
面,如果 logger 的 DEBUG 级别被启用,那么会导致两次评估 logger 是否被启用:一次是
isDebugEnabled 方法, 一次是 debug 方法。 在实践中, 这种额外开销无关紧要, 因为评估 logger
所消耗的时间不足实际记录请求所用时间的 1%。
更好的替代方法
还有一种基于消息格式的方便的替代方法。假设 entry 是一个 object,你可以编写:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
在评估是否作记录后,仅当需要作记录时,logger 才会格式化消息,用 entry 的字符串
值替换"{}"。换句话说,当记录语句被禁用时,这种方法不会产生参数构造所带来的性能消
耗。
工作原理
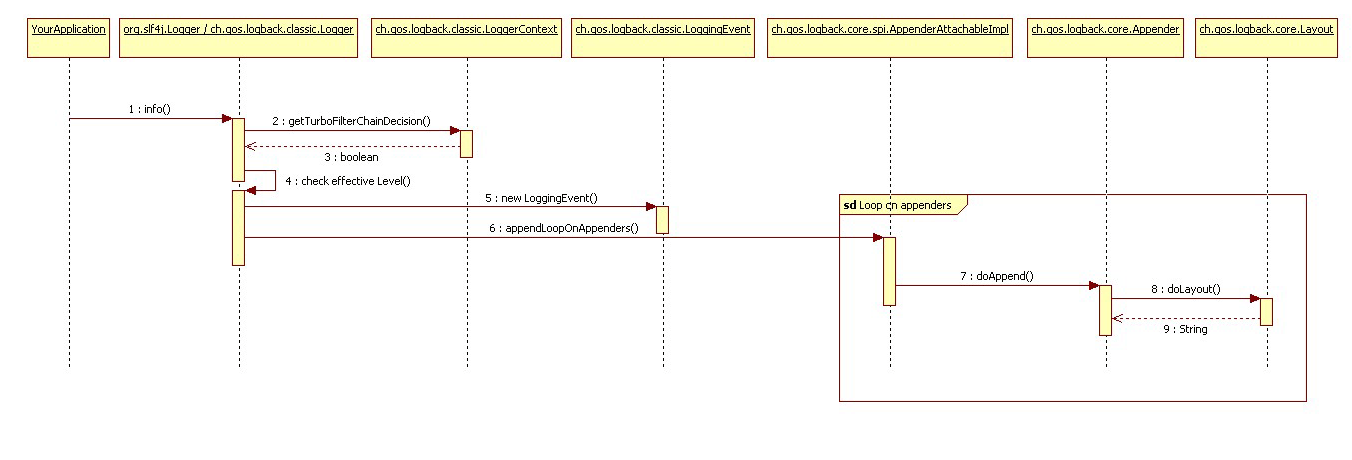
介绍过 logback 的核心组件后,下面描述 logback 框架在用户调用 logger 的打印方法时
所做的事情。在本例中,用户调用名为 com.wombat 的 logger 的 info()方法。
1. 取得过滤链(filter chain)的判定结果
如果 TurboFilter 链存在,它将被调用。Turbo filters 能够设置一个上下文范围内的
临界值,这个临界值或者表示过滤某些与信息有关(比如 Marker、级别、Logger、
消息)的特定事件,或者表示与每个记录请求相关联的 Throwable。如果过滤链的
结果是 FilterReply.DENY, 则记录请求被抛弃。 如果结果是 FilterReply.NEUTRAL,
则继续下一步, 也就是第二步。 如果结果是 FilterReply.ACCEPT, 则忽略过第二步,
进入第三步。
2. 应用基本选择规则
Logback 对 logger 的有效级别与请求的级别进行比较。 如果比较的结果是记录请求
被禁用,logback 会直接抛弃请求,不做任何进一步处理。否则,继续下一步。
3. 创建 LoggingEvent 对象
记录请求到了这一步后, logback 会创建一个 ch.qos.logback.classic.LoggingEvent 对
象,该对象包含所有与请求相关的参数,比如请求用的 logger、请求级别、消息、
请求携带的异常、 当前时间、 当前线程、 执行记录请求的类的各种数据, 还有 MDC。
注意有些成员是延迟初始化的,只有当它们真正被使用时才会被初始化。MDC 用
来为记录请求添加额外的上下文信息。之后的章节会讨论 MDC。
4. 调用 appender
创建了 LoggingEvent 对象后, logback 将调用所有可用 appender 的 doAppend()方法,
这就是说,appender 继承 logger 的上下文。
所有 appender 都继承 AppenderBase 抽象类,AppenderBase 在一个同步块里实现了
doAppend 方以确保线程安全。AppenderBase 的 doAppender()方法也调用 appender
关联的自定义过滤器,如果它们存在的话。自定义过滤器能被动态地关联到任何
appender,另有章节专门讲述它。
5. 格式化输出
那些被调用了的 appender 负责对记录事件(LoggingEvent)进行格式化。然而,有
些但不是全部 appender 把格式化记录事件的工作委托给 layout。Layout 对
LoggingEvent 实例进行格式化,然后把结果以字符串的形式返回。注意有些
appender,比如 SocketAppender,把记录事件进行序列化而不是转换成字符串,所
以它们不需要也没有 layout。
6. 发送记录事件(LoggingEvent)
记录事件被格式化后,被各个 appender 发送到各自的目的地。
下图是整个流程的 UML 图。(http://logback.qos.ch/manual/underTheHood.html)
性能
一个关于记录的常见争论是它的计算代价。 这种关心很合理, 因为即使是中等大小的应
用程序也会生成数以千计的记录请求。 人们花了很多精力来测算和调整记录性能。 尽管如此,
用户还是需要注意下面的性能问题。
1. 记录被彻底关闭时的记录性能
你可以将根 logger 的级别设为最高级的 Level.OFF,就可以彻底关闭记录。当记录
被彻底关闭时,记录请求的消耗包括一次方法调用和一次整数比较。在 CPU 为
3.2Ghz 的 Pentium D 电脑上,一般需要 20 纳秒。
但是,任何方法调用都会涉及“隐藏的” 参数构造消耗,例如,对于 logger x,
x.debug("Entry number: " + i + "is " + entry[i]);
把整数 i 和 entry[i]都转换为字符串和连接各字符串会造成消息参数构造消耗, 不管
消息是否被记录。
参数构造消耗可以变得非常高,同时也跟参数大小有关。利用 SLF4J 的参数化记
录可以避免这种消耗。
x.debug("Entry number: {} is {}", i, entry[i]);
这种方式不会造成参数构造消耗。与前面的 debug()方法相比,这种方法快得多。
只有当请求在被发送给 appender 时,消息才会被格式化。在格式化的时候,负责
格式化消息的组件性能很高, 不会对整个过程造成负面影响。 格式化 1 个和 3 个参
数分别需要 2 和 4 微妙。
请注意,无论如何,应当避免在紧密循环里或者非常频繁地调用记录语句,因为很
可能降低性能。即使记录被禁用,在紧密循环里作记录仍然会拖慢应用程序,如果
记录被启用,就会产生大量(也是无用的)输出。
2. 当记录启用时,判断是否进行记录的性能
在 logback 中, logger 在被创建时就明确地知道其有效级别 (已经考虑了级别继承) 。
当父 logger 的级别改变时,所有子 logger 都会得知这个改变。因此,在根据有效
级别去接受或拒绝请求之前,logger 能够作出准即时判断,不需要咨询其祖先。
3. 实际记录(格式化和写入输出设备)
性能消耗包括格式化肌瘤输出和发送到目的地。我们努力使 layout(formatter)和
appender都尽可能地快。 记录到本地机器的文件里的耗时一般大约在 9至12微秒。
如果目的地是远程服务器上的数据库时,会增加早几个毫秒。
尽管功能丰富,logback 最首要的一项设计目标就是执行速度,重要程度仅排在可靠性
之后。为提高性能,logback 的一些组件已经被多次重写
java_log_01的更多相关文章
随机推荐
- 安装配置MongoDB
1.下载mongodb https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.6.8.tgz 2.解压 tar zxf mongodb-lin ...
- Delphi生成GUID
Delphi生成GUID Uses ComObj; Var aGUID: string; aGUID := GetClassId; // 取得GUID
- HDOJ(HDU) 2135 Rolling table
Problem Description After the 32nd ACM/ICPC regional contest, Wiskey is beginning to prepare for CET ...
- 《A First Course in Probability》-chaper8-极限定理-切比雪夫不等式
基于对概率问题的抽象化,通过期望.方差.随机变量X及其概率,我们想要通过几个量推出另外几个量的特征,笼统的来说,极限定理起到的作用便在于此 切比雪夫不等式: 在证明切比雪夫不等式之前,我们先要完成对马 ...
- SwingConsole
Java的Swing默认不是线程安全的,类的调度应该由线程分派器来安排.如果每个类都各个各的调度,有可能造成线程紊乱,带来一些难以检测的错误. 对于编写实验性代码(每次都只有一个JFrame),如果每 ...
- Multipath多路径冗余全解析
一.什么是multipath 普通的电脑主机都是一个硬盘挂接到一个总线上,这里是一对一的关系.而到了有光纤组成的SAN环境,由于主机和存储通过了光纤交换机连接,这样的话,就构成了多对多的关系.也就是说 ...
- mysql 添加定时任务
之前定时任务都是用quartz 或者spring的任务调度来做的,易于管理,但是要写代码加 配置,其实mysql 自带了job ,先创建一个存储过程
- iOS 关于枚举的使用
枚举值 它是一个整形(int) 并且,它不参与内存的占用和释放,枚举定义变量即可直接使用,不用初始化. 在代码中使用枚举的目的只有一个,那就是增加代码的可读性. 使用: 枚举的定义如下: typed ...
- 自动开机和自动关机设定方法(包括linux和windows)
(一) linux 机器 1.关机 : 编辑 /etc/crontab添加一条并且保证crontab服务的运行即可 f1 f2 f3 f4 f5 root sudo shutdown –h now 假 ...
- 初识AM335X
TI 的AM335X,linux 操作系统,全都是陌生的东东,一点一点来熟悉吧. 拿的TI代理的一开发板,直接看文档.环境由于之前一同事已经装好了,公司条件受限,没法让我们一人一台ubuntu的机子来 ...