【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的。前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个页面抓取然后自动存到EXCEL中。今天完成了第一个页面的处理,抓取到了所有的二级链接。
要爬取初始网页:http://www.zizzs.com/zt/zzzsjz2017/###
任务:将招生简章中2017对应的二级页面的招生计划整理到EXCEL
初始目标:爬取http://www.zizzs.com/zt/zzzsjz2017/### 中招生简章2017年对应的二级链接,爬取到二级链接之后再接着往下爬取二级页面的表格,并存到EXCEL中.
我打算用BeautifulSoup来解析网页页面.
BeautifulSoup是Python中的一个HTML/XML解析器,通过定位HTML标签来格式化和组织复杂网络. 它可以很好的处理不规范标记并生成剖析树(parse tree),提供简单又常用的导航(navigating),搜索以及修改剖析树的操作.
中文文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
首先看下我要爬取的网页源码:

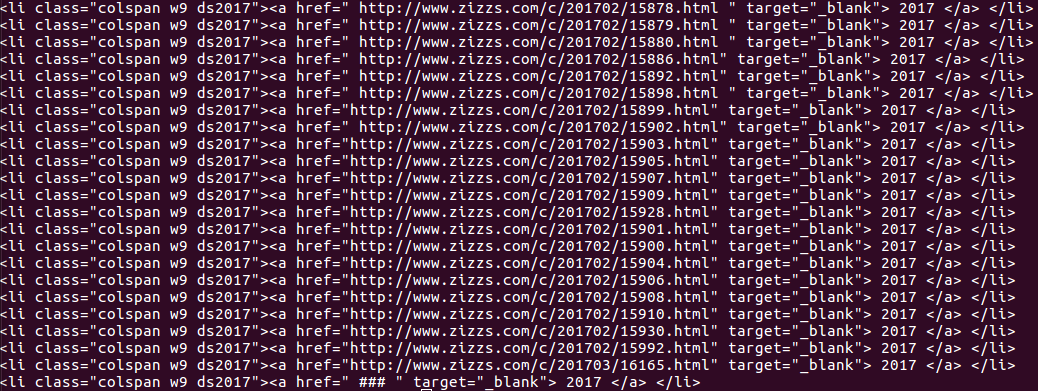
可以看见我要爬取的表格在图中红框圈住的页面中. 可以用BeautifulSoup的find()方法使用标签和属性定位这个表格.
找到表格所在位置之后可以看到我要找的页面都在class="colspan w9 ds2017" 中, 借用findAll()定位这个内容.
但是print出来是整个内容,而我要提取的是href中的页面链接.
对于这个问题我使用python的正则表达式re.findall()方法来提取链接.
使用方法: re.findall(pattern, string, flags=0),第一个参数是你要查找的字符串模式可以用正则表达式设计,第二是整个字符串
要了解python字符串可以看看这篇博文.
http://blog.csdn.net/eastmount/article/details/51082253
可以观察到我要查找的字符串有些是以空格开头的,有些不是, 我的正则表达式为:
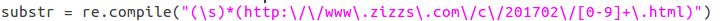
最后成功抓取到自己想要的链接:
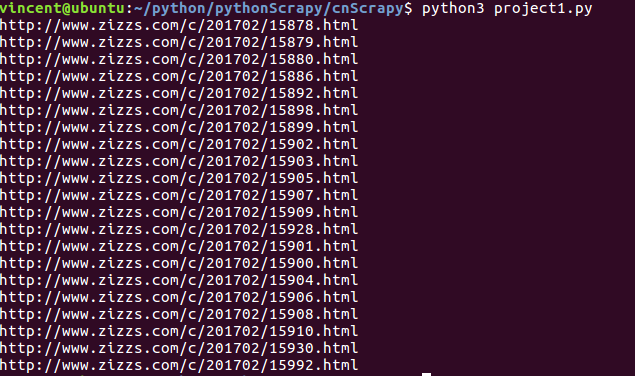
后面就是用这些链接去抓取表格内容的各个学校的招生信息了。
贴上源码:
# _*_ coding: UTF-8 _*_
from urllib import request
from bs4 import BeautifulSoup
import re
url = 'http://www.zizzs.com/zt/zzzsjz2017/###'
# 这一段是将python urllib伪装成chrome 浏览器,防止被服务器拒绝,原因在我另一篇文章python文章总结里面
def getHTML(url):
headers = {'User-Agent':'User-Agent:Mozilla/5.0(Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url,headers = headers)
return request.urlopen(req)
html = getHTML(url) #得到BeautifulSoup对象
bsObj = BeautifulSoup(html,'lxml')
foundLinks = [] #成功找到初始页面的所有二级链接
substr = re.compile("(\s)*(http:\/\/www\.zizzs\.com\/c\/201702\/[0-9]+\.html)")
for link in bsObj.find("div",{"id":"tab2_content"}).findAll("",{"class":"colspan w9 ds2017"}):
#print(str(link))
if len(re.findall(substr,str(link))) != 0:
foundLinks.append(re.findall(substr,str(link))[0][1]) print(foundLinks)
整个程序虽然比较简单,但是自己对BeautifulSoup和正则表达式还不是很熟悉,还是调试了很久.
【python爬虫和正则表达式】爬取表格中的的二级链接的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
随机推荐
- JQuery选择器排除某元素实现js代码
使用JQuery选择器实现排除某一大元素下的某一元素的核心代码是使用.not()方法,如下所示: $("button").not("#save").attr(& ...
- Unity5.X 编辑器介绍
导航窗口中有一个 Add Asset Package 按钮,可以导入一些官方的资源包,例如Characters角色控制器 Windows → Layouts 可以更换窗口的摆放 常见视图 ...
- selenim
一.安装selenium Pip install selenium==2.53.1 (稳定版) 下载火狐浏览器35.0.1 http://dl.pconline.com.cn/download ...
- 关于read函数的一些分析
ssize_t readn(int fd, std::string &inBuffer, bool &zero) { ssize_t nread = ; ssize_t readSum ...
- HDU 2303 The Embarrassed Cryptographer
The Embarrassed Cryptographer 题意 给一个两个素数乘积(1e100)K, 给以个数L(1e6), 判断K的两个素数是不是都大于L 题解 对于这么大的范围,素数肯定是要打表 ...
- BZOJ 4016 [FJOI2014]最短路径树问题 (贪心+点分治)
题目大意:略 传送门 硬是把两个题拼到了一起= = $dijkstra$搜出单源最短路,然后$dfs$建树,如果$dis_{v}=dis_{u}+e.val$,说明这条边在最短路图内,然后像$NOIP ...
- 2019-03-22 Python Scrapy 入门教程 笔记
Python Scrapy 入门教程 入门教程笔记: # 创建mySpider scrapy startproject mySpider # 创建itcast.py cd C:\Users\theDa ...
- java类的属性
类的嵌套!!!!!!!!!! 首先我们创建一个学生卡卡号的一个类,这个类有两个属性,校园卡号和银行卡号 package cuteSnow; public class StudentCard { pub ...
- (hdu step 7.1.6)最大三角形(凸包的应用——在n个点中找到3个点,它们所形成的三角形面积最大)
题目: 最大三角形 Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- Centos yum 安装lamp PHP5.4版本号
centos 6.5 1.yum安装和源码编译在使用的时候没啥差别.可是安装的过程就大相径庭了,yum仅仅须要3个命令就能够完毕,源码须要13个包,还得加压编译.步骤非常麻烦,并且当做有时候会出错,源 ...