04 Django-ORM多表操作(进阶)
一、创建模型
下面我们通过图书管理系统,来设计出每张表之间的对应关系。

通过上图关系,来定义一下我们的模型类。
from django.db import models class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey("Publish", on_delete=models.CASCADE)
authors = models.ManyToManyField("Author") class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=64)
email = models.EmailField() class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
au_detail = models.OneToOneField("AuthorDetail", on_delete=models.CASCADE) class AuthorDetail(models.Model):
tel = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
birthday = models.DateField()
from django.db import models # Create your models here. class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField() #一对多 外键声明写在多的那一方
publish = models.ForeignKey('Publish', on_delete=models.CASCADE, null=True) # django1时不用指定on_delete参数。
#on_delete=models.CASCADE 当关联的Publish表中的记录删除时 Book表也相应的删除
#publish在数据库表中 会自动加_id publish_id authors = models.ManyToManyField("Author") #该句写在Author表或者Book表都可以 看业务
# authors = models.ManyToManyField("AuthorBook") def __str__(self):
return self.title # class AuthorBook(models.Model): 可以自己写第三张表
# book = models.ForeignKey("Book", on_delete=models.CASCADE)
# author = models.ForeignKey("Author", on_delete=models.CASCADE) class Publish(models.Model):
name = models.CharField(max_length=64)
city = models.CharField(max_length=64)
email = models.EmailField() def __str__(self):
return self.name class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField() # au_detail = models.ForeignKey("AuthorDetail", unique=True) #第一种方式
au_detail = models.OneToOneField("AuthorDetail", on_delete=models.CASCADE)
#第二种方式该方法继承了ForeignKey类 一对一 该句写在Author表或者AuthorDetail表都可以 看业务 def __str__(self):
return self.name class AuthorDetail(models.Model):
tel = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
birthday = models.DateField()
代码实现
注意,不要忘了django使用MySQL数据库的步骤,一步一步执行完成,方可通过orm操作数据库。
二、操作表记录
1、添加一些简单的数据
1、publish表:

2、author表:

3、authordatail表:
2、一对多
# 方式一 传对象的形式
pub_obj = models.Publish.objects.get(pk=1)
book = models.Book.objects.create(title="独孤九剑", price=180, pub_date="2018-10-23", publish=pub_obj) # 方式二 传对象id的形式
book = models.Book.objects.create(title="独孤九剑", price=180, pub_date="2018-10-23", publish_id=1)
def query(request):
# 一对多
# 方式一 传对象
# pub_obj = models.Publish.objects.filter(name="丐帮出版社").first() #过滤出出版社对象
# book = models.Book.objects.create(title="打狗棒法", price=160, pub_date="2017-10-11", publish=pub_obj)#传出版社对象
# print(book, type(book)) 打狗棒法 <class 'app01.models.Book'> #def __str__(self):return self.name # 方式二: 传对象的id
pub_obj = models.Publish.objects.filter(name="丐帮出版社").first() # 过滤出出版社对象
book = models.Book.objects.create(title="睡梦罗汉拳", price=160, pub_date="2017-10-11", publish_id=pub_obj.pk)
print(book, type(book)) return HttpResponse('操作成功')
views.py实现

核心:明白book.publish 和 book.publish_id 的区别?
3、多对多
# 方式一 传对象的形式
book = models.Book.objects.filter(title="独孤九剑").first()
ling = models.Author.objects.filter(name="令狐冲").first()
ying = models.Author.objects.filter(name="任盈盈").first()
book.authors.add(ling, ying) # 方式二 传对象id的形式
book = models.Book.objects.filter(title="独孤九剑").first()
ling = models.Author.objects.filter(name='令狐冲').first()
ying = models.Author.objects.filter(name='任盈盈').first()
book.authors.add(ling.pk, ying.pk)
核心:book.authors.all()是什么?
多对多其他常用API:
|
1
2
3
|
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])book_obj.authors.clear() #清空被关联对象集合book_obj.authors.set() #先清空再设置 |
4、基于对象的跨表查询
1、一对多查询(Publish 与 Book)
正向查询(按字段 publish)
|
1
2
3
4
|
# 查询主键为1的书籍的出版社所在的城市book_obj=Book.objects.filter(pk=1).first()# book_obj.publish 是主键为1的书籍对象关联的出版社对象print(book_obj.publish.city) |
反向查询(按book表)
|
1
2
3
4
5
6
|
# 查询明教出版社出版的书籍名publish=Publish.objects.get(name="明教出版社")#publish.book_set.all() : 与明教出版社关联的所有书籍对象集合book_list=publish.book_set.all() for book_obj in book_list: print(book_obj.title) |
2、一对一查询(Author 和 AuthorDetail)
正向查询(按字段:au_detail):
|
1
2
|
# 查询令狐冲的电话<br>ling=Author.objects.filter(name="令狐冲").first()print(ling.au_detail.tel) |
反向查询(按表名:author):
|
1
2
3
4
5
|
# 查询所有住址在黑木崖的作者的姓名 authorDetail_list=AuthorDetail.objects.filter(addr="黑木崖")for obj in authorDetail_list: print(obj.author.name) |
3、多对多查询 (Author 与 Book)
正向查询(按字段:authors):
|
1
2
3
4
5
6
|
# 独孤九剑所有作者的名字以及手机号book_obj = Book.objects.filter(title="独孤九剑").first()authors = book_obj.authors.all()for author_obj in authors: print(author_obj.name, author_obj.au_detail.tel) |
反向查询(按表名:book_set):
|
1
2
3
4
5
6
|
# 查询令狐冲出过的所有书籍的名字 author_obj=Author.objects.get(name="令狐冲") book_list=author_obj.book_set.all() #与令狐冲作者相关的所有书籍 for book_obj in book_list: print(book_obj.title) |
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Book model 中做一下更改:
|
1
|
publish = models.ForeignKey("Publish", on_delete=models.CASCADE, related_name="book_list") |
那么接下来就会如我们看到这般:
|
1
2
3
4
|
# 查询 明教出版社出版过的所有书籍publish=Publish.objects.get(name="明教出版社")book_list=publish.book_list.all() # 与明教出版社关联的所有书籍对象集合 |
5、基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
'''
1、一对多查询
# 练习: 查询明教出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects.filter(publish__name="明教出版社").values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects.filter(name="明教出版社").values_list("book__title","book__price")
2、多对多查询
# 练习: 查询令狐冲出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects.filter(authors__name="令狐冲").values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects.filter(name="令狐冲").values_list("book__title","book__price")
3、一对一查询
# 查询令狐冲的手机号
# 正向查询
ret=Author.objects.filter(name="令狐冲").values("au_detail__tel")
# 反向查询
ret=AuthorDetail.objects.filter(author__name="令狐冲").values("tel")
4、进阶练习(连续跨表)
# 练习: 查询明教出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects.filter(publish__name="明教出版社").values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects.filter(name="明教出版社").values_list("book__title","book__authors__age","book__authors__name")
# 练习: 手机号以132开头的作者出版过的所有书籍名称以及出版社名称
# 方式1:
queryResult=Book.objects.filter(authors__au_detail__tel__startswith="132").values_list("title","publish__name")
# 方式2:
ret=Author.objects.filter(au_detail__tel__startswith="132").values("book__title","book__publish__name")
6、聚合查询和分组查询
1、聚合查询aggregate
我们先通过一个例子来感受一下吧。
|
1
2
3
|
# 计算所有图书的平均价格books = models.Book.objects.aggregate(Avg("price"))books = models.Book.objects.aggregate(avg_price=Avg("price")) # 指定字典的key为avg_price |
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句指定它(如上例)。
如果你希望生成不止一个聚合,你可以向aggregate() 子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
|
1
2
3
4
|
from django.db.models import Avg, Max, Min# 计算所有图书的平均价格、最贵价格和最便宜价格books = models.Book.objects.aggregate(Avg("price"), Max("price"), Min("price")) |
2、分组查询annotate
在讲之前,我们先回忆一下,我们之前学过的SQL语句,该如何查询。咱们对比一下ORM代码,来加深理解。
先来单表的练练手:
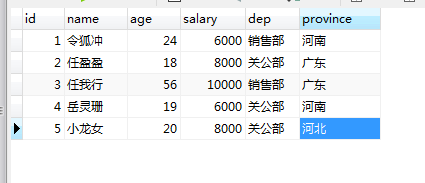
表结构为:

class Emp(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
salary = models.DecimalField(max_digits=8, decimal_places=2)
dep = models.CharField(max_length=32)
province = models.CharField(max_length=32)
准备数据:
INSERT INTO `bkm`.`app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('1', '令狐冲', '24', '6000.00', '销售部', '河南');
INSERT INTO `bkm`.`app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('2', '任盈盈', '18', '8000.00', '关公部', '广东');
INSERT INTO `bkm`.`app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('3', '任我行', '56', '10000.00', '销售部', '广东');
INSERT INTO `bkm`.`app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('4', '岳灵珊', '19', '6000.00', '关公部', '河南');
INSERT INTO `bkm`.`app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('5', '小龙女', '20', '8000.00', '关公部', '河北');
查询操作:
# 查询每一个部门名称以及对应的员工数
SQL:
select dep, count(1) from emp group by dep;
ORM:
models.Emp.objects.values('dep').annotate(c=Count('id')) # 查询每一个部门名称以及对应的员工的平均工资
SQL:
select dep, avg(salary) from app01_emp GROUP BY dep;
ORM:
models.Emp.objects.values('dep').annotate(a=Avg('salary'))
好了,接下来。我们在玩一下多表的分组查询。
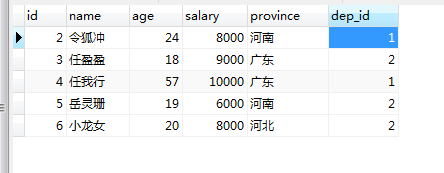
表结构为:
class Emps(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
salary = models.DecimalField(max_digits=8, decimal_places=2)
dep = models.ForeignKey("Dep", on_delete=models.CASCADE)
province = models.CharField(max_length=32) class Dep(models.Model):
title = models.CharField(max_length=32)
准备数据:
1、Dep表:
INSERT INTO `bkm`.`app01_dep` (`id`, `title`) VALUES ('1', '销售部');
INSERT INTO `bkm`.`app01_dep` (`id`, `title`) VALUES ('2', '关公部');
2、Emps表:
INSERT INTO `bkm`.`app01_emps` (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('2', '令狐冲', '24', '8000.00', '河南', '1');
INSERT INTO `bkm`.`app01_emps` (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('3', '任盈盈', '18', '9000.00', '广东', '2');
INSERT INTO `bkm`.`app01_emps` (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('4', '任我行', '57', '10000.00', '广东', '1');
INSERT INTO `bkm`.`app01_emps` (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('5', '岳灵珊', '19', '6000.00', '河南', '2');
INSERT INTO `bkm`.`app01_emps` (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('6', '小龙女', '20', '8000.00', '河北', '2');
查询操作:
# 查询每一个部门名称以及对应的员工数 SQL:
SELECT app01_dep.title,count(app01_emps.id) FROM app01_emps LEFT JOIN app01_dep ON app01_emps.dep_id = app01_dep.id GROUP BY app01_emps.dep_id; ORM:
models.Emps.objects.values("dep__title").annotate(c=Count("id")) # 查询每一个部门名称以及对应的员工的平均工资 SQL:
SELECT app01_dep.title,avg(app01_emps.salary) FROM app01_emps LEFT JOIN app01_dep ON app01_emps.dep_id = app01_dep.id GROUP BY app01_emps.dep_id; ORM:
models.Emps.objects.values("dep__title").annotate(a=Avg("salary"))
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
3、查询练习
1、练习:统计每一个出版社的最便宜的书的价格
# 练习:统计每一个出版社的最便宜的书的价格
SQL:
select name, min(app01_book.price)
from app01_publish LEFT
JOIN
app01_book
on
app01_book.publish_id = app01_publish.id
GROUP
BY
app01_publish.name; ORM:
models.Publish.objects.values("name").annotate(min_price=Min("book__price"))
2、练习:统计每一本书的作者个数
练习:统计每一本书的作者个数
SQL:
SELECT
title,
count(NAME)
FROM
app01_book
LEFT JOIN app01_book_authors ON app01_book.id = app01_book_authors.book_id
LEFT JOIN app01_author ON app01_book_authors.author_id = app01_author.id
GROUP BY
app01_book.id; ORM:
models.Book.objects.annotate(num=Count('authors__name')).values("title", "num")
3、练习:统计每一本以“九”开头的书籍的作者个数
# 练习:统计每一本以“九”开头的书籍的作者个数
SQL:
SELECT
title,
count(NAME)
FROM
app01_book
LEFT JOIN app01_book_authors ON app01_book.id = app01_book_authors.book_id
LEFT JOIN app01_author ON app01_book_authors.author_id = app01_author.id
WHERE
app01_book.title LIKE '九%'
GROUP BY
app01_book.id; ORM:
models.Book.objects.filter(title__startswith="九").annotate(num=Count('authors__name')).values("title", "num")
4、练习:统计不止一个作者的图书名称
# 练习:统计不止一个作者的图书名称 SQL:
SELECT
title,
count(NAME) AS num
FROM
app01_book
LEFT JOIN app01_book_authors ON app01_book.id = app01_book_authors.book_id
LEFT JOIN app01_author ON app01_author.id = app01_book_authors.author_id
GROUP BY
app01_book.id
HAVING
num > 1; ORM:
models.Book.objects.annotate(num_author=Count("authors__name")).filter(num_author__gt=1).values("title")
5、练习:根据一本图书作者数量的多少对查询集QuerySet进行排序
# 练习:根据一本图书作者数量的多少对查询集QuerySet进行排序 SQL:
SELECT
title,
count(author_id) AS num
FROM
app01_book
LEFT JOIN app01_book_authors ON app01_book.id = app01_book_authors.book_id
LEFT JOIN app01_author ON app01_author.id = app01_book_authors.author_id
GROUP BY
app01_book.id
ORDER BY
num; ORM:
models.Book.objects.annotate(num_author=Count("authors__name")).order_by("num_author").values("title", "num_author")
6、练习:查询各个作者出的书的总价格
# 练习:查询各个作者出的书的总价格 SQL:
SELECT
NAME,
sum(price)
FROM
app01_author
LEFT JOIN app01_book_authors ON app01_author.id = app01_book_authors.author_id
LEFT JOIN app01_book ON app01_book.id = app01_book_authors.book_id
GROUP BY
app01_author.id; ORM:
models.Author.objects.annotate(total=Sum("book__price")).values('name', 'total')
7、F查询与Q查询
1、F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
|
1
2
3
4
|
# 查询工资大于年龄的人from django.db.models import F, Qmodels.Emp.objects.filter(salary__gt=F('age')) |
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
|
1
2
3
|
# 查询工资小于两倍年龄值的人models.Emp.objects.filter(salary__lt=F("age") * 2) |
修改操作也可以使用F函数,比如将每一本书的价格提高100元
|
1
|
models.Book.objects.update(price=F('price') + 100) |
2、Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
|
1
2
3
|
from django.db.models import QQ(title__startswith="九") |
Q 对象可以使用 & 、 | 和 ~(与 或 非)操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
|
1
2
3
|
# 查询价格大于300或者名称以九开头的书籍 models.Book.objects.filter(Q(price__gt=300)|Q(title__startswith="九")) |
等同于下面的SQL where子句:
|
1
|
WHERE (`app01_book`.`price` > 300 OR `app01_book`.`title` LIKE BINARY '九%') |
综合使用,请看示例:
|
1
2
3
|
# 查询价格大于300或者不是2019年三月份的书籍models.Book.objects.filter(Q(price__gt=300)|~Q(Q(pub_date__year=2019)&Q(pub_date__month=3))) |
04 Django-ORM多表操作(进阶)的更多相关文章
- Django ORM 多表操作
目录 Django ORM 多表操作 表模型 表关系 创建模型 逆向到表模型 插入数据 ORM 添加数据(添加外键) 一对多(外键 ForeignKey) 一对一 (OneToOneFeild) 多对 ...
- Django ORM多表操作
多表操作 创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对 ...
- django ORM单表操作
1.ORM介绍 ORM是“对象-关系-映射”的简称 映射关系: mysql---------Python 表名----------类名 字段----------属性 表记录--------实例化对象 ...
- Django框架06 /orm多表操作
Django框架06 /orm多表操作 目录 Django框架06 /orm多表操作 1. admin相关操作 2. 创建模型 3. 增加 4. 删除 5. 修改 6. 基于对象的跨表查询 7. 基于 ...
- django框架基础-ORM单表操作-长期维护
############### 单表操作-添加数据 ################ import os if __name__ == '__main__': os.environ.set ...
- Django框架05 /orm单表操作
Django框架05 /orm单表操作 目录 Django框架05 /orm单表操作 1. orm使用流程 2. orm字段 3. orm参数 4. orm单表简单增/删/改 5. orm单表查询 5 ...
- day53:django:URL别名/反向解析&URL分发&命名空间&ORM多表操作修改/查询
目录 1.URL别名&反向解析 2.URL分发&命名空间 3.ORM多表操作-修改 4.ORM多表操作-查询 4.1 基于对象的跨表查询 4.2 基于双下划线的跨表查询 4.3 聚合查 ...
- Django ORM那些相关操作zi
Django ORM那些相关操作 一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <1> all(): 查询所有结果 <2> filter(**kwargs) ...
- Django ORM 那些相关操作
Django ORM 那些相关操作 一般操作 必知必会13条 <> all(): #查询所有的结果 <> filter(**kwargs) # 它包含了与所给筛选条件相匹配的对 ...
- day59——orm单表操作
day59 orm单表操作 对象关系映射(object relational mapping) orm语句 -- sql -- 调用pymysql客户端发送sql -- mysql服务端接收到指令并执 ...
随机推荐
- 2.SpringBoot的properties的属性配置详解
SpringBoot是为了简化Spring应用的创建.运行.调试.部署等一系列问题而诞生的产物,自动装配的特性让我们可以更好的关注业务本身而不是外部的XML配置,我们只需遵循规范,引入相关的依赖就可以 ...
- IT培训机构的招生诈骗大曝光
作者曾在某知名IT培训机构工作过,目睹了招生欺诈,后来作者果断辞职,不能为奸商工作,助纣为虐,在此曝光,以免学生的血汗钱白交.社会上的IT培训机构手法大都一样,奸商都是有套路的.X大青鸟,X内外企IT ...
- App后台开发运维和架构实践学习总结(1)——App后台核心技术之用户验证方案
对于初学者来说,对Token和Session的使用难免会限于困境,开发过程中知道有这个东西,但却不知道为什么要用他?更不知道其原理,今天我就带大家一起分析分析这东西. 一.使用Token进行身份鉴权 ...
- Android执行时ART载入OAT文件的过程分析
在前面一文中,我们介绍了Android执行时ART,它的核心是OAT文件.OAT文件是一种Android私有ELF文件格式,它不仅包括有从DEX文件翻译而来的本地机器指令.还包括有原来的DEX文件内容 ...
- ZOJ 1649 Rescue(有敌人迷宫BFS)
题意 求迷宫中从a的位置到r的位置须要的最少时间 经过'.'方格须要1s 经过'x'方格须要两秒 '#'表示墙 因为有1s和2s两种情况 须要在基础迷宫bfs上加些推断 令到达每一个点的时间初 ...
- Service启动模式
Service简单介绍 Service表示服务.是Android系统的核心组件之中的一个. Service的本质是一个继承了android.app.Service的java类: ...
- Android 怎样实现 焦点图的 无线循环滑动的状态?
參考网址:http://my.oschina.net/xsk/blog/119167 总体的架构:ViewPgaer 中直接嵌套 IamgeView 方案一: 重写Viewpager 这样有局限性 ...
- Qt中暂停线程的执行(主线程和工作线程共用一把锁,一旦主线程将它锁上,工作线程就无法运行了,这也是一个办法)
在线程中定义一个信号量: QMutex pause; 把run()函数中循环执行的部分用信号量pause锁住: void run() { while(1) { pause.lock ...
- Error解决:Property's synthesized getter follows Cocoa naming convention for returning 'owned'
在项目中定义了以new开头的textField.结果报错: 先看我的源代码: #import <UIKit/UIKit.h> @interface ResetPasswordViewCon ...
- dns tunnel 使用 nishang 下载TXT里的cmd(TXT里)实现CC command+ ceye实现数据外发
摘自:https://hk.saowen.com/a/a06909f1c57cb8452db969b3deede4151de42a7d69f4bb52c5bf027033fb91bd Powershe ...