python爬虫之『入门基础』
HTTP请求
1.首先需要了解一下http请求,当用户在地址栏中输入网址,发送网络请求的过程是什么?
可以参考我之前学习的时候转载的一篇文章一次完整的HTTP事务过程–超详细
2.还需要了解一下http的请求方式
有兴趣的同学可以去查一下http的八种请求方法,这里呢主要说下get请求和post请求,这两种在以后学习中会用到的比较多。
get请求:GET方法用于使用给定的URI从给定服务器中检索信息,即从指定资源中请求数据。我们输入网址访问网站一般就是get请求。[做运维的小年轻]使用GET方法的请求应该只是检索数据,并且不应对数据产生其他影响。
优点:比较便捷
缺点:由于是明文传输,所以安全性比较低,另外参数长度有限制。
post请求:POST请求通常是使用来提交HTML的表单,表单中的数据传输到服务器,由服务器对这些数据处理。我们平常执行登录操作的那一下基本上都是post请求。
关于get请求和post请求区别优缺点这里推荐一篇博文:http GET 和 POST 请求的优缺点、区别以及误区
下面说一下Headers中的Request Headers(请求头信息),

Accept:指定客户端能够接收的内容类型,图中text/html表示要请求返回文本格式的数据
Accept-Encoding:指定浏览器可以支持的web服务器返回内容压缩编码类型,图中gzip表示支持gzip格式的压缩文件
Accept-Language:浏览器可接受的语言 图中 zh-CN表示接受中文
Connection:表示是否需要持久连接。(HTTP 1.1默认进行持久连接)图中keep-alive意为保持长链接
Cookie:是服务器发送到浏览器并保存在本地的一小块数据,存储在header中,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上,通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。
Host:指定请求的服务器的域名和端口号,图中是www.baidu.com也就是我在地址栏中请求的网址
User-Agent:包含的是发出请求的用户信息,客户机的软件环境浏览器类型等
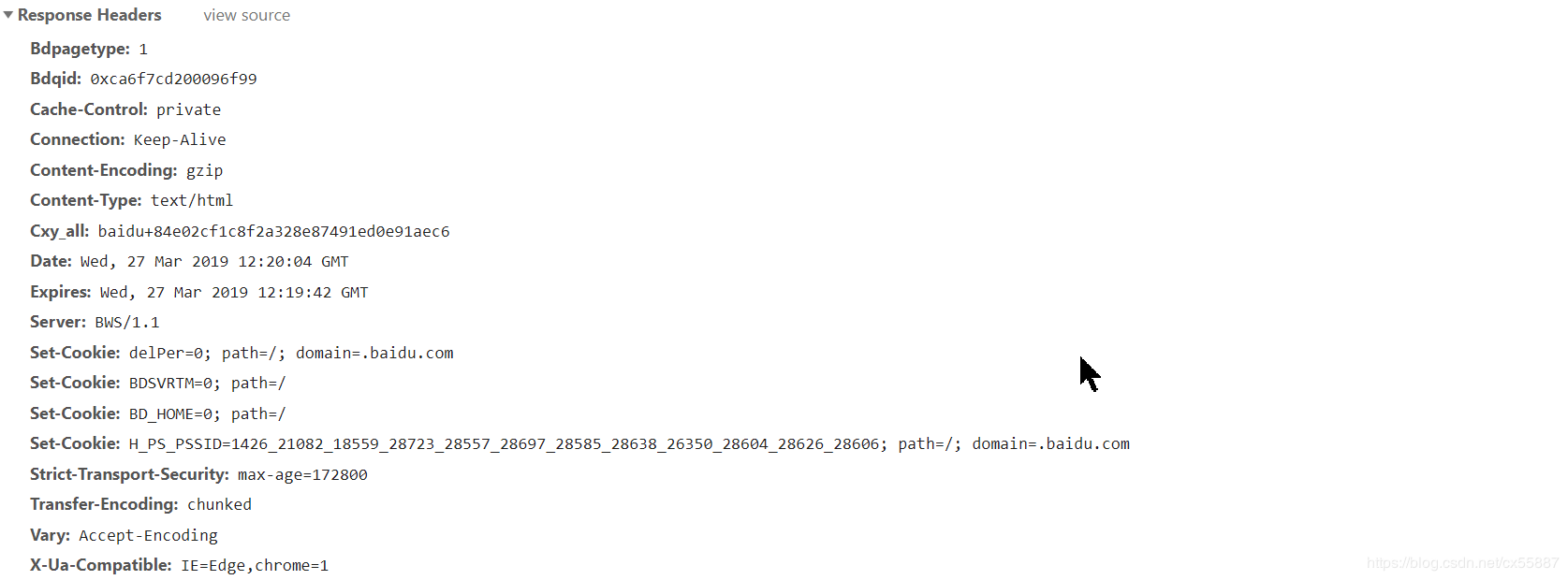
Response Header 和Request Headers对应,如下图
了解完这些呢,就来看下爬虫吧
关于爬虫
爬虫通俗来说,就是使用代码模拟用户,批量发送网络请求,批量的获取数据
爬虫的的分类
1.通用爬虫:搜索引擎的爬虫
优势:开放性很好,速度比较快
劣势:目标不明确,举个例子哈,例如我在百度搜索图片,搜索结果如下图,我想要的是图片,但是看下图红色方框所圈的内容并不是我们所要找的图片资源,这就是我所说[做运维的小年轻]的目标不明确,导致的结果呢就是返回的很多内容并不是用户所需要的。

2.聚焦爬虫:全称聚焦网络爬虫,又称为主题网络爬虫
优点:目标明确,对用户的需求非常精准,返回内容很固定,比如我就请求一张图片,那么就返回一张图片。
关于爬虫的分类其实在以后越来越深入的学习中,会自然而然的理解,现在只需有个大概了解就行了关于网络爬虫分类日百度百科中讲的比较详细,点击传送门去了解。
python爬虫之『入门基础』的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫的简单入门(一)
Python爬虫的简单入门(一) 简介 这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇 ...
随机推荐
- php八大设计模式之适配器模式
将一个抽象被具体后的结果转换成另外一个需求所需的格式. 在生活中也处处有适配器的出现,比如转换头,就是让两种不同的规格合适的搭配在一起. <?php header("content-t ...
- Hope is a good thing, maybe the best of things and no good thing ever dies !
- 高并发MYSQL如何优化处理?
1)代码中sql语句优化 2)数据库字段优化,索引优化 3)加缓存,redis/memcache等 4)主从,读写分离 5)分区表 6)垂直拆分,解耦模块 7)水平切分
- CodeForcesEducationalRound40-D Fight Against Traffic 最短路
题目链接:http://codeforces.com/contest/954/problem/D 题意 给出n个顶点,m条边,一个起点编号s,一个终点编号t 现准备在这n个顶点中多加一条边,使得st之 ...
- python常用函数库收集。
学习过Python都知道python中有很多库.python本身就是万能胶水,众多强大的库/模块正是它的优势. 收集一些Python常用的函数库,方便大家选择要学习的库,也方便自己学习收集,熟悉运用好 ...
- PHP实现几种经典算法详解
前言 在编写JavaScript代码的时候存在一些对于数组的方法,可能涉及的页面会很多,然后每次去写一堆代码.长期下去代码会特别的繁多,是时候进行一波封装了,话不多说开始书写优美的代码 代码已上传gi ...
- 08-for循环
- 进程:linux用户态-内核态
用户态:Ring3运行于用户态的代码则要受到处理器的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中I/O许可位图(I/O Permi ...
- BZOJ5204: [CodePlus 2018 3 月赛]投票统计
[传送门:BZOJ5204] 简要题意: 有n个选手,每个选手会选择一道题投票,求出投票最多的题目个数和这些题目的编号,如果所有题目的投票数相同,则输出-1 题解: 直接搞 离散化,然后判断就可以了 ...
- jquery tmpl插件
动态请求数据来更新页面是现在非常常用的方法,比如博客评论的分页动态加载,微博的滚动加载和定时请求加载等. 这些情况下,动态请求返回的数据一般不是已拼好的 HTML 就是 JSON 或 XML,总之不在 ...