scrapy——8 scrapyd使用
scrapy——8 scrapyd使用
- 什么是scrapyd
- 怎么安装scrapyd
- 如何使用scrapyd--运行scrapyd
- 如何使用scrapyd--配置scrapy.cfg
- 如何使用scrapyd--添加到爬虫工程
- 如何使用scrapyd--运行爬虫任务
- 如何使用scrapyd--停止爬虫任务
- 如何使用scrapyd--删除爬虫项目
- 如何使用scrapyd--查看存在的爬虫工程
什么是scrapyd?
scrapyd是运行scrapy爬虫的服务程序,它支持以http命令方式发布、删除、启动、停止爬虫程序。而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本。
特点:
- 可以避免爬虫源码被看见。
- 有版本控制。
- 可以远程启动、停止、删除
scrapyd官方文档:https://scrapyd.readthedocs.io/en/stable/overview.html
怎么安装scrapyd
安装scrapyd
主要有两种方法:
pip install scrapyd (安装的版本可能不是最新的)
从 https://github.com/scrapy/scrapyd 中下载源码,
运行python setup.py install 命令进行安装
2. 安装scrapyd-deploy
主要有两种安装方式:
pip install scrapyd-client(安装的版本可能不是最新版本)
从 http://github.com/scrapy/scrapyd-client 中下源码,
运行python setup.py install 命令进行安装。
如何使用scrapyd?
运行scrapyd
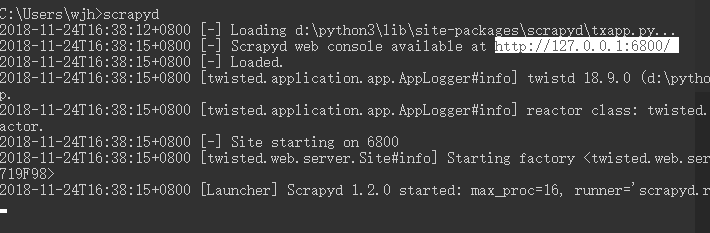
直接在终端输入scrapyd,访问http链接
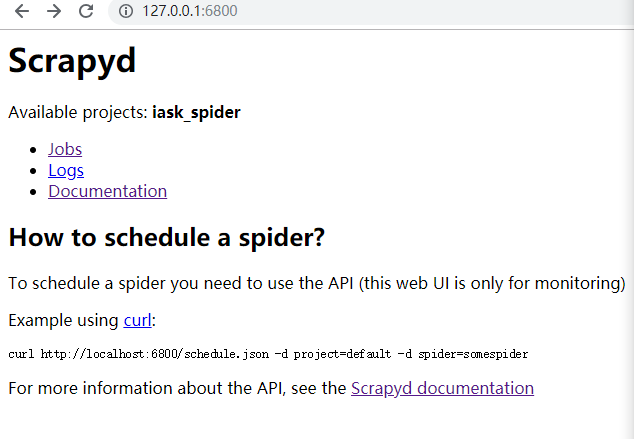
配置scrapy.cfg
这时进入到我们的scrapy项目中,找到新建scrapy项目都会生成的scrapy.cfg文件
打开后是这样的内容
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html [settings]
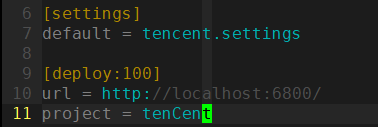
default = tencent.settings [deploy]
#url = http://localhost:6800/
project = tencent
- 首先去掉url前面的注释符号,url是scrapyd服务器的网址
- 然后project=tenCent为项目名称,可以随意起名
- 修改[deploy]为[depoly:100],表示把爬虫发布到名为100的爬虫服务器上,一般在需要同时发布爬虫到多个目标服务器时使用
添加到爬虫工程
命令如下:
Scrapyd-deploy <target> -p <project> --version <version>
参数解释:
- target:deploy后面的名称。
- project:自行定义名称,跟爬虫的工程名字无关。
- version:自行定义版本号,不写的话默认为当前时间戳
现在我们来上传一个新的项目到scrapd中
来到项目的能运行scrapy的路径下,输入:
scrapyd-deploy 100 -p tenCent --version v1

这是刷新6800端口网页,会发现已经有项目被添加进来了
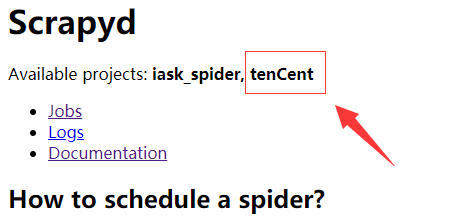
此时的job还是没有数据的
运行爬虫任务
运行爬虫项目的命令如下:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
- project:scrapy.cfg中设置的project
- spider_name:运行scrapy的项目名称===》scrapy list

运行代码以后:


停止爬虫任务
curl http://localhost:6800/cancel.json -d project=project_name -d job=job_id
job_id:如图所致
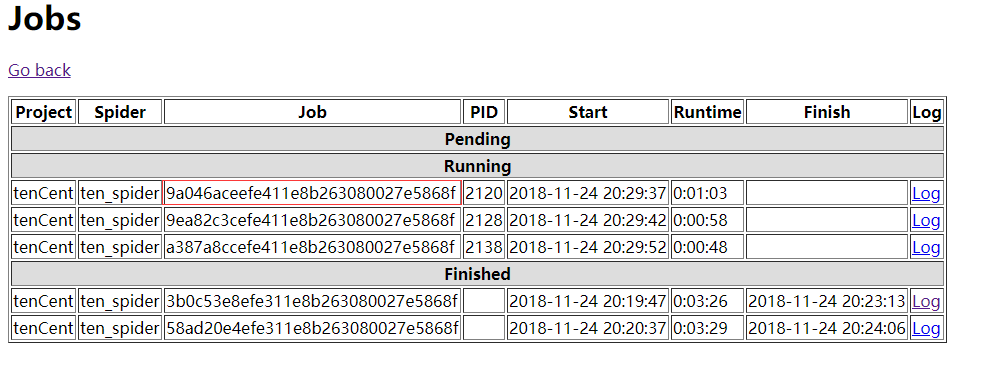

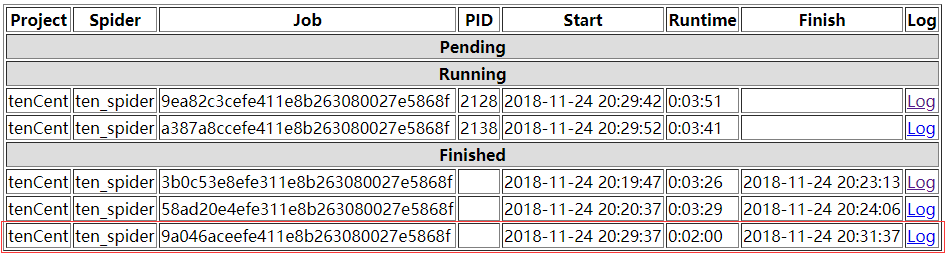
可以看出,爬虫在2:00时就停止了
log可以查看运行结果
删除爬虫
curl http://localhost:6800/delproject.json -d project=project_name


查看scrapyd中存在的项目
curl http://localhost:6800/listprojects.json

还有其他更多的命令,请参考官网:https://scrapyd.readthedocs.io/en/latest/api.html
scrapy——8 scrapyd使用的更多相关文章
- scrapy的scrapyd使用方法
一直以来,很多人疑惑scrapy提供的scrapyd该怎么用,于我也是.自己在实际项目中只是使用scrapy crawl spider,用python来写一个多进程启动,还用一个shell脚本来监控进 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- scrapy与scrapyd安装
Scrapy是用python编写的爬虫程序. Scrapyd是一个部署与运行scrapy爬虫的应用,提供JSON API的调用方式来部署与控制爬虫 . 本文验证在fedora与centos是安装成功. ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- 如何部署Scrapy 到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- 基于scrapyd爬虫发布总结
一.版本情况 python以丰富的三方类库取得了众多程序员的认可,但也因此带来了众多的类库版本问题,本文总结的内容是基于最新的类库版本. 1.scrapy版本:1.1.0 D:\python\Spid ...
随机推荐
- Codesys——PLCopen基本运动控制功能块的使用方法总结
MC_Halt 在MC_MoveVelocity模式下,用MC_Halt停止其轴,当前轴的状态由 ContinuousMotion(当前转速)--->DiscreteMotion(速度不为0)- ...
- JavaScript Patterns 2.3 For loops
HTMLCollections are objects returned by DOM methods such as: • document.getElementsByName() • docume ...
- Kaggle "Microsoft Malware Classification Challenge"——就是沙箱恶意文件识别,有 Opcode n-gram特征 ASM文件图像纹理特征 还有基于图聚类方法
使用图聚类方法:Malware Classification using Graph Clustering 见 https://github.com/rahulp0491/Malware-Classi ...
- [转]Dialog
在Android开发中,我们经常会需要在Android界面上弹出一些对话框,比如询问用户或者让用户选择.这些功能我们叫它Android Dialog对话框,在我们使用Android的过程中,我归纳了一 ...
- 面向对象软件工程与UML
软件工程基本概念 软件危机 软件的功能.规模及复杂性与日俱增,软件的复杂性达到了它的开发者难以控制的程度 这种情况导致了严重的后果: 软件可靠性下降 开发效率低下 维护极为困难 这使软件开发者陷入困境 ...
- Linex系统 配置php服务器
此文是可以参考 楼主也不是系统管理员只是迫不得已所以自己才找的 大家可以参考 .... ..... 安装apache 安装mysql 安装PHP 测试服务器 php -v 查询php的版本 就这些了 ...
- mysql select 操作优先级
单表查询操作 select filed1,filed2... form table where ... group by ... having .... order by ... limit ... ...
- linux命令大杂烩之网络管理
在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具.它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具. 作为一款强力 ...
- C语言关键字之sizeof
C语言关键字 sizeof 是一个操作符,返回对象或类型所占内存字节数,类型为size_t(定义在<stddef.h>),有2种用法: sizeof unary-expression si ...
- Floyd模板
比较简单的算法:但是当点太多需要剪枝,不然很耗时 void Floyd() { ;k<n;++k) ;i<n;++i) ;j<n;++j) dj[i][j] = min(dj[i][ ...