聚类(Clustering)
- 简介
相对于决策树、朴素贝叶斯、SVM等有监督学习,聚类算法属于无监督学习。
有监督学习通常根据数据集的标签进行分类,而无监督学习中,数据集并没有相应的标签,算法仅根据数据集进行划分。
由于具有出色的速度和良好的可扩展性,Kmeans聚类算法算得上是最著名的聚类方法。
- 基本思想
在没有标签的数据集中,所有的数据点都是同一类的。
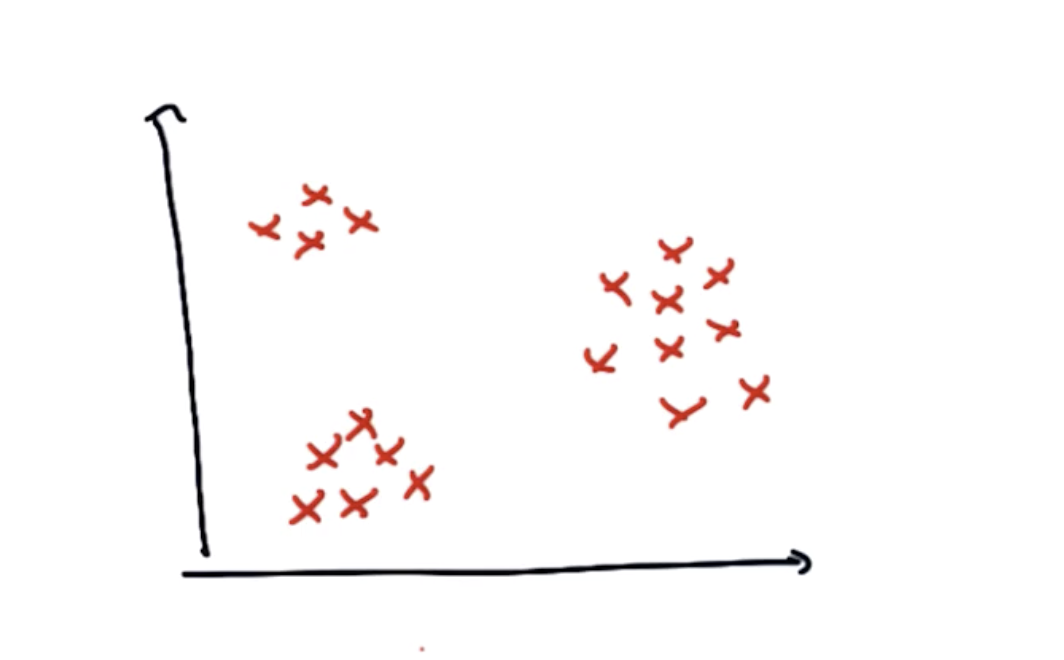
在这张图中,虽然数据都为同一类,但是可以直观的看出,数据集存在簇或聚类。这种数据没有比标签,但能发现其结构的情况,称作非监督学习。
最基本的聚类算法,也是目前使用最多的聚类算法叫做K-均值(K-Means)。
假设一组数据集为下图:
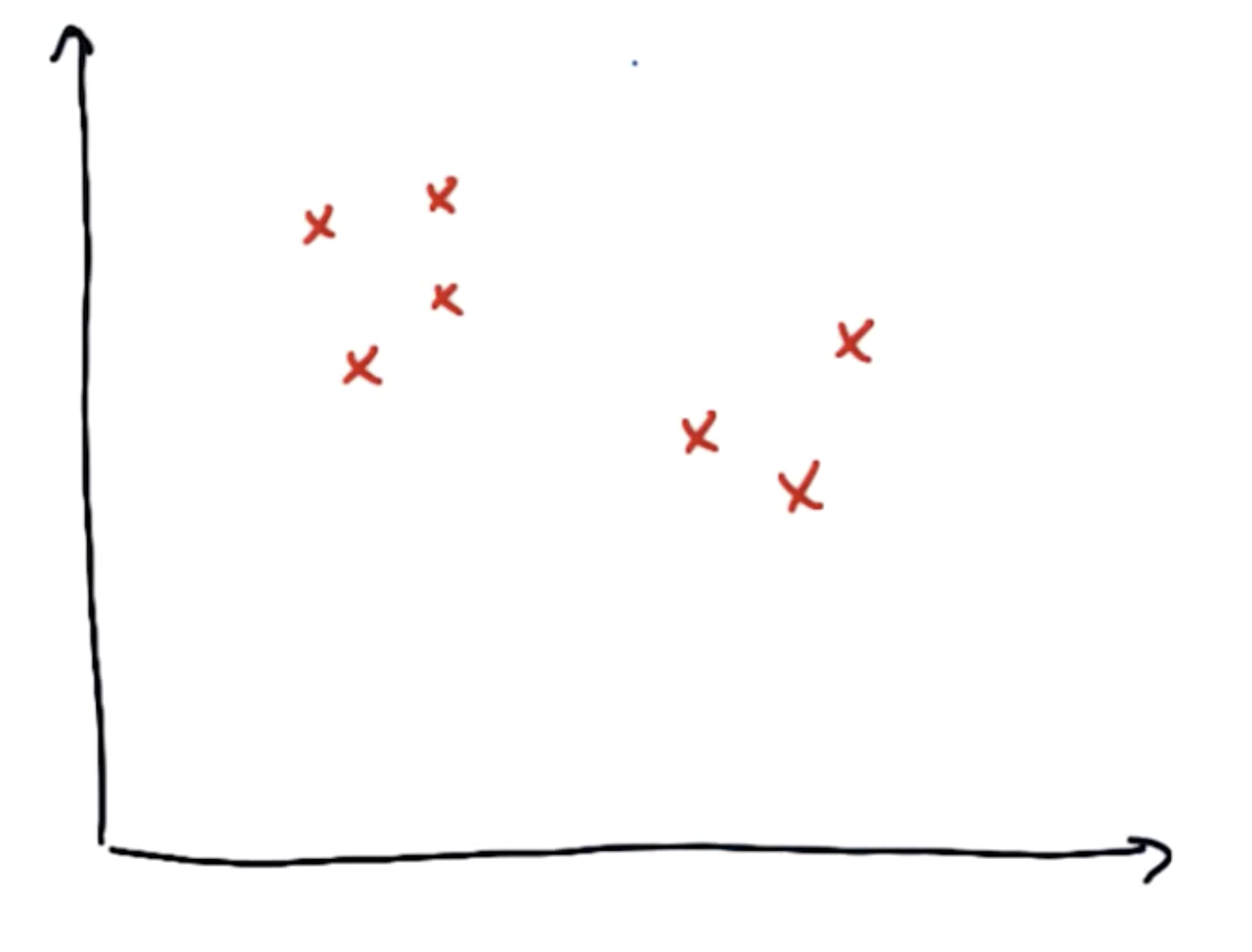
他们应该有两个簇,其中簇的中心如下图:
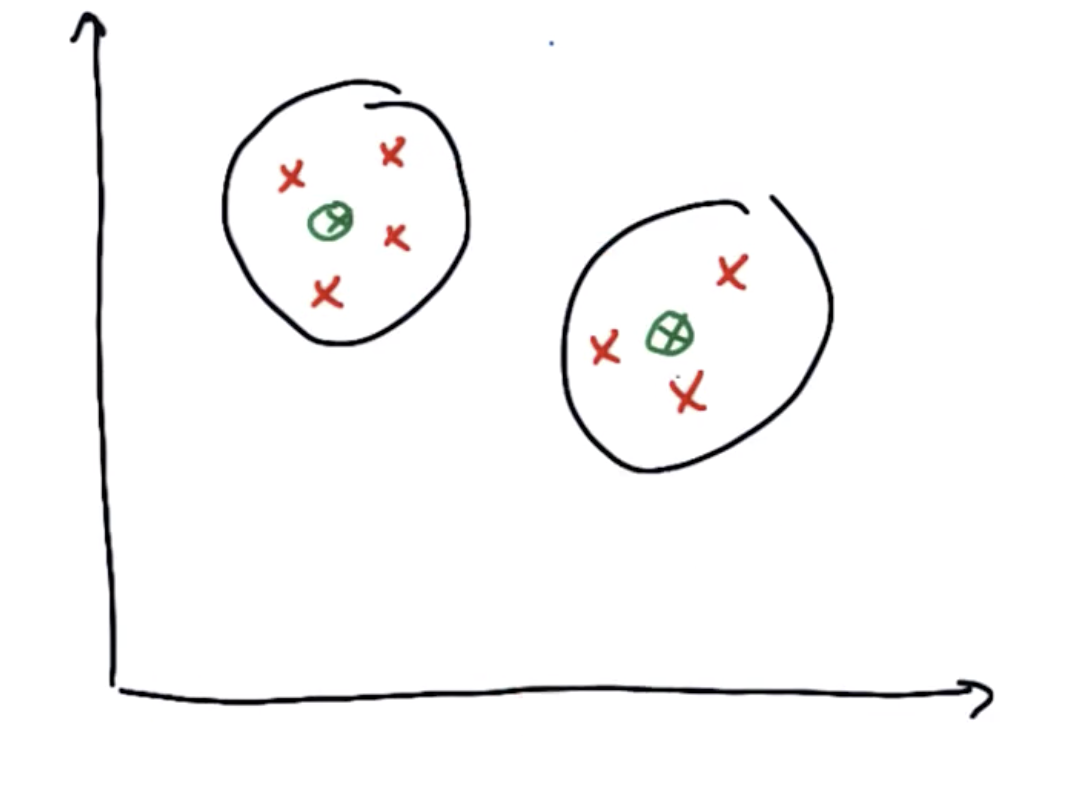
在K-Means算法中,首先随便画出聚类中心,它可以是不正确的:
(假设上方绿点为中心1,下方绿点为中心2)

K-Means算法分为两个步骤:
1、分配
2、优化
进行第一步,对于上图的数据集,首先找出在所有红色点中,距离中心1比距离中心2更近的点
简单的方法是找出两个中心点的垂直平分线,将红色的点分割为两部分,分别是距离各自中心更近的点
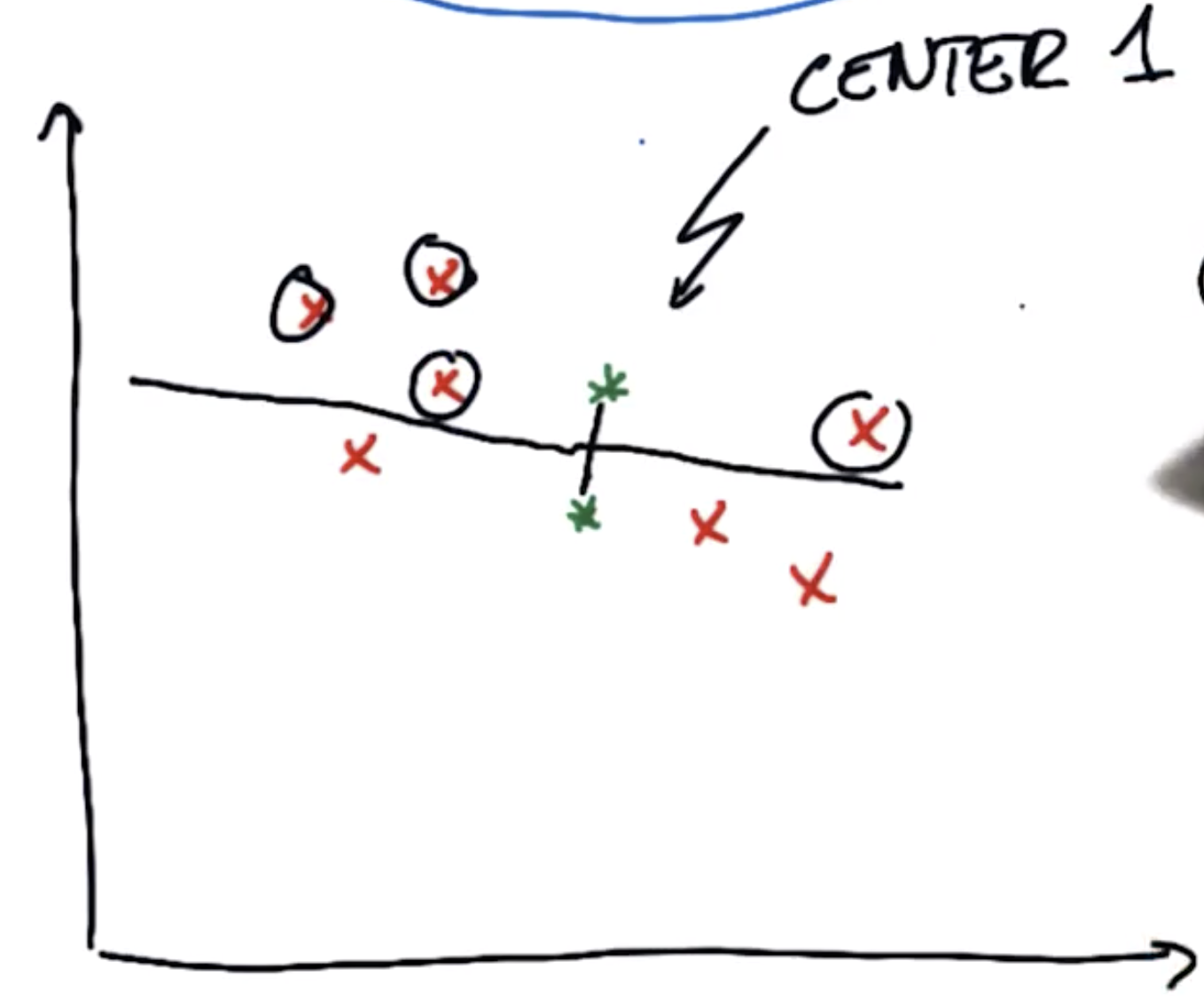
第二步是优化。首先将聚类中心和第一步分配完的点相连接,然后开始优化:移动聚类中心,使得与聚类中心相连接的线的平方和最短。
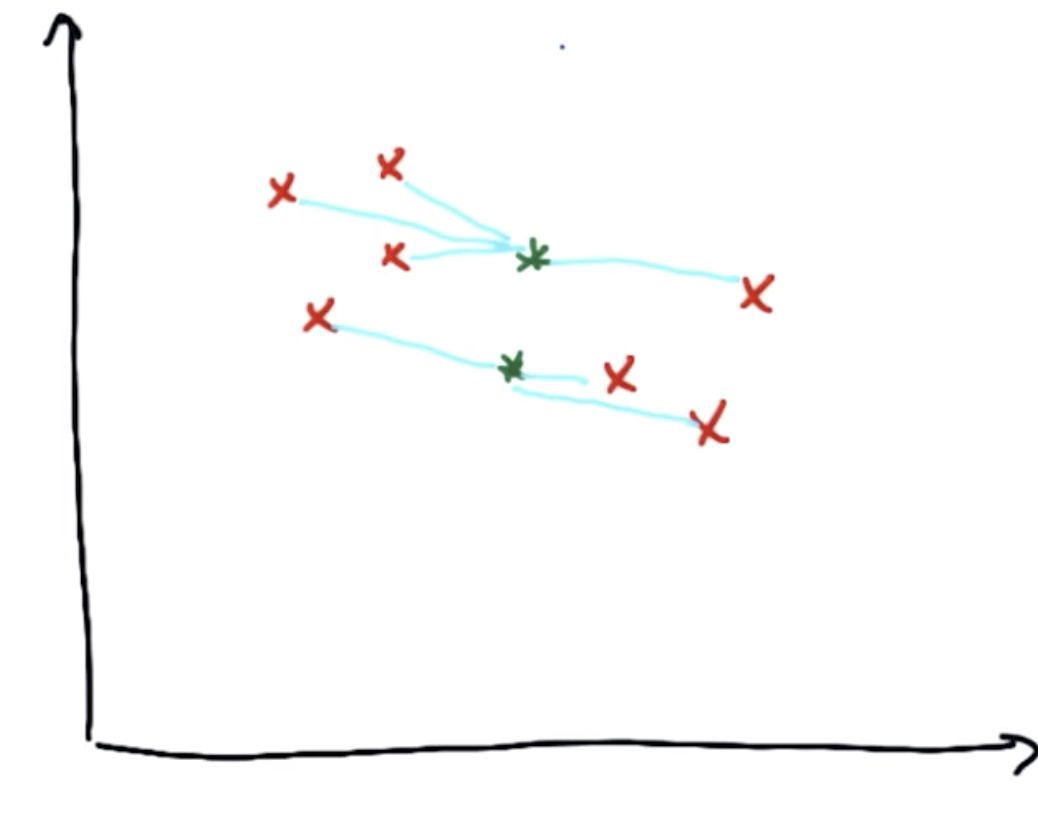
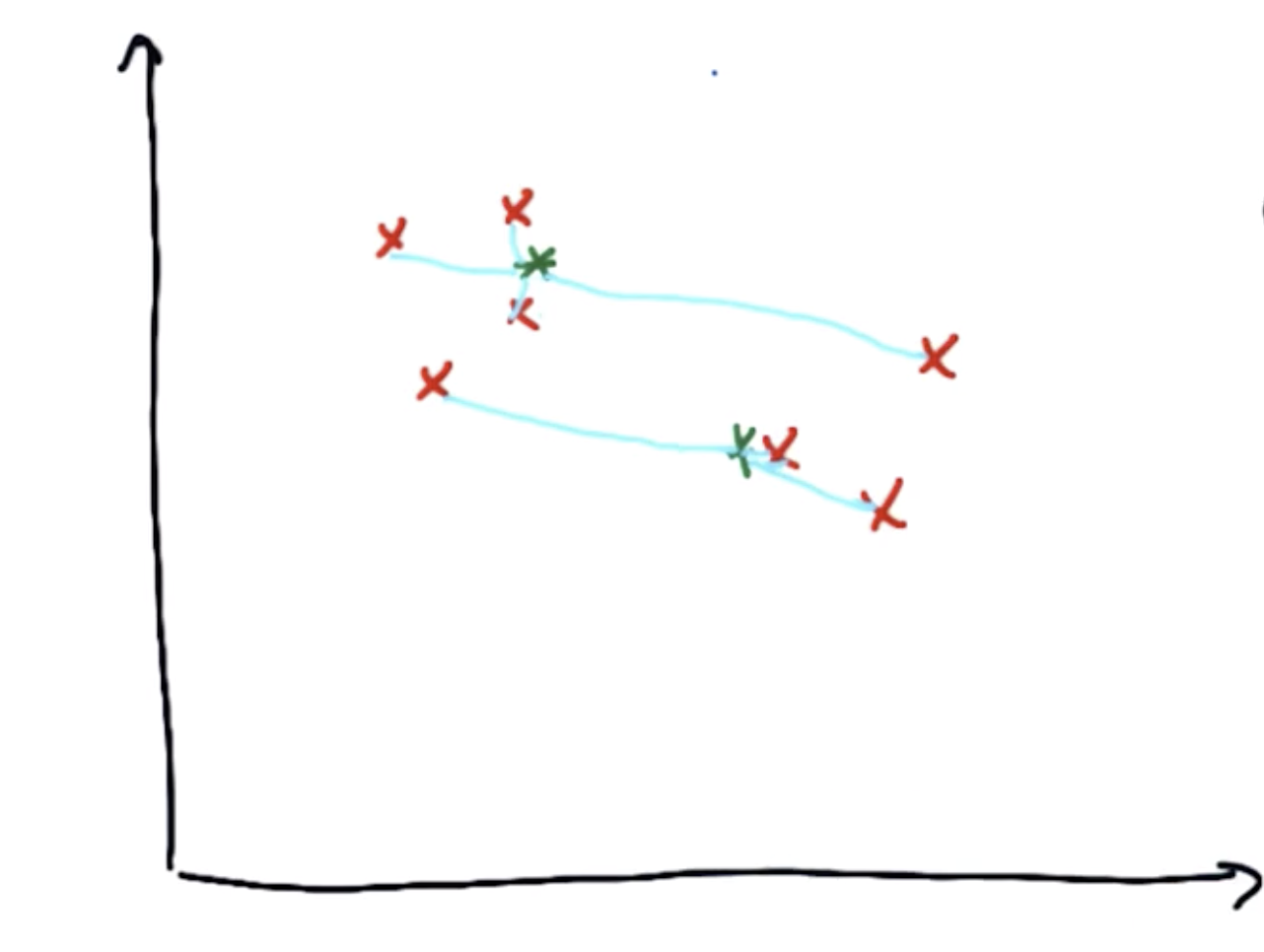
多次进行步骤1和2,即先分配再优化,聚类中心将会逐步移动到数据簇的中心。

- 代码实现
环境:MacOS mojave 10.14.3
Python 3.7.0
使用库:scikit-learn 0.19.2
sklearn.cluster.KMeans官方库:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]]) #输入六个数据点 >>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
#确定一共有两个聚类中心 >>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32) >>> kmeans.predict([[0, 0], [12, 3]]) #预测两个新点的聚类分类情况
array([1, 0], dtype=int32) >>> kmeans.cluster_centers_ #输出两个聚类中心的坐标
array([[10., 2.],
[ 1., 2.]])
聚类(Clustering)的更多相关文章
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- sklearn:聚类clustering
http://blog.csdn.net/pipisorry/article/details/53185758 不同聚类效果比较 sklearn不同聚类示例比较 A comparison of the ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
第十三章.聚类--Clustering ******************************************************************************** ...
- [C8] 聚类(Clustering)
聚类(Clustering) 非监督学习:简介(Unsupervised Learning: Introduction) 本章节介绍聚类算法,这是我们学习的第一个非监督学习算法--学习无标签数据,而不 ...
- 机器学习(九)-------- 聚类(Clustering) K-均值算法 K-Means
无监督学习 没有标签 聚类(Clustering) 图上的数据看起来可以分成两个分开的点集(称为簇),这就是为聚类算法. 此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者 ...
- 机器学习-聚类(clustering)算法:K-means算法
1. 归类: 聚类(clustering):属于非监督学习(unsupervised learning) 无类别标记(class label) 2. 举例: 3. Kmeans算法 3.1 clust ...
- 聚类clustering
聚类:把相似的东西分到一组,是无监督学习. 聚类算法的分类: (1)基于划分聚类算法(partition clustering):建立数据的不同分割,然后用相同标准评价聚类结果.(比如最小化平方误差和 ...
- 海量数据挖掘MMDS week5: 聚类clustering
http://blog.csdn.net/pipisorry/article/details/49427989 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [综]聚类Clustering
Annie19921223的博客 [转载]用MATLAB做聚类分析 http://blog.sina.com.cn/s/blog_9f8cf10d0101f60p.html Free Mind 漫谈 ...
随机推荐
- 全球级的分布式数据库 Google Spanner原理
开发四年只会写业务代码,分布式高并发都不会还做程序员?->>> Google Spanner简介 Spanner 是Google的全球级的分布式数据库 (Globally-Di ...
- [Beginning SharePoint Designer 2010]列表和库&内部内容类型
本章概要: 1.SPS如何组织管理数据 2.如何创建列表和文档库 3.如何使用视图来过滤分类,分组列表和库 4.如何创建内容类型来应用一个定义好的结构到数据和文档中
- 怎样通过反编译工具与插件 查看java *.class 文件源代码
Java Decompiler[java 反编译]:开发了反编译工具.能够方便查看*.class 文件源代码.以下介绍几种查看源代码的方式:工具&插件 1.JD-GUI JD-GUI 是显示 ...
- .net mvc Model 验证总结
ASP.NET MVC4中的Model是自验证的,这是通过.NET4的System.ComponentModel.DataAnnotations命名空间完毕的. 我们要做的仅仅是给Model类的各属性 ...
- Android Handler 具体解释
Android开发中常常使用Handler来实现"跨越线程(Activity)更新UI".本文将从源代码角度回答:为什么使用Handler可以跨线程更新UI?为什么跨线程更新UI一 ...
- 【为小白菜打call】
作为本校的竞赛生,我必须为我大OJ打call caioj,小白菜oj,顾名思义,就是为刚踏进OI的“小白菜”们准备的网站,里面包含了许多专题内容,各种模版和讲解视频 而且对于刚学习C++的同学,更有帮 ...
- EMC存储划分lun过程
下图是EMC存储系统示意图: 若将lun打散重建,需按以下步骤进行: 1. 在Storage Groups上点右键选择Select Luns,在打开的窗口中,将右边Selected Lun项下的lun ...
- [POJ 1316] 树上的询问
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=1316 [算法] 点分治 由于边权较大,笔者在计算时使用了STL-set 注意当询问为 ...
- SQLserver中用convert函数转换日期格式(1)
SQLserver中用convert函数转换日期格式2008-01-15 15:51SQLserver中用convert函数转换日期格式 SQL Server中文版的默认的日期字段datetime格式 ...
- Redis学习笔记(七) 基本命令:Set操作
原文链接:http://doc.redisfans.com/set/index.html 虽然set和list很相似但还是有一些差别的,如set中的顺序没有先后之分,所以不像list一样可以在首尾增删 ...