is == id 的用法;代码块;深浅copy;集合
4-1-2 Python基础数据类型 - 7种
(一).Outline
1.整型(int)
1.1py2 & py3的区别
- 1.整数类型
- 2.除法
1.2强制转换:2种类型可转。
- int('str中的可渡之人')【重要】
- int(bool)
1.3进制
- 4种进制介绍
- 进制转换
2.布尔类型(bool)
强制转换:
1.其他6种数据类型均可转成bool。bool(int/str/list/tuple/dict/set)
2.强制转换中bool为False的情况:7种,0,'',[],(),{},set(),None。
3.字符串(str) -不可变。有序。
3.0字符串定义
(一).公共功能 -即,其他数据类型也可能会有的功能。
3.1加 - str + str
3.2乘数字 -str * int
3.3索引/下标
3.4切片
- 坑:list -若取不到值,则打印空列表。
- str -若取不到值,则什么都不打印(计算机内部自动将str两边的引号去掉了)。
3.5步长
3.6for循环
- for循环 -遍历str中的各元素
- for循环+range:遍历str中各元素的索引
3.7len
3.8in 判断某字符是否在str中
(二).str的方法
写在前面:因为str是不可变数据类型,故对其进行操作,并不会对原来的值产生影响。而是生成一个新的字符串。这是由str本身是不可变数据类型所决定的。
3.8字符串方法 :
(1).常用方法 -11个。
ps:其他操作方法可去pycharm里查看源码。操作:写上str,按住ctrl点进去。即可查看源码。
1.全部大写 .upper() 返回值:新str
- .upper() 全部变大写
- .isupper() 判断是否全部是大写 返回值:bool
2.全部小写 .lower() 返回值:新str
- .lower() 全部变小写
- .islower() 判断是否全部是小写 返回值:bool
- .casefold() 将所有字符(拉丁文)全部变为小写 返回值:新str # py3中才有此功能。
- 应用场景:字符串大小写做验证码
3.判断是否以什么开头 .startswith('某字符/某序列') 返回值:bool
4.判断是否以什么结尾 .endswith('某字符/某序列') 返回值:bool
5.字符串替换 .replace('被替换的字符/子序列','要替换为的内容') 返回值:新str
.replace('被替换的字符/子序列','要替换为的内容',1/其他数字) -从左到右数,替换掉str里的几个字符/子序列.
- 格式
- ps:
- 应用场景:敏感字符替换。
6.去除头尾左边/右边/两边的空格/换行符(/n)/制表符(/t)/特定字符 返回值:新str
- 去除str两边的空格/换行符/n/制表符/t/特定字符
- rstrip .rstrip() -去除str右边的空格 返回值:新str
- lstrip .lstrip() -去除str左边的空格 返回值:新str
- strip .strip() -去除str两边的空格 返回值:新str
- str.rstrip/lstrip/strip('要去除的字符') 返回值:新str
- 去除str里边的空格/换行符/n/制表符/t
- str.replace('空格/换行符/n/制表符/t', '')
7.拼接 -用某符号(连接符) 将str的各字符连接起来。 '连接符'.join(序列)。 返回值:新str 。
ps: 序列里的元素必须全部是str才能用join拼接!!
8.分割 .split('根据str里的某字符进行分割') 返回值:list。list里的元素均是str片段。
.split('根据str里的某元素进行分割',1/其他数字) -从左向右数,分割前几个。 返回值:list。
.rsplit('根据str里的某元素进行分割',1/其他数字) -从右向左数,分割前几个。 返回值:list。
- ps:is系列的返回值是bool 。
- split -从左到右切
- rsplit -从右向左切
拓展(了解):.partition/rpartition('str中的某字符-->分割符') # 总共分成3份:前 分割符 后。
9.字符串格式化 -3种 %,.format,f。
10.is系列 .isdecimal() 返回值:bool。
- ps
- 判断str中是否是十进制数字 .isdecimal()
- .isdecimal() -好! # '1'-->True; '二'-->False; '②'-->False
- .isdigit() # '1'-->True; '二'-->False; '②'-->True
- .isnumeric() # '1'-->True; '二'-->True; '②'-->True
- 判断str中是否是数字/字母/数字+字母 .isalnum()
- 判断str中是否是汉字/字母/汉字+字母 .isalpha()
11.str的编码(把str-->二进制) *******
12.练习题
13.写在最后:strip、split分左右。lstrip/rstrip/strip -3种,split/rsplit -2种。
(2).不常用方法
- 1.首字母大写 .capitalize() 返回值:新str
- 2.大小写转换 .swapcase() 返回值:新str
- 3.统计某字符/子序列出现的次数 .count('某字符') 返回值:int
- 4.查找某字符的索引位置
- .find('某字符') 若字符不存在,则返回-1。
- .find('某字符') # 从左边开始找
- .rfind('某字符') # 从右边开始找
- .index('某字符') 若字符不存在,则报错。
- .index('某字符') # 从左边开始找
- .rindex('某字符') # 从右边开始找
- .find('某字符') 若字符不存在,则返回-1。
- 5.居中 .center(总长度, '两边的填充物') # 不写填充物,则默认用空格填充。
- 将str居中 .center(总长度, '两边的填充物')
- 将str居左 .l just(总长度, '右边的填充物')
- 将str居右 .r just(总长度, '左边的填充物')
- 6.将str中每一个单词的首字母变成大写 .title()
- 7.判断str是否是空白 .isspace() # 空str,判定为False。返回值:bool。
(三).强制转换
写在前面-1:int和bool此2种可直接转。list/tuple/dict/set此4种容器类要想转成str,要通过str的join方法。
写在前面-2:用join时,序列里的元素必须全部都是str类型才可以转。
写在前面-3:当要拼接的序列是dict时,转换的只是dict的key。
- str(999) # '999'
- str(true) # 'True'
- list-->str ,s1 = ''.join(li) # li里的元素必须是str。
- tuple-->str,s2 = ''.join(tu1) # tuple里的元素必须是str。
- dict-->str, s3 = ''.join(dict1) # 转换的只是dict的key。
- set-->str,s4 = ''.join(set1) # set里的元素必须是str。
4.列表(list) -可变数据类型。有序。
4.0列表定义
(一).公共功能 -10个全都具备。
4.1列表相加
4.2列表*int
(1).查 -索引,切片,步长。for循环。4种公共方法查。
4.3索引
4.4切片
- 坑:list -若取不到值,则打印空列表。
- str -若取不到值,则什么都不打印(计算机内部自动将str两边的引号去掉了)。
4.5步长
4.6for循环 只适用于可迭代的数据类型:str/list/dict/set/tuple。
- for循环 -遍历list中的各元素
- for循环+range:遍历list中各元素的索引
- for循环的嵌套。-拆了再拆,适用于list元素中的可迭代类型。
4.7len
(2).删 -公共1种。(独有3种) # 仅仅是删除,没有返回值,也不报错。
4.8删除 list中的某个/某些元素 。
写在前面:只适用于可变数据类型中的:list/dict(set虽可变,但无序,故不能索引)。
- del li[索引] 按索引删
- del li[起:终] 按切片删
- del li[起:终:步长] 按步长,跳着删
(3).改 -只有公共这1种。
4.9修改list中的某元素 li[索引] = '新元素'。
最外层元素:对于本层元素,不管可变不可变都可修改。
深层元素:不可变数据类型的元素(str/int/bool),不能修改;
可变数据类型元素(list/dict/tuplr/set),可以修改。
4.10练习题
4.11in
(二).list的方法 -增&删&反转/排序/统计/通过元素 获取索引。
写在前面:list和str不一样。list是可变数据类型.。故,对其进行操作,会直接在原来的对象上产生变化。
(4).增 -3种。
4.9列表的增
- append 追加
- insert 插入
- extend 迭代着添加
(5).删 -3种。
4.10列表的删
- pop 根据索引删。a.不写索引,默认删最后一个;b.可以设置返回值。
- remove 根据元素删。没有则报错。
- clear 清空
4.11列表的其他操作
- 反转
- 排序
- 统计
- 通过元素 获取下标/索引
(三).list的嵌套
- 取值 -根据索引一层一层取值。
- 改值 -先找到要修改的元素,根据li[索引] [索引]...[索引] = 新值的格式去做改值操作。
(四).list的强制转换
写在前面-1:只能将容器类的数据类型转换为list。
写在前面-2:str-->list,是将str的每个字符作为list的元素。
(五).list的坑 -2个。
- 1.循环添加
- 2.列表循环删除
5.元组(tuple) -不可变。有序。
- 5.0定义
(一).公共功能 -共7个。tuple不能删和改。
5.1元组相加
5.2元组*int
5.3索引
5.4切片
5.5步长
5.6for循环
5.7len
5.8in
(二).tuple的方法(无)
(三).tuple的强制转换 -同list。
6.字典(dict) -可变。3.5版本后开始有序。
6.0字典定义
6.0‘字典的创建方式 -3种
(一).公共功能 -
6.1索引
6.2for循环
6.3len
6.4修改 dict['键'] = '值' #键存在,则改值;键不存在,则添加键值对。
6.5删除 del dict[键] #通过键删除键值对。
6.6in -判断字典中的键/值/键值对是否在dict中。
(二).字典的方法 -keys,values,items。
1.keys,values,items 3种。**
- 获取字典的键
- 获取字典的值
- 获取字典的键值对
- 解构
- 循环字典获取键/值/键和值。
2.查 dict.git('键',返回值) ** # 键不存在,不报错,可以自定义返回的结果。
3.删 dict.pop('键') 可以看到删除的值(不常用)
4.增 dict.update({'键':值,'键':值}) 键不存在,增加键值对;键存在,则更新(覆盖)(不常用)
(三).字典的嵌套
(四).字典的坑 -fromkeys。
7.集合(set) -可变。无序。
7.0定义
(一).公共功能 -
7.1for循环
7.2len
7.3in -判断字典中的键/值/键值对是否在dict中。
(二).集合的方法 -增&删&求交/并/差/对称差集。
- add 追加 **
- set.update({要增加的集合}) 批量增加 *
- discard 删除 ** # 元素不存在,不会报错。
- 交集:set.intersection(集合/列表/元组) 或 set1 & set2。
- 并集:set.union(集合/列表/元组) 或 set1 | set2。
- 差集:set.difference(集合/列表/元组) 或 set1 - set2。# 谁在前面就是求谁的差集。
- 对称差集(反交集):set.symmetric_difference(集合/列表/元组) 或 set1 ^ set2。
8.None -一种特殊的数据类型。
- None是种特殊的数据类型,该类型表示空(无任何功能,专门用于提供空值)。
9.常用的类型转换_小结
10.七种数据类型_小结
- 7种数据类型对比
- 公共功能小结
11.for循环
12.len -获取长度(仅适用于7种数据类型中的:str/list/tuple/dict/set,int和bool不行)
- 使用while循环 -打印str/list/tuple/dict/set中的每个元素
- 使用for循环 -打印str/list/tuple/dict/set中的每个元素
13.内置函数: range() -用在for循环中。
14.内置函数: type()
(二).Content
一.整型 int
def:int数字/整型(整数类型):eg:666,7and so on,被称为数字/整型。
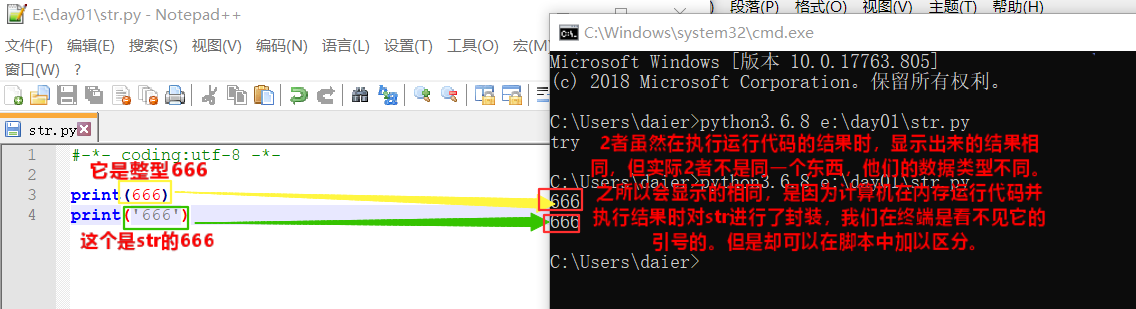
ps:int可进行+-*/ 等运算。
1.在py2 & py3中的区别:2个
(1). 整数类型不同:
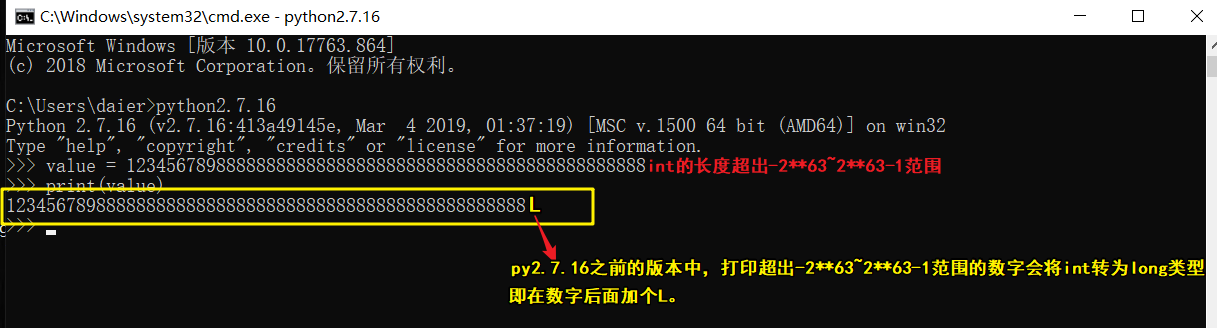
在python2x(2.7.16版本之前的版本)中:对int的长度有限制,
在32位机器上,整数的位数为32位,取值范围为-2 * * 31~2 * * 31-1,即-2147483648~2147483647;
在64位系统上,整数的位数为64位,取值范围为-2 * * 63~2 * * 63-1,即-9223372036854775808~9223372036854775807;
超出长度之后就会变为long类型(长整型)。
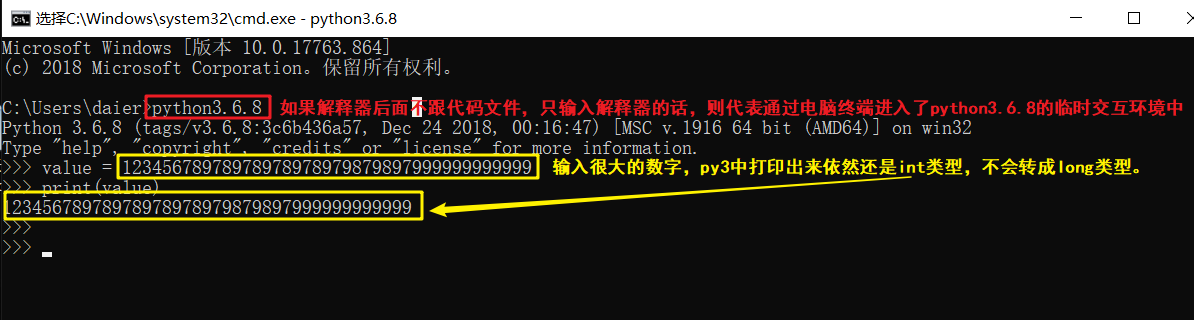
在python3x中:
只有int没有long,所有数字都是int类型。
小结:
在py2x中,有int和long类型,如果用户输入的数字特别大,py2会自动将int转换成long类型;
在py3x中,只有int,没有long。所有的整形全部用int来代指。
try一下:
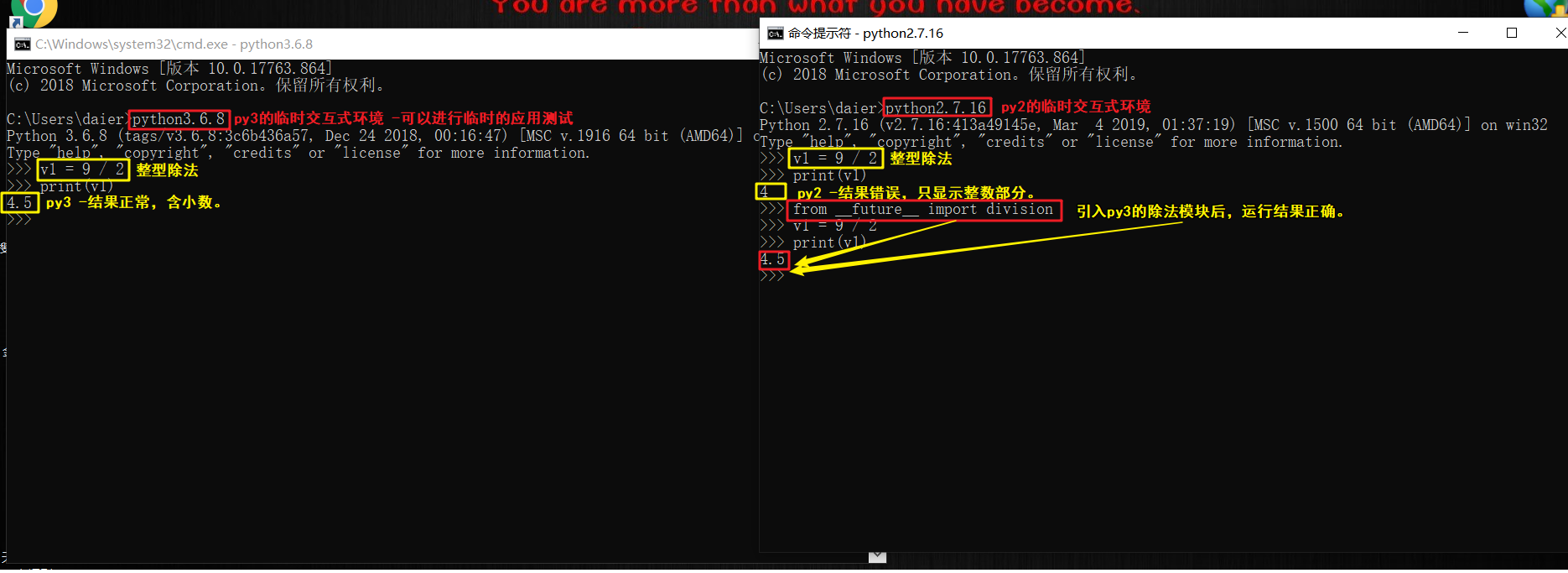
(2).在python2中做整型除法时,只能保留整数位,如果想要保留小数位,必须先导入一个模块。
# from __future__ import division # division 除法; # 2个_.
value = 9/2
print(value) #4.5
2.强制转换:2种类型可转。
- int('str中的可渡之人')【重要】
# str -->int 只渡可渡之人。
s = '18' # str里必须是数字才可转int。
value = int(s)
print(value) # 18
- int(bool)
# bool -->int
v1 = int(True)
v2 = int(False)
print(v1, v2) # 1 0
3.进制
(1). 四种进制
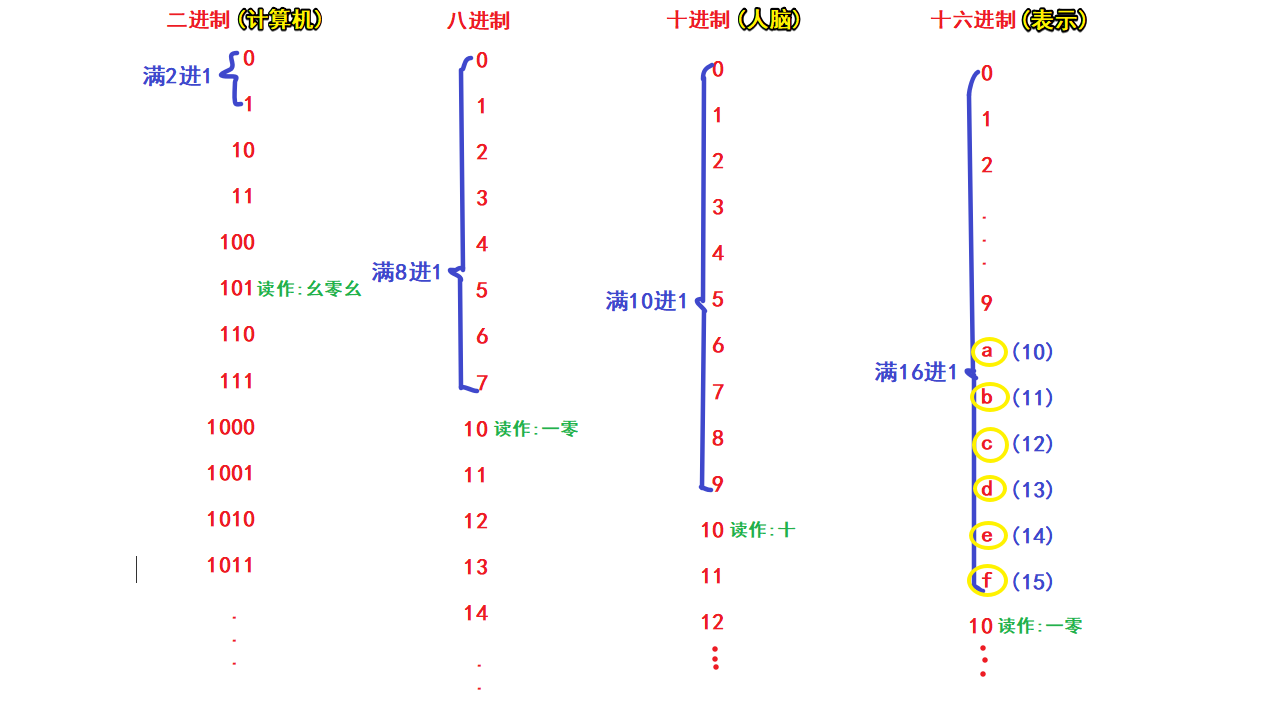
二进制:计算机只认识二进制。计算机底层使用的是二进制语言(机器语言)。一般是0b开头。
对于计算机而言无论是文件存储/网络传输输入本质上都是:二进制(010101010101)。
如:电脑上存储视频/图片/文件都是二进制;QQ/微信聊天发送的表情/文字/语言/视频也全部都是二进制。ps: 对于计算机而言:
八进制:计算机内部使用。
十进制:通常人脑使用的就是十进制。一般情况下计算机可以获取十进制,然后在内部会自动转换成二进制并操作。
十六进制:一般用于表示二进制(用更短的内容表示更多的数据)。经常用来表示大数据。因为相比其他3种进制而言,十六进制的10-15只用一位表示,简洁。一般是\x开头。
(2). 进制转换
十进制 -->二进制
- 采用"除2取余,逆序排列"法。具体做法是:用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。

42 -----> 0010 1010 # 逆序排列,自右向左写,不够8位用0补齐
二进制 -->十进制
- 采用二进制上的数字乘以2的位数次方,再相加.(自右向左8位依次是2**0,...2的7次方)
0001 1010 ------> ? 26
b = 1*2**1 + 1*2**3 + 1*2**4 # 幂次:自右向左8位依次是2**0,...2的7次方。
# print(b) # 26
bit_length() 十进制转化成二进制的有效长度(有效位数)
# bit_length 有效的二进制的长度
a = 4
print(a.bit_length()) # 3
二.布尔值 bool
2.1布尔值
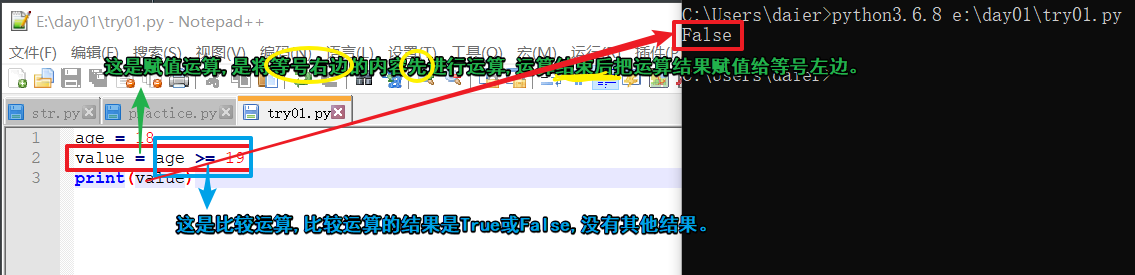
def:布尔值(bool):True/False,判断真假。
1.python语法 人类语言 计算语言
2. True 真 1
3. False 假 0

举例:
2.2强制转换:
- 1.其他6种数据类型均可转成bool。bool(int/str/list/tuple/dict/set)
- 2.强制转换中bool为False的情况:7种,0,'',[],(),{},set(),None。
三.字符串 str/string -不可变。有序。
3.0 字符串的定义
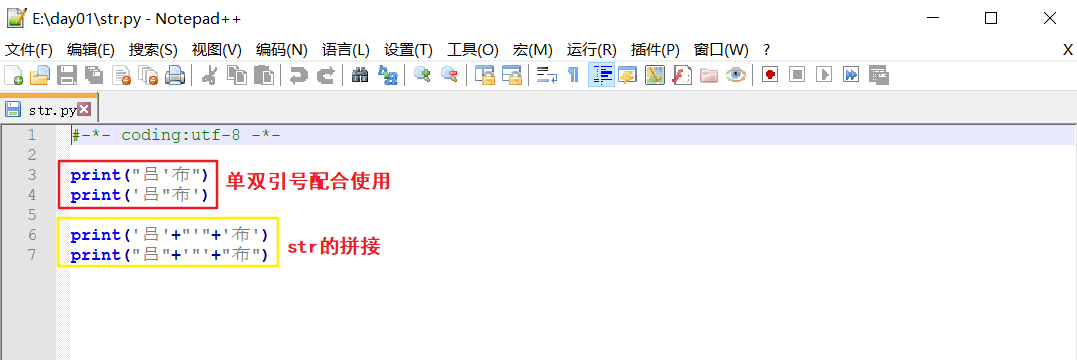
def:字符串(str):被英文单/双/三引号引起来的(凡是被引号引起来的),一般称为字符串。可以保存少量数据并进行相应的操作。
eg:'xiaohei' or "吕布" or """小吕布真可爱"""/'''吕布是暖男'''。
**ps-1: ** 单双引号可以配合使用,以作区分。但同一个str的首尾引号要一致。
ps:单双引号切换:英文模式下,不按shift是单引号,按shift是双引号。
eg:打印 吕'布 and 吕"布。
代码运行结果如下:

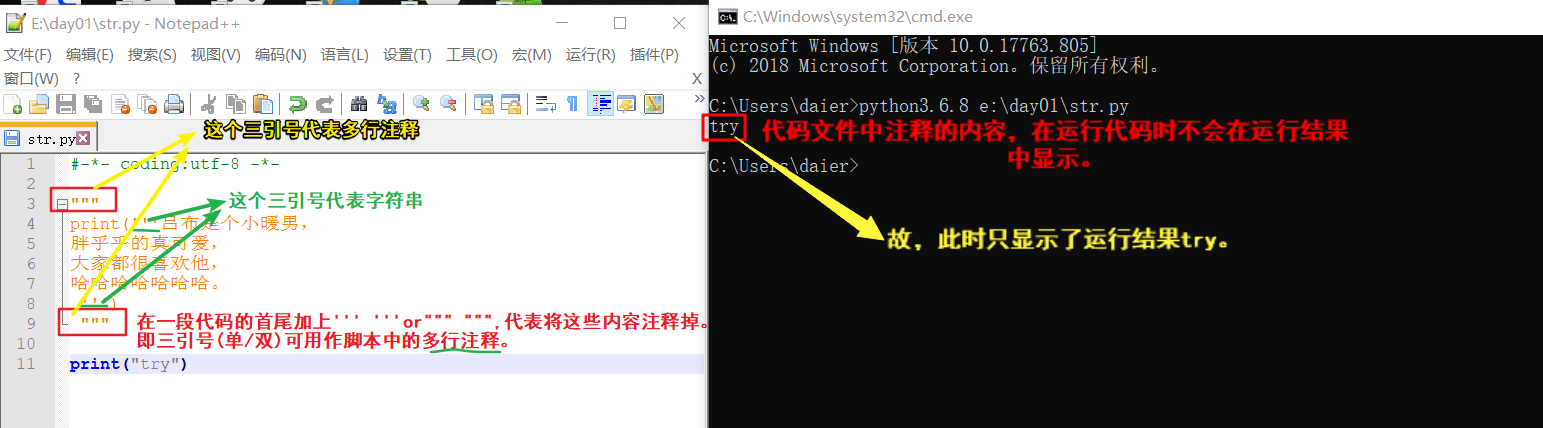
ps-2: 被三引号引起来的内容,是支持换行的字符串。它仍是str,只不过可换行而已。
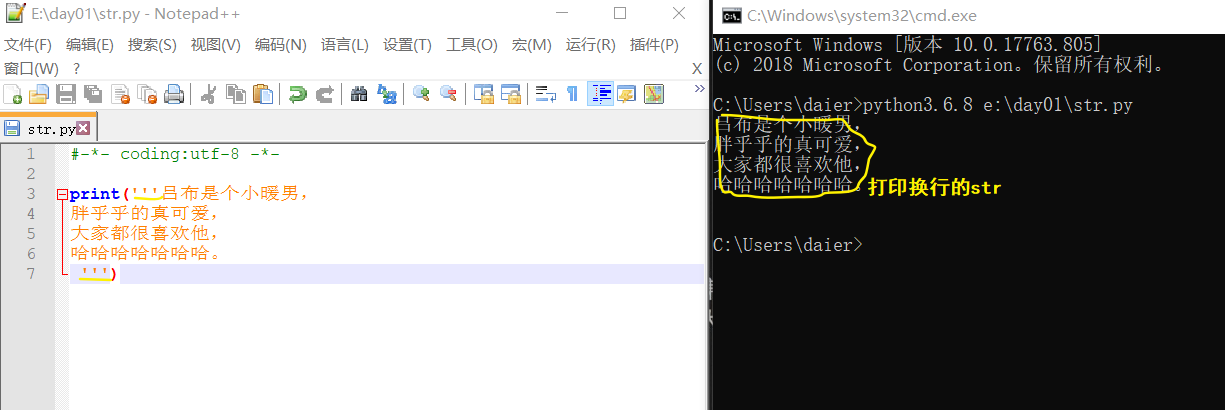
或:

注:在代码文件中,三引号可用于多行注释,'''注释内容'''/"""注释内容""",它依然是个str,只不过没有被引用而已。
(ps:前面有变量接收,那它就是个str,前面若没有变量接收,那它就是个多行注释。)
(一).公共功能 -即,其他数据类型也可能会有的功能。
3.1字符串加 - str + str
运算规则:字符串+字符串,即字符串的拼接 。
s1 = "5"
new_s = s1 + "20"
print(new_s) # 520
ps:字符串的拼接是将引号里的内容直接拼接到一起,而不是进行运算。若遇到str中的可渡之人,要与整型的相加区分开,看好是str相加还是int相加。
注:字符串不能和int相加,否则报错。因为2者数据类型不同,故不能相加。要转换后再进行运算。

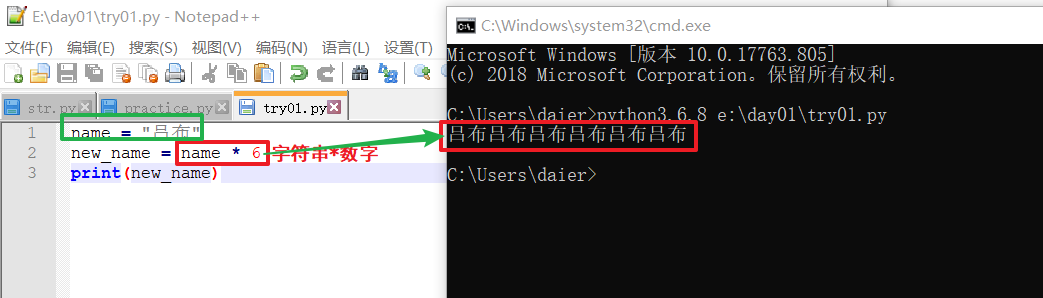
3.2字符串乘 - str * int
运算规则:字符串×int !!!
ps:乘的只能是int。
运行结果是:int个这样的str拼接到一起。
3.3 索引/下标
写在前面:str里的每一个字符均有其对应的索引。根据索引我们可以找到str中的某个字符。
def:val = str[索引],val就是根据索引取到的str中的某字符。
str的索引有两种排序方式:
1.从左向右排序,第一个索引(str左边第一个字符的索引)是0。
2.从右向左排序,第一个索引(str右边第一个字符/str倒数第一个字符的索引)是-1。
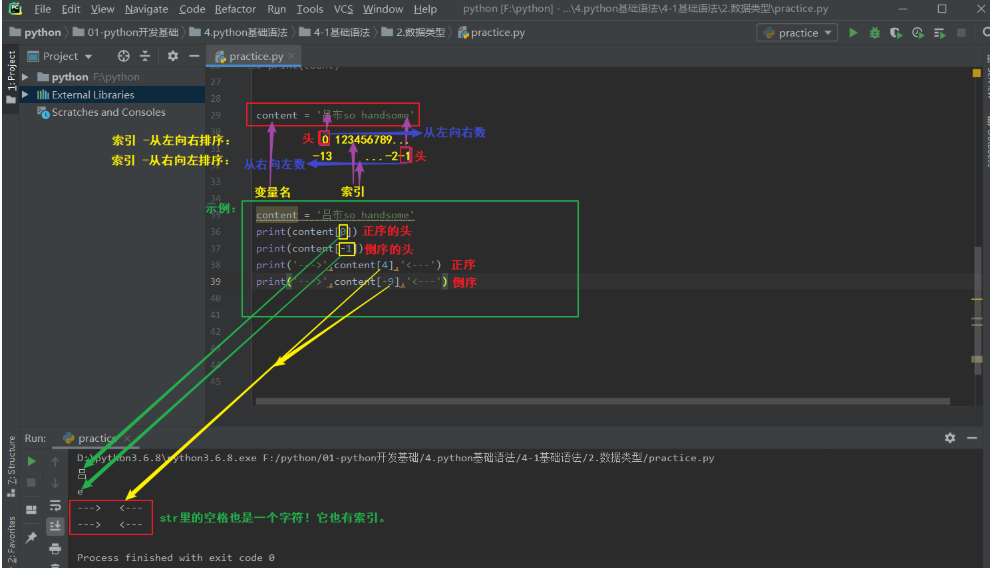
ps-1:根据索引取值 -取到的某个字符仍是str类型。
ps-2:根据索引取值时,2种索引排序方式,要取的元素离哪边近就从哪边开始数(怎么方便怎么取)。
ps-3:根据索引取值 -超出索引范围,会报错。
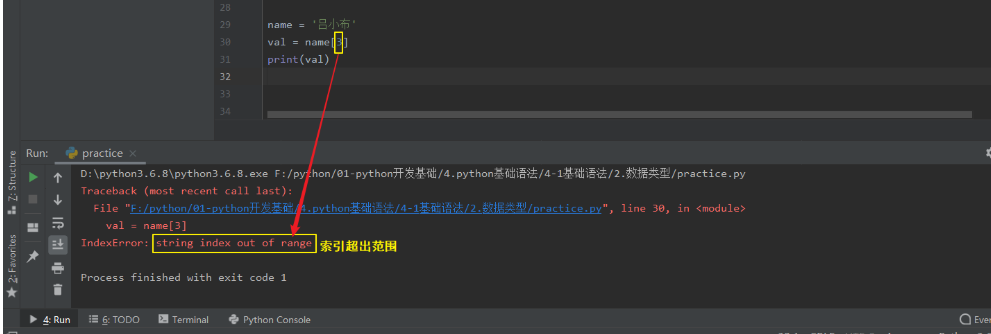
3.4 切片
写在前面(坑):
- 1.list -若取不到值,则打印空列表。
- 2.str -若取不到值,则什么都不打印(计算机内部自动将str两边的引号去掉了)。
# 看代码写结果:
l1 = [1, 2, 3, 4, 5]
print(li[10:]) # []
s = '1,2,3,4,5'
print(s[10:]) # 什么都不打印。
# 诠释:按理说结果应该是空str,但最后却什么都不打印。这是因为计算机内部自动将str两边的引号去掉了。
def:[起始位置的元素索引 : 终止位置的元素索引+1],中间必须使用分号。
ps-1:切片 -右边是开区间,取不到。 (-终止位置索引对应的字符取不到,取到的是它前面的哪个字符)。
即,想取到谁,就顺着x轴往右顺延一个(无论索引是正序/倒序都是向右顺延,因为步长默认1->正序,故向右顺延)。
即终止索引算数+1。
ps-2:从头开始取,规定头写成空。eg: value = name[:3] ;
ps-3:取到尾,规定尾写成空。eg:value = name[2:] -代表从索引2的字符一直取到最后1个字符。
ps-4:从头取到尾 -全切:[:]
ps-5:切片/步长取值时,务必保证索引的方向和步长的方向一致!
ps-6:切片取值,不写步长,则步长默认是1 -正序。 —故索引方向必须也是正序!
ps-7:你写的0,计算机会默认它是正序起始的0,而不是倒序起始的-1往右顺延1得到的0!!!
故,在写切片的首尾时,一定要书写规范,if是从头切/取到尾,则一定要写成空!可以避免出错!
示例1:注意切片取值中什么都不打印的例子。
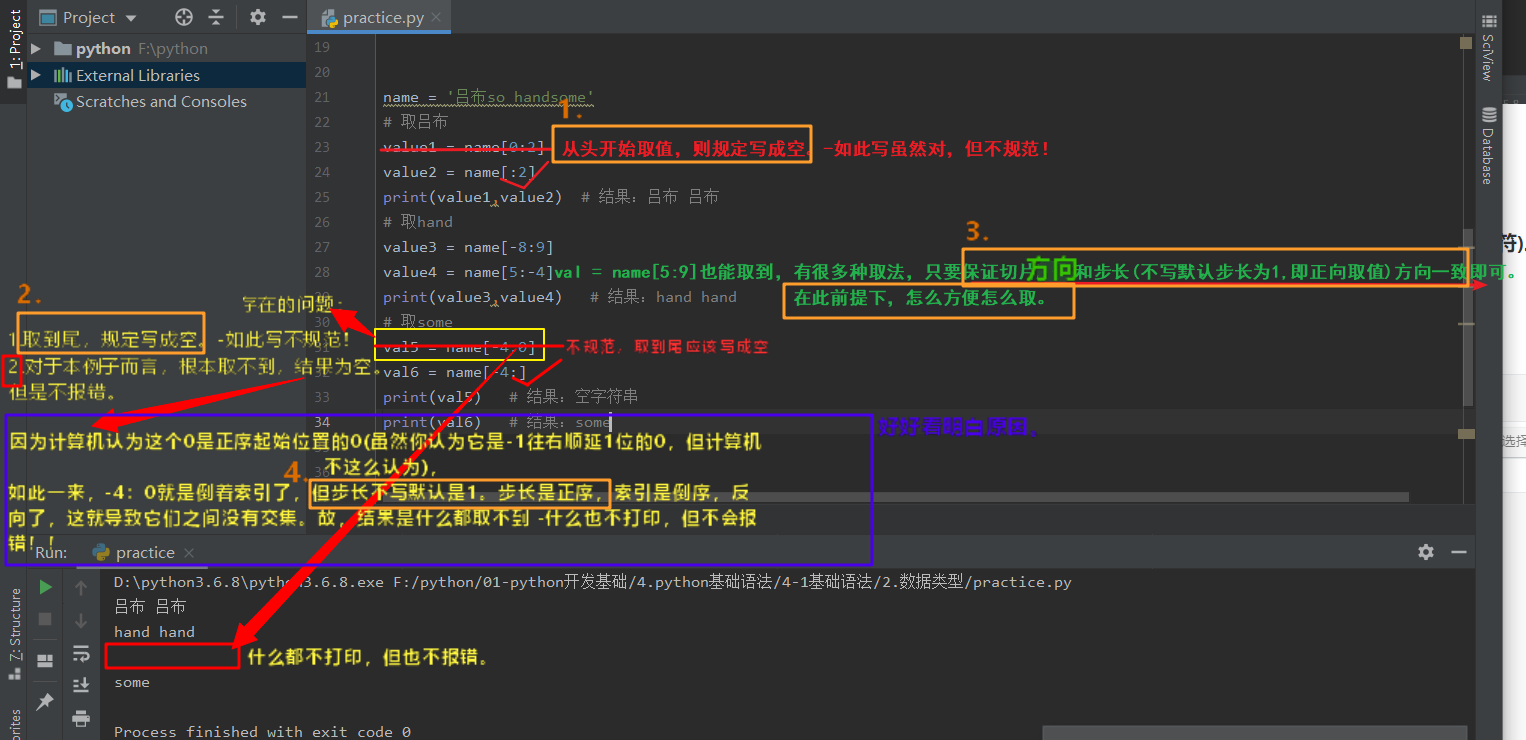
示例2:步长取值中结果什么都不打印的例子:
(原因:也是索引方向和步长方向反向了,导致2者无交集,故结果什么都取不到。)
练习题:
# 需求:让用户输入任意一个str,取这个str的最后2个字符。
方法一:
data = input('请输入:')
value = data[-2:]
print(value)
方法二:len -更严谨,因为可加个if判断这个str够不够2个字符再取切片。
data = input('请输入:')
total_len = len(data)
value2 = data[total_len - 2:total_len]
print(value2)
# 完整版:
value = input('请输入内容:')
total_len = len(value)
if total_len >= 2:
val = value[total_len - 2:total_len]
print(val)
else:
print('输入有误')
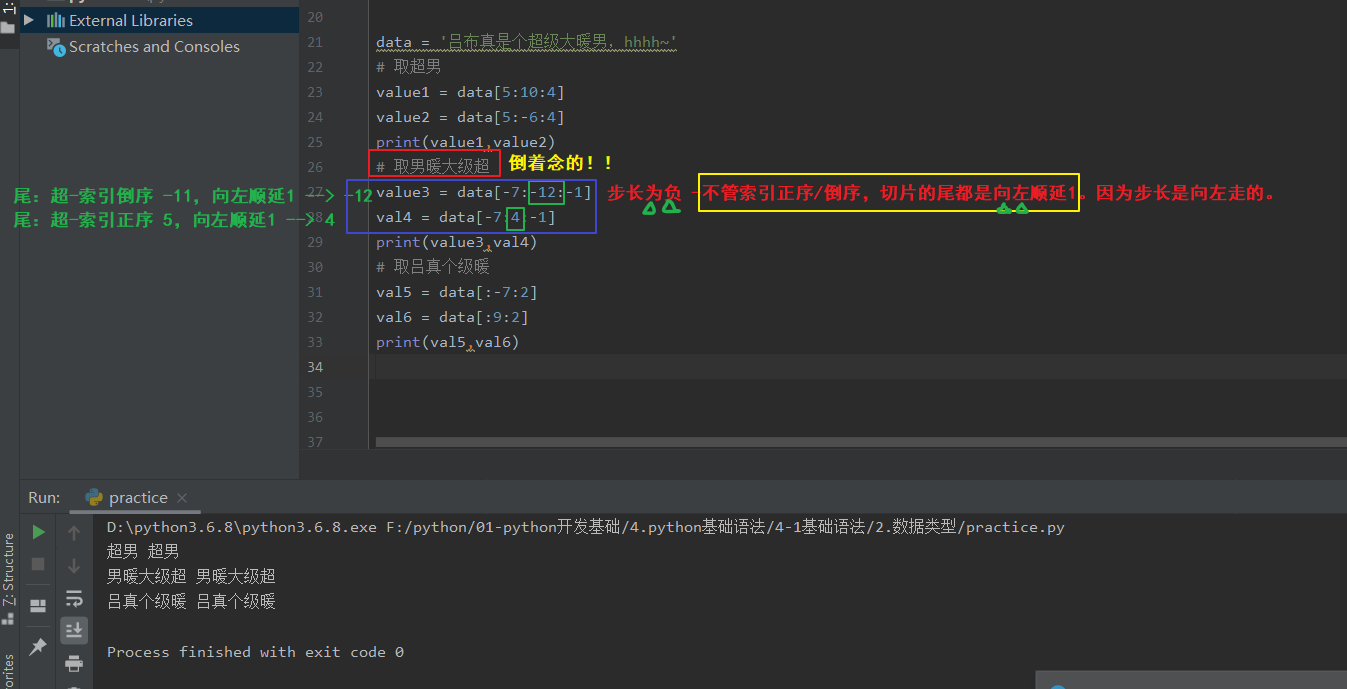
3.5 步长
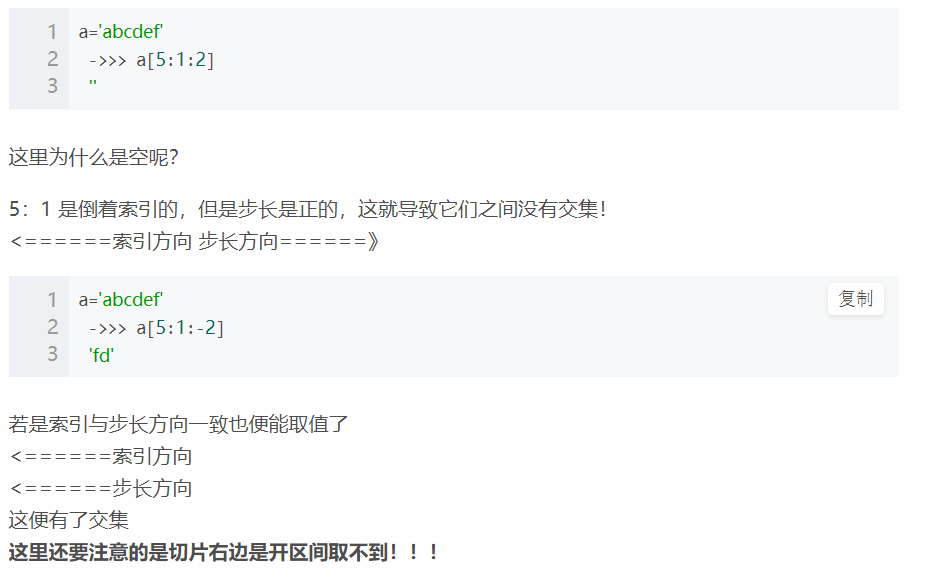
def:[起始位置的字符索引 : 终止位置的字符索引 : 步长],中间必须使用分号。
ps:前面的切片部分依然沿用切片取值的规则和ps。
(1).切片的ps:
ps-1:切片 -右边依然是开区间,取不到。-要想取到某个字符,要将该字符对应的索引沿步长方向往后顺延1。
ps-2:3种书写规则:
a.从头开始取,规定头写成空;
b.取到尾,规定尾写成空。-切记不要写成0!!计算机会默认这个0是正序起始位置的0。如此一来,就会导致索引方向与步长方向反向,最后啥都取不到!
c.全取是str[:]
(2).步长的ps:
ps-1:步长是几就从起始位置开始沿着步长方向查几个字符之间的间隔。-步长是几就查几个间隔,即就走几步。
ps-2:步长是正数,则是正序取;步长是负数,则按倒序取。
ps-3:步长取值时,要保证索引的方向和步长的方向一致! -如果反向了,则什么都取不到。什么都不打印。
ps-4:步长为负时,倒序取值,取出来的str也是倒着的!!!
ps-5:步长为负时,倒序取值,此时切片的尾是向左顺延1。
示例:
(3).interview
# 需求:将str进行翻转。 # 8种方法。
# 写在前面:str的方法里没有revers功能,revers是list的功能。数据类型的方法不要混淆!
# 法一(推荐):步长 -最简单。
name = '吕布睡着了'
new_value = name[::-1]
print(new_value)
# 法二:while 循环 + str相加。
name = '吕布睡着了'
result = ''
index = len(name) - 1
while index >= 0:
result = result + name[index]
index -= 1
print(result)
# 法三(变态-不推荐):for循环 + str相加。 -把for当成while来用。只不过不用手动自加让其转起来。
result = ''
index = len(name) - 1
for item in name:
result = result + name[index]
index -= 1
print(result)
# 法四:for循环 + str相加 + range倒序。
result = ''
max_index = len(name) - 1
for item in range(max_index, -1, -1):
result = result + name[item]
print(result)
# 法五(推荐):str转为list,用list的独有方法-reverse。再将列表用join转回str。
s = '吕布睡着了'
l = list(s)
l.reverse()
reversed_s = "".join(l) # 用join将序列str/列表/元组/字典中元素用某连接符连起来。
print(reversed_s) # 返回值:新str。
# 结果:了着睡布吕
# 法六:while循环 + 列表 + join。
s = '吕布睡着了'
li = []
index = len(s) - 1
while index >= 0:
li.append(s[index])
index -= 1
result_s = ''.join(li)
print(result_s)
# 法七:for循环 + 列表 + range + join。
s = '吕布睡着了'
li = []
for item in range(len(s) - 1, -1, -1):
li.append(s[item])
result_s = ''.join(li)
print(result_s)
# 法八:for循环 + 列表 + reversed(字符串/列表/元组) + join。
# 写在前面:补充一个知识点。
# 1.reversed()是个序列,一般和for循环一起使用。不能单独使用。
# 2.它的应用对象只能是有序的数据类型:str/list/tuple。dict和set均无此方法(因为2者内部是利用hash算法存储和查询的,无序)。
# 3.reversed(字符串/列表/元组)内部代表将str/list/tuple进行反转。但表现不出来。只能和for一起使用。
# 示例1:
s = 'abc'
for i in reversed(s):
print(i)
结果:
c
b
a
# 示例2:
li = [1, 2]
for i in reversed(li):
print(i)
结果:
2
1
# 示例3:
tu = (1, 2)
for i in reversed(tu):
print(i)
结果:
2
1
# 本题:
s = '吕布睡着了'
li = []
for item in reversed(s):
li.append(item)
result_s = ''.join(li)
print(result_s)
# 结果:了着睡布吕
3.6 for循环
写在前面-1:for循环内部自加,不需要我们再去自加让其转起来。
写在前面-2:for循环的对象必须可迭代。eg:字符串/列表/字典/元组/集合这5种可迭代的类型and其他可迭代的序列(eg:range())。)
写在前面-3:for循环可嵌套。
写在前面-4:break和continue在for循环中依然适用。
格式:
for 变量 in 序列:
循环体内容
示例:
# 需求:遍历字符串中的每一个元素。
value = '吕布666'
for item in value:
print(item)
结果:
吕
布
6
6
6
ps:
# ps-1:与for平齐的行,只打印for循环的序列中的最后一个元素。
value = '吕布'
for item in value:
print(item)
print(item) # 只打印最后一个元素。
# 结果:
吕
布
布 # ps-2:break和continue在for循环中依然适用。
value = '吕布666'
for i in value:
print(i)
break
# 结果:吕
value = '吕布666'
for i in value:
print(i)
break
print('啊哈') # 不打印。
# 结果:吕
value = '吕布666'
for i in value:
print(i)
continue
print('啊哈') #不打印。
# 结果:
吕
布
6
6
6
for和while的应用场景:
# 有穷尽优先使用for,无穷尽用while。
练习题:
1.遍历str中的各元素
content = 'MrLin_儒雅先生'
for item in content:
print(item)
2.遍历str各元素的索引
content = 'MrLin_儒雅先生'
max_index = len(content) -1
for item in range(0,max_index + 1):
print(item)
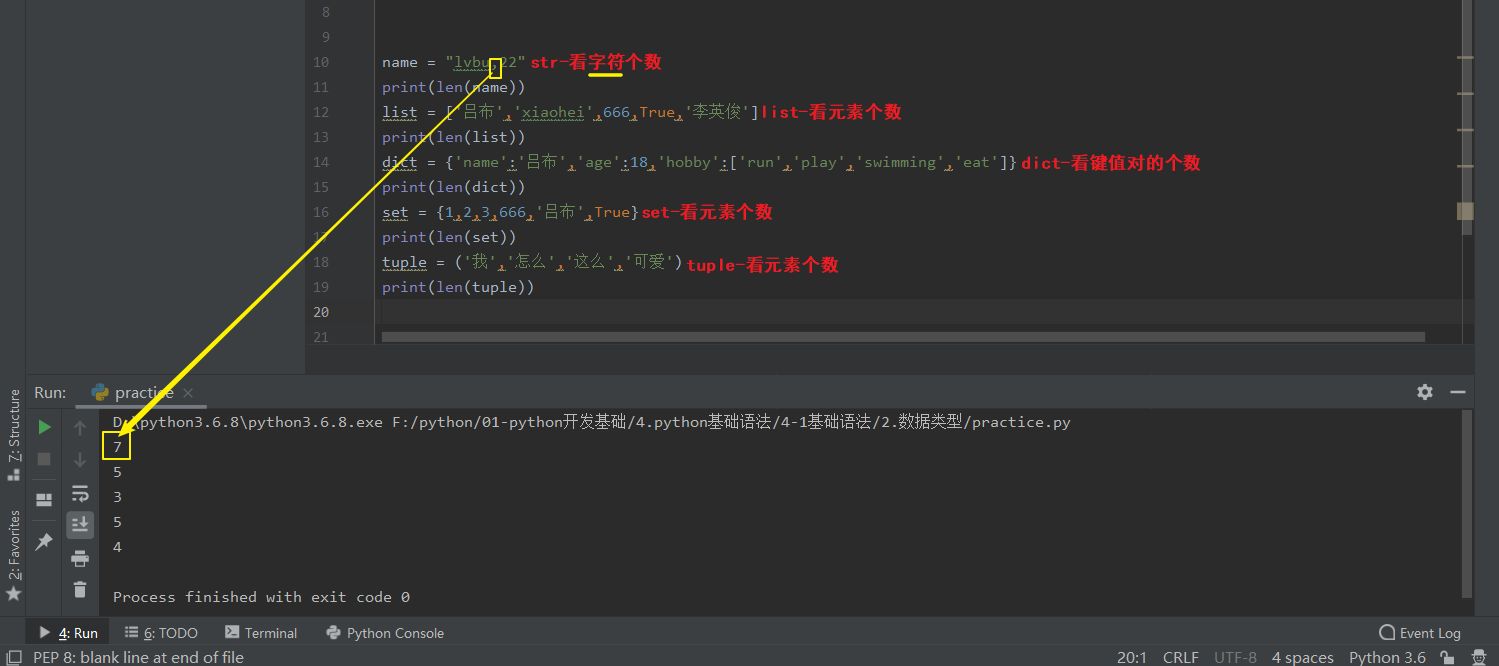
3.7 len -获取长度
(1).definition
ps-1:仅适用于7种数据类型中的可迭代类型(容器类):str/list/tuple/dict/set,int和bool不行。
ps-2:len(5种数据类型)的返回值判断依据。
对于str,返回值是:str中的字符个数;
对于list,返回值是:list中的元素个数;
对于tuple,返回值是:tuple中的元素个数;
对于dict,返回值是:dict中的键值对的个数;
对于set,返回值是:set中的元素个数。
示例:
(2).应用
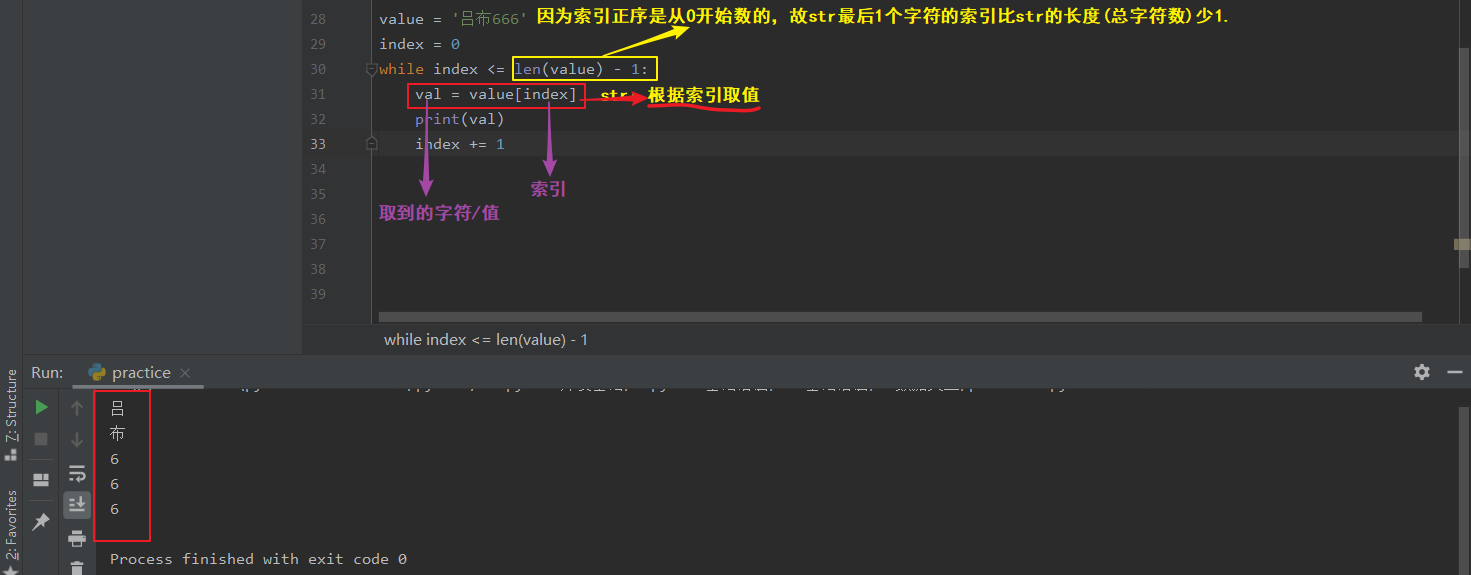
1.使用while循环 -打印str/list/tuple/dict/set中的每一个元素
- 使用while循环遍历str中的每一个元素:
value = '吕布666'
index = 0
while index <= len(value) - 1:
val = value[index] # 根据索引取值。
print(val)
index += 1
2.使用for循环 -打印str/list/tuple/dict/set中的每一个元素
写在前面:for循环时可以循环的数据结构必须是可迭代的:str/list/tuple/dict/set,int和bool不行。
- 使用for循环遍历str中的每一个元素:
value = '吕布666'
for i in value:
print(i)
# 结果:
吕
布
6
6
6
(3).练习题
1.需求:让用户输入任意字符串,获取字符串之后计算其中有多少个数字。
(1).while循环:
content = input('请输入内容:')
index = 0
count = 0
while index <= len(content) - 1:
val = content[index]
if val.isdigit():
count += 1
index += 1
print(count)
(2).for循环:
content = input('请输入内容:')
count = 0
for i in content:
if i.isdigit(): # i.isdigit()的返回值就是True/False,如果是True(即if的条件是True),
count += 1 # 则满足if的条件,就会执行if里面的内容。
print(count)
2.需求:让用户输入任意一个str,取这个str的最后2个字符。
方法一:
data = input('请输入:')
value = data[-2:]
print(value)
方法二:len -更严谨,因为可加个if判断这个str够不够2个字符再取切片。
data = input('请输入:')
total_len = len(data)
value2 = data[total_len - 2:total_len]
print(value2)
# 完整版:
value = input('请输入内容:')
total_len = len(value)
if total_len >= 2:
val = value[total_len - 2:total_len]
print(val)
else:
print('输入有误')
3.8 in -判断某字符是否在str中
- 写在前面:判断某元素是否在序列中,对str/list/tuple/dict/set/range/dic.keys()/dic.values()/dic.items()均适用(只要是序列就适用)。其中,dict只是判断的键。
# 需求:让用户输入内容,判断用户输入的内容中是否含有敏感字符'你胖了',若含有,则用***替换。
content = input('请输入内容:')
if '你胖了' in content:
content = content.replace('你胖了','***')
print(content)
# 结果:
请输入内容:你胖了好多
***好多
(二).str的方法
写在前面:因为str是不可变数据类型,故对其进行操作,并不会对原来的值产生影响。而是生成一个新的字符串。这是由str本事是不可变数据类型所决定的。
3.8 字符串方法
(1).常用方法 -11个。
ps:其他操作方法可去pycharm里查看源码。操作:写上str,按住ctrl点进去。即可查看源码。
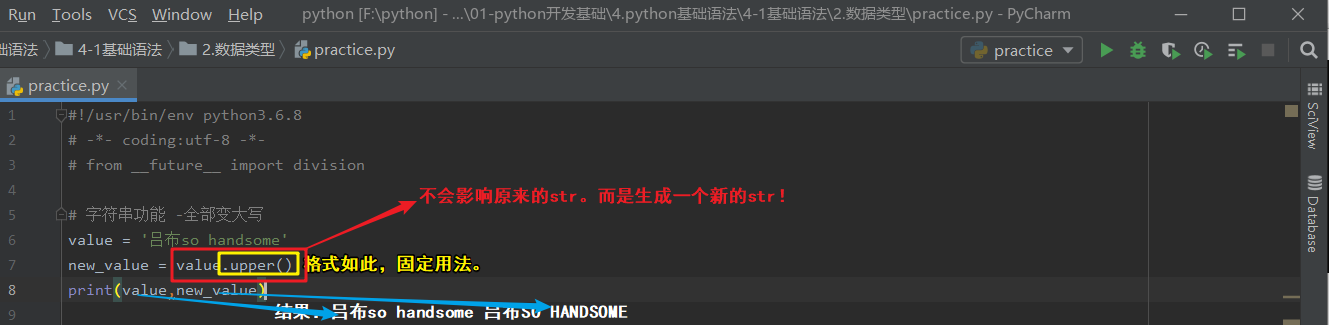
1.全部变大写
# 全部变大写:
# 格式:str.upper() # 变身 -固定格式
s = 'MrLIn'
new_s = str.upper() # 返回值:新str。
print(new_s) # 必须打印新str才能看到修改效果。
# 结果:MRLIN
# 判断是否全部是大写:
# 格式:str.isupper()
s1 = 'LVBU'
print(str.isupper()) # 返回值:bool。
# 结果:True
2.全部变小写
# 1.全部变小写:
value = '吕布STRONG'
new_value = value.lower() # 返回值:新str。
print(value,new_value)
# 结果:吕布STRONG 吕布strong
# 2.判断是否全部是小写:
value1 = 'handsome'
print(value1.islower()) # 返回值:bool。
# 结果:True
# 3(了解).将所有字符变为小写(eg:拉丁文等) # 只有py3版本才有的功能。
格式:new_s = s.casefold() # 返回值:新str。
print(new_s)
ps-1:字符串的方法均不会影响原来的str。而是生成一个新的str。要打印新str才能看到变身后的结果。
ps-2:此方法变身后的结果是个新str。
应用场景:字符串大小写做验证码
# 比较用户输入的验证码(全部大写后)是否和已给验证码大写后一致.
check_code = 'iCbC'
code = input('请输入验证码 %s :' % (check_code,))
if code.upper() == check_code.upper():
print('登录成功')
或:
# 比较用户输入的验证码(全部小写后)是否和已给验证码小写后一致.
check_code = 'iCbC'
code = input('请输入验证码 %s :' % (check_code,))
if code.lower() == check_code.lower():
print('登录成功')
# 完整版:
username = input('输入用户名:')
password = input('输入密码:')
check_code = 'AcBc'
code = input('输入验证码:')
if code.upper() == check_code.upper():
if username == '吕布' and password == '123456':
print('登录成功')
else:
print('用户名或密码错误')
else:
print('验证码错误')
3.判断是否以什么开头
flag = str.startswith('某字符'/'某序列')
print(flag) # 返回值:bool
示例:
# 需求:判断字符串data是否以吕布开头
# 方法一:
data = '吕布so handsome'
val = data[:2]
if val == '吕布':
print('Y')
else:
print('N')
# 方法二:
data = '吕布so handsome'
flag = data.startswith('吕布')
if flag:
print('Y')
else:
print('N')
# 简写:
data = '吕布so handsome'
if data.startswith('吕布'):
print('Y')
else:
print('N')
4.判断是否以什么结尾
.endswith('某字符/某序列') # 返回值:bool
示例:
# 需求:判断字符串data是否以狗粮结尾
# 方法一:
data = '吕布so handsome,真想多喂它点狗粮'
total_len = len(data)
val = data[total_len - 2:]
if val == '狗粮':
print('Y')
else:
print('N')
# 方法二:
data = '吕布so handsome,真想多喂它点狗粮'
flag = data.endswith('狗粮')
if flag:
print('Y')
else:
print('N')
# 简写:
data = '吕布so handsome,真想多喂它点狗粮'
if data.endswith('狗粮'):
print('Y')
else:
print('N')
5.字符串的替换
格式:
str.replace('大爷','**') # 将str中的大爷用**来替换 -全部替换掉。
str.replace('大爷','**',1) # 从左到右数,只替换str里的第一个‘大爷’。
str.replace('大爷','**',2) # 从左到右数,替换str里的前两个‘大爷’。
ps-1:字符串的此操作方法不会影响原来的str。而是生成一个新的str。
要打印新str才能看到变身后的结果。
ps-2:变身后的结果仍是str。
ps-3:只能从左到右替换,没有从右向左替换这种操作方法。
示例:
msg = '吕布真可爱,还真舍不得送给你大爷。舍不得送给你大爷!舍不得送给你大爷!'
new_msg = msg.replace('大爷','**')
print(new_msg)
# 结果:吕布真可爱,还真舍不得送给你**。舍不得送给你**!舍不得送给你**!
msg = '吕布真可爱,还真舍不得送给你大爷。舍不得送给你大爷!舍不得送给你大爷!'
new_msg = msg.replace('大爷','**',1)
print(new_msg)
# 结果:吕布真可爱,还真舍不得送给你**。舍不得送给你大爷!舍不得送给你大爷!
msg = '吕布真可爱,还真舍不得送给你大爷。舍不得送给你大爷!舍不得送给你大爷!'
new_msg = msg.replace('大爷','**',3)
print(new_msg)
结果:吕布真可爱,还真舍不得送给你**。舍不得送给你**!舍不得送给你**!
应用场景:敏感字符替换。
练习题:
# 需求:让用户输入内容,判断用户输入的内容中是否含有敏感字符'你胖了',若含有,则用***替换。
content = input('请输入内容:')
if '你胖了' in content:
content = content.replace('你胖了','***')
print(content)
# 结果:
请输入内容:你胖了好多
***好多
拓展:关于成员运算符in的使用
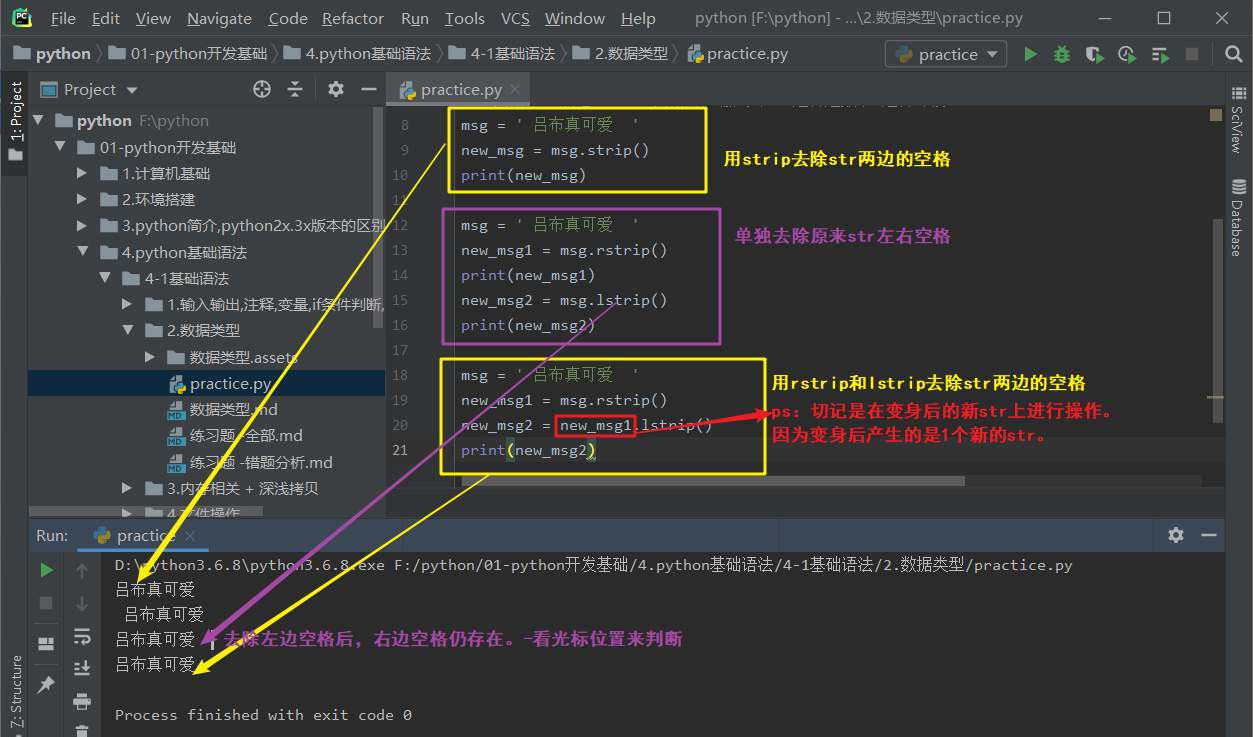
6.去除str头尾两边的空格/换行符(\n)/制表符(\t)/特定字符 返回值:新str
ps-1:字符串的此操作方法不会影响原来的str。而是生成一个新的str。
要打印新str才能看到变身后的结果。
ps-2:变身后的结果仍是str。
ps:the meaning of strip is 去除。
去除str两边的空格/换行符(\n)/制表符(\t)/特定字符
rstrip .rstrip() -去除str右边的空格/换行符(\n)/制表符(\t)/特定字符 返回值:新str
lstrip .lstrip() -去除str左边的空格/换行符(\n)/制表符(\t)/特定字符 返回值:新str
strip .strip() -去除str两边的空格/换行符(\n)/制表符(\t)/特定字符 返回值:新str
去除str两边的某个/某些字符 str.rstrip/lstrip/strip('要去除的字符') 返回值:新str
ps:制表符\t相当于1个tab键(2个空格)
# 制表符:\t
s1 = 'a\tMrLin'
print(s1)
# 结果:a MrLin
# 换行符:\n
s1 = 'a\nMrLin'
print(s1)
# 结果:
a
MrLin
去除str里边的空格/换行符(\n)/制表符(\t)
- str.replace('空格/换行符(\n)/制表符(\t)', '')
示例:
7.连接
写在前面:join是str的独有操作方法。join前面的连接符是以str形式存在的,但join后面可以是任意序列,只要可迭代即可。
ps:序列里的元素必须全部是str,才能用join去拼接!!
what:将某序列的各元素之间用某连接符连起来。
格式: '连接符'.join(序列)
原理:在join内部会循环该序列的每个元素,并在元素和元素之间加入连接符。
ps:返回值:新str !!(不管要连接的序列是str/list/dict/tuple/set/其他,拼接后都是str形式。)
示例:
# '连接符'.join(字符串)
data = '123'
new_data = '+'.join(data)
print(new_data)
结果:'1_2_3'
# '连接符'.join(列表)
练习一:有列表user = ['吕布', '妥妥', '大黄'],用逗号将list中的元素拼接成字符串'吕布,妥妥,大黄'。
users = ['吕布', '妥妥', '大黄']
new_str = ','.join(users)
print(new_str)
# '连接符'.join(元组)
练习二:有元组tuple1 = ('吕布', '妥妥', '大黄'),用逗号将tuple中的元素拼接成字符串'吕布,妥妥,大黄'。
tuple1 = ('吕布', '妥妥', '大黄')
new_str = ','.join(tuple1)
print(new_str)
# '连接符'.join(字典) # 只是拼接的键。
dict1 = {'name': '吕布', 'age': 18}
new_str = '_'.join(dict1)
print(new_str)
# 结果:name_age
练习题:
# 需求:用_将str中的每个字符连接起来。ps:用2种循环 + str方法去实现。
# 法一:for循环
name = '123'
value = name[0]
for i in name[1:]:
value = value + '_' + i # value += '_' + i
print(value)
# 法二:while循环
name = '123'
index = 1
value = name[0]
while index <= 2:
value = value + '_' + name[index]
index += 1
print(value)
# 法三:
name = '123'
new_name = '_'.join(name)
print(new_name)
# 结果:1_2_3
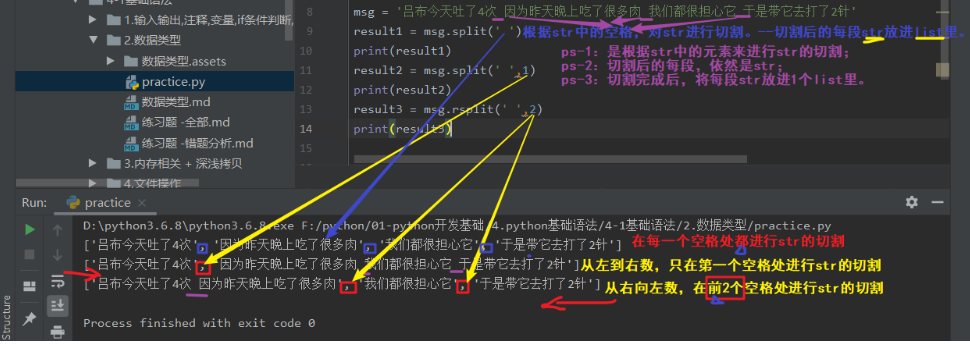
8.分割 .split('字符串中的某字符->分割符')
ps-1:字符串的此操作方法不会影响原来的str。返回值:列表!
ps-2:是按str中已有的元素,进行str的切割。
ps-3:切割后的每小段,依然是str。
ps-4:分割后的结果是将每段str放进list里!!
a.split -从左到右按str中的某元素,对str进行切割。
b.rsplit -从右向左按str中的某元素,对str进行切割。
示例:
拓展:了解。
# str的partition方法:
# 返回值:元组。元组里是3个str。
# 1.str.partition('str中的某字符-->分割符') # 从左边开始分割。
s = '123+456+789'
new_s = s.partition('+')
print(new_s)
# 结果:('123', '+', '456+789') # 将指定字符串分为三份(从左边开始分割):前面,分割符,后面。
# 2.str.rpartition('str中的某字符-->分割符') # 从右边开始分割。
s = '123+456+789'
new_s = s.rpartition('+')
print(new_s)
# 结果:('123+456', '+', '789') # 将指定字符串分为三份(从右边开始分割):前面,分割符,后面。
9.字符串的格式化 -3种
(1).引入
示例:
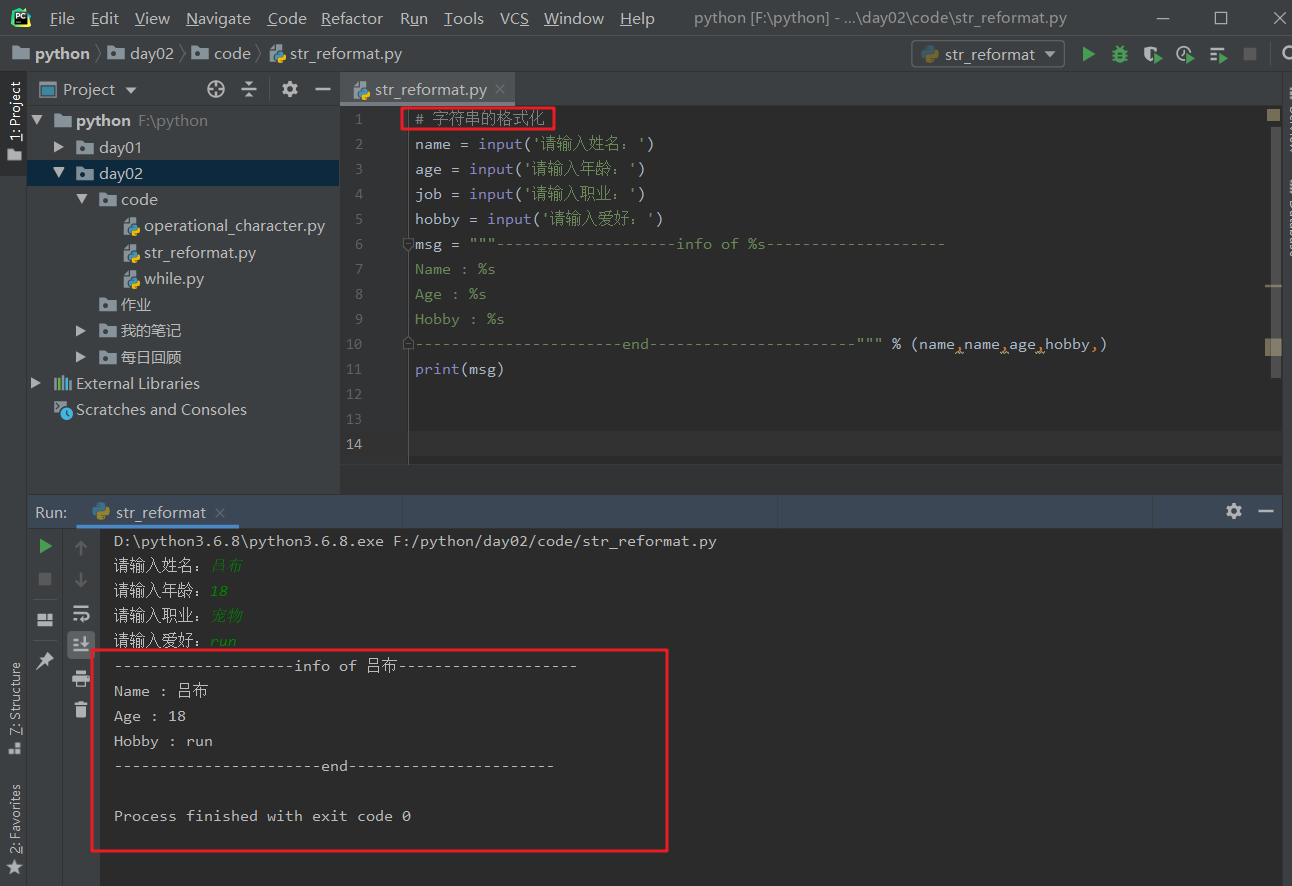
现在有个需要我们录入我们身边好友的信息,格式如下:
------------ info of 吕布 -------------
Name : 吕布
Age : 18
job : 宠物
Hobby: run
----------------- end --------------------
我们现在能想到的办法就是用以下方法: 字符串的拼接。用10个变量拼成如上格式。
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入职业:')
hobby = input('请输入爱好:')
a = '------------ info of 吕布 ----------'
b = 'Name:'
c = 'Age:'
d = 'Job:'
e = 'Hobby:'
f = '------------- end ----------------'
print(a+'\n'+b+name+'\n'+c+age+'\n'+d+job+'\n'+e+hobby+'\n'+f) # \n是换行符。
# 运行结果
------------ info of 吕布 ----------
Name:吕布
Age:18
Job:宠物
Hobby:run
------------- end ----------------
ps: 这样写完全没有问题,但是比较繁琐,不建议这么写。
(2)%占位符 -%s %d %%
写在前面:
ps-1:用%去进行str的格式化, 必须使%前面占位符的数量和位置 与 %后的填充物的数量和位置一一对应。(一个萝卜一个坑.)
ps-2:%后的最后1个填充物后面一定要写上英文的逗号。因为这是个元组,若元组里只有1个元素的话,不加逗号则这就是该元素本身的数据类型,而不是元组。(即,元组记得加逗号。)
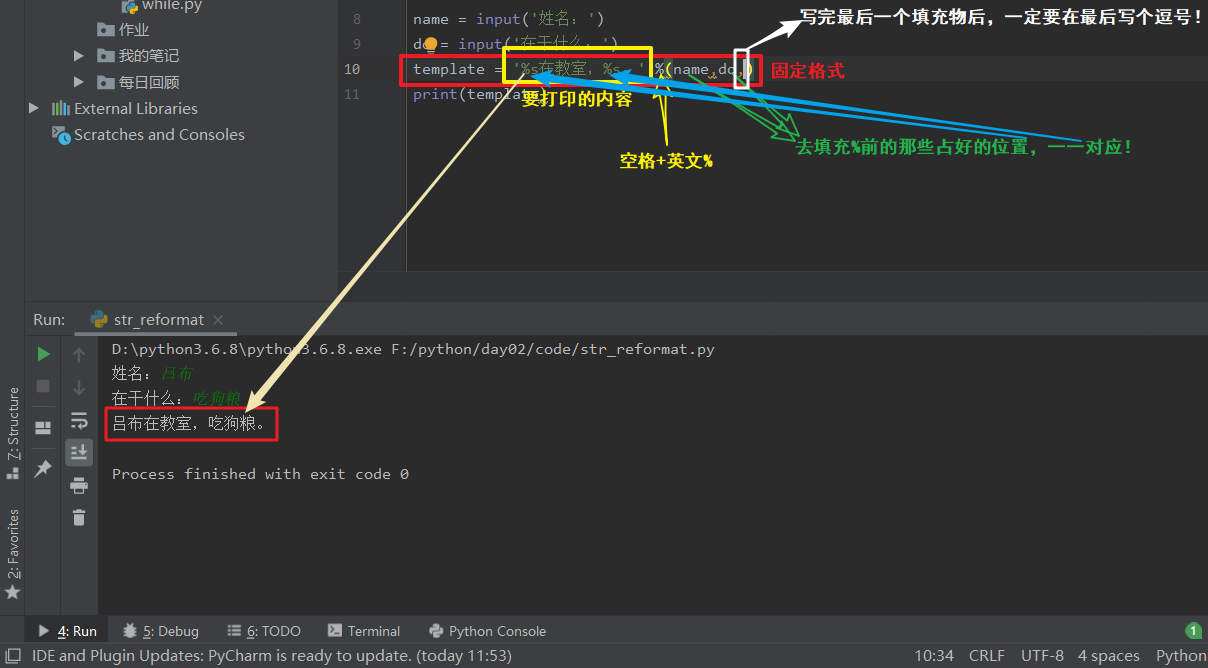
%s - 字符串的占位符
a.字符串格式化存在的意义:将str自动进行拼接。
name = input('姓名:')
do = input('在干什么:')
template = '%s在教室,%s。' %(name,do,) # %s叫str占位符,%后是填充物,最后写上逗号。
print(template)
结果:
姓名:吕布
在干什么:吃狗粮
吕布在教室,吃狗粮。
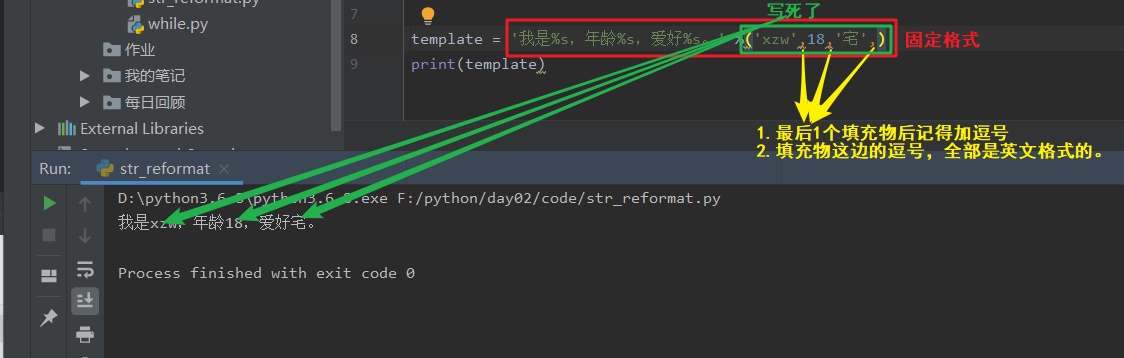
b.%后直接跟具体变量 - 写死。
template = '我是%s,年龄%s,爱好%s。' %('xzw',18,'宅',) #最后有逗号
print(template)
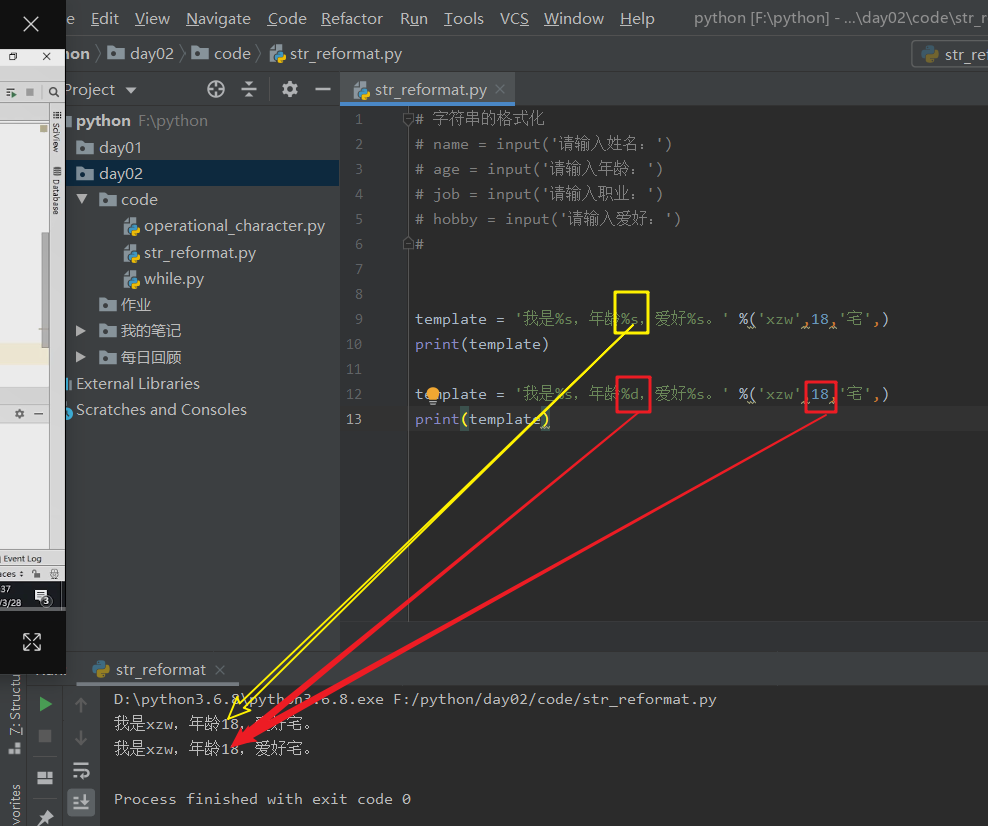
%d或%i - 数字占位符
template = '我是%s,年龄%s,爱好%s。' %('xzw',18,'宅',)
print(template)
template = '我是%s,年龄%d,爱好%s。' %('xzw',18,'宅',)
print(template)
#2者都对。
%% - 在前面的格式里代表单纯的百分号
name = input('请输入姓名:')
template = '%s现在的手机电量是100%%' %(name,)
print(template)
结果:
请输入姓名:xiaohei
xiaohei现在的手机电量是100%
综上,引入示例重写:
个人名片的例子:
# name = input("请输入姓名: ")
# age = input("请输入年龄: ")
# hobby = input("请输入爱好: ")
# template = """--------------------info of %s--------------------
# Name : %s
# Age : %s
# Hobby : %s
# -----------------------end-----------------------""" % (name,name,age,hobby,)
print(template)
结果:
请输入姓名:吕布
请输入年龄:18
请输入职业:宠物
请输入爱好:run
--------------------info of 吕布--------------------
Name : 吕布
Age : 18
Hobby : run
-----------------------end-----------------------
(3).format
写在前面: 用format进行str的格式化 ,也要一一对应 。
ps:最后一个填充物后记得加逗号。因为format后是个元组。
第一种用法:{}相当于%s
msg = '我叫{}今年{}性别{}'.format('大壮',25,'男',) # 要一一对应
print(msg)
# 个人名片的例子:
name = input('请输入姓名:')
age = input('请输入年龄:')
hobby = input('请输入爱好:')
template = '''
------------ info of {} -------------
Name : {}
Age : {}
Hobby: {}
----------------- end --------------------
'''
template = template.format(name,name, age, hobby)
print(template)
第二种用法:按索引格式化
msg = '我叫{0}今年{1}性别{2}我依然叫{0}'.format('大壮', 25,'男') # 要一一对应,但最后一个不用写
print(msg)
# 个人名片的例子:
name = input('请输入姓名:')
age = input('请输入年龄:')
hobby = input('请输入爱好:')
template = '''
------------ info of {0} -------------
Name : {0}
Age : {1}
Hobby: {2}
----------------- end --------------------
'''
template = template.format(name, age, hobby)
print(template)
第三种用法:关键字格式化 #指名道姓去填充
注: .format()的括号里给每对关键字的顺序可以打乱
a = 100
msg = '我叫{name}今年{age}性别{sex}'.format(age=a, sex='男', name='大壮') # 可乱序
print(msg)
# 个人名片的例子:
template = '''
------------ info of {name} -------------
Name : {name}
Age : {age}
Hobby: {hobby}
----------------- end --------------------
'''
template = template.format(name=input('请输入姓名:'), age=input('请输入年龄:'), hobby='eat')
print(template)
(4)f
写在前面-3点注意: 用f 进行str的格式化,{}里只能是变量名;一一对应; python3.6版本以上才能使用。
name = "小黑"
hobbie = "游泳"
dishobby = "落后"
msg = f"我叫{name},我喜欢{hobbie},讨厌{dishobby}"
print(msg)
#错误示例:{}里不能是具体的数据,只能是变量。
msg = f"我叫{"小黑"},我喜欢{"游泳"},讨厌{"落后"}" #会报错
print(msg)
个人名片的例子
name = input("请输入姓名: ")
age = input("请输入年龄: ")
hobbie = input("请输入爱好: ")
msg = f"""--------------------info of name--------------------
Name : {name} #花括号里是变量名
Age : {age}
Hobby : {hobbie}
-----------------------end-----------------------"""
print(msg)
msg = f"""--------------------info of {input("请输入姓名: ")}-------------------
Name : {input("请输入姓名: ")}#大括号里直接是要格式化的内容,此处可如此,是因为input是Python的内置函数
Age : {input("请输入年龄: ")}
Hobby : {input("请输入爱好: ")}
--------------------end-------------------"""
print(msg)
小结:3种格式对比如下:

10.is系列
ps:is系列变身后的结果是bool 。
- 判断str中是否是十进制数字 str.isdecimal() # 返回值:bool
- .isdecimal() -好! # '1'-->True; '二'-->False; '②'-->False
- .isdigit() # '1'-->True; '二'-->False; '②'-->True
- .isnumeric() # '1'-->True; '二'-->True; '②'-->True
注意:
str.isdecimal() 判断的是str是否是十进制数字。其他情况一律为False。 # 推荐使用!
str.isdigit()/str.isnumeric() 不仅仅判断十进制数字,其他形式的也会判定为True。但'②'/'二'并不能转换为int,故此两种方法不好(有漏网之鱼)。
应用场景:欢迎致电10086。
# 致电10086 -判断用户输入的str是否是数字(即判断str是否可渡)
print('''欢迎致电10086
1.话费查询
2.业务办理
3.宽带业务
4.人工服务''')
num = input('请选择要办理的业务:')
# 判断用户输入的str是否是十进制数字 -即判断输入的str是否可渡。
flag = num.isdecimal()
# print(flag) # 返回结果是布尔值。 # '1' -> True;'吕布' -> False
if flag: # if flag:等价于 if flag == True:;因为只有当if的条件是True时,计算机才会执行if里的
num = int(num) # 代码。故此时可如此简写。
print(num)
else: # else: 等价于 if flag == False:
print('请输入数字')
# 完整版:
print('''欢迎致电10086 #换行的字符串,三引号。
1.话费查询;
2.流量查询;
3.业务办理;
4.人工服务。''') # 要先显示内容,才能让用户选择。
index = input('请输入你要选择的服务:')
flag = index.isdecimal()
if flag:
index = int(index)
if index == 1:
print('话费查询')
elif index == 2:
print('流量查询')
elif index == 3:
print("""业务办理:
1.修改密码;
2.更改套餐;
3.宽带业务""")
num = input('请输入要办理的业务:')
if num.isdecimal():
num = int(num)
if num == 1:
print('修改密码')
elif num == 2:
print('更改套餐')
elif num == 3:
print('宽带业务')
else:
print('输入错误,请重新输入')
else:
print('请输入数字')
elif index == 4:
print('人工服务')
else:
print('输入错误,请重新输入') # 逻辑要严谨。
else:
print('请输入数字')
isalnum -判断某个str里是否是字母/数字/字母+数字。
ps:the meaning of alnum is 字母+数字。
isalpha -判断某个str里是否只有字母/汉字/字母+汉字。
ps:**the meaning of alpha is **希腊字母的第一个字母/开端。
11.字符串的编码 -常用。
(1).Python解释器是如何承上启下,将python代码执行起来的:
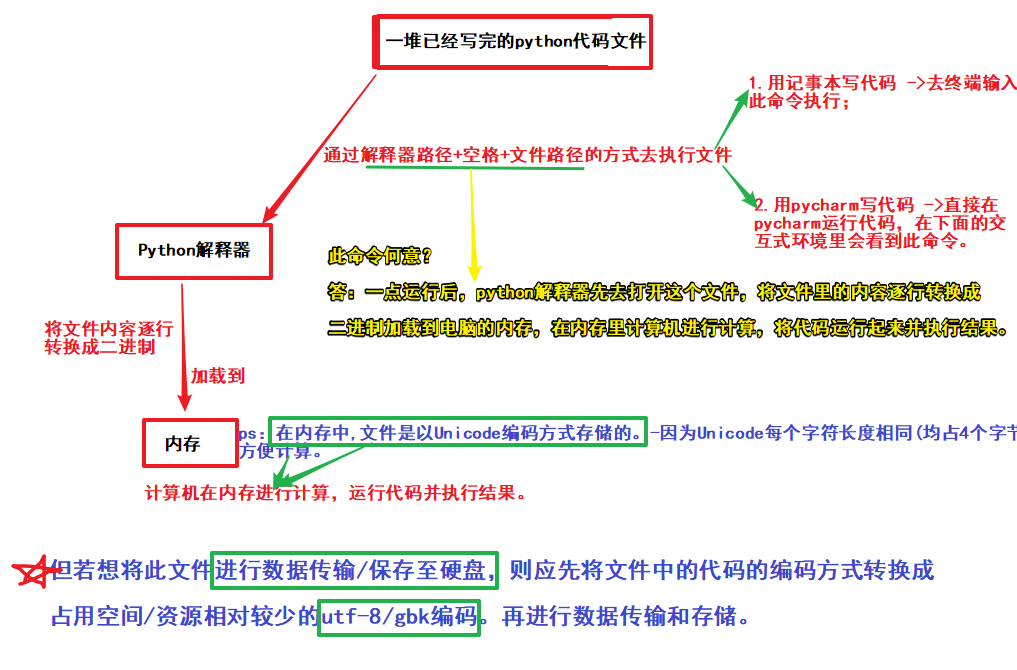
ps:在程序运行阶段,使用的是unicode编码(因为便于计算机进行计算);
在程序进行数据传输和存储时,使用的是utf-8/gbk编码(因为utf-8/gbk在数据传输/存储过程中,占用的空间和资源少)。
在python中可以把文字信息进行编码. 编码之后的内容就可以进行传输or存储了。
(2).如何对文字信息(eg:str)进行编码呢?: 用encode!!
即如何将(内存中)str的Unicode编码 -->(传输/存储中)utf-8/gbk编码,以进行文字信息的传输和存储:

# 当str是中文时,编码之后的结果根据编码方式的不同,编码结果也不同.utf-8:1中文占3字节;gbk:1中文占2字节
# 写在前面:str的二进制是bytes类型的数据。
name = '吕布'
value1 = name.encode('utf-8') # 将str根据UTF-8编码转换成bytes类型(二进制)
print(value1)
val2 = name.encode('gbk') # 将str根据gbk编码转换成bytes类型(二进制)
print(val2)
结果:b'\xe5\x90\x95\xe5\xb8\x83' # 这是用十六进制表示的二进制。
结果:b'\xc2\xc0\xb2\xbc'
# 当str是英文时,编码之后的结果和源字符串一致。
name = 'xiaokeai'
value1 = name.encode('utf-8') # 将str根据UTF-8编码转换成bytes类型(二进制)
print(value1)
val2 = name.encode('gbk') # 将str根据gbk编码转换成bytes类型(二进制)
print(val2)
结果:b'xiaokeai'
结果:b'xiaokeai'
ps-1:编码之后的数据是bytes类型的数据,这是str的二进制表现形式。
其实,还是原来的数据。只是经过编码之后表现形式发生了改变而已。
bytes的表现形式:
- 英文:b’xiaokeai’ 英文的表现形式和字符串没什么两样;
- 中文:b'\xe5\x90\x95 这是一个汉字的UTF-8的bytes表现形式。
- 中文:b'\xc2\xc0 这是一个汉字的gbk的bytes表现形式。
ps-2:encode的作用:对str进行utf-8/gbk编码,将用Unicode编码的字符串转换成utf-8/gbk编码的字符串,以用来进行str的数据传输/将其保存至硬盘。(即encode的作用是用来进行str编码方式的转换的。)
ps-3:何时用encode:在将str保存至硬盘/进行str的数据传输时,会用到encode。因为需要转换str的编码方式。
ps-4:编码格式:str.encode('utf-8/gbk')
ps-5:encode转换编码方式后,数据类型变成了bytes类型。即在str进行数据传输/存储时是以bytes的形式存在的。
(3).如何对bytes类型的数据进行解码:
即如何将bytes的utf-8/gbk编码 -->str的Unicode编码,以进行解码还原:
ps:在网络传输和硬盘存储的时候我们python是保存和存储的bytes 类型。
那么在对方接收的时候,也是接收的bytes类型的数据。我们可以使⽤decode()来进行解码操作,
把bytes类型的数据还原回我们熟悉的字符串:
name = '吕布'
value = name.encode('utf-8') # 将字符串编码成UTF-8
print(value)
# 结果:b'\xe5\x90\x95\xe5\xb8\x83'
value2 = b'\xe5\x90\x95\xe5\xb8\x83'.decode('utf-8') # 将bytes类型解码(还原)成我们认识的str
print(value2)
# 结果:吕布
注意:1.见到认识(str)的就编码,见到不认识(bytes类型)的就解码还原成我们认识的。
2.用哪种编码方式编码的,就再用哪种编码方式解码 。
(4).二次编码 -编码和解码
示例:文字信息的GBK(bytes类型) -->UTF-8(bytes类型),中间需要一个桥梁:Unicode(还原为str)。
见到1个str,先用gbk编码,获得bytes类型数据;再用gbk对bytes解码,还原为原str;再对此str进行utf-8编码。
# 需求:在py3中,将s = "我是文字"转换成gbk的bytes类型;转换成功后再将得到的bytes类型数据转换成utf-8的bytes类型。
s = "我是文字"
# 1th: 我们这样可以获取到GBK的文字
bs = s.encode("GBK")
print(bs) # 结果:b'\xce\xd2\xca\xc7\xce\xc4\xd7\xd6'
# 2th: 把GBK转换成UTF-8
# 首先要把GBK转换成unicode. 也就是需要解码
former = bs.decode("GBK") # 将gbk的bytes类型进行解码还原 -ps:用什么编码的,就再用什么解码。
print(former) # 结果:我是文字
# 然后需要将解码后的str重新编码成UTF-8
bss = s.encode("UTF-8") # 重新编码
print(bss) # 结果:b'\xe6\x88\x91\xe6\x98\xaf\xe6\x96\x87\xe5\xad\x97'
12.练习题:
1.需求:让用户输入任意字符串,获取字符串之后计算其中有多少个数字。
(1).while循环:
content = input('请输入内容:')
index = 0
count = 0
while index <= len(content) - 1:
val = content[index]
if val.isdigit():
count += 1
index += 1
print(count)
(2).for循环:
content = input('请输入内容:')
count = 0
for i in content:
if i.isdigit(): # i.isdigit()的返回值就是True/False,如果是True(即if的条件是True),则满足if的条件,就会执行if里面的内容。
count += 1
print(count)
2.需求:去除字符串的空格。
name = ' 吕 布是暖男and so handsome '
# 一.去除前后的空格
name = name.strip()
print(name)
结果:吕 布是暖男and so handsome
# 二.去除所有的空格
name = name.replace(' ', '')
print(name)
结果:吕布是暖男andsohandsome
(2).不常用方法 -(了解)
1.首字母大写 .capitalize() 返回值:新str
s = 'lvbu'
new_s = s.capitalize()
print(new_s) # Lvbu
2.大小写转换 .swapcase() 返回值:新str
s = 'liBU'
new_s = s.swapcase()
print(new_s)
# 结果:LIbu
3.统计某字符/子序列出现的次数 .count('某字符') 返回值:int
s = 'aaaaa小吕布'
print(s.count('a'))
4.查找某字符的索引位置
- .find('某字符') 若字符不存在,则返回-1。
- .find('某字符') # 从左边开始找,返回左边第一个字符的索引。
- .rfind('某字符') # 从右边开始找,返回右边第一个字符的索引。
- .index('某字符') 若字符不存在,则报错。
- .index('某字符') # 从左边开始找,返回左边第一个字符的索引。
- .rindex('某字符') # 从右边开始找,返回右边第一个字符的索引。
s = 'MrLin666先生 & Miss哈哈哈小姐'
print(s.find('M')) # 0
print(s.rfind('M')) # 13
print(s.find('7')) # -1 print(s.index('M')) # 0
print(s.rindex('M')) # 13
print(s.index('7')) # ValueError:substring not found -找不到字符串。
- .find('某字符') 若字符不存在,则返回-1。
5.居中 .center(总长度, '两边的填充物') # 不写填充物,则默认用空格填充。
- 将str居中 .center(总长度, '两边的填充物')
- 将str居左 .ljust(总长度, '右边的填充物')
- 将str居右 .rjust(总长度, '左边的填充物')
s = '暖男吕布'
print(s.center(10)) # 暖男吕布 # 不写则默认用空格填充。
print(s.center(10, '*')) # ***暖男吕布*** # 居中
print(s.ljust(10, '*')) # 暖男吕布****** # 居左
print(s.rjust(10, '*')) # ******暖男吕布 # 居右
6.将str中每一个单词的首字母变成大写 .title() 标题
s = 'Lvbu is a handsome dog.'
new_s = s.title()
print(new_s) # Lvbu Is A Handsome Dog.
7.判断str是否是空白 .isspace() # 空str,判定为False。返回值:bool。
s1 = ' '
print(s1.isspace()) # True
s2 = ''
print(s2.isspace()) # False
(三).强制转换
写在前面-1:int和bool此2种可直接转。list/tuple/dict/set此4种容器类要想转成str,要通过str的join方法。
写在前面-2:list/tuple/set/dict-->str: 用join时,序列里的元素必须全部都是str类型才可以转。
写在前面-3:当要拼接的序列是dict时,转换的只是dict的key。
- str(999) # '999'
- str(true) # 'True'
- list-->str ,s1 = ''.join(li) # li里的元素必须是str。
- tuple-->str,s2 = ''.join(tu1) # tuple里的元素必须是str。
- dict-->str, s3 = ''.join(dict1) # 转换的只是dict的key。
- set-->str,s4 = ''.join(set1) # set里的元素必须是str。
# 示例:
# 示例一:list--》str
li = ['1', '2', '3']
v2 = ''.join(li)
print(v2)
# 示例二:tuple--》str
tu1 = ('1', '2', '3', '4', )
s2 = ''.join(tu1)
print(s2)
# 示例三:dict--》str
dict1 = {"name": '吕布', 'age': 18}
s3 = ''.join(dict1) # 拼接起来的知识dict的键。
print(s3)
# 示例四:set--》str
set1 = {'1', '2', '3'}
s4 = ''.join(set1) # set无序。
print(s4)
# 结果:
123
1234
nameage
213
四.列表list -可变。有序。
4.0定义
def:用[ ]括起来, 每个元素之间用","隔开,可以存放各种数据类型。可以储存大量数据。有序。有索引切片步长,方便取值。(在其他 语言里叫数组eg:在JS、Java中都称之为数组。)
eg:li = [['MrLin',520,True,7],0,'吕布',True,(1,'妥妥',666),{'age':18,'job':'teacher'}]
ps-1:相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据。
32位python的限制是 536870912 个元素,
64位python的限制是 1152921504606846975 个元素。
ps-2: 列表是有序的。有索引值,可切片,方便取值。
ps-3: 若list中盛放大量数据,则查询速度慢。不如dict/tuple的hash算法查值快。
(一).公共功能 -共9个。list全都具备。
4.1列表相加
- 相加后是形成一个新列表,列表里放的是这2个小列表的所有元素;
- 新列表依然有序。
list1 = [1,2,666,'吕布']
list2 = ['handsome','暖男',666]
new_li = list1 + list2
print(new_li)
# 结果:[1, 2, 666, '吕布', 'handsome', '暖男', 666]
4.2列表*int
- 形成一个新列表。新列表里是int个被乘列表里的元素。
- 依然有序。
li = ['吕布','handsome','暖男',666]
new_li = li * 2
print(new_li)
# 结果:['吕布', 'handsome', '暖男', 666, '吕布', 'handsome', '暖男', 666]
(1).查 -4种公共方法。索引、切片、步长、for循环。
4.3列表的索引
同str
4.4列表的切片
同str
4.5列表的步长
同str
4.6for循环
写在前面-1:for循环内部自加,不需要我们再去自加让其转起来。
写在前面-2:for循环的对象必须可迭代。eg:字符串/列表/字典/元组/集合这5种可迭代的类型and其他可迭代的序列(eg:range())。)
写在前面-3:for循环可嵌套。
写在前面-4:break和continue在for循环中依然适用。
格式:
for 变量 in 序列:
循环体内容
示例:
# 需求:遍历字符串中的每一个元素。
value = ['吕布666',True,7]
for item in value:
print(item)
结果:
吕布666
True
7
ps:
# ps-1:与for平齐的行,只打印for循环的序列中的最后一个元素。
value = ['吕布666',True,7]
for item in value:
print(item)
print(item) # 只打印最后一个元素。
# 结果:7
# ps-2:break和continue在for循环中依然适用。
value = ['吕布666',True,7]
for item in value:
print(item)
break
# 结果:'吕布666'
value = ['吕布666',True,7]
for i in value:
print(i)
break
print('啊哈') # 不打印。
# 结果:'吕布666'
value = ['吕布666',True,7]
for i in value:
print(i)
continue
print('啊哈') #不打印。
# 结果:
吕布666
True
7
for和while的应用场景:
有穷尽优先使用for,无穷尽用while。
练习题:
1.遍历list中的各元素
content = ['MrLin_儒雅先生','纳兰容若']
for item in content:
print(item)
2.遍历list各元素的索引
content = ['MrLin_儒雅先生','纳兰容若',666,True,'Faye']
max_index = len(content) -1
for item in range(0,max_index + 1):
print(item)
3.for循环的嵌套
- 练习题:
1.看代码写结果:
users = ['吕布','小花','流浪歌手','天赋']
for item in users:
for ele in item:
print(ele)
2.看代码写结果:
users = ['吕布','小花','流浪歌手','天赋']
for item in users:
print(item)
for ele in item:
print(ele)
4.7len
ps:对于list,返回值是:list中的元素个数;
li = ['吕布','handsome','暖男',666]
print(len(li))
# 结果:4
(2).删 -1种公共方法。(3种独有方法)
4.8删除list中的某元素。del li[索引/切片/步长]。
写在前面-1:只适用于可变数据类型中的 list/dict。(set无序,没办法索引,del set是删除整个集合)
写在前面-2:仅仅是删除,没有返回值。
写在前面-3:按切片/步长删,依然保持切片/步长原有的特性。
格式: 3种。
- del li[索引] 按索引删 # 类似于.pop(索引)。但pop可以有返回值,它没有。
- del li[起:终] 按切片删
- del li[起:终:步长] 按步长,跳着删
示例:
# 示例1:按索引删
li = [1, '二哈', 2, 666, '狗子']
del li[1]
print(li)
# 结果:[1, 2, 666, '狗子']
# 示例2:按切片删 -尾是开区间。
li = [1, '二哈', 2, 666, '狗子']
del li[:3]
print(li)
# 结果:[666, '狗子']
# 示例3:按步长,跳着删。-尾是开区间,步长是几就数几个间隔。
li = [1, '二哈', 2, 666, '狗子']
del li[::3]
print(li)
# 结果:['二哈', 2, '狗子']
ps:此种删除序列里元素的方法,对于str、int、bool、tuple不适用。
因为:str、int、bool、tuple是不可变数据类型。变量一旦生成,它的值就在内存里写死了。不能再对这个值进行修改/删除。要想改值,只能将一个新的值再一次赋值给这个变量。但它原来的值依然在内存里存放着。
示例:
s = '123'
del s[0]
print(s)
# 结果:TypeError: 'str' object doesn't support item deletion.str不支持这种删除方式。
# 要想改值/删除,只能对这个变量进行二次赋值。但它原来的那个值依然在内存里放着呢。
s = '123'
s = '23'
print(s)
# 结果:23
(3).改 -仅此1种公共方法。
4.9修改list中的某元素 li[索引] = '新元素'。只适用于可变数据类型中的list/dict。(set无序,没办法通过索引取值)。
写在前面-1:只适用于可变数据类型中的:list/dict。
写在前面-2:a.最外层元素:此可变数据类型(大框)中的本层所有元素都能修改(因为本层元素均是可变数据类型list中的元素,均可做修改)。但仅限于修改本层。若要修改深层的元素,则要先判断其实可变还是不可变数据类型。
b.对于深层元素:int/bool/str/tuple 此4种不可变数据类型。不能修改。因为其不可变,值已经写死在内存了。
list/dict/set 此4种可变数据类型。可以修改。因为其可变,故哪怕嵌套的再深,其中元素也能修改。
格式:
li[索引] = '新元素' # 通过索引先取到值,再进行修改。
示例:
# 最外层元素:此可变数据类型(大框)中的所有元素都能修改。
li = [1, '二哈', [1, 2, '123'], 2, 666, '狗子']
li[0] = '吕布'
print(li)
# 结果:['吕布', '二哈', [1, 2, '123'], 2, 666, '狗子']
li = [1, '二哈', [1, 2, '123'], 2, 666, '狗子']
li[2] = [666, 10]
print(li)
# 结果:[1, '二哈', [666, 10], 2, 666, '狗子']
# 深层元素:不可变类型不能修改。可变类型可以修改。
a.int/bool/str 此3种不可变数据类型。不能修改。
# 第2层元素:
li = [1, '二哈', [1, 2, '123'], 2, 666, '狗子']
li[1][0] = '小' # 想把'二哈'中的'二'改成'小'。
print(li)
# 结果:TypeError: 'str' object does not support item assignment.
# 第3层元素:
li = [1, '二哈', [1, 2, '123'], 2, 666, '狗子']
li[2][-1][0] = 9 # 想把[1, 2, '123']中的'123'的1改成9。
print(li)
# 结果:TypeError: 'str' object does not support item assignment.
b.list/dict/set/tuple 此4种可变数据类型。可以修改。
# 第2层元素:
li = [1, '二哈', [1, 2, '123'], 2, 666, '狗子']
li[2][0] = '比熊'
print(li)
# 结果:[1, '二哈', ['比熊', 2, '123'], 2, 666, '狗子']
# 第3层元素:
li = [1, '二哈', [1, 2, '123', ['射雕英雄传', '雪山飞狐', '碧血剑'], 8], '狗子']
li[2][-2][0] = '海贼王'
print(li)
# 结果:[1, '二哈', [1, 2, '123', ['海贼王', '雪山飞狐', '碧血剑'], 8], '狗子']
...
# 第n层元素 同理。
4.10练习题
练习1.实现一个整数加法计算器(两个个位数相加)。
如:content = input('请输入内容:'),用户输入:5+9或5+ 9或5 + 9(含空白),然后进行分割转换最终进行整数的计算得到结果。
解:
(一).两个数相加
方法一:个位数的整数加法计算器。局限性:只能计算个位相加。 eg :5+ 9或5 + 9。
思路:根据str的索引取值。
content = input('请输入内容:')
content = content.replace(' ','')
v1 = int(content[0])
v2 = int(content[-1])
v3 = v1 + v2
print(v3)
方法二:个位数的整数加法计算器。局限性:只能计算个位相加。eg :5+ 9或5 + 9。
思路:利用while循环。
content = input('请输入内容:')
content = content.replace(' ','')
total = 0
index = 0
while index <= len(content) - 1:
char = content[index] # char n.字符
flag = char.isdigit()
if flag:
char = int(char)
total = total + char
index += 1
print(total)
拓展:固定格式-两位数的整数加法计算器。 eg: 12+12,02+15,02+03。
思路:利用while循环 + str的相加。
content = input('请输入内容:')
content = content.replace(' ', '')
total = 0
index = 0
while True:
max_index = len(content) -1
char1 = content[index] # char n.字符
if index == max_index: # 到str的最后一个字符就得停了,因为再往后str[index +1]就取不到了。
break # 在最后一个能取到的下一个停,只要能取到必须取完。
char2 = content[index + 1]
flag1 = char1.isdigit()
flag2 = char2.isdigit()
if flag1 and flag2:
sequence = char1 + char2 # sequence n.序列
sequence = int(sequence)
total = total + sequence
index += 1
print(total)
拓展:固定格式-三位数的整数加法计算器。 eg :100+666,001+100,023+003。
思路:利用while循环 + str的相加。
content = input('请输入内容:')
content = content.replace(' ', '')
total = 0
index = 0
while True:
max_index = len(content) - 1
char1 = content[index] # char n.字符
if index == max_index - 1: # 到str的最后一个字符就得停了,因为再往后str[index +1]就
break # 取不到了。在最后一个能取到的下一个停,只要能取到必须取完。
char2 = content[index + 1]
char3 = content[index + 2]
flag1 = char1.isdigit()
flag2 = char2.isdigit()
flag3 = char3.isdigit()
if flag1 and flag2 and flag3:
sequence = char1 + char2 + char3 # sequence n.序列
sequence = int(sequence)
total = total + sequence
index += 1
print(total)
方法三:不限制被加数的位数(个十百千万均可),不要求固定格式。但仅限于2个数相加。
思路:将str用+号分割开,分割后自动生成一个list。通过list索引取值,强制转换后再做加法运算。
eg :1+23,100 +2 3,1 000 +9 9999。
content = input('请输入内容:')
content = content.replace(" ",'')
new_li = content.split("+")
print(new_li)
v1 = int(new_li[0])
v2 = int(new_li[-1])
total = v1 + v2
print(total)
(二).可累加
方法:不限制被加数的位数,不要求固定格式。可累加。均不限!
思路:while循环 + str的分割。
eg: 1+23 +10 01 + 200 +520 +66 66。and so on.
content = input('请输入内容:')
content = content.replace(' ', '')
new_li = content.split('+')
print(new_li)
index = 0
total = 0
while True:
max_index = len(new_li) - 1
if index == max_index + 1: # 等到list里的最后一个元素加完后,再停。否则最后一个元素加不上。
break # 即在累加的最后一位的后一位停。
value = int(new_li[index])
total = total + value
index += 1
print(total)
练习2.通过for循环和数字计数器实现:users = ['吕布','小花','流浪歌手','天赋'],打印出来的效果如下:
效果如下:
"""
0 吕布
1 小花
2 流浪歌手
3 天赋
"""
- 方法一:单独for
users = ['吕布', '小花', '流浪歌手', '天赋']
index = 0
for item in users:
print(index, item)
index += 1
- 方法二:for循环 + range。
users = ['吕布', '小花', '流浪歌手', '天赋']
for item in range(0, len(users)):
print(item, users[item])
4.11 in
# 示例:
li = [1, 2, 88, 100]
if 1 in li:
print('包含该元素')
# 练习题:让用户输入任意字符串,然后判断此字符串是否包含指定的敏感字符。
# 敏感字符:char_list = ['矮','胖','丑']
content = input('请输入内容:')
char_list = ['矮', '胖', '丑']
success = True
for item in char_list:
if item in content:
success = False
break
if success:
print(content)
else:
print('包含敏感字符')
(二).list的方法
写在前面:list和str不一样。list是可变数据类型.。故,对其进行操作,会直接在原来的对象上进行修改。
(4).增 -3种方法。append、insert、extend.
4.9列表的增
- 增 -3种方法
1.追加 .append('要追加的元素') 直接在原list上进行操作。
格式:
li = [1,2,666]
li.append('狗子')
print(li)
结果:[1, 2, 666, '狗子'] # 结果是将元素追加到原列表的最后面。
示例:
# 需求:录入用户信息,并添加到列表中。
# 方法一:录入的用户名个数未知。留口子。
users = []
while True:
name = input('请输入用户名和密码,输入Q退出:')
if name.upper() == 'q'.upper():
break
users.append(name)
print(users)
结果:
请输入用户名和密码,输入Q退出:小吕布,123
请输入用户名和密码,输入Q退出:貂蝉呀,456
请输入用户名和密码,输入Q退出:狗子,666
请输入用户名和密码,输入Q退出:q
['小吕布,123', '貂蝉呀,456', '狗子,666']
# 方法二:若需录入的用户名个数已确定。共录入3个用户名和密码。
users = []
for item in range(0, 3):
name = input('请输入用户名和密码:')
users.append(name)
print(users)
结果:['小吕布,123', '貂蝉呀,456', '狗子,666']
练习题:
# 需求:录入3个用户信息,并添加到列表中。然后判断用户登录信息是否正确(即用户名和密码校验)。
# 1th:录入用户和密码,并添加到列表中。
users = []
for item in range(0, 3):
name = input('请输入用户名和密码:')
users.append(name)
print(users)
# 2th:用户和密码校验
username = input('请输入要登录的用户名:')
password = input('请输入要登录的密码:')
for item in users:
result = item.split(',') # 录入信息时输入的是哪种逗号,这里就用哪种逗号分割。
user = result[0]
pwd = result[-1]
if user == username and pwd == password:
print('登录成功')
break
else:
print('用户名或密码错误')
2.插入 .insert(索引,'要插入的元素')。在指定索引位置处插入元素。
格式:
li.insert(索引,'要插入的元素') # 将某元素插入到该索引位置,原来的元素向后移动一位。
ps:插入某元素后,原来的元素往后挪了一位!!插在原有元素前面。
示例:
li = [1, 2, 666, '狗子']
li.insert(1,'二哈') # 将'二哈'插入到索引1的位置处,之前的元素后挪一位。
print(li)
结果:[1, '二哈', 2, 666, '狗子']
3.迭代着添加 .extend(可迭代的数据类型)。
格式:
li.extend(可迭代的数据类型)
# ps:必须是可迭代的,才可用extend迭代着添加。
示例:
li = [1, '二哈', 2, 666, '狗子']
li.extend('123456')
print(li)
结果:[1, '二哈', 2, 666, '狗子', '1', '2', '3', '4', '5', '6']
li = [1, '二哈', 2, 666, '狗子']
li.extend([5, 2, 0, 'Lin'])
print(li)
结果:[1, '二哈', 2, 666, '狗子', 5, 2, 0, 'Lin']
练习题:
# 请将列表l2 = [1, 2, 3, 4]的每一个元素追加到列表li中,并输出添加后的列表。
li = ['a', 'b', 'c', 'd', 'e']
l2 = [1, 2, 3, 4]
# 方法一:list的独有方法 -extend
li.extend(l2)
print(li)
# 方法二:循环实现
# a.for循环
for i in l2:
li.append(i)
print(li)
# b.while循环
index = 0
while index <= len(l2) - 1:
li.append(l2[index])
index += 1
print(li)
# 结果:['a', 'b', 'c', 'd', 'e', 1, 2, 3, 4]
(5).删 -3种方法。pop、remove、clear.
4.10列表的删
- 删 -3种方法(都不常用!)
1.pop通过索引删除元素。不写索引,则默认删除最后一个。可以设置返回值。
格式:
li.pop(要删除元素的索引)
示例:
li = [1, '二哈', 2, 666, '狗子']
li.pop(1) # 删'二哈','二哈'的索引是1。
print(li)
# 结果:[1, 2, 666, '狗子']
ps-1:若pop(),不写索引。则默认删除最后一个元素。
li = [1, '二哈', 2, 666, '狗子']
li.pop()
print(li)
# 结果:[1, '二哈', 2, 666]
ps-2:可以设置返回值。以查看删除的元素。
li = ['a', 'b', 'c', 'd', 'e']
# del li[0] # 仅仅是删除
# print(li)
deleted = li.pop(0) # 通过索引删除list中的元素,并将删除的数据赋值给deleted。以供查看。
print(li)
print(deleted)
# 结果:
['b', 'c', 'd', 'e']
a
2.remove 通过元素删除。若值不存在,则报错。
格式:
li.remove('要删除的元素')
示例:
li = [1, '二哈', 2, 666, '狗子']
li.remove('二哈')
print(li)
# 结果:[1, 2, 666, '狗子']
ps:若被删除的值不存在,则会报错。
li = ['a', 'b', 'c', 'd', 'e']
li.remove('100')
print(li)
# 结果:ValueError: list.remove(x): x not in list
3.clear 清空
格式:
li.clear() # 清空列表。
示例:
li = [1, '二哈', 2, 666, '狗子']
li.clear()
print(li)
# 结果:[]
4.11列表的其他方法
- 反转 li.reverse()
value1 = [11, 22, 33, 100]
value1.reverse()
print(value1)
# 结果:[100, 33, 22, 11]
- 排序 li.sort(reverse=False/True) 默认从小到大排。
li = [1, 6, 45, 99, 10, 7, 100]
li.sort(reverse=False) # False 从小到大
print(li)
# 结果:[1, 6, 7, 10, 45, 99, 100]
li.sort(reverse=True) # True 从大到小
print(li)
# 结果:[100, 99, 45, 10, 7, 6, 1]
li.sort() # 默认从小到大
print(li)
# 结果:[1, 6, 7, 10, 45, 99, 100]
- 统计 li.count(某元素)
li = [1,2,3,4,84,5,2,8,2,11,88,2]
num = li.count(3) # 统计元素3出现的次数,和字符串中功能一样
print(num)
- 通过元素 获取下标/索引 li.index(某元素)
li = [1,2,3,4,84,5,2,8,2,11,88,2]
n = li.index(5)
print(n)
(三).list的嵌套
写在前面-1:采用降维操作,一层一层的找。
写在前面-2:用在何处? -当需要存储大量的数据,且需要这些数据有序的时候。制定一些特殊的数据群体:按顺序,按规则,自定制设计数据。
取值 -根据索引一层一层取值。0
示例:
li = [666, '吕布', 'MrLin', ['火影', ['柯南', '红猪'], '海贼王'], True]
# 找到MrLin
print(li[2])
# 找到吕布和MrLin
print(li[1:3])
# 找到吕布的布字
print(li[1][-1])
改值 -先找到要修改的元素,根据li[索引] [索引]...[索引] = 新值的格式去做改值操作。
示例:
# 将MrLin拿到,然后全部变大写,再扔回去
new_s = li[2].upper()
li[2] = new_s
print(li)
# 简写
li[2] = li[2].upper()
print(li)
# 把柯南换成风之谷
li[-2][1][0] = '风之谷'
print(li)
# 在红猪后边添加一个起风了
li[-2][1].append('起风了')
print(li)
练习题:
# 8.写代码,有如下列表,按照要求实现每一个功能。
lis = [2, 33, "k", ["qwe", 20, ["k1", ["tt", 3, "1"]], 89], "ab", "adv"]
# 01.将列表lis中的"tt"变成大写(用两种方式)。
# 方法一:直接修改
lis[-3][-2][-1][0] = lis[-3][-2][-1][0].upper()
print(lis)
# 方法二:先删再改
del lis[-3][-2][-1][0]
lis[-3][-2][-1].insert(0, 'TT')
print(lis)
# 02.将列表中的数字3变成字符串"100"(用两种方式)。
# 方法一:直接修改
lis[-3][-2][-1][1] = '100'
print(lis)
# 方法二:先删再改
del lis[-3][-2][-1][1]
lis[-3][-2][-1].insert(1, '100')
print(lis)
# 03.将列表中的字符串"1"变成数字101(用两种方式)。
# 方法一:直接修改
lis[-3][-2][-1][-1] = 101
print(lis)
# 方法二:先删再改
del lis[-3][-2][-1][-1]
lis[-3][-2][-1].append(101)
print(lis)
# 结果:[2, 33, 'k', ['qwe', 20, ['k1', ['tt', 3, 101]], 89], 'ab', 'adv']
# 典型错误:
del lis[-3][-2][-1][-1]
lis[-3][-2][-1].insert(-1, 101) # insert是插入到该索引位置。原有元素后挪!!
print(lis)
# 结果:[2, 33, 'k', ['qwe', 20, ['k1', ['tt', 101, 3]], 89], 'ab', 'adv']
(四).list的强制转换 -直接转。
写在前面-1:只能将容器类的数据类型转换为list。
写在前面-2:str-->list,是将str的每个字符作为list的元素。
示例:
# 示例一:str--》list # 将str的每个字符作为list的每个元素。
s = '吕布睡着了'
l = list(s)
print(l)
# 结果:['吕', '布', '睡', '着', '了']
# 示例二:tuple--》list
tu1 = (1, 2, 3, )
l1 = list(tu1)
print(l1)
# 结果:[1, 2, 3]
# 示例三:dict--》list # 只是将dict的key转换为list。
dict1 = {'name': '吕布', 'age': 18}
l2 = list(dict1)
print(l2)
# 结果:['name', 'age']
# 示例四:set--》list
set1 = {1, 2, 3}
l3 = list(set1)
print(l3)
# 结果:[1, 2, 3]
(五).list的坑 -2个。
- 1.循环添加 ->死循环。
# 坑1 -循环列表并在循环过程中往列表中添加元素,会形成死循环。
li = [1, 2, 3, 4]
for i in li:
li.append(7) # 这样写法就会一直持续添加7。
# print(li) # 死循环。
print(li) # 什么都不打印(因为是死循环,无尽头)
- 2.列表循环删除 ->每删除1个元素,其他元素索引集体前挪1,故导致结果出错。 ***
写在前面:循环一个列表的时,最好不要改变列表的大小(长度),这样会影响你的最终的结果。
# 坑2 -循环列表并在循环过程中删除列表中的元素,会导致结果错误。
# 示例1:删除列表li中的偶数。
# 法一:从前向后循环list,按元素删remove-失败。
li = [2, 4, 5, 6, 7]
for i in li: # 按元素循环,有元素则循环,没有元素则结束循环。
if i % 2 == 0:
li.remove(i) # 按元素删。
print(li)
结果:
[4, 5, 7]
原因剖析: 造成此种结果的原因有2个。
1.for循环的内部机制。-for只按指针进行循环。
2.列表本身的特性。-每删除1个元素,其他元素索引会集体前挪1。
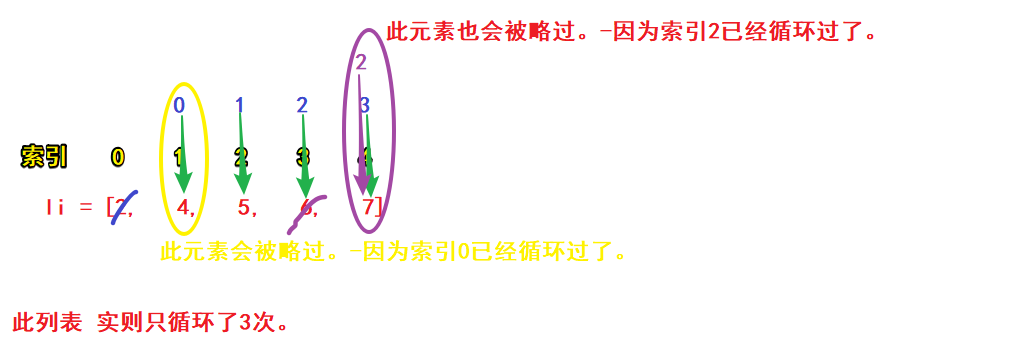
详细:for的运行过程,会有一个指针来记录当前循环的元素是哪一个。
一开始这个指针指向第0 个,然后获取到第0个元素,紧接着删除第0个。 这个时候. 原来是第一个的元素会自动的变成第0个。然后指针向后移动一次, 指向1元素。这时原来的1已经变成了0, 也就不会被删除了。
即:若对list进行for循环删除元素,则每删一个元素,此元素后面的所有元素索引会集体前挪1.则挪完后的第一个元素,由于索引已被遍历过,故不会再循环它(-即漏网之鱼被略过)。如此,便会造成结果错误。
# 法二:从前向后循环list,按索引删del -失败。
li = [2, 4, 5, 6, 7]
for i in range(0, len(li)): # 总共循环5次。# 索引:0,1,2,3,4。
if li[i] % 2 == 0:
del li[i] # 按索引删(公共del)
print(li)
# 结果:IndexError:list index out of range
# 译:索引错误:列表索引超出范围。
# 原因分析:range(0, len(li))代表要循环5次。但是依照上图(list特性)来看,每删除1个元素,后面元素的索引就会前挪1次。循环第一次(找索引0)后,2是偶数,删除.则最大索引由4->3;循环第二次(找索引1)后,5不是偶数,继续循环;循环第三次(找索引2)后,6是偶数,删除.则最大索引由3->2;最大索引2->1;循环第四次(找索引3),此时最大索引是2,找不到索引3,故会报错。
# 法三:从前向后循环list,按索引删pop -失败。
li = [2, 4, 5, 6, 7]
for i in range(0, len(li)): # 循环5次。# 索引:0,1,2,3,4。
if li[i] % 2 == 0:
li.pop(i) # 正向循环删 -pop也不行。
print(li)
# 结果:IndexError:list index out of range
# 译:索引错误:列表索引超出范围。
# 原因同上。
出坑:2种方法。
# 法一:将要删除的元素添加到另一个序列中,然后根据此序列中的元素名称删除原列表中的元素。
li = [2, 4, 5, 6, 7]
del_li = []
for i in li:
if i % 2 == 0:
l2.append(i)
for j in del_li:
li.remove(j) # 根据del_li列表里的元素名,删除li中的数据。
print(li)
# 结果:[5, 7]
# 法二:倒着删。-倒序循环list + 用pop/del按索引删。
li = [2, 4, 5, 6, 7]
for i in range(len(li)-1, -1, -1):
if li[i] % 2 == 0:
del li[i]
print(li)
或:
li = [2, 4, 5, 6, 7]
for i in range(len(li)-1, -1, -1):
if li[i] % 2 == 0:
li.pop(i)
print(li)
# 结果:[5, 7]
示例2:删除列表中的所有元素。
# 错误实例1:正序-remove
li = [11, 22, 33, 44]
for i in li: # 按元素循环,有元素则循环,没有元素则结束循环。
li.remove(i)
print(li)
结果:
[22, 44]
# 原因分析:同实例一。
# 错误实例2:正序-del
li = [11, 22, 33, 44]
for i in range(0, len(li)): # 总共循环4次。# 索引:0,1,2,3。
del li[i]
print(li)
# 结果:IndexError: list assignment index out of range
# 译:索引错误:列表分配索引超出范围。
# 原因分析:range(0, len(li))代表要循环4次。但是依照上图(list特性)来看,每删除1个元素,后面元素的索引就会前挪了1次。删第一个元素(按0删)后,最大索引3->2;删第二个元素(按1删)后,最大索引2->1;删第三个元素时,找不到索引2了,故会报错。
# 错误实例3:正序-pop
li = [11, 22, 33, 44]
for e in li: # 循环的是元素。# 列表里有元素就循环,没元素则结束循环。
li.pop() # pop不写索引,默认删除最后一个元素。
print(li)
结果:
[11, 22]
# 原因分析:循环第一个元素时,删44;循环第二个元素时,删33;循环第三个元素时,没有元素可删,故结束循环。
出坑:3种方法。
# 法一(通用):将要删除的元素添加到另一个序列中,然后根据此序列中的元素名称删除原列表中的元素。
li = [11, 22, 33, 44]
del_li = []
for e in li:
del_li.append(e)
for i in del_li:
li.remove(i)
print(li)
# 结果:[]
# 法二:倒着删。-倒序循环list + 用pop/del按索引删。
li = [11, 22, 33, 44]
for i in range(len(li)-1, -1, -1): # 总共循环len(li)次, 然后从后往前删除
li.pop(i)
print(li)
# 结果:[]
# 法三(此题独有):倒着删。-正序循环list + 用pop()删。
li = [11, 22, 33, 44]
for i in range(0, len(li)): # 总共循环len(li)次, 然后从后往前删除
li.pop()
print(li)
# 结果:[]
五.元组(tuple) -不可变。有序。
5.0定义
# 元祖:俗称不可变的列表,又被称为只读列表,元祖也是python的基本数据类型之一,用小括号括起来,里面可以放任何数据类型的数据。
# 可索引,切片,步长,for循环,len,但只可查询不能修改和删除。
- 格式:
tu = (1,True,'吕布',[1,'MrLin',(1,888,5)],'hfp')
- 什么时候用tuple?
# 将一些非常重要的不可让人改动的数据放在元祖中,只供查看。
- ps-1:书写规范 - 见到元组,不管有几个元素,一定记得最后加逗号。
- ps-2:空元组是(),不用加逗号!!
tu = (1, )
tu2 = (1 )
tu3 = ()
print(type(tu))
print(type(tu2))
print(type(tu3))
# 结果:
<class 'tuple'>
<class 'int'>
<class 'tuple'>
# 面试题:判断以下数据是什么类型。
value1 = 1 # int
value2 = (1) # int
value3 = (1,) # tuple
print(type(value2))
# 另,data = [(1),(2),(3)] 等价于 data = [1,2,3]。
ps-3:关于不可变。***
注意: 这里元组的不可变的意思是子元素不可变。而子元素内部的子元素可以变, 这取决于子元素是否是可变对象。
# 示例一:元组中的最外层元素不可被修改/删除。
tu1 = (1, '吕布', 'MrLin' )
tu1[1] = '貂蝉' # 错误
tu1 = '貂蝉' # 正确
# 示例二:可以嵌套
tu = (1, 2, 22, (666, 7), (0, '吕布来了', (88, 99 ,'eat apple'), 1), 10)
# 示例三:元组中的最外层元素不可被修改/删除。但深层元素可以修改。取决于该元素是否是可变对象。
tu = (11, [1, 2, 3], 22, 33)
tu[1] = 666 # 错误
tu[1][0] = 666 # 正确
print(tu)
# 结果:(11, [666, 2, 3], 22, 33) # list可变,故对其进行修改,会直接改变它本身。
# 示例四:
tu = [11, 22, 33, (1, 2, 3), 44]
tu[-2][0] = 9 # 错误
tu[-2] = 9 # 正确
print(tu)
# 结果:[11, 22, 33, 9, 44] # list可变,故对其进行修改,会直接改变它本身。
(一).公共功能 -共8个。tuple不能删和改。
5.1元组相加
- 相加后是形成一个新元组,列表里放的是这2个小元组的所有元素;
- 新元组依然有序。
tu = (1, 2, 3)
tu2 = (666, )
result = tu + tu2
print(result)
# 结果:(1, 2, 3, 666)
5.2元组*int
- 形成一个新元组。新元组里是int个被乘元组里的元素。
- 依然有序。
tu2 = (666, )
result = tu2 * 3
print(result)
# 结果:(666, 666, 666)
(1).查 -4种公共方法。索引、切片、步长、for循环。
5.3索引
同str
5.4切片
同str
5.5步长
同str
5.6for循环 -同list。
示例:
# 需求:遍历元组中的每一个元素。
tu = (1,True,'吕布',[1,'MrLin',(1,888,5)],'hfp')
for item in tu:
print(item)
ps-1:与for平齐的行,只打印for循环的序列中的最后一个元素。
ps-2:break和continue在for循环中依然适用。
5.7len
ps:对于list,返回值是:tuple中的元素个数;
tu = (1,True,'吕布',[1,'MrLin',(1,888,5)],'hfp')
print(len(tu))
# 结果:5
5.8in
# 判断某元素知否在tuple中。
tu1 = (1, 2, 3, 0)
if 666 in tu1:
print('存在')
else:
print('不存在')
(二).tuple的方法(无)
(三).tuple的强制转换 -同list。
写在前面-1:只能将容器类的数据类型转换为list。
写在前面-2:str-->list,是将str的每个字符作为list的元素。
示例:
# 示例一:str--》tuple # 将str的每个字符作为tuple的每个元素。
s = '吕布睡着了'
tu1 = tuple(s)
print(tu1)
# 结果:('吕', '布', '睡', '着', '了')
# 示例二:list--》tuple
li = [1, 2, 3]
tu2 = tuple(li)
print(tu2)
# 结果:(1, 2, 3)
# 示例三:dict--》tuple # 只是将dict的key转换为tuple。
dict1 = {'name': '吕布', 'age': 18}
tu3 = tuple(dict1)
print(tu3)
# 结果:('name', 'age')
# 示例四:set--》tuple
set1 = {1, 2, 3}
tu4 = tuple(set1)
print(tu4)
# 结果:(1, 2, 3)
六.字典 -可变/无序。(3.5以后有序)
写在前面-1:字典的键和集合一样,利用哈希算法得到的内存地址存储和查询,查询速度快。查的是键。然后通过键再去查值。
写在前面-2:在哈希表中,1和True被认为是同一个值。若2者同为dict的键,则采用old键,new值。
6.0字典定义
字典(dict)是python中唯⼀的⼀个映射类型。它是以{ }括起来的键值对组成。
在dict中key是 唯⼀的.在保存的时候, 根据key来计算出⼀个内存地址. 然后将key-value保存在这个地址中.
这种算法被称为hash算法, 所以, 切记, 在dict中存储的key-value中的key必须是可hash(即不可变)的,这个是为了能准确的计算内存地址⽽规定的。
目前已知的可哈希(不可变)的数据类型: int, str, tuple, bool ;
不可哈希(可变)的数据类型: list, dict, set。
# 字典的特点-1:数据与数据之间关联性强,查询速度快。
# 字典的特点-2:键必须是可哈希的(不可变类型)。值可保存任意类型的数据。
# ps:字典是无序的。python3.6版本以后才有序。
格式:
dict1 = {'key1':value1,'key2':value2}
ps:键必须是可哈希的。int, str, tuple, bool。值没有要求.可以保存任意类型的数据。
6.0’字典的创建方式 -4种
# 面试会考
# 方式一:
dic = dict((('one', 1), ('two', 2), ('three', 3))) # 大元组里套小元组。
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式二:
dic = dict(one=1, two=2, three=3) # 类似关键字。
print(dic)
# 方式三:
dic = dict({'one': 1, 'two': 2, 'three': 3}) # 最常见。
print(dic)
# 方式四:fromkeys 字典的快速创建方式。 # 所有值公用一个内存空间。
# 格式:dic = dict.fromkeys(序列, value) # 序列中的所有元素必须可hash。
dic = dict.fromkeys(['a', 'b', 'c'], 666)
print(dic)
# 结果:{'a': 666, 'b': 666, 'c': 666}
(一).公共功能 -6个。
6.1索引
ps:因为字典无序,所以只能通过键去取值。没有切片和步长。
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
print(dic['name'])
# 结果:吕布
ps:关于dict无序的问题。dict保存的数据不是按照我们添加进去的顺序保存的. 是按照hash表的顺序保存的. ⽽hash表不是连续的. 所以不能进行切片操作. 它只能通过key来获取dict中的数据。
6.2for循环
# 1.循环打印字典的键 -2种。
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
# 法一:直接for循环字典
for i in dic:
print(i)
# 法二:for循环dic.keys()
for i in dic.keys():
print(i)
# 2.循环打印字典的值 -2种。
# 法一:for循环dic.values()
for i in dic.values():
print(i)
# 法二:for循环字典,然后根据键取值。
for i in dic:
print(dic[i])
# 3.循环字典,获取键和值。
for k, v in dic.items(): # 解构
print(k, v)
结果:
name 吕布
age 8
hobby eat
# 4.循环打印元组形式的键值对。 # 不常用。
for i in dic.items(): # 没有对元组解构
print(i)
结果:
('name', '吕布')
('age', 8)
('hobby', 'eat')
6.3len
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
print(len(dic))
# 结果:3
ps:len获取到的是字典中键值对的对数。
6.4修改 -键存在,改值;键不存在,则添加键值对. dict[键] = '新值'
ps: dict[键] = '新值',是根据键是否存在来改值。
# 改值 dict[键] = '值'
# Case1.键存在 -改值
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
dic['name'] = '貂蝉'
print(dic)
# 结果:{'name': '貂蝉', 'age': 8, 'hobby': 'eat'}
# Case2.键不存在 -添加键值对
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
dic['sex'] = '男'
print(dic)
# 结果:{'name': '吕布', 'age': 8, 'hobby': 'eat', 'sex': '男'}
6.5删除 -通过键删除键值对 del dict[键]
ps:删除的是整个键值对。
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
del dic['name']
print(dic)
# 结果:{'age': 8, 'hobby': 'eat'}
6.6 in -判断字典的键/值/键值对是否在dict中。
# 判断字典的键/值/键值对是否在dict中。
# 写在前面:in dic 默认判断的是键。
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
# 1.判断键是否在dict里。
# 法一:in
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
if 'k1' in dic:
print("在里面") # 但replace替换不了。
# 法二:get -键在dict中,返回值;不在dict中,则返回'不是字典的键'。
info = {'name': '吕布', 'age': 18}
data = info.get('age', '不是字典的键')
print(data)
# 2.判断值是否在dict里:没有直接方法。只能通过遍历字典的值/将.values()转换为list再用in判断。
# 方式一:循环判断
flag = '不存在'
for item in dic.values():
if 'v1' == item:
flag = '存在' # 用else是错的。
break
print(flag)
或:
info = {'name': '吕布', 'age': 18}
flag = False
for item in info:
if item == 'name':
flag = True
break
if flag:
print('在')
else:
print('不在')
# 方式二:.values()转换为list后,再用in
fake_li = dic.values()
value_li = list(fake_li)
if 'v1' in value_li:
print('此值存在')
# 简写:
if 'v1' in list(dic.values()):
print('此值存在')
else:
print('不存在')
# 3.分别判断键值对'k2':'v2','k8':'v8'是否在dict里。
# 法一:常规git查
value = dic.get('k8')
if value == 'v2':
print('存在')
else:
print('不存在')
# 法二:利用git可以设置返回值的特性,健不存在,返回自定义结果;键存在,返回值不打印。
if dic.get('k8', '不存在') == '不存在':
print('此键值对不存在')
else:
print('存在')
# 结果:此键值对不存在
if dic.get('k2', '不存在') == '不存在':
print('此键值对不存在')
else:
print('存在')
# 结果:存在
(二).字典的方法 -keys,values,items&查&删&增。
1.查keys,values,items 3种 **
- 获取字典的键 dic.keys()
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
key_fake_l = dic.keys()
print(key_fake_l)
print(type(key_fake_l))
# 结果:
dict_keys(['name', 'age', 'hobby'])
<class 'dict_keys'>
ps:dic.keys()就是'dict_keys'类型。是个高仿列表,存放的都是字典中的key。
- 获取字典的值 dic.values()
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
value_fake_l = dic.values()
print(value_fake_l)
print(type(value_fake_l))
# 结果:
dict_values(['吕布', 8, 'eat'])
<class 'dict_values'>
ps:dic.values()就是'dict_values'类型。是个高仿列表,存放的都是字典中的value。
- 获取字典的键值对 dic.items()
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
key_value_fake_l = dic.items()
print(key_value_fake_l)
print(type(key_value_fake_l))
# 结果:
dict_items([('name', '吕布'), ('age', 8), ('hobby', 'eat')])
<class 'dict_items'>
ps:dic.items()就是'dict_items'类型。是个高仿列表,存放的是多个元组!!元祖中第一个是字典中的键,第二个是字典中的值。
- 练习题:循环字典获取键/值/键和值。
# 1.循环打印字典的键 -2种。
dic = {'name': '吕布', 'age': 8, 'hobby': 'eat'}
# 法一:直接for循环字典
for i in dic:
print(i)
# 法二:for循环dic.keys()
for i in dic.keys():
print(i)
# 2.循环打印字典的值 -2种。
# 法一:for循环dic.values()
for i in dic.values():
print(i)
# 法二:for循环字典,然后根据键取值。
for i in dic:
print(dic[i])
# 3.循环打印元组形式的键值对。
for i in dic.items(): # 没有对元组解构
print(i)
结果:
('name', '吕布')
('age', 8)
('hobby', 'eat')
# 4.循环字典,获取键和值。
for k, v in dic.items(): # 解构
print(k, v)
结果:
name 吕布
age 8
hobby eat
- 解构(拆包) # interview
# 写在前面-1:凡是可迭代的数据类型,都能进行拆包。
# 写在前面-2:前后数量要一致。即序列里有几个元素,前面就必须要有几个变量去接收。否则报错。
# 示例:
a, b = {'name': '吕布', 'age': 8}
print(a, b)
# 结果:name age # 只是键。
a, b, c = [11, 22, 33]
print(a, b, c)
# 结果:11 22 33
a, b = {111, 200} # 集合的解构,最多2个。多了报错。
print(a, b) # 集合是无序的。故拆包后依然无序。
# 结果:200 111
a, b = {111, 200, 5}
print(a, b, c)
# 结果:ValueError: too many values to unpack (expected 2)
# 练习题:
# 1.需求:将字符串value = '1 + 3 + 2'用+号分割,并将分割后的结果加入列表中。然后取列表中的值。
# 法一:常规方法 -麻烦
value = '1 + 3 + 2'
new_li = value.split('+')
v1 = new_li[0]
v2 = new_li[1]
v3 = new_li[2]
print(v1, v2, v3)
# 结果:1 3 2
# 法二:解构 -简便
value = '1 + 3 + 2'
a, b, c = value.split('+')
print(a, b, c)
# 结果:1 3 2
# 2.字典dic.items()方法分析。
# a.循环打印元组形式的键值对。
for i in dic.items(): # 没有对元组解构
print(i)
结果:
('name', '吕布')
('age', 8)
('hobby', 'eat')
# b.循环字典,获取键和值。
for k, v in dic.items(): # 解构
print(k, v)
结果:
name 吕布
age 8
hobby eat
2.查 dict.git('键',返回值) ** # 键不存在,不会报错!可以自定义返回的结果。
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
s = dic['k0'] # 索引查值,如果健不存在,会报错。
print(s)
# 结果:KeyError: 'k0'
s1 = dic.get('k4') # git通过键查值,如果健不存在,会返回None。
print(s1)
# 结果:None
# None是种特殊的数据类型,该类型表示空(无任何功能,专门用于提供空值)。
s2 = dic.get('k0', '没有此值') # git通过键查值,如果健不存在,可以自定义返回的结果。
print(s2)
# 结果:没有此值
s2 = dic.get('k3', '没有此值') # 如果键存在,则设置的返回值不打印。
print(s2)
# 结果:v3
3.删 dict.pop('键') 可以看到删除的值(不常用)
dic = {'v1': 'k1', 'v2': 'k2'}
deleted = dic.pop('v1')
print(dic,deleted)
# 结果:{'v2': 'k2'} k1
4.增 更新dict.update({'键':值,'键':值}) # 键不存在,则添加;存在,则更新(覆盖) -(不常用)。
写在前面:注意hash表中1和True是同一个值。故,若键是1/True则不会增加,而是更新(覆盖)。
ps:1和True等价,无优先顺序。若2者同为dict的键,哪个键在前面,则最后就留哪个键。old值被覆盖。
格式:
dict.update(字典)
示例:
dic = {'v1': 'k1', 'v2': 'k2'}
dic.update({'v3': '666', 'v1': '100'})
print(dic)
# 结果:{'v1': '100', 'v2': 'k2', 'v3': '666'}
特例: 在hash表中,1和True被认为是同一个值。
# 示例1:
dic = {True: '吕布', 1: 18} # 1和True同为dict的键时,则谁在前面最后就留谁。值则是old值被覆盖。
print(dic)
# 结果:{True: 18}
dic = {1: '吕布', True: 18} # 1和True同为dict的键时,则谁在前面最后就留谁。值则是old值被覆盖。
print(dic)
# 结果:{1: 18}
# 示例2:用update时,若键是1/True,不会增加,而是更新(覆盖)。
dic = {True: '吕布', 'age': 18}
dic1 = {1: '貂蝉', 'name': 'MrLin'}
dic.update(dic1)
print(dic)
# 结果:{True: '貂蝉', 'age': 18, 'name': 'MrLin'}
练习题:
1.请输出字典所有的键和值,并让用户输入 name/age/gender/hobby,根据用户输入的键,输出对应的值。
dic = {'name': '吕布', 'age': 8, 'gender': '男', 'hobby': 'eat'}
for k, v in dic.items():
print(k, v)
key = input('请输入键: ')
print(dic[key])
2.给你一个空字典,请在空字典中添加数据:k1:1,k2:'2',k3:3。
dic = {}
dic['k1'] = 1
dic['k2'] = '2'
dic['k3'] = 3
print(dic)
# 结果:{'k1': 1, 'k2': '2', 'k3': 3}
3.给你一个空字典,请让用户输入:key,value,将输入的key和value添加到字典中。
dic = {}
key = input('请输入键:')
value = input('请输入值:')
dic[key] = value
print(dic)
# 结果:{'k1': '123'}
4.给你一个空字典,请一直让用户输入:key,value,将输入的key和value添加到字典中。直到用户输入N,则表示不再输入。
dic = {}
while True:
key = input('请输入键:')
if key.upper() == 'N'.upper():
break
value = input('请输入值:')
dic[key] = value
print(dic)
5.有字符串content = 'k1|v1,k2|v2,k3|123',请将其用如下方式来表示:info = {'k1':'v1','k2':'v2','k3':'123'}
# 法一:常规 -索引取值。
info = {}
content = 'k1|v1,k2|v2,k3|123'
new_li = content.split(",")
for item in new_li:
items_li = item.split("|")
info[items_li[0]] = items_li[1]
print(info)
# 法二:解构取值 -简便。
info = {}
content = 'k1|v1,k2|v2,k3|123'
new_li = content.split(",")
for item in new_li:
k, v = item.split("|") # 解构取值。
info[k] = v
print(info)
6.创建出一个用户列表,格式如下。然后让用户输入用户名和密码进行登陆。
'''user_li = [
{'user': '让用户输入:', 'password': '让用户输入:'},
{'user': '让用户输入:', 'password': '让用户输入:'},
{'user': '让用户输入:', 'password': '让用户输入:'},
{'user': '让用户输入:', 'password': '让用户输入:'},
{'user': '让用户输入:', 'password': '让用户输入:'}, # 输入N,则不再让用户输入。
]'''
# 1th:构建用户列表
# 法一:
user_li = []
while True:
u = input('请输入用户名:')
if u.upper() == 'N':
break
p = input('请输入密码:')
dic = {}
dic['user'] = u # 单独写键和值。
dic['password'] = p
user_li.append(dic)
print(user_li)
# 法二:推荐。
user_li = []
while True:
u = input('请输入用户名:')
if u.upper() == 'N':
break
p = input('请输入密码:')
dic = {'user': u, 'password': p} # 键和值直接写进dict里。
user_li.append(dic)
print(user_li)
# 2th:用户校验
# [{'user': 'k1', 'password': '123'}, {'user': 'k2', 'password': '456'}]
username = input('请输入用户名:')
password = input('请输入密码:')
status = '登录失败'
for item in user_li:
if username == item['user'] and password == item['password']:
status = '登录成功'
break
print(status)
(三).字典的嵌套 **
一层一层降维去找。同list的嵌套。
ps:通常list的嵌套会和dict的嵌套结合。
(四).字典的坑 -fromkeys & 字典在循环时不能修改。
- 1.字典的坑1 -fromkeys
写在前面:fromkeys() 快速创建字典
定义:Python 字典 fromkeys() 函数用于创建一个新字典,以序列中元素做字典的键,value为字典所有键对应的初始值。
格式:
dic = dict.fromkeys(序列,value) # 用于创建一个新字典。
print(dic)
返回值:该方法返回一个新字典。
示例:
dic = dict.fromkeys(['a', 'b', 'c'], ['你好'])
print(dic)
# 结果:{'a': ['你好'], 'b': ['你好'], 'c': ['你好']}
ps:序列里的元素必须全部可hash。
字典的坑1 -fromkeys:
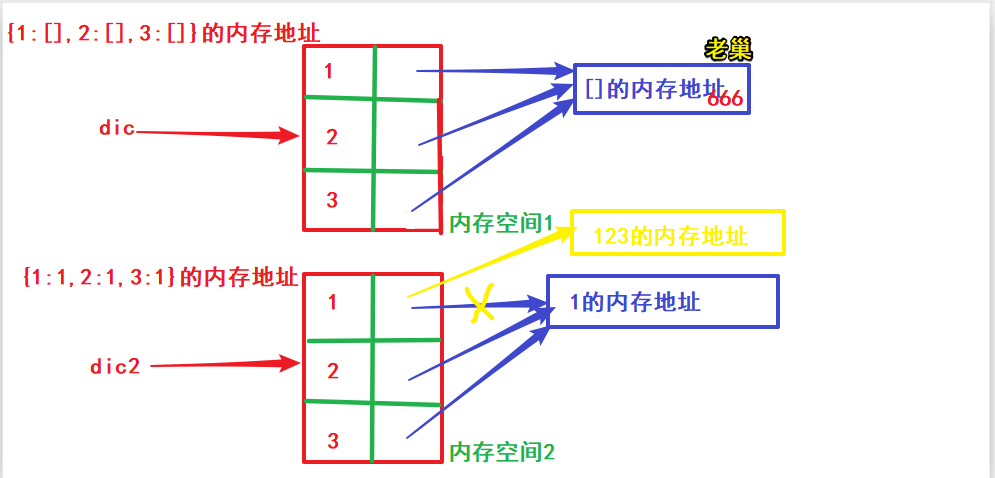
写在前面:dict的值用的都是同一个内存空间,只有值是可变数据类型的时候才会出现坑,使用时需慎重。
# 坑1 -用fromkeys创建dict时,当value是可变数据类型时,修改其中任何一个,其他都会变。
# 看代码写结果:
# 01.当value为可变数据类型时:字典的所有值共用1个内存空间。其中1个变,其他的都会变。
dic = dict.fromkeys([1, 2, 3], []) # 快速创建字典。
# print(dic) # {1: [], 2: [], 3: []}
dic[1].append(666) # 通过dic[1]找到老巢并修改。
print(dic) # {1: [666], 2: [666], 3: [666]}
# 02.当value为不可变数据类型时:1个变,其他的不变。
dic = dict.fromkeys([1, 2, 3], 1)
# print(dic) # {1: 1, 2: 1, 3: 1}
dic[1] = 123 # 改的只是dic[1]的指向。
print(dic) # {1: 123, 2: 1, 3: 1} # 1个变,其他的不变,因为是不可变数据类型
- 2.字典的坑2 -字典在循环时不能修改 ***
# 坑2 -循环问题:循环一个字典时,如果改变这个字典的大小,就会报错。 ***
# 需求:将字典的键中含有'k'元素的键值对删除。
# 错误示例:
dic = {'k1': '吕布', 'k2': '妥妥', 'k3': '大黄', 'age': 18}
for item in dic:
if 'k' in item:
dic.pop(item)
print(dic) # 会报错:RuntimeError:字典在迭代过程中更改了大小
# 出坑:2种方法。
# 法一:既然循环dict的时候不能修改,那就循环其他序列的时候修改。
dic = {'k1': '吕布', 'k2': '妥妥', 'k3': '大黄', 'age': 18}
for key in list(dic.keys()): # 将字典的键放入列表中,再循环修改。
if "k" in key:
dic.pop(key)
print(dic)
或:
for key in dic.keys(): # 循环dic.keys()这一伪列表,然后修改。
if "k" in key:
dic.pop(key)
print(dic)
# 结果:{'age': 18}
# 法二:把需要修改的元素暂时先保存在一个list中, 然后循环list, 根据list中的元素再对dict做修改。
dic = {'k1': '吕布', 'k2': '妥妥', 'k3': '大黄', 'age': 18}
dic_del_list = []
# 删除key中带有'k'的元素
for key in dic:
if 'k' in key:
dic_del_list.append(key)
for e in dic_del_list: # 根据列表中的元素
del dic[e] # 删除dic的键值对
print(dic)
# 结果:{'age': 18}
七.集合set -不可变。无序。
写在前面-1:集合和字典的键一样,利用哈希算法得到的内存地址存储和查询,查询速度快。
写在前面-2:在哈希表中,1和True被认为是同一个值。若2者同时出现在set中,则留先出现的元素。
set1 = {1, 55, 'name', 7, True, 99} # 1先出现,留1。
print(set1)
# 结果:{1, 99, 7, 55, 'name'}
set1 = {True, 55, 'name', 7, 1} # True先出现,留True。
print(set1)
# 结果:{True, 'name', 7, 55}
7.0定义
set集合是python的⼀个基本数据类型。用{}括起来。只能保存可hash(不可变)数据。但是set本身是可变的。
# 特点:无序。元素不重复。
# ps:1.集合中的元素必须是不可变的(int/str/bool/tuple/None);2.但set本身可变。3.用{}括起来。
# 用处:列表去重。爬虫。
格式:
set1 = {1, '小吕布', True,}
# 空集合:set()
示例:
# 1.利用set内元素不重复的特性,进行list去重。
li = [45, 5, "哈哈", 45, '哈哈', 50]
li = list(set(li)) # 把list转换成set, 然后再转换回list
print(li)
# 结果:[5, 50, 45, '哈哈']
# 2.set中的元素是不重复的, 且⽆序的。
s = {"吕布", "貂蝉", "吕布",'张飞'}
print(s)
# 结果:{'张飞', '吕布', '貂蝉'}
# 结果:{'张飞', '貂蝉', '吕布'} # 每次打印的结果元素顺序都不一样。
(一).公共功能 -3个。
写在前面:因为set无序,故不能索引、切片、步长、删除、修改(因为修改&删除是根据索引操作)。
7.1for循环
同list。
7.2len
同list。
7.3 in
# 判断某元素是否在set中。
set1 = {1, 2, 3, 0}
if 666 in set1:
print('存在')
else:
print('不存在')
(二).set的方法 -增&删&求交/并/差/对称差集。
写在前面:set可变,故对其进行操作,会直接对原集合产生影响。除了求交并差集!
(1).set的增 & 删 -直接对原set产生影响。
1.增 -add追加 *
格式:
set1.add(元素) # 元素必须不可变。
示例:
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲")
print(s)
s.add("郑裕玲") # 重复的内容不会被添加到set集合中
print(s)
# 结果:
{'刘嘉玲', '关之琳', '王祖贤', '郑裕玲'}
{'刘嘉玲', '关之琳', '王祖贤', '郑裕玲'}
批量增加 -update *
格式:
set.update({要增加的集合})
示例:
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update({'林青霞', '李若彤', '白娘子', '小青', '关之琳'}) # 重复的元素不再添加。
print(s)
# 结果:{'刘嘉玲', '林青霞', '小青', '王祖贤', '白娘子', '关之琳', '李若彤'}
2.删 -discard * #元素不存在,不会报错(好)。
格式:
set1.discard(元素) # 只能根据元素删,不能索引删(因为set无序)。# discard丢弃。
示例:
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.discard("关之琳")
print(s)
# 结果:{'王祖贤', '刘嘉玲'}
ps:discard比remove好,因为remove元素不存在会报错。
(2).求set的交/并/差/对称差集 -产生新的集合!不是在原有集合上进行操作。
写在前面-1:结果是1个新的集合。不是在原有集合上进行操作。
写在前面-2:intersection/union/difference后面传的值除了可以是set外,还可以是list或tuple!
写在前面-3:若用符号&|- ^ 去求交并差集,则后面传的值只能是set。
1.交集 -set.intersection(集合/列表/元组) 或 &。
# 交集:两个集合中的共有元素。
# 1.intersection求交集 -后面传的值可以是集合/列表/元组。
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
new_s = s1.intersection(s2) # 是产生新的set。
print(new_s)
# 结果:{'⽪⻓⼭'}
# 后面传的值是列表or元组。
s1 = {"刘能", "赵四", "⽪⻓⼭"}
li = ["刘科⻓", "冯乡⻓", "⽪⻓⼭"]
new_s = s1.intersection(li)
print(new_s)
s1 = {"刘能", "赵四", "⽪⻓⼭"}
tu = ("刘科⻓", "冯乡⻓", "⽪⻓⼭")
new_s = s1.intersection(tu)
print(new_s)
# 2.用符号&求交集 -传的值只能是set!!
print(s1 & s2) # 结果:{'⽪⻓⼭'}
2.并集 -set.union(集合/列表/元组) 或 |。
# 并集:不是单纯的将2个序列里的元素合到一起,而是会去重。
# 1.用union求并集 -后面传的值是集合/列表/元组。
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
new_set = s1.union(s2)
print(new_set)
# 结果:{'刘科⻓', '冯乡⻓', '赵四', '⽪⻓⼭', '刘能'}
# 2.用符号|求并集 -传的值只能是set!!
print(s1 | s2)
# 结果:{'刘科⻓', '冯乡⻓', '赵四', '⽪⻓⼭', '刘能'}
3.差集 -set.difference(集合/列表/元组) 或 -。
# 差集
# 写在前面:2种方法求出来的结果都是前面那个set的差集。
# 1.用difference求差集 -后面传的值是集合/列表/元组。结果是前面那个集合的差集。
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
new_set = s1.difference(s2)
print(new_set)
# 结果:{'赵四', '刘能'}
# 2.用符号-去求差集 -01.传的值只能是set。02.结果是前面那个集合的差集。
print(s1 - s2)
# 结果:{'赵四', '刘能'}
4.对称差集(反交集) -symmetric_difference((集合/列表/元组) 或 ^。
# 对称差集(反交集):先取前面这个集合的差集,再取后面这个集合的差集。放一起。
# 1.用symmetric_difference去求对称差集 -后面传的值是集合/列表/元组。
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
new_set = s1.symmetric_difference(s2)
print(new_set) # {'冯乡⻓', '刘能', '刘科⻓', '赵四'}
# 2.用符号^去求对称交集 -传的值只能是set。
print(s1 ^ s2)
# 结果:{'冯乡⻓', '刘能', '刘科⻓', '赵四'}
八.None -一种特殊的数据类型。
def:None是1种特殊的数据类型,该类型表示空(无任何功能,专门用于提供空值)。
九.常用的类型转换
(一).7种转bool为False的情况。
0,'',[],(),{},set(),None。 # 空元组是(),不加逗号;空集合是set()。
# 7种数据类型转bool为False的情况:
None
int 0
str ''
list []
dict {}
set set() # 虽然集合的格式是v = {1,2},但空集合用set()来表示。
tuple ()
# None是一种特殊的数据类型,该类型表示空(无任何功能,专门用于提供空值)。
# 为什么空集合是set()?
# - 因为7种数据类型中,5种序列,在空的情况下,只有集合仅存在1种表现形式,其他数据类型都有2种表现方式。
None v0 = None
int v1 = int() --> 0
bool v2 = bool() --> False
str v3 = ''
v3 = str()
list v4 = []
v4 = list()
tuple v5 = ()
v5 = tuple()
dict v6 = {}
v6 = dict()
set set() # 仅此一种变现方式。
(二).其他6种之间的转换 -常用6种。
# 1.str --》int # 只渡可渡之人
s1 = '666'
value = int(s1) # str中的元素必须是int,才可转。
print(value)
结果:666
# 2.int --》str
value = str(999) # '999'
# 3.list --》tuple
li = ['貂蝉', 123, '吕布', '熬夜长痘aaa']
tu1 = tuple(li)
print(tu1)
结果:('貂蝉', 123, '吕布', '熬夜长痘aaa')
# 4.tuple --》list
tu = ('貂蝉', 123, '吕布', '熬夜长痘aaa')
l1 = list(tu)
print(l1)
结果:['貂蝉', 123, '吕布', '熬夜长痘aaa']
# 5.list <--str # 字符串方法.split('str中的某字符->分割符')
s = '1+ 2 +10 + 2 0'
s_li = s.split('+')
print(s_li)
# 结果:['1', ' 2 ', '10 ', ' 2 0']
# 6.list -->str # 字符串方法.join('连接符')
li = ['吕布', '小黑', '妥妥']
s = '&'.join(li) # join(序列).序列里的元素必须全部是str类型才可进行拼接。
print(s)
# 结果:吕布&小黑&妥妥
练习题:
# 1.将列表nums = [11,22,33]转换成字符串'11_22_33'。
nums = [11, 22, 33]
for item in range(0, len(nums)):
nums[item] = str(nums[item]) # 必须确保序列里的元素全部都是str,才能join拼接。
s = '_'.join(nums) # join拼接后的结果是个str。
print(s)
# 结果:11_22_33
# 2.将'1+ 2+ 3+ 4'转换成[1,2,3,4]
s = '1+ 2+ 3+ 4'
s = s.replace(' ', '')
li = s.split('+')
print(li)
十.七种数据类型小结
(1).7种数据类型对比
1.格式
- int:1。2。666。 # 只能是整数。
- bool:True False
- str:'内容',"内容",'''内容''',"""内容"""。 # 可以保存任意类型的数据or字符。但切片/索引取到的均是str类型。
- list:[1, 2, '吕布', True, [666, 'MrLin'], (11, 22,'貂蝉')] # 可以保存任意类型的数据。
- tuple:(1, 2, '吕布', True, [666, 'MrLin'], (11, 22,'貂蝉')) # 可以保存任意类型的数据。
- dict:{1: '水', False: 0, "name": '吕布', (1, 2): [11,22]} # key不可变, value没有要求.可以保存任意类型数据
- set:{"吕布", "大黄", "妥妥"} # 只能保存不可变的数据。但set本身是可变的。
2.可变 & 不可变
- 可变(不可hash):list、dict、set。
- 不可变(可hash):int、bool、str、tuple。
3.可迭代 & 不可迭代
- 可迭代(容器类):str、list、tuple、dict、set。
- 不可迭代(非容器类):int、bool。
4.有序 & 无序
写在前面:只有容器类(可迭代)数据,说有序/无序才有意义。
- 有序(可索引):str、list、tuple、dict(3.5版本以后有序-不能索引,只能通过键取值/查询)。
- 无序(不可索引取值):set。-集合是无序的。
ps:通常认为dict是无序的。但dict可以通过索引取值,不过取到的只是dict的键。
5.各自特点 -(待续)
- str:切片/索引取到的仍然是str。
- list:str<-->list之间的转换要清楚。均用的是str方法:join,split。
- tuple:不可变。最外层元素不可修改,但深层元素中的可变数据类型可修改。
- dict:查询速度快( 因为内部是利用hash算法存储/查值 )。键必须可hash(不可变)。
- set:无序。元素必须可hash。查询速度快( 因为内部是利用hash算法存储/查值 )。
(2).公共功能小结
写在前面:一共9种公共功能。加,乘数字,索引,切片,步长,for循环,len,删,改,in。
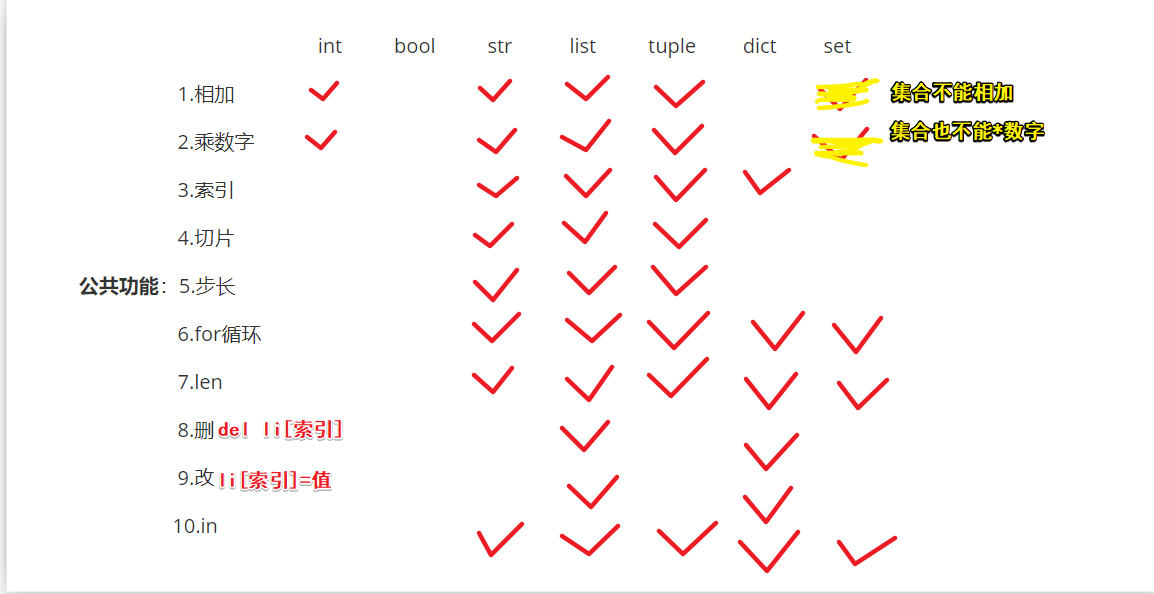
十一.for循环
ps-1:for循环内部自加机制,不需要我们再去自加让其转起来。
ps-2:for循环的对象必须可迭代。eg:字符串/列表/字典/元组/集合这5种可迭代的类型and其他可迭代的序列(eg:range())。)
ps-3:for循环可嵌套。
ps-4:break和continue在for循环中依然适用。
ps-5:与for平齐的行,只打印for循环的序列中的最后一个元素。
另:for和while的应用场景:有穷尽优先使用for,无穷尽用while。
格式:
for 变量 in 序列:
循环体内容
示例:
# 需求:遍历字符串中的每一个元素。
value = ['吕布666',True,7]
for item in value:
print(item)
结果:
吕布666
True
7
ps详细:
# ps-1:与for平齐的行,只打印for循环的序列中的最后一个元素。
value = ['吕布666',True,7]
for item in value:
print(item)
print(item) # 只打印最后一个元素。
# 结果:7 # ps-2:break和continue在for循环中依然适用。
value = ['吕布666',True,7]
for item in value:
print(item)
break
# 结果:'吕布666'
value = ['吕布666',True,7]
for i in value:
print(i)
break
print('啊哈') # 不打印。
# 结果:'吕布666'
value = ['吕布666',True,7]
for i in value:
print(i)
continue
print('啊哈') #不打印。
# 结果:
吕布666
True
7
练习题:
1.遍历list中的各元素
content = ['MrLin_儒雅先生','纳兰容若']
for item in content:
print(item)
2.遍历各元素的索引
content = ['MrLin_儒雅先生','纳兰容若',666,True,'Faye']
max_index = len(content) -1
for item in range(0,max_index + 1):
print(item)
3.for循环的嵌套
- 练习题:
1.看代码写结果:
users = ['吕布','小花','流浪歌手','天赋']
for item in users:
for ele in item:
print(ele)
2.看代码写结果:
users = ['吕布','小花','流浪歌手','天赋']
for item in users:
print(item)
for ele in item:
print(ele)
十二.len -获取长度
(一).len
ps-1:仅适用于7种数据类型中的可迭代类型:str/list/tuple/dict/set,int和bool不行。
ps-2:len(5种数据类型)的返回值判断依据。
对于str,返回值是:str中的字符个数;
对于list,返回值是:list中的元素个数;
对于tuple,返回值是:tuple中的元素个数;
对于dict,返回值是:dict中的键值对的个数;
对于set,返回值是:set中的元素个数。
示例:
(二).应用
1.使用while循环 -打印str/list/tuple/dict/set中的每一个元素
- 使用while循环遍历str中的每一个元素:
value = '吕布666'
index = 0
while index <= len(value) - 1:
val = value[index] # 根据索引取值。
print(val)
index += 1
2.使用for循环 -打印str/list/tuple/dict/set中的每一个元素
写在前面:for循环时可以循环的数据结构必须是可迭代的:str/list/tuple/dict/set,int和bool不行。
- 使用for循环遍历str中的每一个元素:
value = '吕布666'
for i in value:
print(i)
# 结果:
吕
布
6
6
6
(三).练习题
1.需求:让用户输入任意字符串,获取字符串之后计算其中有多少个数字。
(1).while循环:
content = input('请输入内容:')
index = 0
count = 0
while index <= len(content) - 1:
val = content[index]
if val.isdigit():
count += 1
index += 1
print(count)
(2).for循环:
content = input('请输入内容:')
count = 0
for i in content:
if i.isdigit(): # i.isdigit()的返回值就是True/False,如果是True(即if的条件是True),
count += 1 # 则满足if的条件,就会执行if里面的内容。
print(count)
2.需求:让用户输入任意一个str,取这个str的最后2个字符。
方法一:
data = input('请输入:')
value = data[-2:]
print(value)
方法二:len -更严谨,因为可加个if判断这个str够不够2个字符再取切片。
data = input('请输入:')
total_len = len(data)
value2 = data[total_len - 2:total_len]
print(value2)
# 完整版:
value = input('请输入内容:')
total_len = len(value)
if total_len >= 2:
val = value[total_len - 2:total_len]
print(val)
else:
print('输入有误')
十三.内置函数 -range()
写在前面:range()是python的1个内置函数,用在for循环中!!
定义:
range()是一个范围。它的内部是一个乘放整数的伪列表,通过()里的参数来控制伪列表里数字的范围。
若直接打印range(),则结果是它本身,而不会显示伪列表里的内容(若要其显示,则需将range类型转换为list类型)。
这就是range()类型。
剖析:
fake_l = range(1,5,2) print(fake_l)
print(type(fake_l))
print(list(fake_l))
结果:
range(1, 5, 2) # 一个范围。
<class 'range'> # 它就是range类型,不是list类型。只不过它的内部表现形式是个看似列表的伪列表而已。
[1, 3] # 若想看range到底是哪些范围的数字,可将其转换为list类型,再进行查看。
格式:
range(start, stop, step)
参数说明:
第一个参数start是范围的起始位置。默认是从 0 开始。例如range(5)等价于range(0, 5);
第二个参数stop是范围的结束位置。但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5;
第三个参数step是步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
ps-1:这里的起始位置,类似于切片。不顾尾;步长类似于str的步长,步长为负,则尾向左顺延1位。
ps-2:str的切片/步长,若取不到,是什么都不打印但不报错。但range若取不到值,则伪列表为空!!
示例:
>>> range(10) # 代表 从 0 开始到 9 的数字范围
>>> range(1, 11) # 代表 从 1 开始到 10
>>> range(0, 30, 5) # 代表 从 0 开始到 29,步长为 5 的数字范围
>>> range(0, -10, -1) # 代表 [0, -1, -2, -3, -4, -5, -6, -7, -8, -9]的范围,但显示不出来。
>>> range(0) # 代表 [] ,需将range类型转换为list类型才能看到结果。eg:print(list(range(0)))。
>>> range(1, 0) # [] # 当范围里的参数取值,什么都取不到时,伪列表里为空。
>>> range(0, 0) # []
>>> range(0, 1) # [0]
适用场景:一般用在for循环中。 (因range()本身可迭代,故可for循环)
练习题:
1.利用for循环和range打印出下面str的索引。
s = "哈哈哈哈哈那大傻"
for i in range(0,len(s)):
print(i)
2.利用for循环和range打印出下面列表的索引。
li = ['暖男吕布','呲牙大黄','傻二妥妥','x']
for i in range(0,len(li)):
print(i)
3.打印2-10 ,用for循环和while循环分别实现。
for i in range(2,11):
print(i) # for循环内部自加 count = 2
while count <= 10:
print(count)
count += 1 # 需要自加
4.用for打印1 2 3 4 5 6 8 9 10(没有7)。
for i in range(1,11):
if i != 7:
print(i) for i in range(1,11):
if i == 7:
pass
else:
print(i)
5.利用for循环和range从100~1,倒序打印。
for i in range(100,0,-1): # 步长为负,则向左顺延。
print(i)
6.利用for循环和range找出100以内所有的偶数,并将这些偶数加入到一个列表中。
# 法一:range步长
li = []
for i in range(0,101,2):
li.append(i)
print(li)
# 法二:range切片
li = []
for i in range(0,101):
if i % 2 == 0:
li.append(i)
print(li)
7.打印1-100的所有偶数,并将这些偶数放到一个列表中。
li = []
for i in range(2,101,2): # 从第一个偶数开始.
li.append(i)
print(li)
8.利用for循环和range找出50以内能被3整除的数,并将这些数加入到一个列表中。
li = []
for i in range(0,51):
if i % 3 == 0: # % 是取余数。
li.append(i)
print(li)
# 结果:[0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48]
9.利用for循环和range找出50以内能被3整除的数,并插入到列表的第0个索引位置。 # 即倒序加入列表。
li = []
for i in range(0,51):
if i % 3 == 0: # % 是取余数。
li.insert(i)
print(li)
结果:[48, 45, 42, 39, 36, 33, 30, 27, 24, 21, 18, 15, 12, 9, 6, 3, 0]
9.利用for循环和range,将1-30的数字一次添加到一个列表中,并循环这个列表,将能被3整除的数改成。
li = []
index = 0
for i in range(1,31):
li.append(i)
for i in li:
if i % 3 == 0:
li[index] = ''
else:
index += 1
print(li)
10.用range分别打印0-9和9-0。并将其放入列表中。
print(list(range(0,10))) # 尾开区间。步长为正,向右顺延。
print(list(range(9, -1, -1))) # 切片的尾是开区间。步长为负,则向左顺延。
结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
11.将字符串name = '吕布睡着了'进行反转。
思路:for循环+range倒序。ps:其他方法见面试题。
result = ''
max_index = len(name) - 1
for item in range(max_index, -1, -1):
result = result + name[item]
print(result)
### 十四.内置函数 -type()
```python
# type()是python的一个内置函数,用来判断变量的数据类型。
# 示例:判断一个变量是什么数据类型? # interview.
v = [1, 2, 3]
if type(v) == str: # str是类。固定写法。
print('v是字符串')
elif type(v) == list: # list是类
print('v是列表')
elif type(v) == tuple: # tuple是类
print('v是元组')
elif type(v) == dict: # dict是类
print('v是字典')
elif type(v) == set: # set是类
print('v是集合')
is == id 的用法;代码块;深浅copy;集合的更多相关文章
- Python基础学习Day6 is id == 区别,代码块,小数据池 ---->>编码
一.代码块 Python程序是由代码块构造的.块是一个python程序的文本,他是作为一个单元执行的. 代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块. 而作为交互方式输入的每个命令都是 ...
- 总结day6 ---- set集合,基本类型的相互转化,编码,数据类型总结,循环时候不要动列表或者字典,深浅copy
python小数据池,代码块的最详细.深入剖析 一. id is == 二. 代码块 三. 小数据池 四. 总结 一,id,is,== 在Python中,id是什么?id是内存地址,比如你利用id ...
- IOS开发之----代码块的使用(二)
iOS4引入了一个新特性,支持代码块的使用,这将从根本上改变你的编程方式.代码块是对C语言的一个扩展,因此在Objective-C中完全支持.如果你学过Ruby,Python或Lisp编程语言,那么你 ...
- 自定义代码块移植,将Xcode中自定义的代码块导出发送到另一台mac
在终端输入 cd /users/xiefan/library/developer/xcode/userdata/codeSnippets xiefan是我的用户名,记得换成自己的用户名 进入CodeS ...
- python代码块和小数据池
id和is 在介绍代码块之前,先介绍两个方法:id和is,来看一段代码 # name = "Rose" # name1 = "Rose" # print(id( ...
- Python小数据池,代码块
今日内容一些小的干货 一. id is == 二. 代码块 三. 小数据池 四. 总结 python小数据池,代码块的最详细.深入剖析 一. id is == 二. 代码块 三. 小数据池 四. ...
- python 小数据池,代码块, is == 深入剖析
python小数据池,代码块的最详细.深入剖析 一. id is == 二. 代码块 三. 小数据池 四. 总结 一,id,is,== 在Python中,id是什么?id是内存地址,那就有人问了, ...
- Python 小数据池和代码块缓存机制
前言 本文除"总结"外,其余均为认识过程:3.7.5: 总结: 如果在同一代码块下,则采用同一代码块下的缓存机制: 如果是不同代码块,则采用小数据池的驻留机制: 需要注意的是,交互 ...
- 记录我的 python 学习历程-Day06 is id == / 代码块 / 集合 / 深浅拷贝
一.is == id 用法 在Python中,id是内存地址, 你只要创建一个数据(对象)那么就会在内存中开辟一个空间,将这个数据临时加载到内存中,这个空间有一个唯一标识,就好比是身份证号,标识这个空 ...
随机推荐
- 【JavaScript框架封装】数据类型检测模块功能封装
数据类型检测封装后的最终模块代码如下: /*数据类型检验*/ xframe.extend(xframe, { // 鸭子类型(duck typing)如果它走起路来像鸭子,叫起来也是鸭子,那么它就是鸭 ...
- ios风格的时间选择插件
1.起因 在上个项目中,客户希望时间选择插件可以是ios风格的那种,但是找了很久,发现并没有用vue的ios风格时间插件,于是自己便自己造了一个轮子. 2.插件效果 3.插件依赖以及安装使用 插件依赖 ...
- Zepto.js 源码解析(emoji版)
graph LR A($) --- B(function) A($) --- C(zepto) A($) --- D(fn) C(zepto) --- CA(init) C(zepto) --- CB ...
- vue组件通信,点击传值,动态传值(父传子,子传父)
转载:https://blog.csdn.net/xr510002594/article/details/83304141 一.父组件传子组件,核心--props 在这里触发 handleClick ...
- 将 excel文件数据导入MySQL数据库中
第一步:先将Excel文件另存为文本文件(制表符分割) 第二步:将生成的txt文件另存,并修改编码格式utf8; 第三步:将文件放到指定位置,或自己想要的位置: G:\city.txt 第四步:避免创 ...
- Google Spanner (中文版)
温馨提示:本论文由厦门大学计算机系林子雨翻译自英文论文,转载请注明出处,仅用于学习交流,请勿用于商业用途. [本文翻译的原始出处:厦门大学计算机系数据库实验室网站林子雨老师的云数据库技术资料专区htt ...
- Oracle学习(11):PLSQL程序设计
PL/SQL程序结构及组成 什么是PL/SQL? •PL/SQL(Procedure Language/SQL) •PLSQL是Oracle对sql语言的过程化扩展 •指在SQL命令语言中添加了过程处 ...
- 网络抓包工具 Fiddler
网络抓包工具 Fiddler 下载网址 http://www.telerik.com/fiddler 简单介绍 Fiddler是一个http协议调试代理工具,它能够记录并检查全部你的电脑和互联网之间的 ...
- 防止 Chrome 屏蔽 非官方 扩展程序 教程(二)
说明 前面介绍过一篇通过开发人员模式载入扩展程序的方法,尽管能够正常使用,可是每次又一次打开 Chrome 都会弹出询问窗体,比較麻烦.这里介绍第二种防止屏蔽的方法.与前一种方法相比,尽管应用的步骤多 ...
- 网页爬虫框架jsoup介绍
序言:在不知道jsoup框架前,因为项目需求.须要定时抓取其它站点上的内容.便想到用HttpClient方式获取指定站点的内容.这样的方法比較笨,就是通过url请求指定站点.依据指定站点返回文本解析. ...